在Java领域,实现并发程序的主要手段就是多线程,使用多线程还是比较简单的,但是使用多少个线程却是个困难的问题。工作中,经常有人问,“各种线程池的线程数量调整成多少是合适的?”或者“Tomcat的线程数、Jdbc连接池的连接数是多少?”等等。那我们应该如何设置合适的线程数呢?
要解决这个问题,首先要分析以下两个问题:
- 为什么要使用多线程?
- 多线程的应用场景有哪些?
为什么要使用多线程?
使用多线程,本质上就是提升程序性能。不过此刻谈到的性能,可能在你脑海里还是比较笼统的,基本上就是快、快、快,这种无法度量的感性认识很不科学,所以在提升性能之前,首要问题是:如何度量性能。
度量性能的指标有很多,但是有两个指标是最核心的,它们就是延迟和吞吐量。延迟指的是发出请求到收到响应这个过程的时间;延迟越短,意味着程序执行得越快,性能也就越好。 吞吐量指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好。这两个指标内部有一定的联系(同等条件下,延迟越短,吞吐量越大),但是由于它们隶属不同的维度(一个是时间维度,一个是空间维度),并不能互相转换。
我们所谓提升性能,从度量的角度,主要是降低延迟,提高吞吐量。这也是我们使用多线程的主要目的。那我们该怎么降低延迟,提高吞吐量呢?这个就要从多线程的应用场景说起了。多线程的应用场景
要想“降低延迟,提高吞吐量”,对应的方法呢,基本上有两个方向,一个方向是优化算法,另一个方向是将硬件的性能发挥到极致。前者属于算法范畴,后者则是和并发编程息息相关了。那计算机主要有哪些硬件呢?主要是两类:一个是I/O,一个是CPU。简言之,在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升I/O的利用率和CPU的利用率。
估计这个时候你会有个疑问,操作系统不是已经解决了硬件的利用率问题了吗?的确是这样,例如操作系统已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免CPU轮询I/O状态,也提升了CPU的利用率。但是操作系统解决硬件利用率问题的对象往往是单一的硬件设备,而我们的并发程序,往往需要CPU和I/O设备相互配合工作,也就是说,我们需要解决CPU和I/O设备综合利用率的问题。关于这个综合利用率的问题,操作系统虽然没有办法完美解决,但是却给我们提供了方案,那就是:多线程。
下面我们用一个简单的示例来说明:如何利用多线程来提升CPU和I/O设备的利用率?假设程序按照CPU计算和I/O操作交叉执行的方式运行,而且CPU计算和I/O操作的耗时是1:1。
如下图所示,如果只有一个线程,执行CPU计算的时候,I/O设备空闲;执行I/O操作的时候,CPU空闲,所以CPU的利用率和I/O设备的利用率都是50%。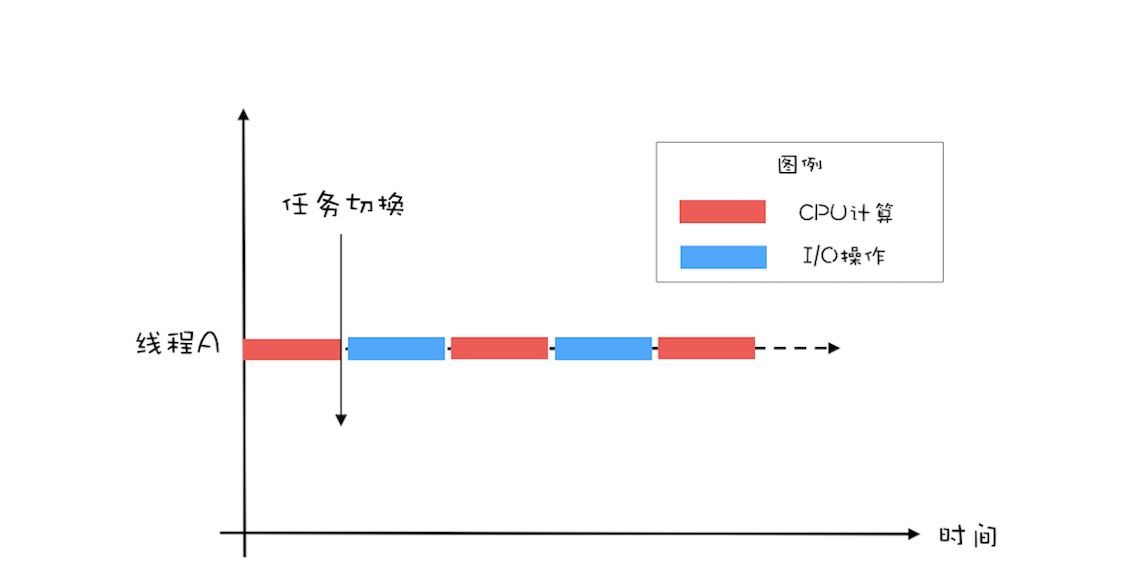 单线程执行示意图如果有两个线程,如下图所示,当线程A执行CPU计算的时候,线程B执行I/O操作;当线程A执行I/O操作的时候,线程B执行CPU计算,这样CPU的利用率和I/O设备的利用率就都达到了100%。
单线程执行示意图如果有两个线程,如下图所示,当线程A执行CPU计算的时候,线程B执行I/O操作;当线程A执行I/O操作的时候,线程B执行CPU计算,这样CPU的利用率和I/O设备的利用率就都达到了100%。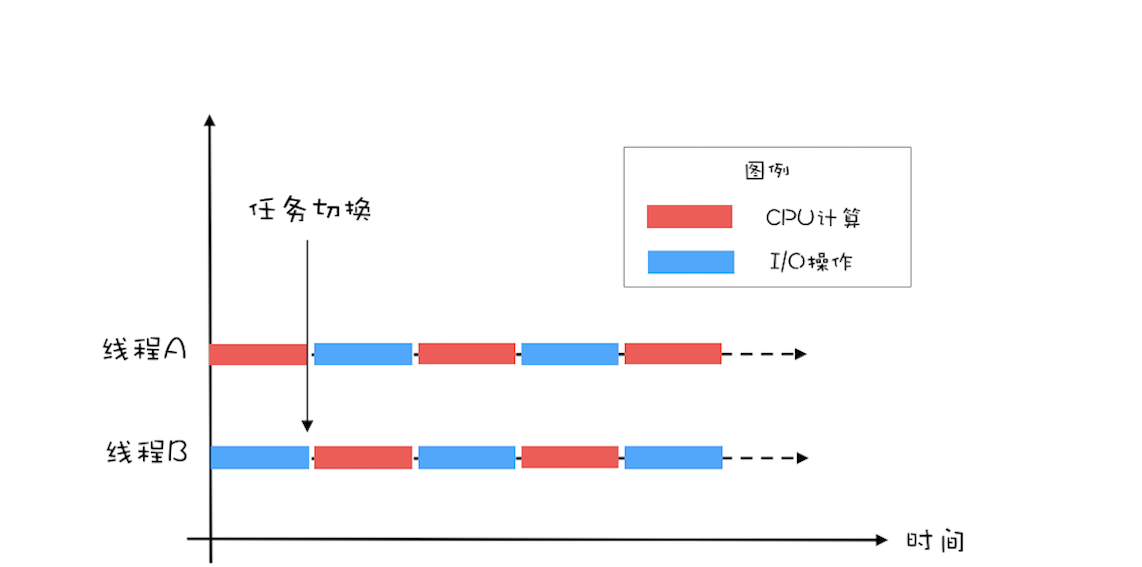 二线程执行示意图我们将CPU的利用率和I/O设备的利用率都提升到了100%,会对性能产生了哪些影响呢?通过上面的图示,很容易看出:单位时间处理的请求数量翻了一番,也就是说吞吐量提高了1倍。此时可以逆向思维一下,如果CPU和I/O设备的利用率都很低,那么可以尝试通过增加线程来提高吞吐量。
二线程执行示意图我们将CPU的利用率和I/O设备的利用率都提升到了100%,会对性能产生了哪些影响呢?通过上面的图示,很容易看出:单位时间处理的请求数量翻了一番,也就是说吞吐量提高了1倍。此时可以逆向思维一下,如果CPU和I/O设备的利用率都很低,那么可以尝试通过增加线程来提高吞吐量。
在单核时代,多线程主要就是用来平衡CPU和I/O设备的。如果程序只有CPU计算,而没有I/O操作的话,多线程不但不会提升性能,还会使性能变得更差,原因是增加了线程切换的成本。但是在多核时代,这种纯计算型的程序也可以利用多线程来提升性能。为什么呢?因为利用多核可以降低响应时间。
为便于你理解,这里我举个简单的例子说明一下:计算1+2+… … +100亿的值,如果在4核的CPU上利用4个线程执行,线程A计算[1,25亿),线程B计算[25亿,50亿),线程C计算[50,75亿),线程D计算[75亿,100亿],之后汇总,那么理论上应该比一个线程计算[1,100亿]快将近4倍,响应时间能够降到25%。一个线程,对于4核的CPU,CPU的利用率只有25%,而4个线程,则能够将CPU的利用率提高到100%。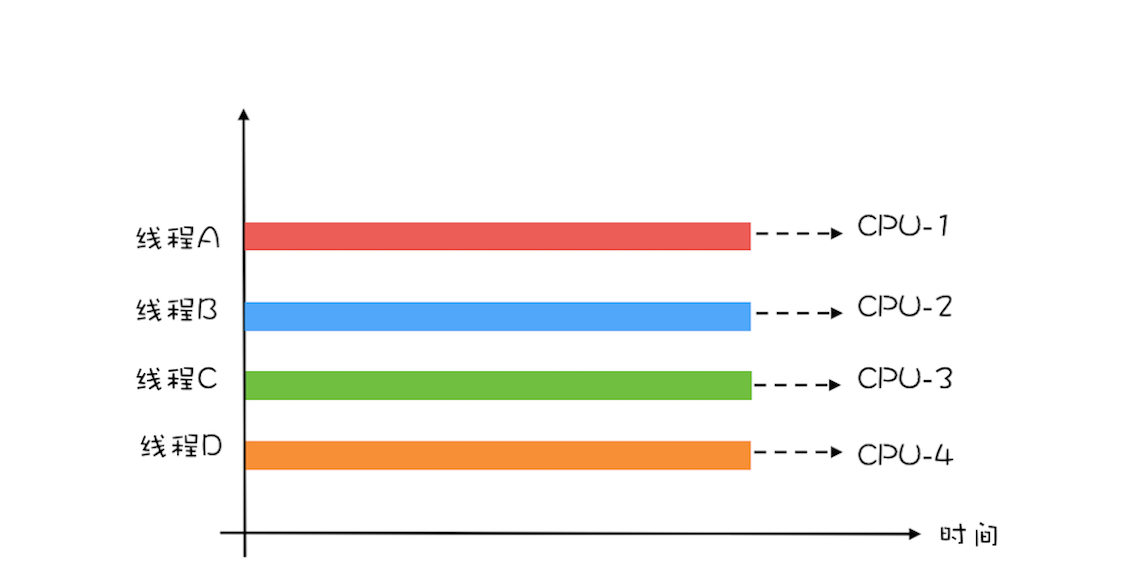 多核执行多线程示意图## 创建多少线程合适?
创建多少线程合适,要看多线程具体的应用场景。我们的程序一般都是CPU计算和I/O操作交叉执行的,由于I/O设备的速度相对于CPU来说都很慢,所以大部分情况下,I/O操作执行的时间相对于CPU计算来说都非常长,这种场景我们一般都称为I/O密集型计算;和I/O密集型计算相对的就是CPU密集型计算了,CPU密集型计算大部分场景下都是纯CPU计算。I/O密集型程序和CPU密集型程序,计算最佳线程数的方法是不同的。
多核执行多线程示意图## 创建多少线程合适?
创建多少线程合适,要看多线程具体的应用场景。我们的程序一般都是CPU计算和I/O操作交叉执行的,由于I/O设备的速度相对于CPU来说都很慢,所以大部分情况下,I/O操作执行的时间相对于CPU计算来说都非常长,这种场景我们一般都称为I/O密集型计算;和I/O密集型计算相对的就是CPU密集型计算了,CPU密集型计算大部分场景下都是纯CPU计算。I/O密集型程序和CPU密集型程序,计算最佳线程数的方法是不同的。
下面我们对这两个场景分别说明。
对于CPU密集型计算,多线程本质上是提升多核CPU的利用率,所以对于一个4核的CPU,每个核一个线程,理论上创建4个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于CPU密集型的计算场景,理论上“线程的数量=CPU核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU核数+1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证CPU的利用率。
对于I/O密集型的计算场景,比如前面我们的例子中,如果CPU计算和I/O操作的耗时是1:1,那么2个线程是最合适的。如果CPU计算和I/O操作的耗时是1:2,那多少个线程合适呢?是3个线程,如下图所示:CPU在A、B、C三个线程之间切换,对于线程A,当CPU从B、C切换回来时,线程A正好执行完I/O操作。这样CPU和I/O设备的利用率都达到了100%。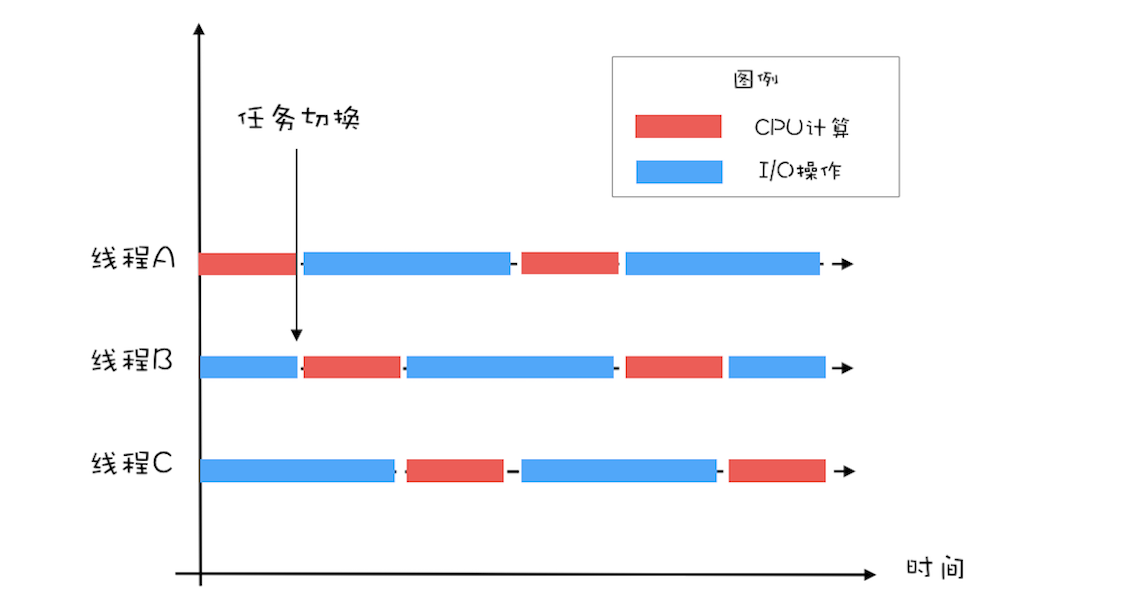 三线程执行示意图通过上面这个例子,我们会发现,对于I/O密集型计算场景,最佳的线程数是与程序中CPU计算和I/O操作的耗时比相关的,我们可以总结出这样一个公式:
三线程执行示意图通过上面这个例子,我们会发现,对于I/O密集型计算场景,最佳的线程数是与程序中CPU计算和I/O操作的耗时比相关的,我们可以总结出这样一个公式:
最佳线程数=1 +(I/O耗时 / CPU耗时)
我们令R=I/O耗时 / CPU耗时,综合上图,可以这样理解:当线程A执行IO操作时,另外R个线程正好执行完各自的CPU计算。这样CPU的利用率就达到了100%。
不过上面这个公式是针对单核CPU的,至于多核CPU,也很简单,只需要等比扩大就可以了,计算公式如下:
最佳线程数=CPU核数 * [ 1 +(I/O耗时 / CPU耗时)]
总结
很多人都知道线程数不是越多越好,但是设置多少是合适的,却又拿不定主意。其实只要把握住一条原则就可以了,这条原则就是将硬件的性能发挥到极致。上面我们针对CPU密集型和I/O密集型计算场景都给出了理论上的最佳公式,这些公式背后的目标其实就是将硬件的性能发挥到极致。
对于I/O密集型计算场景,I/O耗时和CPU耗时的比值是一个关键参数,不幸的是这个参数是未知的,而且是动态变化的,所以工程上,我们要估算这个参数,然后做各种不同场景下的压测来验证我们的估计。不过工程上,原则还是将硬件的性能发挥到极致,所以压测时,我们需要重点关注CPU、I/O设备的利用率和性能指标(响应时间、吞吐量)之间的关系。
课后思考
有些同学对于最佳线程数的设置积累了一些经验值,认为对于I/O密集型应用,最佳线程数应该为:2 * CPU的核数 + 1,你觉得这个经验值合理吗?
欢迎在留言区与我分享你的想法,也欢迎你在留言区记录你的思考过程。感谢阅读,如果你觉得这篇文章对你有帮助的话,也欢迎把它分享给更多的朋友。

若有收获,就点个赞吧
0 人点赞
