- 21python并发编程之Futures
- 20 python 的协程
- async修饰词用于声明异步函数
- await同步调用
- async def main(urls):
- for url in urls:
- await crawl_page(url)
- 使用task实现异步调用
- for task in tasks:
- await task
- 18 拓展内容 看不懂
- 17 装饰器
- 16 python的参数传递
- 15 python对象的比较、拷贝
- 14 答疑
- 13 python的模块化
- 12 面向对象(下)
- 刚看完c再来看python “代码真的易懂很多啊…”
- python函数的参数可以设置默认值
- 嵌套可以保护数据,提升运行效率
- 闭包,外部函数返回的是一个函数
21python并发编程之Futures
线程与进程
concurrent.futures.ThreadPoolExecutor(max_workers = 5)用于创建总线程数为5的线程池concurrent.futures.ProcessPoolExecutor(workers)用于创建进程池
区别并发与并行
并发:某一具体时刻,只有一个线程/任务在运行,线程/任务之间会不断切换,直至完成;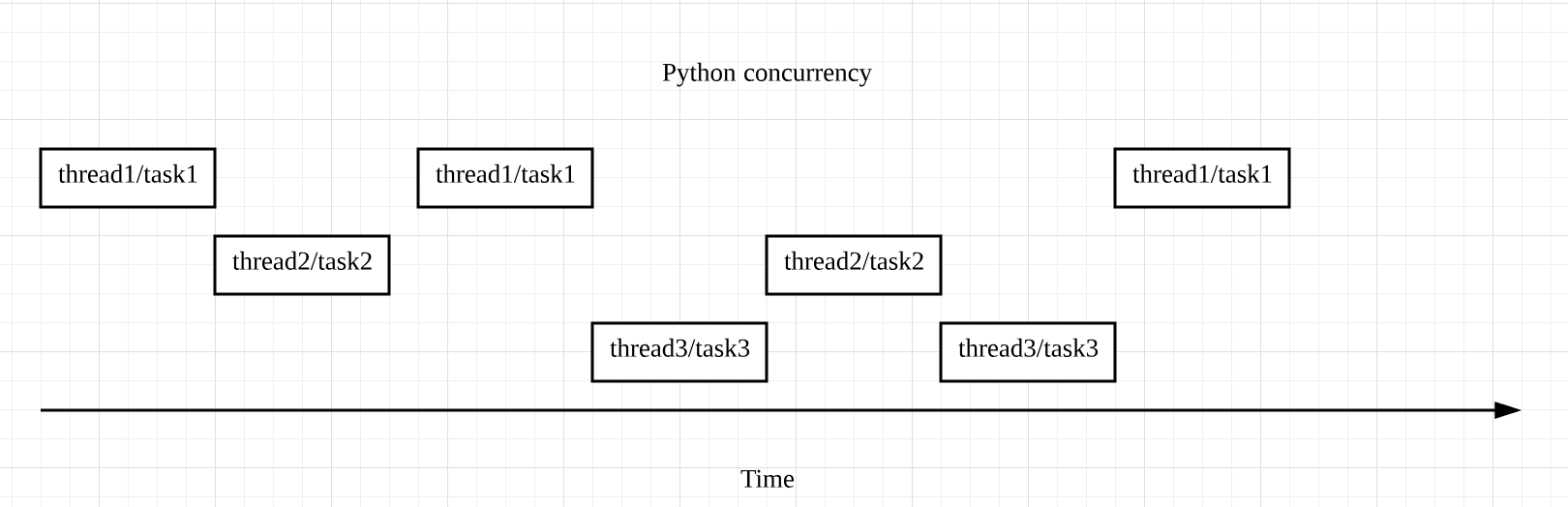
并行:多个任务,同时发生,同时运行
import requestsimport concurrent.futuresimport timedef download_one(url):resp = requests.get(url)print('read {} from {}'.format(len(resp.content), url))def download_all(sites):with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:to_do = []for site in sites:future = executor.submit(download_one, site) # executor.submit(func)会安排func执行,所以download是在这一步进行的?并返回future实例to_do.append(future)for future in concurrent.futures.as_completed(to_do): # as_completed(fs)会根据给定的future迭代器fs,在其完成后,返回完成后的迭代器future.result() # result()当future完成后,返回对应的结果或异常def main():sites = ['https://www.baidu.com/','https://www.kaochong.com/',]start_time = time.perf_counter()download_all(sites)end_time = time.perf_counter()print('download {} sites in {} seconds'.format(len(sites), end_time - start_time))if __name__ == '__main__':main()
Future、asyncio、多线程有什么区别?
asyncio即异步(Async),单线程异步,不同操作间可以交替执行,如果某个操作被block了,程序不会等待,而是找到可执行操作继续执行;async工作原理:- 只有一个主线程,
- 但是可以进行不同的任务(task);这里的任务,就是特殊的future对象?
- 被一个叫做
event loop的对象所控制, - 简化理解,任务分为两种状态:预备状态和等待状态
- 预备:任务目前空闲,随时待命准备运行
- 等待:任务已经运行,但在等待外部操作完成
event loop会维护两个列表,分别对应两种状态;event loop选取预备状态的一个任务使其运行,直到任务把控制权交还给event loop为止;- 控制权交还给
event loop时,e…会根据其是否完成,将任务放到预备或等待状态的列表,然后遍历等待状态列表里的任务,查看他们是否完成; - 如果完成,就放到预备状态列表
- 如果未完成,就放到等待状态列表
- 这样,当所有任务被放到合适的列表里后,新一轮的循环又开始了;
Asyncio用法
async和await关键字,表示这个语句/函数是non-block(非阻塞)的- 先定义download_one
- 在定义download_all
- 再在main函数里调用
asyncio.run20 python 的协程
await的作用是什么?有疑问
课程代码: ```python
import asyncio
async修饰词用于声明异步函数
async def crawlpage(url): print(‘crawling{}’.format(url)) sleep_time = int(url.split(‘‘)[-1]) await asyncio.sleep(sleep_time) print(‘OK {}’.format(url))
await同步调用
async def main(urls):
for url in urls:
await crawl_page(url)
# 调用异步函数 得到的是协程对象,并不会真的执行这个函数# await print(crawl_page(''))
使用task实现异步调用
async def main(urls): tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
for task in tasks:
await task
# 有了协程对象后,便可以通过asyncio.create_task来创建任务,任务创建后很快就会被调度执行,代码不会阻塞在任务里,所以,需要等所有的任务都结束才行,用for循环即可(await是用来等任务结束的?)
asyncio.run(main([‘url_1’, ‘url_2’, ‘url_3’, ‘url_4’]))
‘’’ 执行协程的常见3种方法:
- 通过await来调用;效果和正常执行相同,程序会阻塞在await的位置 进入被调用的函数,执行完毕返回后再继续 await是同步调用,在craw_page(url)在当前的调用结束之前,是不会触发下一次调用的
- 通过asyncio.creat_task()来创建任务
- 需要asyncio.run来触发运行
‘’’
```
把22、23行注释掉后,输出的内容是这样的:

不注释,输出的内容是这样的:
分析异步的流程:
import asyncioasync def worker_1():print('worker_1 start')await asyncio.sleep(1)print('worker_1 done')async def worker_2():print('worker_2 start')await asyncio.sleep(2)print('worker_2 done')# # 常规运行# async def main():# print('before await')# await worker_1()# print('awaited worker_1')# await worker_2()# print('awaited worker_2')# 异步async def main():task1 = asyncio.create_task(worker_1())task2 = asyncio.create_task(worker_2())print('before await')await task1print('awaited worker_1')await task2print('awaited worker_2')asyncio.run(main())
asyncio.run(main())开始运行程序task1、task2创建两个任务,等待被调用await task1被执行时,用户选择从当前的主程序中切出,事件调度器开始调度worker_1();worker_1运行到await asyncio.sleep(1)从当前事件切出,事件调度器开始调度worker_2();
1秒钟后,work_1的sleep完成,事件调度器将控制权重新传给task1,输出worker_1 done,task1完成,从事件循环中退出await task1完成后,事件调度器将控制器传输给主任务,print('awaited task1')
2秒钟后,work_2的sleep完成,事件调度器将控制权重新给task2,输出worker_2 done,task2完成任务,从事件循环中退出
主任务输出awaited worker_2,协程任务全部结束,事件循环结束
自己总结:
await好像只能放在异步函数或asyncio自带的功能之前- 使用
asyncio.run()来触发运行异步函数 使用
asyncio.creat_task()可以从协程对象创建任务坑1:直接
requests.get(),发现获取的内容为0;可能是没有添加headers被网站认为是非法请求;→加上headers,这里没有用自己的浏览器的headers,复制了菜鸟的headers;获取内容成功;- 坑2:
get获得的内容是什么?<class 'requests.models.Response'>get的结果的字节形式为requests.get().content
beautifulsoup接收的是什么内容?
安装aiohttp
原文中的可运行代码
import asyncioimport aiohttpfrom bs4 import BeautifulSoupheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}async def fetch_content(url):async with aiohttp.ClientSession(headers = headers, connector = aiohttp.TCPConnector(ssl = False) )as session:async with session.get(url) as response:return await response.text()async def main():url = "https://movie.douban.com/cinema/later/beijing/"init_page = await fetch_content(url)init_soup = BeautifulSoup(init_page, 'lxml')movie_names, urls_to_fetch, movies_dates = [], [], []all_movies = init_soup.find('div', id = 'showing-soon')for each_movie in all_movies.find_all('div', class_ = 'item'):all_a_tag = each_movie.find_all('a')all_li_tag = each_movie.find_all('li')movie_names.append(all_a_tag[1].text)urls_to_fetch.append(all_a_tag[1]['href'])movies_dates.append(all_li_tag[0].text)tasks = [fetch_content(url) for url in urls_to_fetch]pages = await asyncio.gather(*tasks)for movie_name, movie_date, page in zip(movie_names, movies_dates, pages):soup_item = BeautifulSoup(page, 'lxml')img_tag = soup_item.find('img')print('{} {} {}\n'.format(movie_name, movie_date, img_tag['src']))asyncio.run(main())
实现输出到excel
- 参考:
- 安装库
openpyxl 
- 需要安装excel吗?好像不需要,只安装了wps可以使用
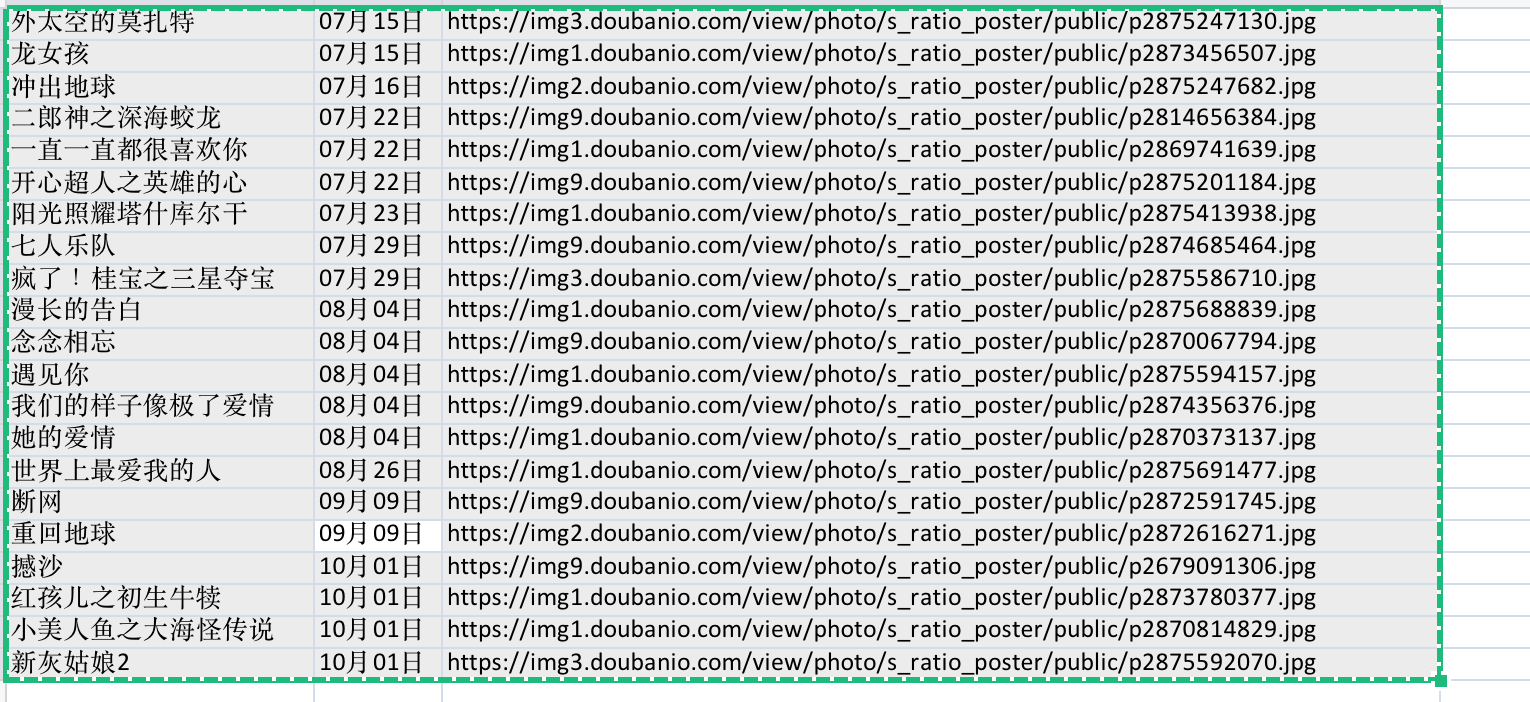
- 成功了 !!!!
 ```python
import asyncio
import aiohttp
```python
import asyncio
import aiohttp
from bs4 import BeautifulSoup from openpyxl import Workbook
async def fetch_content(url): headers = {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”} async with aiohttp.ClientSession(headers = headers, connector = aiohttp.TCPConnector(ssl = False) )as session: async with session.get(url) as response: return await response.text()
async def main(): url = “https://movie.douban.com/cinema/later/beijing/“ init_page = await fetch_content(url) init_soup = BeautifulSoup(init_page, ‘lxml’)
movie_names, urls_to_fetch, movies_dates = [], [], []all_movies = init_soup.find('div', id = 'showing-soon')for each_movie in all_movies.find_all('div', class_ = 'item'):all_a_tag = each_movie.find_all('a')all_li_tag = each_movie.find_all('li')movie_names.append(all_a_tag[1].text)urls_to_fetch.append(all_a_tag[1]['href'])movies_dates.append(all_li_tag[0].text)tasks = [fetch_content(url) for url in urls_to_fetch]pages = await asyncio.gather(*tasks)wb = Workbook()sheet = wb.activesheet.title = 'new sheet'i = 1for movie_name, movie_date, page in zip(movie_names, movies_dates, pages):soup_item = BeautifulSoup(page, 'lxml')img_tag = soup_item.find('img')print('{} {} {}'.format(movie_name, movie_date, img_tag['src']))sheet['A%d' % i] = movie_namesheet['B%d' % i] = movie_datesheet['C%d' % i] = img_tag['src']i += 1wb.save('豆瓣.xlsx')
asyncio.run(main())
<a name="KWU8P"></a>#### 访问次数过多会被反爬虫爬不到内容后会出现如下错误:`'NoneType' object has no attribute 'find_all'`<a name="Q4VkP"></a>### 19 迭代器和生成器**在python中,一切皆是对象,对象的抽象是类,对象的集合就是容器**- 所有的**容器都是可迭代的**- 容器可以使用`iter()`函数获得一个迭代器,迭代器可以通过`next()`函数来得到下一个元素,从而支持遍历;- 在调用next()方法后,要么获得迭代器的下一个对象,要么获得StopIterarion的错误- 生成器是一种特殊的迭代器,使用生成器能写出更简洁清晰地代码- 生成器在python2.*上是协程的一种重要实现方式,但python3引入了async await语法糖后,生成器实现协程的方式就落后了<a name="Ix4Jc"></a>#### 生成器的语法用小括号括起来:- `(i for i in range(100))`是生成器- `[i for i in range(100)]`是一个包含100个元素的列表<a name="ZoThC"></a>#### 用生成器判断子序列```pythondef is_subsequence(a, b):b = iter(b) # 把列表b转化为了一个迭代器return all(i in b for i in a) # 通俗解释:对于a里的每个i,检查i是否在b里print(is_subsequence([1, 2], [1, 3, 2, 4, 5]))print(is_subsequence([2, 1], [1, 3, 2, 4, 5]))# 输出# True# False
def is_subsequence(a, b):b = iter(b)print(b) # 输出:<list_iterator object at 0x7fc628835250> 说明创建了一个列表生成器gen = (i for i in a)print(gen) # 输出:<generator object is_subsequence.<locals>.<genexpr> at 0x7fc626085150> 利用小括号创建了一个生成器for i in gen:print(i) # 输出:1\n 3\n 5\ngen = ((i in b) for i in a) # 小括号里的in是判断,外面括号里的in是生成器print(gen) # 输出:<generator object is_subsequence.<locals>.<genexpr> at 0x7fc6266551d0>for i in gen: # 遍历上面的生成器,此时生成器的每一次迭代内容都是基于(i in b)的判断,即输出的是布尔值print(i) # 输出: True True True False (此处省略了换行)return all(((i in b) for i in a)) # 因为上面的for循环已经将生成器迭代完了,所以此时如果写 return all(gen) 会因为遇到StopIteration而报错,所以又初始化了一个生成器,和gen相同,从头开始遍历print(is_subsequence([1, 3, 5], [1, 2, 3, 4, 5]))print(is_subsequence([1, 4, 3], [1, 2, 3, 4, 5]))
思考题:
对于一个有限元素的生成器,迭代完成后,继续调用next()函数会发生什么?生成器可以迭代多次吗?

18 拓展内容 看不懂
17 装饰器
16 python的参数传递
如何理解python的参数传递是赋值传递,或者叫做_对象的引用传递_;
课程的讲解方式不好理解,这个更容易理解一些
def my_func1(b):b = 2a = 1my_func1(a)print('a = {}'.format(a)) # 输出 a = 1# 调用将 a = 1 作为参数传递给my_func1()的时候,传递的是对“对象1”的引用,即调用后,b指向了“对象1”# 进入函数后,b = 2,又建立了 b 对“对象2”的引用,而此时的a仍旧指向“对象1”# 函数结束后,打印a,因为a指向“对象1”,所以打印的结果是 a = 1
当可变对象作为参数传递进函数时,改变可变对象的值,就会影响所有指向他们的变量
比如:
def my_func1(l1):l1.append(4)l2 = [1, 2, 3]l3 = l2my_func1(l2)print('l2 = {}\nl3 = {}'.format(l2, l3))'''输出l2 = [1, 2, 3, 4]l3 = [1, 2, 3, 4]'''
因为列表是可变对象,因此指向同一列表的l2和l3同时被改变了
但也不是所有针对可变列表的行为,都会影响引用其的其他变量:
def my_func1(l1):l1 = l1 + [4]l2 = [1, 2, 3]my_func1(l2)print('l2 = {}'.format(l2))'''输出 l2 = [1, 2, 3]'''
在上述例子中,l1 = l1 + [4]相当让l1指向了+ [4]后的新列表对象,而原来的l2仍旧指向旧列表对象
如果想改变l2的值,需要在函数中加上return语句,将引用返回
def my_func1(l1):l1 = l1 + [4]return l1l2 = [1, 2, 3]l2 = my_func1(l2)print('l2 = {}'.format(l2))'''输出 l2 = [1, 2, 3, 4]'''
总结:
- 如果对象是可变的,当对象改变是,所有指向该对象的变量都会改变
- 如果对象是不可变的,简单的赋值只能改变其中一个变量的值,其余的变量不受影响
- 因此当你想通过一个函数来改变某个变量的值,通常有两种方法:
- 将可变的数据类型作为参数传入,并在其上直接进行更改(列表、字典、集合)
- 创建一个新的变量,用来保存修改后的值,并将其返回给原来的变量
思考题:
# 下列的l1, l2, l3指的是同一个列表吗l1 = [1, 2, 3, 4]l2 = [1, 2, 3, 4]l3 = l2# 答:l1, l2不是同一个,l2, l3 是同一个
# 预测输出结果def func(d):d['a'] = 10d['b'] = 20d = {'a': 1, 'b': 2}func(d)print(d)# 答:输出结果是{'a': 10, 'b': 20}# 3,4行的语句,相当于对可变对象字典的修改,而第5行则创建了一个新的局部变量d,并让其指向新字典# 因此输出的是改变之后的旧字典{'a': 1, 'b': 2}
15 python对象的比较、拷贝
==会递归的比较两个对象中的每个元素is会直接对比两个对象的ID;因此is的效率高于==浅拷贝后的对象中的元素,是对原对象中,子对象的引用,因此如果源对象中的元素是可变的,改变后也会影响浅拷贝后的对象,有一定的副作用深拷贝会递归的拷贝源对象中的每一个子对象,因此拷贝后的对象和源对象互不关联;另外,深拷贝会维护一个字典,记录已经拷贝的对象和对应的ID,来提高效率并防止无限递归的发生;14 答疑
13 python的模块化
在环境变量李添加项目根目录,以确保python在调用时能找到相应的模块
if __name__ == '__main__'的作用原理12 面向对象(下)
实现自己的搜索引擎
搜索引擎的四个组成部分:
搜索器 在互联网上爬虫
- 索引器 搜索引擎形成自己的索引
- 检索器 在自己的索引内搜索用户想要的内容
- 用户界面 app和网页前端页面
倒序索引的搜索算法没看懂没看懂
```c
import re
class BOWInvertedIndexEngine(SearchEngineBase): def init(self): super(BOWInvertedIndexEngine, self).init() self.inverted_index = {}
def process_corpus(self, id, text):words = self.parse_text_to_words(text)for word in words:if word not in self.inverted_index:self.inverted_index[word] = []self.inverted_index[word].append(id)def search(self, query):query_words = list(self.parse_text_to_words(query))query_words_index = list()for query_word in query_words:query_words_index.append(0)# 如果某一个查询单词的倒序索引为空,我们就立刻返回for query_word in query_words:if query_word not in self.inverted_index:return []result = []while True:# 首先,获得当前状态下所有倒序索引的 indexcurrent_ids = []for idx, query_word in enumerate(query_words):current_index = query_words_index[idx]current_inverted_list = self.inverted_index[query_word]# 已经遍历到了某一个倒序索引的末尾,结束 searchif current_index >= len(current_inverted_list):return resultcurrent_ids.append(current_inverted_list[current_index])# 然后,如果 current_ids 的所有元素都一样,那么表明这个单词在这个元素对应的文档中都出现了if all(x == current_ids[0] for x in current_ids):result.append(current_ids[0])query_words_index = [x + 1 for x in query_words_index]continue# 如果不是,我们就把最小的元素加一min_val = min(current_ids)min_val_pos = current_ids.index(min_val)query_words_index[min_val_pos] += 1@staticmethoddef parse_text_to_words(text):# 使用正则表达式去除标点符号和换行符text = re.sub(r'[^\w ]', ' ', text)# 转为小写text = text.lower()# 生成所有单词的列表word_list = text.split(' ')# 去除空白单词word_list = filter(None, word_list)# 返回单词的 setreturn set(word_list)
search_engine = BOWInvertedIndexEngine() main(search_engine)
#### 输出
little found 2 result(s): 1.txt 2.txt little vicious found 1 result(s): 2.txt
<a name="xEkTe"></a>#### 评论区一个解法的注释<br /><a name="LzVqG"></a>### 11 面向对象(上)<a name="QpOg8"></a>#### 类的三种函数- 成员函数 第一个参数是`self`,代表对当前对象的引用- 类函数 第一个参数一般为`cls`,即传入一个类,类函数的常用功能是实现不同的init构造函数 `@classmethod`- 静态函数 用来做简单独立的任务,特点是不会影响对象本身的属性 `@staticmethod`<a name="YpCKE"></a>#### 抽象类与抽象函数本身不能实例化,会报错,天生作为父类存在;<br />抽象函数定义在抽象类中,不能直接使用,必须在子类中重写才可以使用;<br />抽象类的作用:用少量的代码描述清楚将要做的事情,定义好接口,然后交给不同的开发人员去开发<a name="eKq96"></a>#### 面向对象编程的四要素类、属性、函数、对象:<br />类是一群具有相同属性和函数的对象的集合;<a name="Bmgf1"></a>### 10 lambda函数(匿名函数)<a name="QLvfS"></a>### 09 函数<a name="Ba5al"></a>#### def是可执行语句:和c不一样,python的函数定义语句`def`是`可执行语句`,意味着在函数调用之前,都是不存在的,在函数被调用的时候,def才会创建一个新的函数对象,并赋予其名字;<a name="HfUGx"></a>#### python的“多态”:python函数不需要考虑输入类型,而是交给代码去判断;对于下面的函数:如果是两个整型,就按规则相加;如果是两个字符串,就将其拼接;```cdef my_sum(a, b):return a + bprint(my_sum(1, 2)) # 输出3print(my_sum('geek', 'bang')) # 输出geekbang
刚看完c再来看python “代码真的易懂很多啊…”
python函数的参数可以设置默认值
嵌套可以保护数据,提升运行效率
闭包,外部函数返回的是一个函数
合理使用闭包,可以简化程序,提升可读性

若有收获,就点个赞吧
0 人点赞
