第一次成功!!!
学了很多,实际操作后才发现,不是那么回事
很打击积极性——我学了这么久,连个简单的excel表格处理需求都处理不好!?
从上周六(7.15)开始弄,到现在7.19 下午18:08才完成了初版、可执行、可使用的代码
从这件事上可以看出:
- 学习的方式有问题;学了很多,掌握很少,理论过多,实操过少;→改进学习的方式
- 心态不稳定;遇到了困难,就开始怀疑自己→少想,多做,加快学习的速度
需求:从A.xlsx文件中提取B.xlsx中表头中的列,新建保存到C.xlsx中
第一次成功的代码:(感觉有很大可改进空间)
from openpyxl import load_workbookfrom openpyxl.utils import get_column_letterfrom openpyxl import Workbookwb = Workbook()ws1 = wb.activesor_wb = load_workbook("7月社保增减员 - 副本.xlsx")sor_ws = sor_wb.activemodl_wb = load_workbook("汇缴增加变更清册模版.xlsx")modl_ws = modl_wb.activedef find_col_index(sor_ws, modl_ws):col_index = []for i in sor_ws[1]:if i.value in [cell.value for cell in modl_ws[1]]:col_index.append(get_column_letter(i.column))print(col_index)return col_indexdef get_colums(col_index, sor_ws, tar_ws):prj = sor_ws.columnsprjTuple = tuple(prj)t_row = 1t_col = 1all_columns = sor_ws.columnsfor idx in col_index:for cell in sor_ws[f"{idx}:{idx}"]:# print(f"copy sor_ws['{idx}{cell.row}']")tar_ws.cell(row = cell.row, column = t_col, value = cell.value)t_col += 1print(f"got {t_col - 1} cols")col_index = find_col_index(sor_ws, modl_ws)get_colums(col_index, sor_ws, ws1)wb.save("try123.xlsx")
使用openpyxl获取某一列
wb = load_workbook("文件路径\文件名")sheet = wb.get_sheet_by_name("索要获取信息的sheet名称")print(sheet.title)prj = sheet.columnsprjTuple = tuple(prj)for idx in range(1,len(prjTuple)):#可以自己选取对应的列for cell in prjTuple[idx]:print(cell.value)
idx就是列的索引,idx=3 就是第3列
那么,只需要挑选出我们需要的列,保存为数字列表就好
需求:入离职人员提取
两个主体
元满母婴 光而不耀
状态不是{待入职}
增员:
入职时间:上个月16日到本月15日(含15
减员:
离职日期:上月16(含16 到本月15日(不含15
同时满足的:标出来入职没几天就离职了
pandas 字符串转换为日期
参考
pandas.to_datetime(str)
返回的是Timestamp对象:
可以直接提取月份: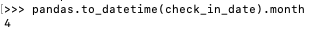
也可以调用date()方法,返回的是date对象:
同时,datetime.today()返回的也是datetime对象: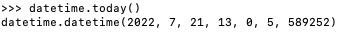
调用datetime对象的date()方法,获得了date对象:
现在来看,两者能不能直接比较:
可以!
做减法呢?
也可以!获得timedelta对象,并标明了days的天数
该对象的天数,可以通过days属性提取出来,返回整型
那么,如果想计算两个日期之间的差值,直接做差就可以了;
错误TypeError: unsupported operand type(s) for -: 'NaTType' and 'datetime.date'
经测试,只留checkin_date就可以正常运行,猜测因为checkin_date对数据的处理,导致check_out数据的类型出错?
知道了 有些人的离职日期是nan,所以减操作不成功
pandas在读取空单元格的时候,读到空字符串是nan
让pandas读取的空字符串为''——keep_default_na = False
参考:
如何通过字符串创建datetime对象?
使用datetime.datetime.strptime(str, pattern)
参考
获取当前月份
datetime.datetime.today().month
dateframe 获取行索引
df.keys()
list转换为DataFrame
v2.0导出为excel
#!/usr/bin/env python# coding: utf-8# %load /Users/niuyinglei/Desktop/try_excel/in_decrease_staff.py#!/usr/bin/pythonimport mathfrom datetime import datetimeimport pandas as pdimport csvimport openpyxlsubject = ['北京元满母婴护理有限公司', '北京光而不耀科技有限公司']status = ['待入职']# 分别记录入离职人数checkout_num = 0checkin_num = 0datas = []out_datas = []# 打开表格,用pd,引擎用openpyxldf = pd.read_excel("1 copy.xlsx", engine = "openpyxl", keep_default_na = False)# 计算绝对值def abs_value(a):if a >= 0:a = aelse:a = -areturn a# 获取当前月份year = datetime.today().yearmonth = datetime.today().monthcurmon_15 = datetime.strptime(f"{year}/{month}/15", "%Y/%m/%d").date()premon_16 = datetime.strptime(f"{year}/{month - 1}/16", "%Y/%m/%d").date()print(f"curmon_15:{curmon_15}\npremon_16:{premon_16}")# 获取单元格date并修改格式def get_date(str_date):if str_date is not '':date = pd.to_datetime(str_date).date()else:date = datetime.strptime('1900/01/01', '%Y/%m/%d').date()return date# 多条件筛选,参数分别为[read_excel文件][主体名称列表][入职状态][入职时间检查]def mul_filter(df, subject, status, check):if df.loc[i].values[23] in subject:if df.loc[i].values[34] not in status:if check:return Truereturn False# 获取行号索引,遍历,根据需要的列的内容进行筛选,并记录for i in df.index.values:checkin_date = get_date(df.loc[i].values[35])checkout_date = get_date(df.loc[i].values[39])# 离职判断checkout_judge = premon_16 <= checkout_date < curmon_15# 入职判断checkin_judge = premon_16 <= checkin_date <= curmon_15if mul_filter(df, subject, status, checkin_judge):# print(df.loc[i].values)datas.append(df.loc[i].values.tolist())if mul_filter(df, subject, status, checkout_judge):# print(df.loc[i].values)out_datas.append(df.loc[i].values.tolist())df_datas = pd.DataFrame(datas[1:], columns = df.keys().tolist())df_datas.to_excel('入职名单.xlsx', encoding = 'utf8', index = False) # index = False 不生成索引,这样第一列就不是0开头的数字索引了df_datas = pd.DataFrame(out_datas[1:], columns = df.keys().tolist())df_datas.to_excel('离职名单.xlsx', encoding = 'utf8', index = False)
如何打包为可执行文件
pyinstaller库
常用参数
| 参数 | 描述 |
|---|---|
| -h | 查看帮助 |
| —clean | 清理打包过程中的临时文件(-pycacle-、build) |
| -D | 将可执行的文件以一组文件的形式生成在dist目录中,默认值生成dist文件夹 |
| -F | 在dist文件夹中只生成独立的打包文件 |
| -i | 指定打包程序使用的图标 |
使用参数-F打包后,会多出三个内容: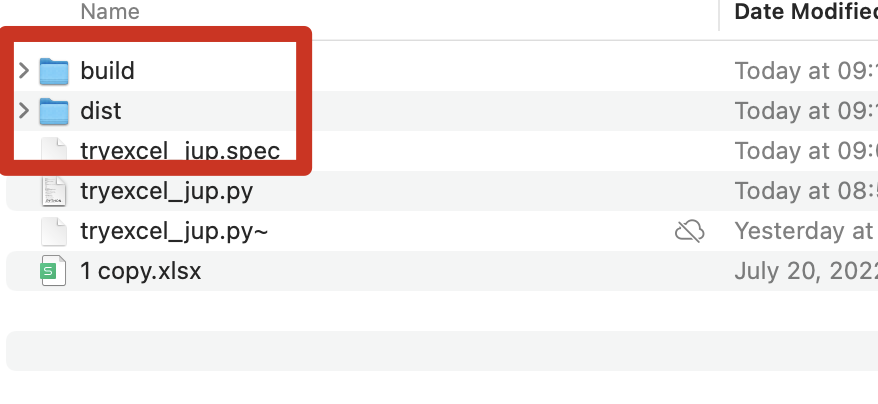
可运行文件在文件夹dist内,第一次运行,报错filenotfound,没有找到文件FileNotFoundError: [Errno 2] No such file or directory: '1 copy.xlsx'
此时程序应该是在用户根目录niuyinglei里找,修改输入文件的位置:
改为桌面:
再次打包运行,成功,生成的名单在根目录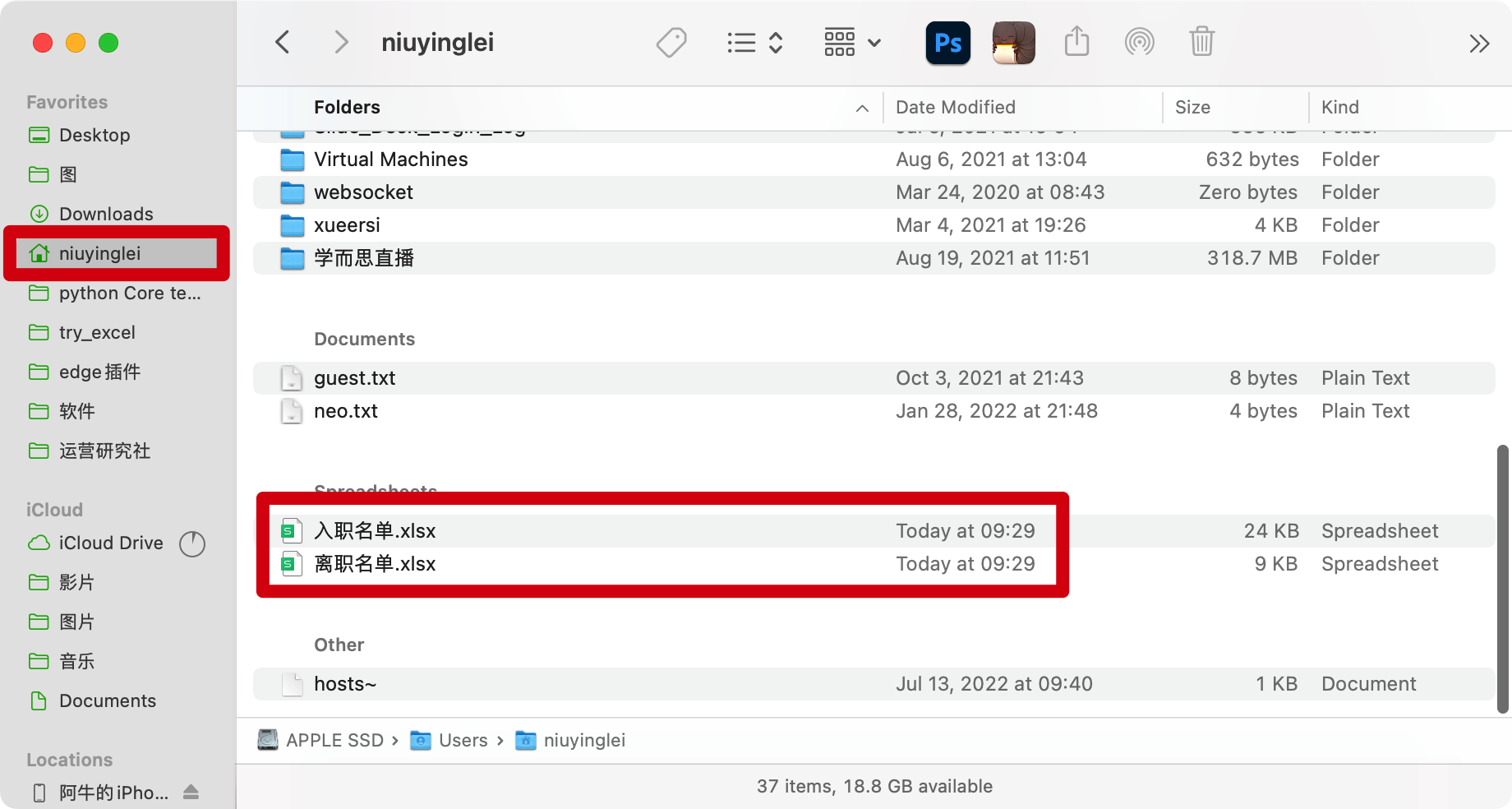
在macOS下打包的内容,在win下是否可以运行?
不可以运行
好像不可以,不是exe可执行文件,更改扩展名也不行
pyinstaller在macOS和win上都可以使用,但macOS下打包的只能在macOS上运行,win同理,所以需要在win上搭建python环境、所需要的库等
>>>win搭建python环境 《win搭建python环境》
在win下检查运行并打包
检查运行

错误1 win下的\转义
python下,\符号有转义的含义,比如\n是换行,因此需要采取一些方式,让\不再转义,让python能正确读取路径:
- 用
\\代替所有\ - 在路径外面加
r'',让python忽略字符串中的转义 -
错误2
is not抛出语法错误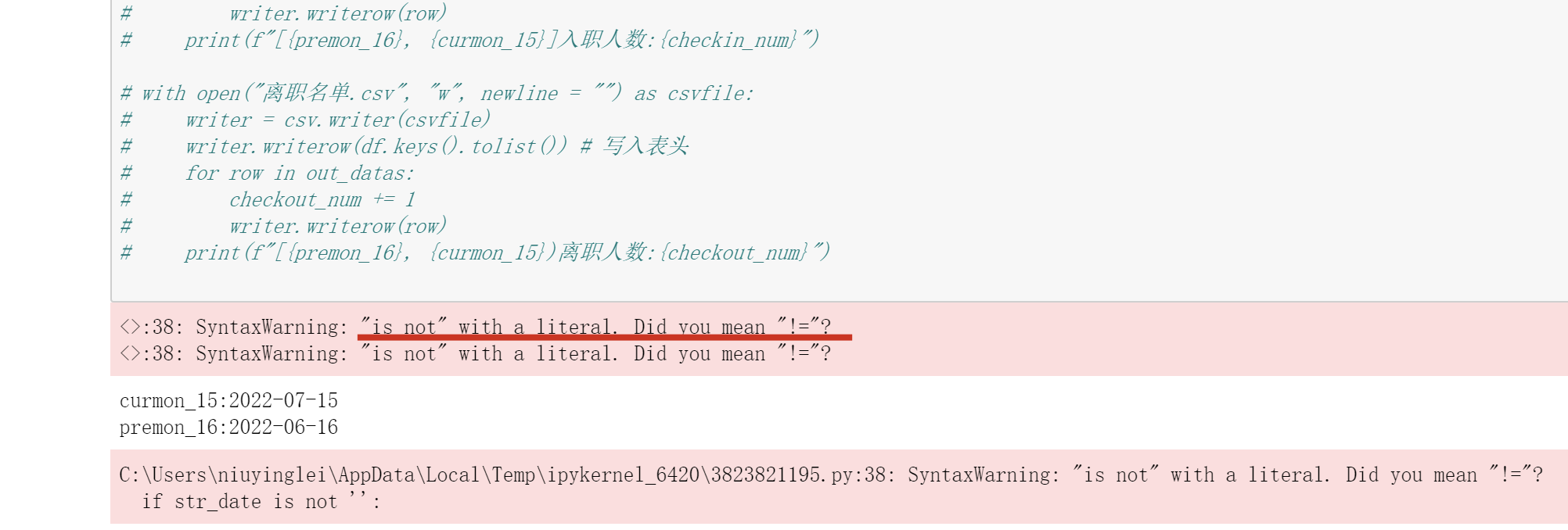
好像是因为我的win的python版本高于macOS,而高版本的python中使用is和is not会抛出语法错误: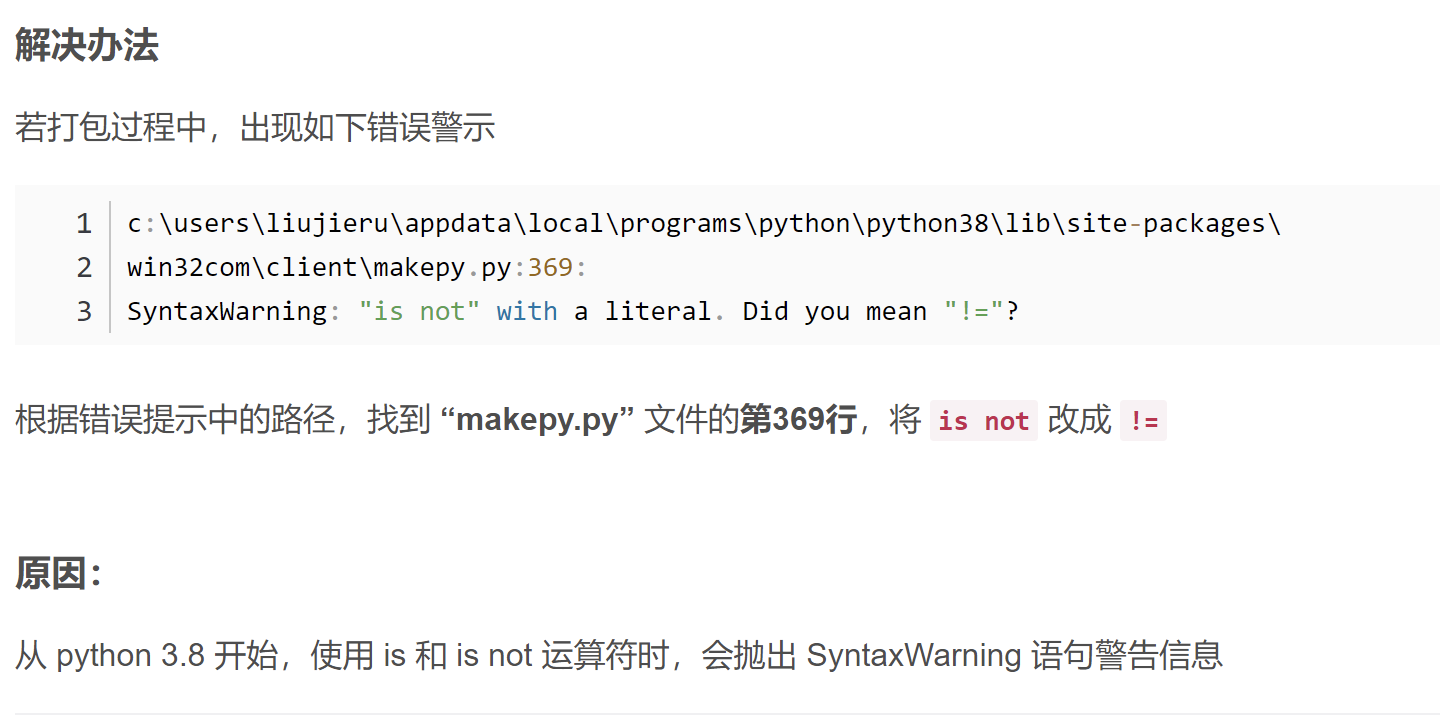
解决方式:用!=替换is not运行成功,文件输出在了桌面
实现读取、输出的文件都放在桌面
直接都放在桌面,代码里不用添加文件路径,自动会读取桌面文件并输出到桌面有疑问
好像不是上述所说,而是因为我的notebook文件默认地址是桌面win下打包
安装pyinstaller:

打包:
错误1:IndexError: tuple index out of range
参考:
打包成功,生成exe文件: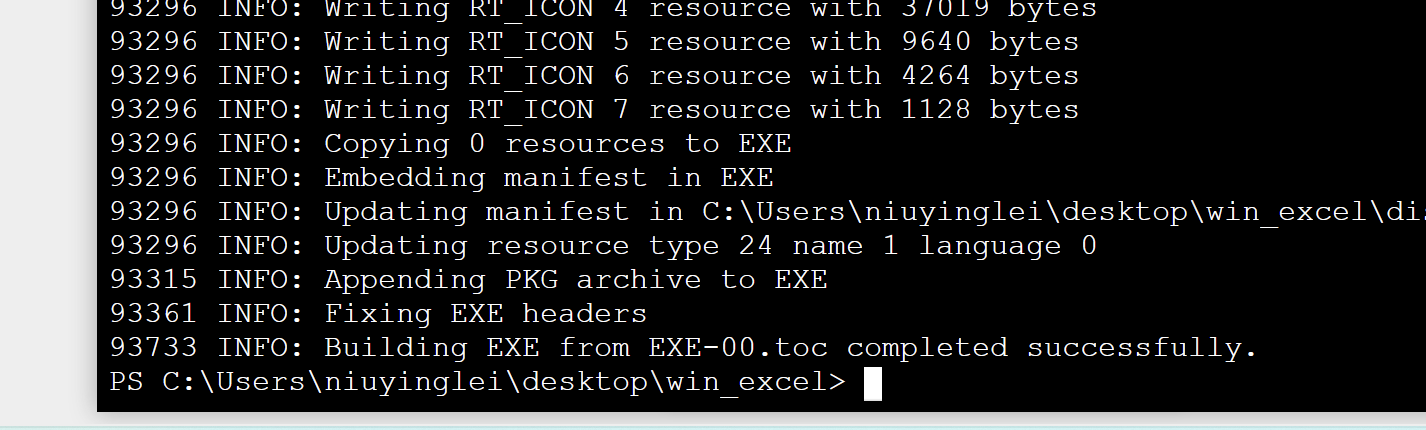
尝试运行,没找到输入文件: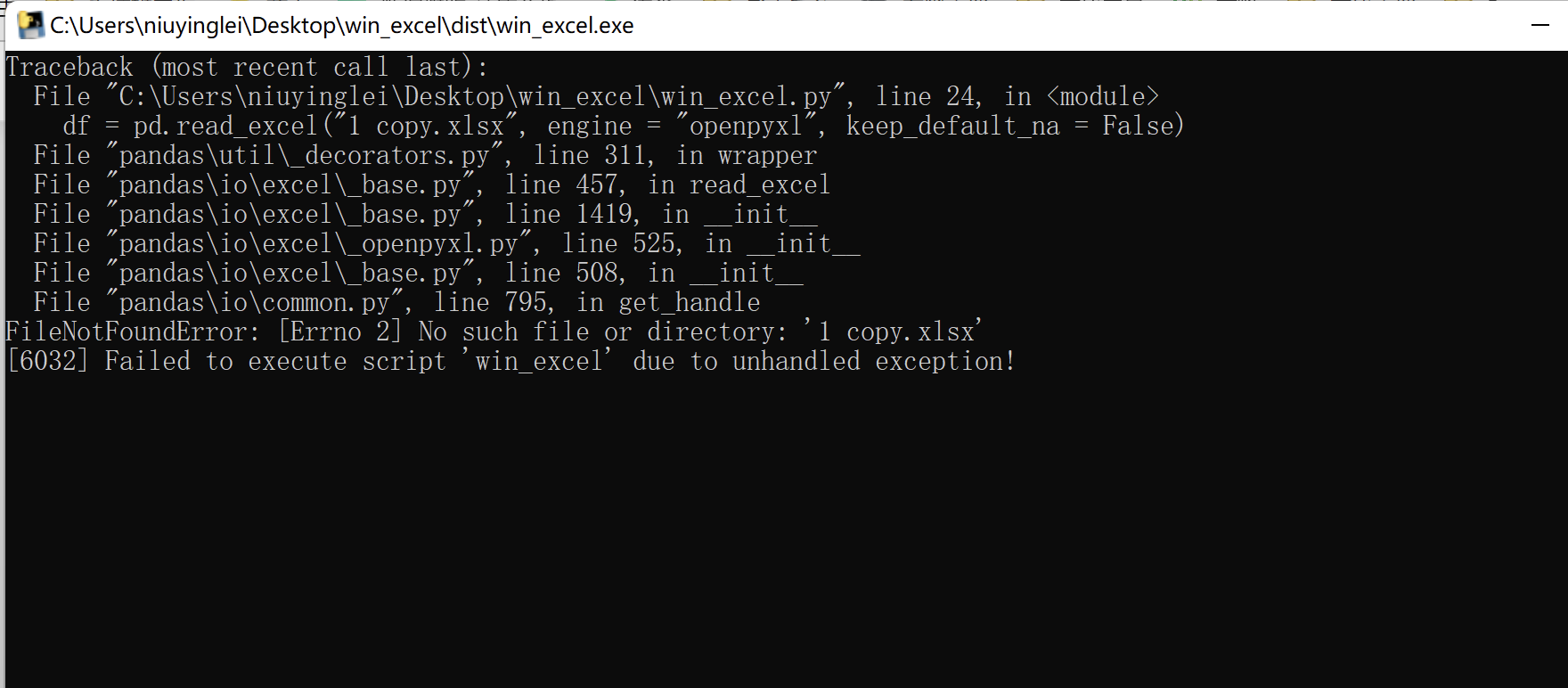
打包后的路径问题 避免打包后不能使用或放到其他机器上不能使用
参考:
背景知识: 如果python 文件打包成了exe文件,那么sys.executable将显示为被执行exe路径,此外sys会多出frozen属性
os.path.abspath()作用:显示当前绝对路径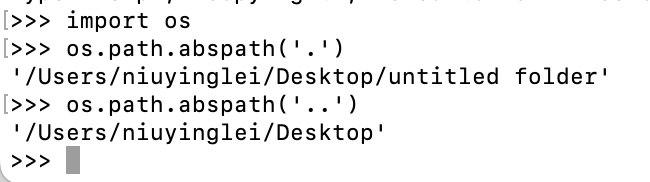
os.path.dirname()作用:去掉文件名,返回路径
os.path.join()作用:连接两个或多个路径名组建- 如果有一个路径是绝对路径,那么在它之前的路径会被舍弃:

打包路径问题的解决办法:
已解决
用上述方法解决路径问题后,打包后运行成功!!!!
将需要处理的文件命名为1 copy.xlsx放在exe同级文件夹,输出文件也在同级文件夹内;
且,-F模式下的打包exe,除了exe外的其他内容均可直接删除,只留exe即可pyinstaller打包参数参考:

若有收获,就点个赞吧
0 人点赞
