原课程地址:https://time.geekbang.org/column/article/192053
别人写的笔记:https://www.cnblogs.com/liugangjiayou/category/1680565.html
小记归档
printf函数的格式字符
printf函数的声明:
int printf(const char *format, ...)
format是字符串,包含了要被写入到标准输出stdout的文本,他可以包含嵌入的format标签,format标签可悲后续附加参数中指定的值替换,并按需求进行格式化。
format标签属性是%[flags][width][.precision][length]specifier附加参数根据不同的format字符串,函数需要不同的附加参数,每个参数对应了一个需要替换的format中的%标签,因此,参数的个数应该和%标签的个数相同;
数据类型
整型
浮点型
- float
- double
- long double
c语言中的单引号和双引号
起因:
单引号用来初始化单个字符,双引号用来初始化字符串?char a = "a"会warning
而char a = 'a'就不会..待进一步搜索:
- 含义不同;单引号引起的字符,实际上代表一个整数,该整数对应于字符在对应字符集中的序列值;比如常用的ASCII字符集,
's'的含义其实和十进制数115是相同的;而双引号引起的字符串,代表的是一个指向无名数组起始字符的指针; - 大小不同;单引号引起的字符,大小就是1个字节,双引号引起的字符串,大小是字符个数+1个字节,因为会自动在字符串末尾添加二进制值为0的字符
'\0';试验
printf("%d", 'b' - 'a');输出的结果是1,即两个字符相减的结果是一个整型;getchar的用法、和scanf的区别
以无符号char强制转换为int的形式返回读取的字符
即将一个字符强制转换为int形式putchar则与其相反,以无符号 char 强制转换为 int 的形式返回写入的字符,如果发生错误则返回 EOF。
scanf遇到回车停止读取,但不接收回车,此时回车在输入缓冲区中;getchar()从缓冲区读走一个字符;
scanf()的返回值
如果成功,返回成功匹配和赋值的个数,如果出现错误或遇到文件末尾,则返回EOF;
scanf()的%[]用法
%[]叫做扫描集,用于给字符串或字符数组赋值;scanf函数以空白字符空格符、制表符或回车符结束对变量的赋值;- 所有变量都已赋值的情况下,回车是对scanf函数的结束,即继续执行下面的语句;
这就引出来问题:
- 如果想把空白字符赋值给变量怎么办?
- 如果不想用空白字符作为结束,能否用自定的其他字符作为赋值的结束?
此时,%[]扫描集就能解决以上问题:
int main() { char str[100]; printf(“input str:”); scanf(“%[abc]”, str); printf(“str = %s”, str); return 0;
}
输出:abcdef 输出:str = abc
2. `%[^string]`只读取非string字符(^有取反的作用),换言之,只要出现了string中的字符,就停止赋值;```python#include <stdio.h>int main() {char str[100];printf("input str:");scanf("%[^abc]", str);printf("str = %s", str);return 0;}===输入:12a34输出:12
引用:
标识符 c++中 using namespace std的作用
https://blog.csdn.net/fsz520w/article/details/82561795
如何让double类型输出时 不显示多余的0
%[长度修饰][类型修饰][输出类型]
例如printf("%0.2f", i)表示输出小数点后两位;
shift-and算法理解
文本串中每个字符的编码情况,记录着模式串的字符的出现情况
参数p带着模式串与字符串之前位数的匹配情况(如果最近1位的结果是1,说明,上一位就是匹配成功的)p<<1|1和code(str[i])分别代表了两个信息:之前的匹配情况和下一位即将匹配内容的出现情况
每个字符的编码长度=模式串的长度
编码方式描述:模式串第i个字符的编码,等于“1左移i位”与“0”进行“逻辑或”运算;是我一开始想复杂了,并不是递推的关系式,只是把1移到固定的位置——
第0个字符,就把1左移0位,即把从右向左数的第0位赋值为1,说明该字符在第0位出现了;
第i位字符,就把1左移i位,把从右向左数的第i位赋值为1,说明该字符在第i位出现了;
为什么是code的长度是256?
猜测:因为ASCII码有8位,一共能表示256个字符,为了能给所有可能出现的字符提供编码的位置,所以把code的长度定义成了256;
而且code的键是一个“指针”,是一个“地址”;所以本质上讲,对于每一个指向任意字符的地址,都有其对应的code编码,供我们在单模匹配中使用;
编码的形式,我们看到的是十进制形式,但其二进制表示就是我们想要的内容;??有疑问
// str是字符串,p_str是模式串int shift_and(const char *str, const char *p_str) {int code[256] = {0}, m = 0; // code是一个长度为256的数组,并且每一位都初始化为0;为什么是256?,m用于记录模式串的长度// 初始化每一个字符的编码,怎么编的??不懂;编码方式描述:模式串第i个字符的编码,等于“1左移i位”与“上一个字符的编码”进行“逻辑或”运算for (int i = 0; p_str[i]; i++, m++) {code[p_str[i]] |= (1 << i);}int p = 0;for (int i = 0; str[i]; i++) {p = (p << 1 | 1) & code[str[i]];// 如果 p 所对应的模式串最高位为1,代表匹配成功if (p & (1 << (m - 1))) return 1;}return 0;}
按位或、按位与、按位异或:
将位对齐,位与位之间进行计算
- 按位或:两者其中一个是
1,按位或的结果就是1,否则是0 - 按位与:只有两者同时是
1,按位与的结果才是1,否则是0 - 按位异或:两者不一样,按位异或的结果就是
1,否则是0
课程笔记
30 自己编写简易计算器
二叉树的三种遍历方式
- 前序遍历:根节点 { 前序遍历左子树 } { 前序遍历右子树 }
- 中序遍历:{ 中序遍历左子树 } 根节点 { 中序遍历右子树 }
- 后序遍历:{ 后序遍历左子树 } { 后序遍历右子树 } 根节点
仔细观察上面的遍历定义,是一种“递归”定义方式;即{ 前序遍历左子树 }中,把左子树的子节点看做根节点,继续遵循前序遍历的原则进行遍历;
表达式树与后序遍历
任何一个四则运算的表达式,都可以表现为一个二叉树
而表达式计算的值,就是对应的二叉树**后序遍历**的结果
用后序遍历的思路去做递归,代码体现就是:
// 假设函数get_val可以计算字符串表达式String的结果// op代表string表达式中,最后一个计算的运算符// 对于任1字符串表达式,都可以写成下述形式:get_val(String) = get_val(L_String) op get_val(R_String)
如何确定运算的顺序?
针对上面的计算逻辑:“确定当前表达式中,最后一个计算的运算符”就显得尤为重要
如何确定运算符之间的优先级?——通过给所有的运算符附上“计算权重”
对于括号对运算符计算顺序的改变,可以“遇到左括号”就“给运算符加上一个很大的权重”,相反,“遇到右括号”就给运算符减去相同数量的权重
同时,设置一个标签,用于记录当前最低运算优先级的位置;(需在该位置将字符串切分为两个字符串)
#include <stdio.h>#include <string.h>#define INF 0x3f3f3f3f// 计算表达式的值int calc(const char* String, int l, int r) {// 查找当前表达式的根节点// pos记录当前根节点的位置,初始化为-1// priority 记录根节点的权重等级// temp 记录括号带来的权重增加int pos = -1, priority = INF - 1, temp = 0;for (int i = l; i <= r; i++) {int cur_priority = INF;switch(String[i]) {case '(' : temp += 100; break;case ')' : temp -= 100; break;case '+' :case '-' : cur_priority = 1 + temp; break;case '*' :case '/' : cur_priority = 4 + temp; break;default : break;}// 判断当前运算符的优先级// 如果其小于根节点的运算符,就将其设置为新的根节点if (cur_priority <= priority) {pos = i;priority = cur_priority;// printf("update priority: %c, %d, priority is %d\n", String[pos], pos, priority);}}// 如果当前根节点就是优先级最低的根节点,说明当前表达式中没有运算符?则计算if (pos == -1) {int sum = 0;for (int i = l; i <= r; i++) {// 判断 如果有空格之类的,直接跳过if (String[i] < '0' || String[i] > '9') continue;sum = sum * 10 + (String[i] - '0');}// printf("num = %d\n", sum);return sum;}int a = calc(String, l, pos - 1);int b = calc(String, pos + 1, r);switch(String[pos]) {case '+' : printf("%d + %d = %d\n\n", a, b, a + b); return a + b;case '-' : printf("%d - %d = %d\n\n", a, b, a - b); return a - b;case '*' : printf("%d * %d = %d\n\n", a, b, a * b); return a * b;case '/' : printf("%d / %d = %d\n\n", a, b, a / b); return a / b;}return 0;}int get_value(const char *str) {return calc(str, 0, strlen(str) - 1);}int main() {char str1[100];char a[] = "2+(1+3)*2";printf("%s = %d\n", a, get_value(a));while (scanf("%[^\n]", str1) != EOF) { // 只读取非回车字符getchar(); //getchar在此处的作用是什么?猜测是清空掉空格//测试了一下,如果不写getchar,回车后,//程序会不断循环计算第一次输入的公式//但,具体是如何实现的呢?//分析:getchar读走了scanf停止读入时,留在输入缓存区里的\n//如果没有getchar,缓存区中一直有内容//scanf的结果就一直!=EOF,就陷入了死循环printf("%s = %d\n", str1, get_value(str1));}return 0;}
如何实现定义变量?未解决
只需要将26个小写字母作为变量,可以定义一个结构体?
利用小写字符的ascii码,将其与数组的i对应起来?(a的ASCII码是97)
定义一个结构体,用于储存定义的变量和对应的值
结构体内有两个成员:
- 字符型的
名称 - 整型的
值
尝试使用结构体:
#include <stdio.h>struct new_number //定义结构体{char name; // 结构体成员int value; // 结构体成员};int main() {struct new_number a = {'a', 1}; // 结构体实例初始化printf("a.name = %c, a.value = %d", a.name, a.value); // 结构体成员的访问return 0;}
将结构体融入之前的代码:
01 先尝试无输入,直接在程序内部初始化结构体:
需要有一个“把变量替换成数值”的过程——遍历表达式中的每个字符,如果是26个字母中的一个,就替换成对应的数值
问题:如何根据结构体的某个成员,访问结构体的另一个成员?(有点像对字典中内容的访问)?
感觉实现起来有些麻烦,决定再去看看关于“链表”的内容
(其中的7.2讲述的是简单链表简单链表)
为什么要尝试链表?可以动态管理,在计算器中,不确定用户想要输入几个变量;
简单链表的尝试
#include <stdio.h>struct student {long number;float score;struct student *next;};int main () {struct student a, b, c, *head, *p;a.number = 10001, a.score = 99.8;b.number = 10002, b.score = 98.1;a.next = &b, b.next = &c, c.next = NULL;head = &a;p = head;while(p != NULL) {printf("number: %ld\nscore: %.1f\n", p->number, p->score);p = p->next;}return 0;}
如何实现链表的动态管理?未解决
scanf的类型说明符``%[]
char const *strscanf("%[]", str)%[]在scanf中用于扫描字符集合scanf("%[^\n]", str)语句的作用是碰见了回车就把缓冲区的内容按字符串格式存入到str指向的地址中,但此时回车还留在缓冲区内;ps.^是异或运算符,不同则结果为1,相同则结果为0;
29
28
27 测试框架
26 算法篇小结
25动态规划(下)
多重背包
解析:(c++版本)
#include <stdio.h>#define N 100#define max(a, b) (a) > (b) ? (a) : (b)int m, C, dp[N][N]; // 分别是数量、背包容量和能拿的最大价值int w[N] = {0, 4, 3, 12, 9}, n[N] = {0, 5, 4, 2, 7}, v[N] = {0, 10, 7, 12, 8}; // 分别是重量、数量、价值int new_m;int new_w[N], new_n[N], new_v[N];// 写在函数里,发现不行...但写在主程序里的却可以int get_dp(int n, int W, int * n_w, int * n_v) {// 初始化 dp[0] 阶段for (int i = 0; i <= W; i++) dp[0][i] = 0;// 假设 dp[i - 1] 成立,计算得到 dp[i]// 状态转移过程,i 代表物品,j 代表背包限重for (int i = 1; i <= n; i++) {for (int j = 0; j <= W; j++) {// 不选择第 i 种物品时的最大值dp[i][j] = dp[i - 1][j];// 与选择第 i 种物品的最大值作比较,并更新if (j >= n_w[i] && dp[i][j] < dp[i - 1][j - n_w[i]] + n_v[i]) {dp[i][j] = dp[i - 1][j - n_w[i]] + n_v[i];}}}return dp[n][W];}int main() {m = 18;// 二进制拆分new_m = 0;for (int i = 1; i < m; i++) {for (int j = 1; j <= n[i]; j <<= 1) {n[i] -= j; // 减去拆掉的内容new_w[++new_m] = w[i] * j; // 新重量new_v[new_m] = v[i] * j; // 新价值}if (n[i]) { // 余下的是余数,计算余数的重量和价值new_w[++new_m] = w[i] * n[i];new_v[new_m] = v[i] * n[i];}}// 打印二进制分配后的物品for (int i = 0; i < 20; i++) printf("%3d %3d\n", new_v[i], new_w[i]);printf("new_m = %d\n", new_m);// 0/1背包// int ans = get_dp(new_m, 30, new_w, new_n);// printf("ans = %d\n", ans);C = 15;// 初始化物品为0的阶段for (int i = 0; i <= C; i++) dp[0][i] = 0;// 假设dp[i - 1]成立,计算dp[i]for (int i = 0; i <= new_m; i++) {for (int j = 1; j <= C; j++ ) {dp[i][j] = dp[i - 1][j];if (j >= new_w[i] && dp[i][j] < dp[i - 1][j - new_w[i]] + new_v[i]) {dp[i][j] = dp[i - 1][j - new_w[i]] + new_v[i];}}}printf("%d", dp[new_m][C]);return 0;
24 动态规划(上)
动态规划问题的四步骤:
int tgle [7][7] = { {0}, {0, 3}, {0, 9, 5}, {0, 4, 2, 1}, {0, 3, 4, 9, 6}, {0, 3, 5, 3, 7, 3}, {0, 2, 1, 3, 9, 3, 2}, };
// 递推写法 int dp(int i, int j) { if (i == 0) return tgle[i][j]; return max(dp(i - 1, j - 1), dp(i - 1, j)) + tgle[i][j]; }
// 循环写法 int s[50][50] = {0}; int dp1(int i, int j) { if (i == 0) return tgle[i][j]; for (int m = 1; m <= i; m++) { for (int n = 1; n <= 10; n++ ) { s[m][n] = max(s[m - 1][n - 1], s[m - 1][n]) + tgle[m][n]; } } return s[i][j]; }
int main() { printf(“%d\n”, tgle[0][4]); printf(“%d, %d\n”, dp(2, 2), dp1(2, 2)); return 0;
} // max(dp(0, 0), dp(0, 1) + tgle[1][1]) = max(3, 0 + 0) = 3
<a name="NC0mA"></a>### 23 容拆原理与递推算法如果想更深入地了解一下容斥原理,可以通过学习莫比乌斯函数、狄利克雷卷积与莫比乌斯反演等内容,进一步感受一下这个思想所绽放出的光芒。```c// 凑钱#include <stdio.h>int val[8] = {0, 1, 2, 5, 10, 20, 50, 100};int find_combs (int i, int j) {if (j == 0 || i > j) return 1; // 为什么j=0的时候 要return 1;呢?if (i == 1 && (j % val[1] == 0)) return 1;return find_combs(i - 1, j) + find_combs(i, j - val[i]);}int main () {int a = find_combs(3, 1);printf("%d\n", a);printf("%d\n", val[3]);return 0;}
22 单调栈、木板切割
括号有效性 leetcode关于此题的讲解:leetcode
#include <stdio.h>#include <string.h>//读入有括号,返回对应的左括号,如果读入的是左括号,就返回0char pair(char a) {if (a == ']') return '[';if (a == '}') return '{';if (a == '>') return '<';if (a == ')') return '(';return 0;}//利用栈,检查是否匹配;//先将左括号依次填入栈//对于每个右括号,返回其匹配的左括号,如果此时栈内不为空,且栈顶的左括号与返回的左括号相同,则匹配成功//检查下一个栈顶;int isValid(char *s) {int n = strlen(s);char stk[n + 1], top = 0;for (int i = 0; i < n; i++) {char ch = pair(s[i]);if (ch) {if(top == 0 || stk[top - 1] != ch) return 0;top--;} else {stk[top++] = s[i];}}return 1;}int main() {char s[4] = "<(>";int ans = isValid(s);printf("%d", ans);}
太难了 示例代码都看不懂未解决
姑且看懂了一些
ps条件表达式? :
bool ? a : b
条件bool是否成立?如果成立,则值为a,否则为b
#define MAX_N 1000#define max(a, b) ((a) > (b) ? (a) : (b))int s[MAX_N + 5], top;int l[MAX_N + 5], r[MAX_N + 5];int max_matrix_area(int *h, int n) {h[0] = h[n + 1] = -1;top = -1, s[++top] = 0;// 找到每一块木板,左边第一块比其矮的木板编号// 如果栈顶指向的木板比i长,就看栈里下一块木板(从底至顶单调递增栈)// 直到找到第一块比i短的木板,记录在l[i]中,就是左侧第一块比其矮的木板// 并通过s[++top] = i将其记录在栈顶// 疑问:单调递增栈是何时形成的?-是通过s[++top] = i形成的// 单独看while循环和s[++top] = i,意思是:从顶到底遍历栈,当遍历项长度小于当前i长度时,将i放在该项之上(就是形成递增栈的过程)for (int i = 1; i <= n; i++) {while (top >= 0 && h[s[top]] >= h[i]) --top;l[i] = s[top];s[++top] = i;}// 找到每一块木板,右边第一块比其矮的木板编号top = -1, s[++top] = n + 1;for (int i = n; i >= 1; i--) {while (top >= 0 && h[s[top]] >= h[i]) --top;r[i] = s[top];s[++top] = i;}// 在所有木板中,找到面积最大的矩形int ans = 0;for (int i = 1; i <= n; i++) {ans = max(ans, (r[i] - l[r] - 1) * h[i]);}return ans;}
21 单调队列 滑动区间最大值
#include <stdio.h>#define MAX_N 1000int q[MAX_N + 5], head, tail;//a指向原始队列,m是单调队列长度,n是原始队列总个数void invertal_max_number(int *a, int n, int m) {head = tail = 0;for (int i = 0; i < n; i++) {//形成初始队列,将不符合单调性的都踢出去while (head < tail && a[q[tail - 1]] < a[i]) tail--;//直到维护了单调性,i可以入队了q[tail++] = i;//判断队列长度是否超出了范围if(i - m == q[head]) head++;//输出区间内的最大值,i+1大于区间长度,确保第一个区间已经形成if(i + 1 >= m) {printf("invert(%d, %d)=", i - m + 1, i);printf("%d\n", a[q[head]]);printf("q[head]=%d, q[tail]=%d\n\n", q[head], q[tail]);}}return ;}int main() {int a[8] = {1, 3, -1, -3, 5, 3, 6, 7};invertal_max_number(a, 8, 3);return 0;}
20 二分查找
二进制右移>>通常可以理解为除以2(大部分情况下成立)
练习:通过税后工资 反推税前工资
思路:读入工资-二分法查找所在区间-反推税前工资-
#include <stdio.h>//计算税后工资的函数double salary_aft(double salary) {if (salary <= 3000) return salary * 0.97;if (salary <= 12000) return (salary - 3000) * 0.9 + 3000 * 0.97;if (salary <= 25000) return (salary - 12000) * 0.8 + 3000 * 0.97 + 9000 * 0.9;if (salary <= 35000) return (salary - 25000) * 0.75 + 3000 * 0.97 + 9000 * 0.9 + 13000 * 0.8;return -1;}//二分查找double binary_search(double x, double l, double r) {double mid;while (l < r) {mid = (l + r) / 2.0;if (salary_aft(mid) == x) return mid;if (salary_aft(mid) < x) l = mid;r = mid;}return -1.0;}int main () {double y;y = binary_search(23000.0, 0.0, 35000.0);printf("%.2f\n", y);return 0;}
分析:永远返回-1,是因为无论循环多少次,结束循环的时候都会return -1;
解决办法:改成return mid;当循环结束的时候,l == r == mid,也就是我们要找的值,直接返回mid即可;
可运行的代码如下:
bug1:输入小于3000的数字,会让程序陷入无线循环;
bug2:输入最后一个梯度的数字,计算是错误的,如下图: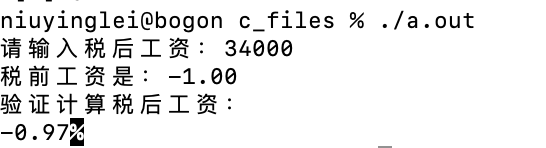
分析原因,无限循环和 segmentation fault错误,是因为double的精度有限,不可能无限的循环下去,因此需要以double类型的精度为基准,为循环设置条件——一般我们认为浮点数的误差在10的负七次方以下的时候,就认为两个数字相等,因此将while循环的条件做更改:
由while(r < l)改为while(r - l >= 1e-7)
并且在起始位置增加条件if(r - l <= 1e-7) return r;
最终可运行的代码如下:
#include <stdio.h>//计算税后工资的函数double salary_aft(double salary) {if (salary <= 3000) return salary * 0.97;if (salary <= 12000) return (salary - 3000) * 0.9 + 3000 * 0.97;if (salary <= 25000) return (salary - 12000) * 0.8 + 3000 * 0.97 + 9000 * 0.9;if (salary <= 35000) return (salary - 25000) * 0.75 + 3000 * 0.97 + 9000 * 0.9 + 13000 * 0.8;return -1;}//二分查找double binary_search(double x, double l, double r) {double mid;if (r - l <= 1e-7) return r;while (r - l >= 1e-7) {mid = (l + r) / 2.0;if (salary_aft(mid) == x) return mid;if (salary_aft(mid) < x) l = mid;if (salary_aft(mid) > x) r = mid;}return mid;}int main () {double x, y;printf("请输入税后工资:");scanf("%lf", &x);y = binary_search(x, 0.0, 35000.0);printf("税前工资是:%.2f\n", y);printf("验证计算税后工资:\n");printf("%.2f", salary_aft(y));return 0;}
#include <stdio.h>//计算税后工资的函数double salary_aft(double salary) {if (salary <= 3000) return salary * 0.97;if (salary <= 12000) return (salary - 3000) * 0.9 + 3000 * 0.97;if (salary <= 25000) return (salary - 12000) * 0.8 + 3000 * 0.97 + 9000 * 0.9;if (salary <= 35000) return (salary - 25000) * 0.75 + 3000 * 0.97 + 9000 * 0.9 + 13000 * 0.8;return -1;}//二分查找,递归思维double binary_search(double x, double l, double r) {double mid = (l + r) / 2.0;if (r - l <= 1e-7) return l;if (salary_aft(mid) == x) return mid;if (salary_aft(mid) < x) return binary_search(x, mid, r);if (salary_aft(mid) > x) return binary_search(x, l, mid);return -1.0;}int main () {double x, y;printf("请输入税后工资:");scanf("%lf", &x);y = binary_search(x, 0.0, 35000.0);printf("税前工资是:%.2f\n", y);printf("验证计算税后工资:\n");printf("%.2f", salary_aft(y));return 0;}
二分法切绳子
#include <stdio.h>#include <math.h>//初始化记录,原始的绳子长度和数量double l[100], n;//切绳子函数,接收参数:想要的绳子长度x,返回参数:能切出的最多个数yint f(double x) {int m = 0;for(int i =0; i < n - 1; i++) {m += (int)floor(l[i] / x);}return m;}//二分法查找double binary_search(double l, double r, int k) {if (r - l <= 1e-7) return r;double mid = (l + r) / 2.0;if (f(mid) < k) return binary_search(l, mid, k);return binary_search(mid, r, k);}int main() {double l[3] = {4.0, 5.0, 6.0};int n = 3;double m;m = binary_search(l[0], l[2], 4);printf("%f\n", m);}
19 运用链表思维解决快乐数问题
18 链表
链表的插入,为什么我理解的总是错位?
struct Node *insert(struct Node *head, int ind, struct Node *a) {struct Node ret, *p = &ret;ret.next = head;// 从【虚拟头节点】开始向后走 ind 步while (ind--) p = p->next; //这里用的ind--,而不是--ind;即先使用ind的值,再进行--// 完成节点的插入操作a->next = p->next;p->next = a;// 返回真正的链表头节点地址return ret.next;}
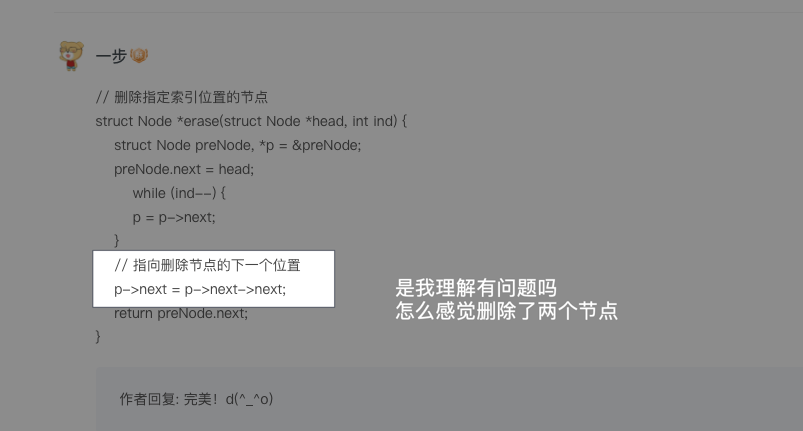
再仔细看,不是删除了两个,而是比我写的向后删除了一个
我的代码是p = p->next;有疑问
#include <stdio.h>//定义链表节点结构struct Node {int data;struct Node *next;};//定义链表的插入方法struct Node *insert(struct *head, int ind, struct Node *a) {struct Node ret, *p = &ret;ret.next = head;//从虚拟头结点向后走ind步while(ind--) p = p->next;//此处ind还是越来ind的值,先用后减//完成节点插入的操作a->next = p->next;p->next = a;//返回链表头结点的位置return ret.next;}//定义链表的删除方法struct Node *erase(struct Node *head, int ind) {struct Node ret, *p = &ret;ret.next = head;//思路:向后走ind步,完成节点的删除操作while(ind--) p->next;p = p->next;return ret.next;}
17
16
实现大整数的相加
函数没能改变main函数中定义的数组a[]
之前明明实现了,是因为我把函数从void改成了int吗?不是
好像是因为在函数中又定义了一个同名数组a[];是的
现在把a[]的定义放在所有代码的最前面,并且不在函数中定义同名的数组,函数所更改的就是最前面定义的a[];
如何实现在main中定义,在函数中修改、或者 不需要定义,直接在函数中返回呢?未解决
c语言不允许返回数组作为函数的参数,但是通过指定不带索引的数组名来返回一个指向数组的指针,可以通过该指针访问数组
strlen
-
c语言 字符和数字的相互转换:
int类型加‘0’变字符
char类型减‘0’变int
char b = '5';printf("%d", b - '0');
https://blog.csdn.net/qq742143797/article/details/107450976
如何不用len函数”计算数组的长度“或”遍历数组“?未解决
-
15
用筛法求解积性函数
真的废了不少劲啊…. ```c
include
include
define MAX_N 10000
int prime[MAX_N + 5] = {0};
void init_prime() { for (int i = 2; i i <= MAX_N; i++) { if(prime[i]) continue; for (int j = 2 i; j < MAX_N; j +=i) { if (prime[j]) continue; prime[j] = i; } } for (int i = 2; i < MAX_N; i++) { if(prime[i] == 0) prime[i] = i; } return ; }
int g_cnt[MAX_N + 5];
void init_g_cnt() { g_cnt[1] = 1;
//将prime中等于0的项,初始化为下标,因为对于素数,其自身就是最小素数for (int i = 1; i <= MAX_N; i++) {if (prime[i] == 0) prime[i] = i;}//利用prime数组记录的最小素因子,计算每个数对应的素因子的个数for (int i = 2; i <= MAX_N; i++) {int n = i, cnt = 0, p = prime[i];while (n % p == 0) {cnt += 1;n /= p;}//在这里运用了”数论积性函数“的性质g_cnt[i] = g_cnt[n] * (cnt + 1);}return ;
}
//等比数列求和 int sum_euq(int m, int n) { int sum = 0; for (int i = 0; i <= n; i++) { sum += pow(m, i); } return sum; }
int g_sum[MAX_N + 5];
void init_g_sum() { g_sum[1] = 1; g_sum[2] = 3; g_sum[3] = 4;
//利用prime数组记录的最小素因子,计算每个数对应的素因子的和for (int i = 3; i <= MAX_N; i++) {int n = i, cnt = 0, p = prime[i];while (n % p == 0) {cnt += 1;n /= p;}g_sum[i] = g_sum[n] * (sum_euq(p, cnt));}
}
int main() { init_prime(); int i; scanf(“%d”, &i); printf(“最小素数是:%d\n”, prime[i]); init_g_cnt(); printf(“素因数的个数是:%d\n”, g_cnt[i]);
init_g_sum();printf("素因数的和是:%d\n", g_sum[i]);return 0;
}
<a name="FFzff"></a>###<a name="lhqBo"></a>### 07<a name="j8xVJ"></a>#### 结构体占用的储存空间逻辑?- 结构体的“最小储存单元”大小,等同于其内部储存的最大的基础类型占用的空间大小;- 结构体内,数据的储存顺序,按照定义结构体时的顺序;如果当前“最小储存单元”不足以储存下一个基本数据类型,则从下一个储存单元的头部开始储存;分析:- 两个结构体的最小储存单元都是其内部的最大基础类型:int,占4字节- `Data1`结构体中,先储存整型,再储存两个字节- 一个整型占一个“最小储存单元”,4字节- 后两个字符型,占两个字节;第二个“最小储存单元”够用- →所以,`Data1`的大小是8字节- `Data2`结构体中,先储存一个字符型,1字节,再储存一个整型,4字节,再储存一个字符型,1字节- 一个字符型占1个“最小储存单元”的1字节;- 但剩余的3个字节,不足以储存下一个数据类型:整型(4字节);- 因此,整型a储存在下一个“最小储存单元”中- 字符类型c储存在第三个“最小储存单元”中- →需要3个“最小储存单元”,即3×4=12字节<a name="HvK9b"></a>#### `&`与`*`是什么意思?- `&`可以取到变量的地址- `*`用来声明定义的变量是指针变量;也代表取指针内部所储存的值,也叫`**取值运算符**`;```cint a = 45, *p = &a;// 此时:*p == a == 45;// 注意,两个*的区别,第一个用于声明定义的是一个指针变量,第二个是“取值运算符”
一个指针变量占用多少空间?
无论如何,指针变量都是一个指针,所以无论是什么类型的指针变量所占用的空间大小都是一样的;就像无论城市的量级有多不同,邮编都只占6位;
什么是间接引用与直接引用?
对于下面的结构体a[1].x是直接引用;a+1->x就是间接引用;
a是指向结构体变量a第一个元素,首个字段的首地址?
a+1是一个指针,指向变量a[1],那么a+1->x等价于a[1].x
前者是间接引用,后者是直接引用;
思考题:
struct Data {int x, y;} a[2];struct Data *p = a;printf("%p", &a[1].x);
用尽可能多得形式,替换代码中&a[1].x 的部分,使得代码效果不变 :
- 用间接引用实现
&((a+1)->x)
- 巧妙使用指针类型
- 思考结构体
a在内存中的储存形式 a[1].x在内存中的前1位是什么?- 是
a[0].y - 那么地址
&a[1].x就等价于地址&(a[0].y)+1 - 同理,也等价于
&(a[1].y)-1 - 也等价于
&(a[2].x)-2 - 也等价于
&(a[2].y)-3
- 思考结构体
利用指针和a的等价:
- 所有的
p都可以用来替换a[0] - 所有的
p+1都可以用来替换a[1],也可以等价于p[1] - 所有的
p+2都可以用来替换a[2],也可以等价于p[2]
以上方式的思路都是通过a定位x的地址;
如何通过指针p定位x的地址呢?
*p = a指针p,指向的是a的头部,也就是a[0]p + 1是哪?a[1]的头部- 那么
&a[1].x等价于&(p + 1).x?- 有错误,取地址运算符
&的优先级低于直接引用运算符.,所以正确的写法应该是&((p + 1).x)
- 有错误,取地址运算符
通过p,巧用指针类型:
- 指针的类型,决定了通过指针取值时,向后取的字节数量;
- 指针的类型,决定了指针加减法时向前/后移动的字节的数量;
- 无论是任何类型的指针,大小都相等;
06
“字符串长度”与“字符串占用空间”
"hello world"为例
- 字符串长度是11
- 字符串占用空间是12
- 因为字符串结尾有一个结尾字符
/0占用一个字节
思考题2:在不计算字符串长度的情况下,遍历输出字符串中的每一位;
不能使用if循环,不能使用计算字符串长度的方法
思路:
- 使用while循环遍历
- 通过判断字符串内容是否是
"\0"来判断字符串是否结束 - 还有很多问题没搞清楚有疑问
int main() { char str1[12] = “hello world”; int i = 0; while (str1[i] != ‘\0’) { // printf(“i = %d\n”, i); printf(“%c\n”, str1[i]); i++; } return 0; }
<a name="i77d3"></a>#### 实现任意保留小数思路:- 保留两位语句:`printf("%.2lf", a)`- 保留n位:`printf("%.nlf", a)`- printf的第一个参数其实就是一个字符串,实现根据输入的情况,自定义字符串中的n即可- `printf(str, a)``scanf("%d",&n)``sprintf(str, "%%.%dlf", n)`- sprint的功能是关键的一步,用n替代字符串中的内容,并把字符串赋值给字符数组```python#include <stdio.h>int main() {int n;double num;char str[100];scanf("%lf%d", &num, &n);sprintf(str, "%%.%dlf\n", n);printf(str, num);return 0;}
05
字节、比特与地址
计算题
#include <stdio.h>int f[1001];int main() {// 定义并读入m、nint n, m;printf("input n:");scanf("%d", &n);printf("input m:");scanf("%d", &m);// 逐个读入n个数int f1[n-1];for (int i = 0; i < n; i++){printf("input f[%d]:", i);scanf("%d", &f1[i]);}// 用于记录,每个元素都初始化为0int ans[m+1];for (int i = 0; i <= m + 1; i++) ans[i] = 0;// 把f1中的每个数的倍数作为下标对应的值都置为1for (int t = 0; t < n; t++) { // 针对每个i 逐个检查i能否被整除int n_max = m / f1[t];for (int i = 0; i < n_max + 1; i++) {ans[i * f1[t]] = 1;}}// 输出数组中,值仍为0的元素的下标for (int i = 0; i < m + 1; i++){if (ans[i] == 0) printf("%d ", i);}return 0;}

04
真随机与伪随机
- 真随机,每次取数,相互独立,上一个数不影响下一个数
- 伪随机,实际上是一个伪随机序列,上一个数决定了下一个数;
- 所有语言都是伪随机
?,程序通过第一个随机数和固定计算规则,给出剩下的随机数作业 打印乘法口诀表:
```cinclude
int main() { int i = 1, k = 1;
for(k = 1; k < 7; k++) {for ( i = 1; i <=k; i++) {printf("%d*%d = %d", i, k, i*k);if(i != k) printf("\t"); else printf("\n");}}
return 0; }
<a name="DmSwm"></a>#### 作业 完成日期计算器 done```c#include <stdio.h>int main() {int y, m, d, x;printf("input y m d:\n");scanf("%d%d%d", &y, &m ,&d);printf("input how many days:\n");scanf("%d", &x);for (int i = 0; i < x; i++ ) {d += 1;printf("d plus done.\n");switch (m) {case 1: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;case 2: {if((y % 4 == 0 && y % 100 != 0) || y % 400 == 0) {printf("你输入的是闰年\n");if (d > 28) {d = 1; m += 1;};if (m == 13) {m = 1; y += 1;};} else {printf("不是闰年\n");if (d > 27) d = 1; m += 1;if (m == 13) m = 1; y += 1;};}; break;default: {printf("default, 30days per month.\n");if (d > 30) d = 1, m += 1;if (m == 13) m = 1, y += 1;};case 12: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;case 10: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;case 8: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;case 7: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;case 5: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;case 3: {if (d > 31) d = 1, m += 1;if (m == 13) m = 1, y += 1;}; break;};printf("%d年%d月%d日\n\n", y, m, d);};printf("final:%d年%d月%d日\n", y, m, d);return 0;}// 遇到的坑:if语句,接多个句子,不用大括号,句子之间错误的使用了;而没有使用,// 这导致,第一个;之后的语句 不再属于if结构体。// 基本功很重要,如果不是亲自写代码,不会发现自己有这个问题
为什么c用%d代表整型而不用%i?
- 实际上,用
%i代表整型是可行的,c语言支持 - 其次,
%d中的d是decimal,十进制数,所以用%d不无道理printf如何格式化输出?自动右对齐,每个数字固定占3位那种未解决
printf("%3d",a);打印宽度为3,右对齐,如果字数不足,则在左边补足空格;如何控制随机数的区间?
rand()生成随机数rand() % ran_max得到[0-ran_max)区间的随机数1.0 * rand() / RAND_MAX得到[0.0,1.0]区间的随机数作业 用随机数计算π
```cinclude
include
include
int main() { int x; printf(“how many times:\n”); // 自定义进行实验的次数 scanf(“%d”, &x); int m = 0, n = 0; for (int i = 0; i < x; i++) { double x = 1.0 rand() / RAND_MAX; double y = 1.0 rand() / RAND_MAX; if (x x + y y <= 1) m += 1; n += 1; }; printf(“%lf\n”, 4.0 * m / n); return 0;
}
<a name="cXdgg"></a>#### 搞清楚对象文件的作用:c语言中,程序从源代码到可执行文件,需要4个步骤:- 第一步,预处理源代码,生成“待编译源码”- 源代码就是我们自己写的代码;- 其中包含了一些“需要预先处理的命令”,比如`#include<stdio.h>`;- 预处理的作用,就是执行预处理命令;- 具体操作就是将需要的内容复制到源代码中,供下一个阶段使用;- 第二步,编译“待编译源码”,生成“对象文件”- 待编译源码是完全体的代码,但仍旧是一种“人类创造出来的语言”(c语言)- 但计算机看不懂,计算机只能看懂0和1- 所以需要讲人类的语言“翻译成”计算机能看懂的语言- 这个步骤就是编译- 但是编译后,还有些对象需要链接?未解决- 即对象文件是“已编译但未链接“- 第三步,链接对象文件,生成可执行程序- 比如需要调用`printf`函数,`printf`函数存在于预先编译好的printf.o文件中,链接器负责将printf和调用printf的代码合并,得到可执行程序<a name="SK5yi"></a>#### 如何在macOS终端运行c程序?- 需要安装xcode- 创建hello.c文件- 通过终端编译文件`gcc hello.c`- 编译通过,会在当前目录生成`a.out`文件- 通过终端执行`a.out`文件`./a.out`- 如果是多个c语言源文件,则需要通过`gcc file1.c file2.c -o main.out`生成名为main.out的文件,再通过`./main.out`执行<a name="Sem90"></a>#### 编译+执行太麻烦了 如何用vim直接执行?好像不可以... 用IDE比较方便<a name="iJuAZ"></a>#### c语言中的&和*分别是什么意思?未解决`*`代表指针、或取值(访问指针)<br />`&`代表取地址?<br />`int *p`<br />`printf("%d", p)`——用`%d`来输出地址<a name="FQwg7"></a>#### 关于指针:- 定义一个指针变量`int *p`- 把变量地址赋值给指针```cint a = 100;int *p;p = &a; //把变量的地址赋值给指针
访问指针变量中可用地址的值
int *p;printf("%d", *p); /访问指针变量中可用地址的值
指针的类型可以进行运算
++ -- + -
const int MAX = 3;
int main() { int var[] = {1, 2, 3}; int i, *ptr;
ptr = var;for (i = 0; i < MAX; i++) {printf("var[%d]的地址是:%p\n", i, ptr);printf("var[%d]的值是:%d\n", i, *ptr );ptr++;}return 0;
}
- 指针也可以用来比较`== < >`- 当两个指针`p1 p2`指向了两个相关的变量,比如同一个数组中的两个不同元素,则可以对两个指针进行大小的比较```c#include <stdio.h>const int MAX = 3;int main() {int var[] = {1, 2, 3};int i, *ptr;ptr = var;i = 0;while(ptr <= &var[MAX - 1]) {printf("var[%d]的地址是:%p\n", i, ptr);printf("var[%d]的值是:%d\n", i, *ptr );ptr++;i++;}return 0;}
void getSeconds(unsigned long *par);
int main() { unsigned long sec;
getSeconds( &sec );printf("number of seconds:%ld\n", sec);return 0;
}
void getSeconds(unsigned long par) { par = time(NULL); return; }
<a name="Vv3YK"></a>#### c中的“宏”是什么?未解决查找替换<br />`va_start(va_list argptr, lastparam);`<br />`va_start`是一个宏<a name="Pe0EP"></a>#### c如何注释?- 行内注释`//`- 块注释`/* ... */`<a name="Fvd1L"></a>#### 如何一次性声明多个头文件?<a name="LhC9M"></a>#### 为什么c程序里一定要写main函数<a name="QyxT0"></a>#### 学习可选参数的实现:参考链接:[http://c.biancheng.net/view/344.html](http://c.biancheng.net/view/344.html)```c// 函数add() 计算可选参数之和// 参数:第一个强制参数指定了可选参数的数量,可选参数为double类型// 返回值:和值,double类型#include <stdarg.h>#include <stdio.h>double add(int n, ... ){int i = 0;double sum = 0.0;va_list argptr;va_start( argptr, n ); // 初始化argptrfor ( i = 0; i < n; ++i ) // 对每个可选参数,读取类型为double的参数,sum += va_arg( argptr, double ); // 然后累加到sum中va_end( argptr );return sum;}int main(){printf("%lf", add(4,1.1,2.2,2.3));}
break与continue

若有收获,就点个赞吧
0 人点赞
