主从复制
介绍
主机数据更新后根据配置和策略,自动同步到备机的matser/slave机制,Master以写为主,slave以读为主。
特点
- 读写分离,性能扩展
- 容灾快速恢复
主从复制原理
1.slave启动成功连接到master后,会向matser发送sync命令
2.matser接收到命令后触发一次rdb持久化,等待存储完成后,master会传送整个数据文件到slave,以完成一次完全同步。
3.后续每次master接收到修改数据集的命令都会增量同步给slave,以保证数据一致
如何快速搭建(一主两从)
1.创建文件夹mkdir -p /tools/redis/etcmkdir -p /tools/redis/binmkdir -p /tools/redis/logs2.复制redis.conf配置文件到文件夹中cp /tools/redis/redis.conf /tools/redis/etc3.修改redis.conf文件protected-mode nodaemonize yesbind 0.0.0.0#如果aof开启的话,需要更换文件名称,默认为关闭状态3.配置一主两从的配置文件# redis6379.confinclude /tools/redis/etc/redis.confport 6379pidfile /var/run/redis_6379.pidlogfile /tools/redis/logs/redis_6379.logdbfilename dump6379.rdb# redis6380.confinclude /tools/redis/etc/redis.confport 6380pidfile /var/run/redis_6380.pidlogfile /tools/redis/logs/redis_6380.logdbfilename dump6380.rdb# redis6381.confinclude /tools/redis/etc/redis.confport 6381pidfile /var/run/redis_6381.pidlogfile /tools/redis/logs/redis_6381.logdbfilename dump6381.rdb4.启动服务cd /tools/redis/etc/tools/redis/bin/redis-server redis-6379.conf/tools/redis/bin/redis-server redis-6380.conf/tools/redis/bin/redis-server redis-6381.conf5.配置主从关系#从机执行slaveof host port命令/tools/redis/bin/redis-cli -p 6380slaveof 192.168.72.10 6379/tools/redis/bin/redis-cli -p 6381slaveof 192.168.72.10 63796.主机查看状态/tools/redis/bin/redis-cli -p 6379info replication
常用三种类型
一主两仆
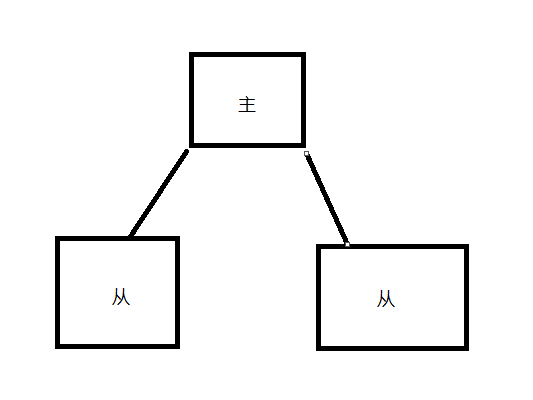
1.主机宕机后,从机不会改变slave身份,等主机恢复后还是master
2.从机宕机后,会断开主从连接,等从机恢复后变为独立服务,需要重新进行主从关联。主从重新关联后从机会全量复制主机的数据保障主从数据一致。
薪火相传
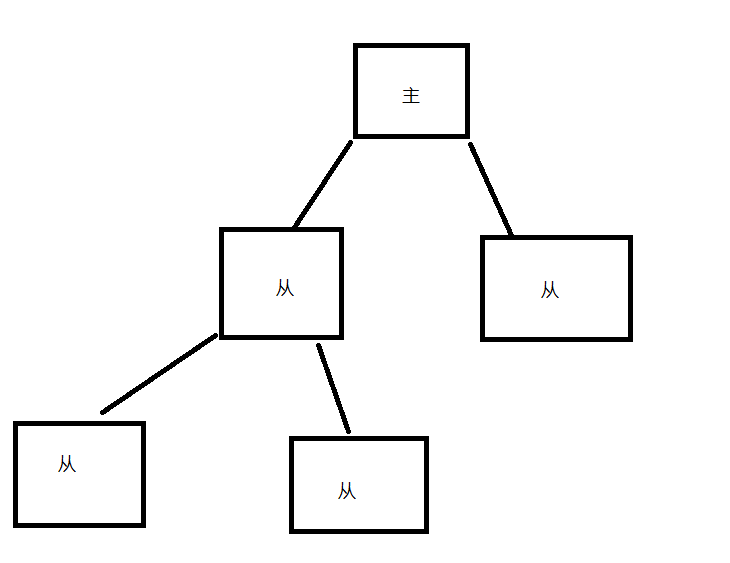
如图所示,一个主管理两个从(一层从),从(一层从)自身也可作为一个主再去管理两个从(二层从,该从与主无直接关联,只与一层从有直接关系)
设置方法只需要通过slaveof ip port命令将主指向一层从就可以配置成功
1.主机宕机后,从机不会改变slave身份,等主机恢复后还是master
2.从机宕机后,会断开主从连接,等从机恢复后变为独立服务,需要重新进行主从关联。主从重新关联后从机会全量复制主机的数据保障主从数据一致。
反客为主(哨兵模式)
顾名思义,正常情况下主从关系不会改变,该模式下从会转变身份为主
通过slaveof no one命令可将从机变为主机,但是该命令需要手动执行不方便,后来演绎为哨兵模式(自动版反客为主)
哨兵模式
哨兵模式原理
1.当主机故障后,在主机所属从机里选择一个从服务将其转换为主服务
选举的条件依次为:
1)选择优先级靠前的从服务
优先级在redis.conf中的配置为:replica-priority 100,默认为100.值越小优先级越高。
2)选择偏移量大的从服务
偏移量是指获得原主机数据最全的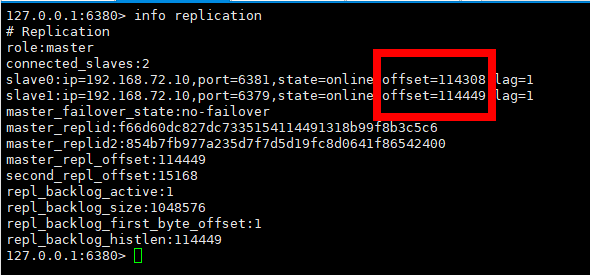
3)选择runid最小的从服务
每个redis实例启动都会随机生成一个40为的runid
2.挑选出新的主服务后,sentinel向该服务器发送slaveof命令,让其成为新主服务
2.故障主机回复后,sentinel会向该服务器发送slaveof命令,让其成为新主从服务
哨兵模式通讯原理
所有的哨兵,都在监控master,哨兵可以从master中取出从的信息,并通过发布订阅,来发现其他哨兵。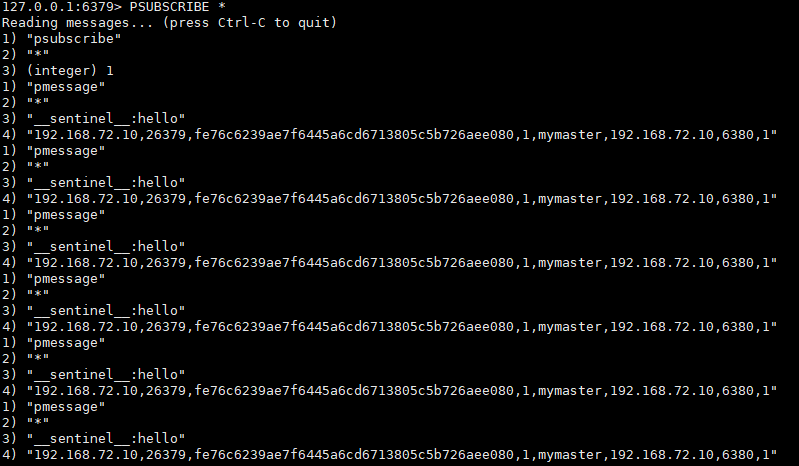
哨兵集群搭建
1.首先根据主从复制的步骤进行redis主从搭建
2.根据如下步骤进行哨兵服务启动
1.创建sentinel.conf(该文件名字固定不可更改),并配置哨兵信息vim /tools/redis/etc/sentinel.conf#以下表示为哨兵监控服务#mymaster为监控对象服务别名#192.168.72.10 6379 为服务的ip和端口#数字1为至少有多少个哨兵同意迁移的数量sentinel monitor mymaster 192.168.72.10 6379 12.启动哨兵服务cd /tools/redis/etc/tools/redis/bin/redis-sentinel sentinel.conf
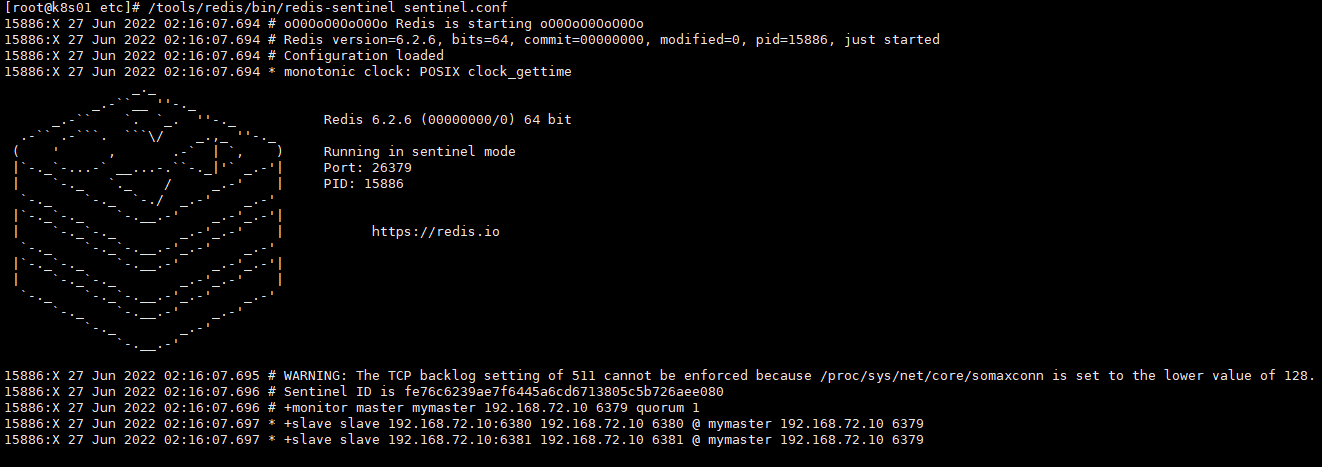
代码如何确定主服务
代码中通过连接sentinel服务(端口:26379),来确定主服务的正确地址。
如java中使用:JedisSentinelPool
缺点
复制延时
由于所有的写操作都在matser上进行操作,然后同步更新到slave上,所以从Master同步到slave机器有一定的延时,当系统很繁忙时,延迟问题会加重,slave机器的数量增加也会使延迟问题家中。
集群(Cluster)
介绍
redis集群实现了对redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点上,每个节点存储总数据的1/N。
redis集群通过分区来提供一定程度的可用性,即是集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
无中心化集群,无论连接那台主机进行读写,都会转发请求到对应节点
集群搭建
注意:
一个集群至少要有3个主节点
分配原则尽量保障每个主库都在不同的IP上,主节点和从节点不要在同一主机上
1.准备配置文件vim /tools/redis/cluster/redis-6379.confinclude /tools/redis/etc/redis.confport 6379pidfile "/var/run/redis_6379.pid"logfile "/tools/redis/logs/redis_6379.log"dbfilename "dump6379.rdb"cluster-enabled yescluster-config-file node-6379.confcluster-node-timeout 150002.复制多份配置,并修改配置cp /tools/redis/cluster/redis-6379.conf /tools/redis/cluster/redis-6380.confcp /tools/redis/cluster/redis-6379.conf /tools/redis/cluster/redis-6381.confcp /tools/redis/cluster/redis-6379.conf /tools/redis/cluster/redis-6389.confcp /tools/redis/cluster/redis-6379.conf /tools/redis/cluster/redis-6390.confcp /tools/redis/cluster/redis-6379.conf /tools/redis/cluster/redis-6391.confsed -i 's/6379/6380/g' /tools/redis/cluster/redis-6380.confsed -i 's/6379/6381/g' /tools/redis/cluster/redis-6381.confsed -i 's/6379/6389/g' /tools/redis/cluster/redis-6389.confsed -i 's/6379/6390/g' /tools/redis/cluster/redis-6390.confsed -i 's/6379/6391/g' /tools/redis/cluster/redis-6391.conf3.启动服务cd /tools/redis/cluster//tools/redis/bin/redis-server redis-6379.conf/tools/redis/bin/redis-server redis-6380.conf/tools/redis/bin/redis-server redis-6381.conf/tools/redis/bin/redis-server redis-6389.conf/tools/redis/bin/redis-server redis-6390.conf/tools/redis/bin/redis-server redis-6391.conf4.组建集群(确认已生成node-xxx.conf)#--cluster-replicas 1 表示为每个主节点创建并分配一个从服务/tools/redis/bin/redis-cli --cluster create --cluster-replicas 1 192.168.72.10:6379 192.168.72.10:6380 192.168.72.10:6381 192.168.72.10:6389 192.168.72.10:6390 192.168.72.10:63915.集群连接(加上-c命令表示集群连接)/tools/redis/bin/redis-cli -c -p 63796.查看集群状态cluster nodes
组建信息如下:
[WARNING] Some slaves are in the same host as their master
提示说明主服务与从服务在同一台主机,可以忽略,生产一般不再同一主机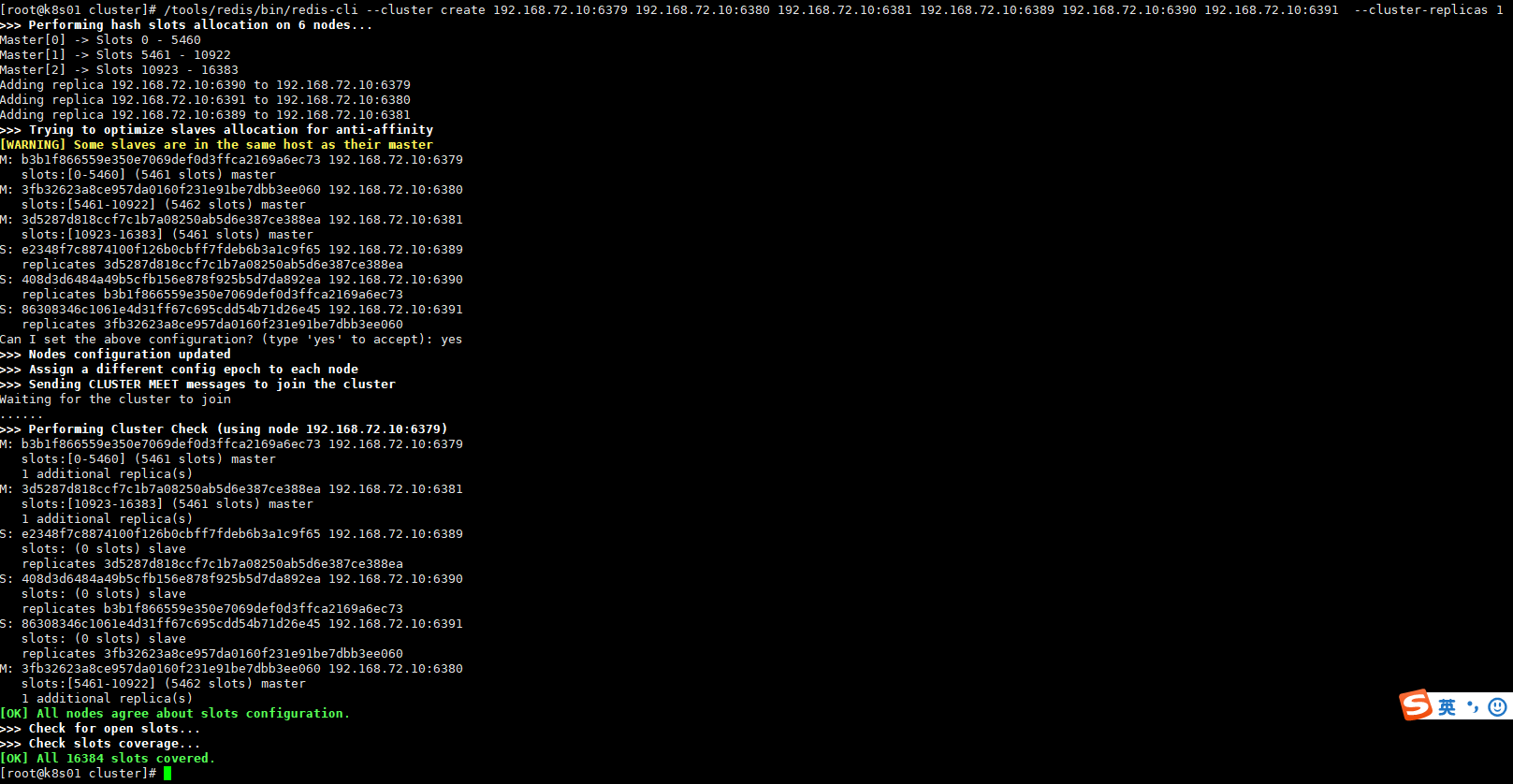
集群常用命令
1.查看集群信息
cluster nodes
2.计算key的slot号
cluster keyslot key
3.计算slot中key的数量(该命令需要在插槽对应的节点执行才可查看出插槽内key的数量,否者显示值为0)
cluster countkeysinslot 4184
4.返回插槽中指定数量的key,下方为返回插槽中10个key
cluster getkeysinslot 4184 10
5.查看slot的信息
cluster slots
6.查看当前节点中key的数量
info keyspace
什么是slots
一个redis集群包含16384个插槽(hash slot),数据库中个每个健都属于插槽中的一个。
集群使用公式CRC16(key)%16384(redis 先对 key(有效值)使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点)来计算key属于哪个槽。
集群的每个主节点负责处理一段插槽,举个例子,如果一个集群三个主节点,其中:
节点A负责处理0至5460号插槽
节点B负责处理5461至10922号插槽
节点C负责处理10923至16383号插槽
集群录入值
由于redis集群会根据key计算出对应的插槽然后存入数据,当我们使用批量插入是会出现插入失败的问题(因为多个key无法进行hast计算出相同的slot),这个时候我们可以通过加入tag(标签分组)进行解决,在插入的key加入{tag},这样对key计算hash值计算时知只会使用花括号里的内用进行计算。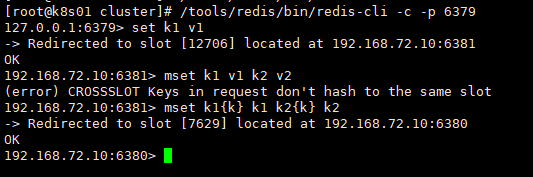
tag使用注意事项
- 当只有一个{..}时,使用花括号里的内容进行hash计算,当{}为空时使用整个key进行hash计算
- 当存在多个{..}时,从左往右使用第一个花括号里的内容进行hash计算,当第一个花括号为空时使用整个key进行hash计算
集群故障恢复
- 当某一段插槽的主机故障后,其从机会自动升为主机,当原主节点恢复后,会自动转为新主机的从机。
- 当某一段插槽的主从机都故障后,如果cluster-require-full-coverage参数为yes则整机集群挂掉,如果cluster-require-full-coverage的参数为no则该插槽数据全部不能使用,也无法存储,但集群运行正常。(cluster-require-full-coverage参数默认配置为yes)
优点
缺点
多键操作不被支持(需要结合tag),多键的redis事务不被支持,lua脚本不被支持
由于集群方案出现的比较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至集群,需要整体迁移而不是逐步过渡,复杂度大。

若有收获,就点个赞吧
0 人点赞
