- RDB(快照)
- Save the DB to disk.
- save
- Redis will save the DB if both the given number of seconds and the given
- number of write operations against the DB occurred.
- Snapshotting can be completely disabled with a single empty string argument
- as in following example:
- save “”
- Unless specified otherwise, by default Redis will save the DB:
- * After 3600 seconds (an hour) if at least 1 key changed
- * After 300 seconds (5 minutes) if at least 100 keys changed
- * After 60 seconds if at least 10000 keys changed
- You can set these explicitly by uncommenting the three following lines.
- save 3600 1
- save 300 100
- save 60 10000
- By default Redis will stop accepting writes if RDB snapshots are enabled
- (at least one save point) and the latest background save failed.
- This will make the user aware (in a hard way) that data is not persisting
- on disk properly, otherwise chances are that no one will notice and some
- disaster will happen.
- If the background saving process will start working again Redis will
- automatically allow writes again.
- However if you have setup your proper monitoring of the Redis server
- and persistence, you may want to disable this feature so that Redis will
- continue to work as usual even if there are problems with disk,
- permissions, and so forth.
- Compress string objects using LZF when dump .rdb databases?
- By default compression is enabled as it’s almost always a win.
- If you want to save some CPU in the saving child set it to ‘no’ but
- the dataset will likely be bigger if you have compressible values or keys.
- Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
- This makes the format more resistant to corruption but there is a performance
- hit to pay (around 10%) when saving and loading RDB files, so you can disable it
- for maximum performances.
- RDB files created with checksum disabled have a checksum of zero that will
- tell the loading code to skip the check.
- Enables or disables full sanitation checks for ziplist and listpack etc when
- loading an RDB or RESTORE payload. This reduces the chances of a assertion or
- crash later on while processing commands.
- Options:
- no - Never perform full sanitation
- yes - Always perform full sanitation
- clients - Perform full sanitation only for user connections.
- Excludes: RDB files, RESTORE commands received from the master
- connection, and client connections which have the
- skip-sanitize-payload ACL flag.
- The default should be ‘clients’ but since it currently affects cluster
- resharding via MIGRATE, it is temporarily set to ‘no’ by default.
- sanitize-dump-payload no
- The filename where to dump the DB
- Remove RDB files used by replication in instances without persistence
- enabled. By default this option is disabled, however there are environments
- where for regulations or other security concerns, RDB files persisted on
- disk by masters in order to feed replicas, or stored on disk by replicas
- in order to load them for the initial synchronization, should be deleted
- ASAP. Note that this option ONLY WORKS in instances that have both AOF
- and RDB persistence disabled, otherwise is completely ignored.
- An alternative (and sometimes better) way to obtain the same effect is
- to use diskless replication on both master and replicas instances. However
- in the case of replicas, diskless is not always an option.
- The working directory.
- The DB will be written inside this directory, with the filename specified
- above using the ‘dbfilename’ configuration directive.
- The Append Only File will also be created inside this directory.
- Note that you must specify a directory here, not a file name.
- 持久化使用建议
redis提供两种持久化方式:
RDB(redis database)默认开启
AOF(append of file)默认不开启
RBD和AOF同时开启时,系统优先读取AOF的数据进行恢复(数据不会存在丢失)
RDB(快照)
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的snapshot快照,它恢复时是将快照文件直接读到内存
备份如何执行
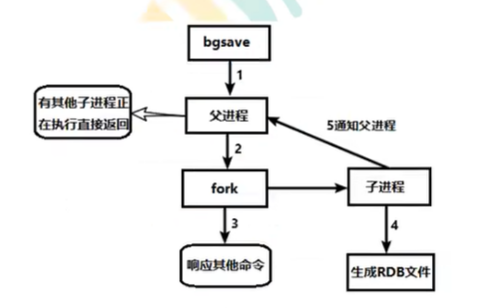
redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的回复,且对于数据恢复的完成性不是非常敏感,那RDB要比AOF方式更加的高校效。RDB的缺点是最后一次持久化的数据可能丢失
Fork
- Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值和原进程一致,但是是一个全新的进程,并作为原进程的子进程
- Fork是linux创建子进程的一个函数,fork()会产生一个和父进程完全相同的子进程。
RDB持久化流程
RDB配置说明
```c########################## SNAPSHOTTING
Save the DB to disk.
#
save
#
Redis will save the DB if both the given number of seconds and the given
number of write operations against the DB occurred.
#
Snapshotting can be completely disabled with a single empty string argument
as in following example:
#
save “”
#
Unless specified otherwise, by default Redis will save the DB:
* After 3600 seconds (an hour) if at least 1 key changed
* After 300 seconds (5 minutes) if at least 100 keys changed
* After 60 seconds if at least 10000 keys changed
#
You can set these explicitly by uncommenting the three following lines.
#
save 3600 1
save 300 100
save 60 10000
By default Redis will stop accepting writes if RDB snapshots are enabled
(at least one save point) and the latest background save failed.
This will make the user aware (in a hard way) that data is not persisting
on disk properly, otherwise chances are that no one will notice and some
disaster will happen.
#
If the background saving process will start working again Redis will
automatically allow writes again.
#
However if you have setup your proper monitoring of the Redis server
and persistence, you may want to disable this feature so that Redis will
continue to work as usual even if there are problems with disk,
permissions, and so forth.
stop-writes-on-bgsave-error yes
Compress string objects using LZF when dump .rdb databases?
By default compression is enabled as it’s almost always a win.
If you want to save some CPU in the saving child set it to ‘no’ but
the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
This makes the format more resistant to corruption but there is a performance
hit to pay (around 10%) when saving and loading RDB files, so you can disable it
for maximum performances.
#
RDB files created with checksum disabled have a checksum of zero that will
tell the loading code to skip the check.
rdbchecksum yes
Enables or disables full sanitation checks for ziplist and listpack etc when
loading an RDB or RESTORE payload. This reduces the chances of a assertion or
crash later on while processing commands.
Options:
no - Never perform full sanitation
yes - Always perform full sanitation
clients - Perform full sanitation only for user connections.
Excludes: RDB files, RESTORE commands received from the master
connection, and client connections which have the
skip-sanitize-payload ACL flag.
The default should be ‘clients’ but since it currently affects cluster
resharding via MIGRATE, it is temporarily set to ‘no’ by default.
#
sanitize-dump-payload no
The filename where to dump the DB
dbfilename dump.rdb
Remove RDB files used by replication in instances without persistence
enabled. By default this option is disabled, however there are environments
where for regulations or other security concerns, RDB files persisted on
disk by masters in order to feed replicas, or stored on disk by replicas
in order to load them for the initial synchronization, should be deleted
ASAP. Note that this option ONLY WORKS in instances that have both AOF
and RDB persistence disabled, otherwise is completely ignored.
#
An alternative (and sometimes better) way to obtain the same effect is
to use diskless replication on both master and replicas instances. However
in the case of replicas, diskless is not always an option.
rdb-del-sync-files no
The working directory.
#
The DB will be written inside this directory, with the filename specified
above using the ‘dbfilename’ configuration directive.
#
The Append Only File will also be created inside this directory.
#
Note that you must specify a directory here, not a file name.
dir ./
**save**:(以下为默认规则)<br />“save 3600 1”表示如果3600 秒(1小时)内至少1个key发生变化(新增、修改和删除),则重写rdb文件;<br />“save 300 100”表示如果每300秒(5分钟)内至少100个key发生变化(新增、修改和删除),则重写rdb文件;<br />“save 60 10000”表示如果每60秒(1分钟)内至少10000个key发生变化(新增、修改和删除),则重写rdb文件。<br />不设置save指令,或者给save传入空字符串会禁用。<br />**stop-writes-on-bgsave-error**:如果您已经设置了对Redis服务器和持久性的正确监视,则可能需要禁用此功能,以便即使在磁盘、权限等方面出现问题时,Redis仍能正常工作。默认yes,yes表示出现bgsaave出现问题时停止写操作,no为不禁止。<br />**rdbcompression**:对存储到磁盘中的快照,可以设置是否进行压缩存储,如果是,redis会采用LZF算法进行压缩<br />如果不想消耗CPU来进行压缩的话,可以关闭该选项,但会导致数据库文件变的巨大推荐yes<br />**rdbchecksum**:在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取最大性能提升,可以关闭此功能,推荐yes<br />**dbfilename**:执行rdb文件名<br />**rdb-del-sync-files**:在未启用持久化的实例中删除复制使用的RBD文件<br />**dir**:默认为启动命令执行所在目录。指定rdb文件存放目录,同时aof文件路径也通过其指定<a name="WdOxL"></a>## 数据恢复保证dump.rdb文件与配置中指定的位置一致,然后重启redis后系统会自动读取dump.rdb文件中的数据<br />若rdb文件损坏可用如下命令进行修复<br />redis-check-rdb dump.rdb<a name="EwRf1"></a>## 优势1.RDB是一个非常紧凑的文件,他可以保存某个时间点的数据集,可以定时传送至其他地方备份,非常适合数据恢复和备份<br />2.在恢复大规模数据时,RDB会比AOF速度更快<a name="CxvoY"></a>## 劣势1.只适合数据完整性要求不高的场景,因为如果redis突然down就会丢失最后一次快照后面修改的数据<br />2..fork的时候,内存中的数据被克隆,需要考虑内存两倍的膨胀性,并且数据量大的场景下会消耗性能<a name="rDCba"></a>## 有那些情况会触发RDB(RDB开启情况下)1.使用shutdown命令正常关闭<br />2.使用kill pid进行关闭,kill -9不会触发<br />3.触发save(主程序持久化,会导致阻塞)或bgsave(fork子进程进行持久化不会阻塞)<br />4.进行主从复制时会进行持久化然后复制rdb文件<br />5.执行dubug reload命令<a name="fyJTN"></a># AOF(文件追加)以日志的形式来记录每个写操作(增量保存),将redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次完成数据的恢复工作。<a name="Houdy"></a>## AOF持久化流程1.客户端的请求写命令会被append追加到AOF缓冲区内<br />2.AOF缓冲区根据AOF持久化策略【alawys,erevrysec,no】将操作sync同步到磁盘的AOF文件中<br />3.AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量<br />4.redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的<a name="ufdoD"></a>## AOF配置说明```c############################## APPEND ONLY MODE ################################ By default Redis asynchronously dumps the dataset on disk. This mode is# good enough in many applications, but an issue with the Redis process or# a power outage may result into a few minutes of writes lost (depending on# the configured save points).## The Append Only File is an alternative persistence mode that provides# much better durability. For instance using the default data fsync policy# (see later in the config file) Redis can lose just one second of writes in a# dramatic event like a server power outage, or a single write if something# wrong with the Redis process itself happens, but the operating system is# still running correctly.## AOF and RDB persistence can be enabled at the same time without problems.# If the AOF is enabled on startup Redis will load the AOF, that is the file# with the better durability guarantees.## Please check https://redis.io/topics/persistence for more information.appendonly no# The name of the append only file (default: "appendonly.aof")appendfilename "appendonly.aof"# The fsync() call tells the Operating System to actually write data on disk# instead of waiting for more data in the output buffer. Some OS will really flush# data on disk, some other OS will just try to do it ASAP.## Redis supports three different modes:## no: don't fsync, just let the OS flush the data when it wants. Faster.# always: fsync after every write to the append only log. Slow, Safest.# everysec: fsync only one time every second. Compromise.## The default is "everysec", as that's usually the right compromise between# speed and data safety. It's up to you to understand if you can relax this to# "no" that will let the operating system flush the output buffer when# it wants, for better performances (but if you can live with the idea of# some data loss consider the default persistence mode that's snapshotting),# or on the contrary, use "always" that's very slow but a bit safer than# everysec.## More details please check the following article:# http://antirez.com/post/redis-persistence-demystified.html## If unsure, use "everysec".# appendfsync alwaysappendfsync everysec# appendfsync no# When the AOF fsync policy is set to always or everysec, and a background# saving process (a background save or AOF log background rewriting) is# performing a lot of I/O against the disk, in some Linux configurations# Redis may block too long on the fsync() call. Note that there is no fix for# this currently, as even performing fsync in a different thread will block# our synchronous write(2) call.## In order to mitigate this problem it's possible to use the following option# that will prevent fsync() from being called in the main process while a# BGSAVE or BGREWRITEAOF is in progress.## This means that while another child is saving, the durability of Redis is# the same as "appendfsync none". In practical terms, this means that it is# possible to lose up to 30 seconds of log in the worst scenario (with the# default Linux settings).## If you have latency problems turn this to "yes". Otherwise leave it as# "no" that is the safest pick from the point of view of durability.no-appendfsync-on-rewrite no# Automatic rewrite of the append only file.# Redis is able to automatically rewrite the log file implicitly calling# BGREWRITEAOF when the AOF log size grows by the specified percentage.## This is how it works: Redis remembers the size of the AOF file after the# latest rewrite (if no rewrite has happened since the restart, the size of# the AOF at startup is used).## This base size is compared to the current size. If the current size is# bigger than the specified percentage, the rewrite is triggered. Also# you need to specify a minimal size for the AOF file to be rewritten, this# is useful to avoid rewriting the AOF file even if the percentage increase# is reached but it is still pretty small.## Specify a percentage of zero in order to disable the automatic AOF# rewrite feature.auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb# An AOF file may be found to be truncated at the end during the Redis# startup process, when the AOF data gets loaded back into memory.# This may happen when the system where Redis is running# crashes, especially when an ext4 filesystem is mounted without the# data=ordered option (however this can't happen when Redis itself# crashes or aborts but the operating system still works correctly).## Redis can either exit with an error when this happens, or load as much# data as possible (the default now) and start if the AOF file is found# to be truncated at the end. The following option controls this behavior.## If aof-load-truncated is set to yes, a truncated AOF file is loaded and# the Redis server starts emitting a log to inform the user of the event.# Otherwise if the option is set to no, the server aborts with an error# and refuses to start. When the option is set to no, the user requires# to fix the AOF file using the "redis-check-aof" utility before to restart# the server.## Note that if the AOF file will be found to be corrupted in the middle# the server will still exit with an error. This option only applies when# Redis will try to read more data from the AOF file but not enough bytes# will be found.aof-load-truncated yes# When rewriting the AOF file, Redis is able to use an RDB preamble in the# AOF file for faster rewrites and recoveries. When this option is turned# on the rewritten AOF file is composed of two different stanzas:## [RDB file][AOF tail]## When loading, Redis recognizes that the AOF file starts with the "REDIS"# string and loads the prefixed RDB file, then continues loading the AOF# tail.aof-use-rdb-preamble yes
appendonly:AOF默认不开启,开启需要改为yes
appendfilename:指定AOF生成的文件名字,默认为 appendonly.aof
appendfsync:AOF同步频率,默认为everysec,可选参数如下
appendfsync always (始终同步,每次redis写入都会立刻记入日志,性能较差单数据完整)
appendfsync everysec (每秒进行同步,每秒进行一次日志记入,但是存在本秒数据丢失问题)
appendfsync no (不同步,把同步时机交给操作系统,默认操作系统30秒会进行刷盘操作)
no-appendfsync-on-rewrite:重写时不追加fsync,默认为no表示重写时会继续执行fsync。
实际上本质还是磁盘I/O的问题,Redis作者认为在AOF中如果你配置了every甚至always,那么就会产生大量的磁盘写入操作(调用sync),假设此时又遇到了bgsave或bgwriteaof,这将会导致主进程阻塞的时间更长,所以提供了这样一个配置,当为no时,表示不考虑磁盘写入的问题,依旧会调用fsync刷盘操作,这样数据可靠性得到保证,但可能会产生较高的阻塞延时问题,如果不能接受阻塞的问题,你可以配置成yes,那么就意味着在重写期间,即使你配置的是every或always,那么也只会调用write函数写入到操作系统缓存中,什么时候刷盘由操作系统自身决定(默认为30秒),这样可以有效减少阻塞问题,但数据的可靠性就无法保证了,最差情况下就会丢失30秒的数据。
auto-aof-rewrite-percentage:设置重写百分比基准值,当aof文件达到上次重写后文件的两倍后触发重写
auto-aof-rewrite-min-size :设置重写的最小基准值,当aof文件达到64M时触发重写
举例说明:
当aof文件达到70M时,由于超过64M触发重写,重写后文件为50M,下一次文件达到100M时触发重写,并修改base size为重写后大写,重写机制为aof文件当前大小>64M(默认) AND >=base_size+base_size*100%(默认)时触发
aof-load-truncated :
aof-use-rdb-preamble:
什么是AOF重写
AOF采用文件追加方式,文件会原来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用bgrewriteaof。
重写的重体流程是当aof文件持续增长过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),redis4.0版本后的重写,是指把rdb的快照以二进制的形式附加在新的aof头部,作为已有的历史数据,替换掉原来的流水账操作
重写例子:
set test test
set test2 test2
以上两个重写后为 set test test test2 test2
AOF重写流程
1)bgrewriteaof触发重写,判断是否当前有bgsave或bgrewriteaof在运行,如果有,则等待该命令结束后再继续执行
2)主进程fork出子进程执行重写操作,保证主进程不会阻塞
3)子进程遍历redis内存中数据到临时文件,客户端的写请求同时写入aof_buf缓冲区和aof_rewirite_buf重写缓冲区保证原aof文件的完整以及新AOF文件生成期间的新数据修改动作不会丢失
4)子进程写完新的AOF文件后,向主进程发信号,父进程更新统计信息。主进程把aof_rewrite_buf中的数据写入新的AOF文件中
5)使用新的AOF文件覆盖旧的AOF文件,完成AOF文件重写
数据恢复
保证appendonly.aof文件与配置中指定的位置一致,然后重启redis后系统会自动读取appendonly.aof文件中的数据.
若aof文件损坏,要恢复可通过如下命令恢复aof文件
redis-check-aof —fix appendonly.aof
优势
持久化使用建议
- 官方推荐两个都启用
- 如果数据不敏感,可以单独用RDB
- 不建议单独用AOF,因为可能出现BUG
- 如果只是做纯内存缓存,可以都不用
- 只要硬盘许可,应该尽量减少AOF的rewrite频率,默认重写基础大写为64M,可以设置到5G以上

若有收获,就点个赞吧
0 人点赞
