网络通信编程基本常识
什么是 Socket?
Socket 是应用层与 TCP/IP 协议族通信的中间软件抽象层,它是一组接口,一般由操作系统提供。在设计模式中,Socket 其实就是一个门面模式,它把复杂的 TCP/IP 协议处理和通信缓存管理等等都隐藏在 Socket 接口后面,对用户来说,使用一组简单的接口就能进行网络应用编程,让 Socket 去组织数据,以符合指定的协议。主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接。
客户端连接上一个服务端,就会在客户端中产生一个 socket 接口实例,服务端每接受一个客户端连接,就会产生一个 socket 接口实例和客户端的 socket 进行通信,有多个客户端连接自然就有多个 socket 接口实例。
短连接
连接 -> 传输数据 -> 关闭连接:传统 HTTP 是无状态的,浏览器和服务器每进行一次 HTTP 操作,就建立一次连接,但任务结束就中断连接。也可以这样说:短连接是指 SOCKET 连接后发送后接收完数据后马上断开连接。
长连接
连接 -> 传输数据 -> 保持连接 -> 传输数据 -> 。。。 -> 关闭连接:长连接指建立 SOCKET 连接后不管是否使用都保持连接。
什么时候用长连接,短连接?
长连接多用于操作频繁,点对点的通讯。每个 TCP 连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,下次处理时直接发送数据包就 OK 了,不用建立 TCP 连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket 错误,而且频繁的 socket 创建也是对资源的浪费。
而像 WEB 网站的 http 服务按照 http 协议规范早期一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像 WEB 网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源。但是现在的 http 协议,HTTP 1.1,尤其是 HTTP 2、HTTP 3 已经开始向长连接演化。
总之,长连接和短连接的选择要视情况而定。
网络编程里通用常识
我们首先来看一个生活中的场景。周瑜老师准备开一个心理咨询中心,嘴上光喊没用,只有到工商局注册“东吴心理诊所”并且在图灵大街888号挂牌了,才算正式开张。疫情来了,准备开展电话业务,申请了一个电话号码88888888。诸葛老师有了心理问题,于是打电话过来,周瑜老师接了电话,但是周瑜老师不懂心理咨询,于是通过内部分机把电话转给请来的心理医生A负责接待诸葛老师,心理医生A和诸葛老师通过电话进行沟通,模式一般就是一个人说另个一人听,两者进行沟通交流。Fox老师也来了,周瑜老师接了电话,又把电话转给请来的心理医生B负责接待Fox老师,心理医生B和Fox老师也通过电话进行沟通。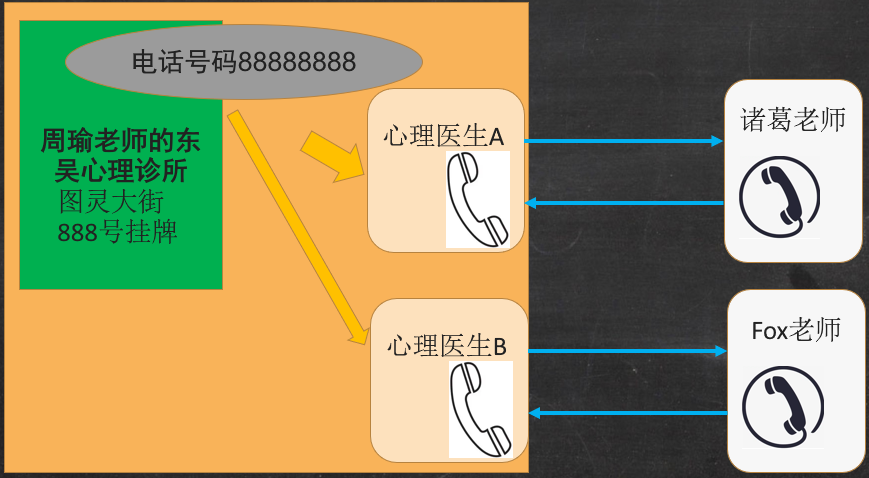
上述的场景和网络编程有很大的相似之处。
我们已经知道在通信编程里提供服务的叫服务端,连接服务端使用服务的叫客户端。在开发过程中,如果类的名字有 Server 或者 ServerSocket 的,表示这个类是给服务端容纳网络服务用的,如果类的名字只包含 Socket 的,那么表示这是负责具体的网络读写的。
那么对于服务端来说 ServerSocket 就只是个场所,就像上面的“东吴心理诊所”,它必须要绑定某个 IP 地址,就像“东吴心理诊所”在“图灵大街888号挂牌”,同时 ServerSocket 还需要监听某个端口,就像“申请了一个电话号码 88888888”。
有电话进来了,具体和客户端沟通的还是一个一个的 socket,就像“周瑜老师不懂心理咨询,于是通过内部分机把电话转给请来的心理医生 A 负责接待诸葛老师”,所以在通信编程里,ServerSocket 并不负责具体的网络读写,ServerSocket 就只是负责接收客户端连接后,新启一个 socket 来和客户端进行沟通。这一点对所有模式的通信编程都是适用的。
在通信编程里,我们关注的其实也就是三个事情:连接(客户端连接服务器,服务器等待和接收连接)、读网络数据、写网络数据,所有模式的通信编程都是围绕着这三件事情进行的。服务端提供 IP 和监听端口,客户端通过连接操作想服务端监听的地址发起连接请求,通过三次握手连接,如果连接成功建立,双方就可以通过套接字进行通信。
我们后面将学习的 BIO 和 NIO 其实都是处理上面三件事,只是处理的方式不一样。
Java 原生网络编程 - BIO
原生 JDK 网络编程 BIO
BIO,意为 Blocking I/O,即阻塞的 I/O。
BIO 基本上就是我们上面所说的生活场景的朴素实现。在 BIO 中类 ServerSocket 负责绑定 IP 地址,启动监听端口,等待客户连接;客户端 Socket 类的实例发起连接操作,ServerSocket 接受连接后产生一个新的服务端 socket 实例负责和客户端 socket 实例通过输入和输出流进行通信。
BIO 的阻塞,主要体现在两个地方:
- 若一个服务器启动就绪,那么主线程就一直在等待着客户端的连接,这个等待过程中主线程就一直在阻塞。
- 在连接建立之后,在读取到 socket 信息之前,线程也是一直在等待,一直处于阻塞的状态下的。
这一点可以通过 cn.tuling.bio 下的 ServerSingle.java 服务端程序看出,启动该程序后,启动一个 Client 程序实例,并让这个 Client 阻塞住,位置就在向服务器输出具体请求之前,再启动一个新的 Client 程序实例,会发现尽管新的 Client 实例连接上了服务器,但是 ServerSingle 服务端程序仿佛无感知一样?为何,因为执行的主线程被阻塞了一直在等待第一个 Client 实例发送消息过来。
所以在 BIO 通信里,我们往往会在服务器的实现上结合线程来处理连接以及和客户端的通信。
传统 BIO 通信模型:采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成后,通过输出流返回应答给客户端,线程销毁。即典型的一请求一应答模型,同时数据的读取写入也必须阻塞在一个线程内等待其完成。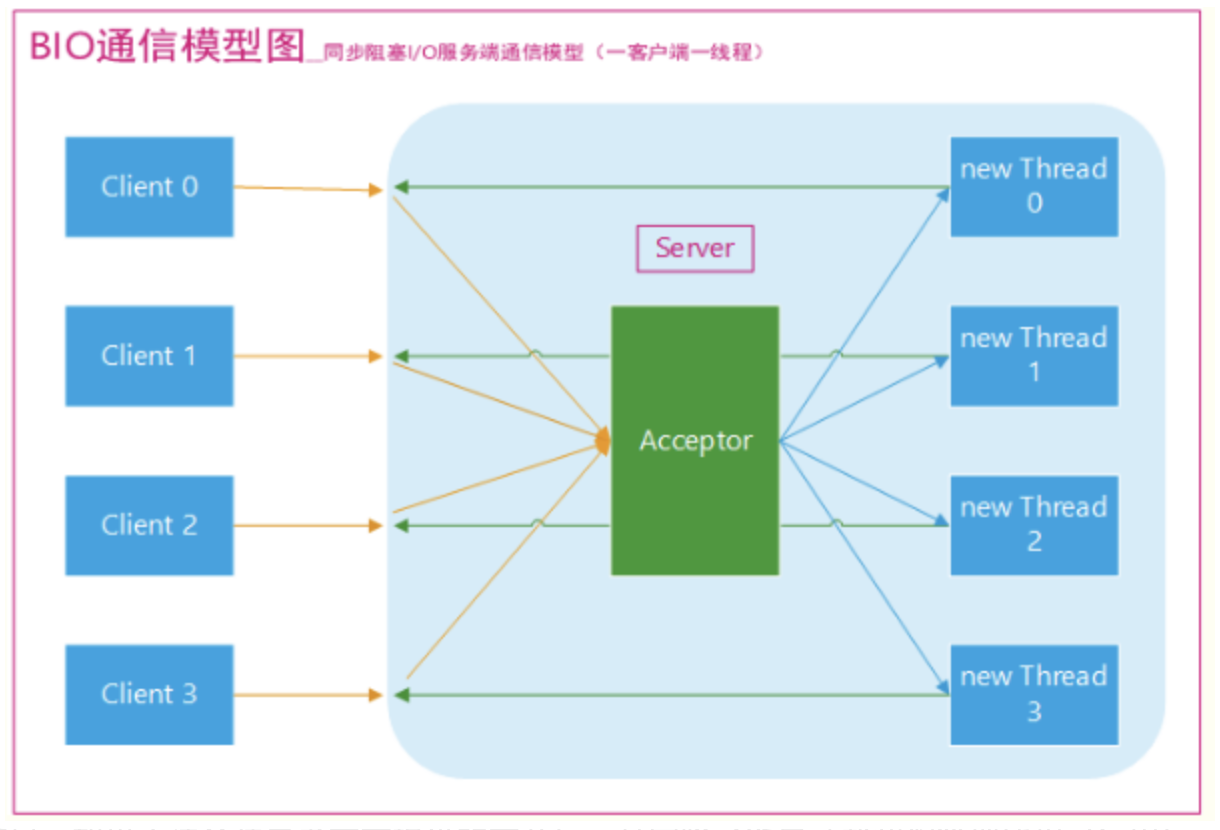
public class SingleServer {static int connectCount = 0;public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket();// 监听端口InetSocketAddress socketAddress = new InetSocketAddress(8888);serverSocket.bind(socketAddress);System.out.printf("Start Server in %s\n", socketAddress.getHostName() + ":" + serverSocket.getLocalPort());while (true) {// ⭐️ 这里会阻塞,等待客户端连接Socket socket = serverSocket.accept();String clientHost = socket.getInetAddress() + ":" + socket.getPort();System.out.printf("【Accept】Socket in %s, totalCount = %d\n", clientHost, (++connectCount));// 实例化客户端对输入输出流try (ObjectInputStream inputStream = new ObjectInputStream(socket.getInputStream());ObjectOutputStream outputStream = new ObjectOutputStream(socket.getOutputStream())) {// ⭐️ 这里会阻塞,等待客户端发送数据// 接受客户端对输出(也就是服务端的输入)String message = inputStream.readUTF();System.out.printf("【Message】%s send Message: %s\n", clientHost, message);// 服务端输出到客户端(也就是客户端的输入)outputStream.writeUTF("【ACK】" + message);outputStream.flush();} catch (Exception ex) {ex.printStackTrace();} finally {socket.close();}}}}
该模型最大的问题就是缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程个数和客户端并发访问数呈1:1的正比关系,Java 中的线程也是比较宝贵的系统资源,线程数量快速膨胀后,系统的性能将急剧下降,随着访问量的继续增大,系统最终就死掉了。
为了改进这种一连接一线程的模型,我们可以使用线程池来管理这些线程,实现 1 个或多个线程处理 N 个客户端的模型(但是底层还是使用的同步阻塞I/O),通常被称为“伪异步 I/O 模型“。
我们知道,如果使用 CachedThreadPool 线程池(不限制线程数量,如果不清楚请参考文首提供的文章),其实除了能自动帮我们管理线程(复用),看起来也就像是 1:1 的客户端:线程数模型,而使用 FixedThreadPool 我们就有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了 N:M 的伪异步 I/O 模型。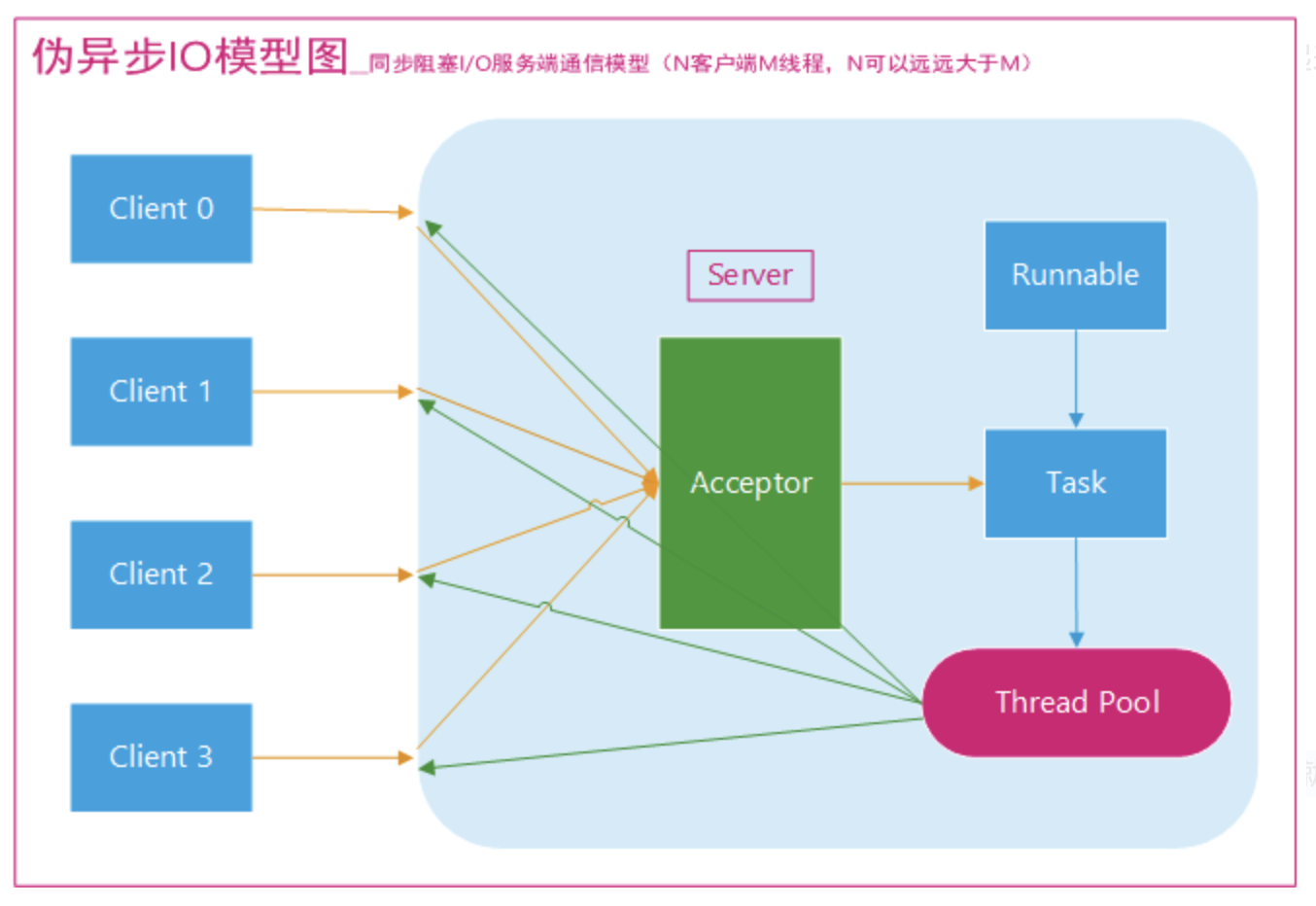
public class MultiServer {public static ExecutorService executorService= Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket();// 监听端口InetSocketAddress socketAddress = new InetSocketAddress(8888);serverSocket.bind(socketAddress);System.out.printf("Start Server in %s\n", socketAddress.getHostName() + ":" + serverSocket.getLocalPort());try (serverSocket) {while (true) {// ⭐️ 只会在 accept 这里阻塞,由于使用了线程,不会阻塞 readexecutorService.execute(new ServerTask(serverSocket.accept()));// new Thread(new ServerTask(serverSocket.accept())).start();}}}public static class ServerTask implements Runnable {private final Socket socket;public ServerTask(Socket socket) {this.socket = socket;}@Overridepublic void run() {String clientHost = socket.getInetAddress() + ":" + socket.getPort();// 实例化客户端对输入输出流try (ObjectInputStream inputStream = new ObjectInputStream(socket.getInputStream());ObjectOutputStream outputStream = new ObjectOutputStream(socket.getOutputStream())) {// 接受客户端对输出(也就是服务端的输入)String message = inputStream.readUTF();System.out.printf("【Message-%s】%s send Message: %s\n", Thread.currentThread().getName(), clientHost, message);// 服务端输出到客户端(也就是客户端的输入)outputStream.writeUTF("【ACK】" + message);outputStream.flush();} catch (Exception ex) {ex.printStackTrace();} finally {try {socket.close();} catch (IOException e) {e.printStackTrace();}}}}}
但是,正因为限制了线程数量,如果发生读取数据较慢时(比如数据量大、网络传输慢等),大量并发的情况下,其他接入的消息,只能一直等待,这就是最大的弊端。
原生 JDK 网络编程 - NIO
什么是 NIO?
NIO 库是在 JDK 1.4 中引入的。NIO 弥补了原来的 BIO 的不足,它在标准 Java 代码中提供了高速的、面向块的 I/O。NIO 被称为 No-Blocking IO 或者 new io都说得通。
和 BIO 的主要区别
面向流与面向缓冲
Java NIO 和 IO 之间第一个最大的区别是,IO 是面向流的,NIO 是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞 IO
Java IO 的各种流是阻塞的。这意味着,当一个线程调用read()或write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO 的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行 IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
NIO 之 Reactor 模式
反应器名字中”反应“的由来:“反应”即“倒置”,“控制逆转”,具体事件处理程序不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣,有事件来了,具体事件处理程序通过事件处理器对某个指定的事件发生做出反应;这种控制逆转又称为“好莱坞法则”(不要调用我,让我来调用你)
例如,路人甲去做男士 SPA,大堂经理负责服务,路人甲现在只对 10000 技师感兴趣,但是路人甲去的比较早,就告诉大堂经理,等 10000 技师上班了或者是空闲了,通知我。等路人甲接到大堂经理通知,做出了反应,把 10000 技师占住了。
然后,路人甲想起上一次的那个 888 号房间不错,设备舒适,灯光暧昧,又告诉大堂经理,我对 888 号房间很感兴趣,房间空出来了就告诉我,我现在先和 10000 这个小姐聊下人生,888 号房间空出来了,路人甲再次接到大堂经理通知,路人甲再次做出了反应。
路人甲就是具体事件处理程序,大堂经理就是所谓的反应器,“10000 技师上班了”和“888号房间空闲了”就是事件,路人甲只对这两个事件感兴趣,其他,比如 10001 号技师或者 999 号房间空闲了也是事件,但是路人甲不感兴趣。
大堂经理不仅仅服务路人甲这个人,他还可以同时服务路人乙、丙……..,每个人所感兴趣的事件是不一样的,大堂经理会根据每个人感兴趣的事件通知对应的每个人。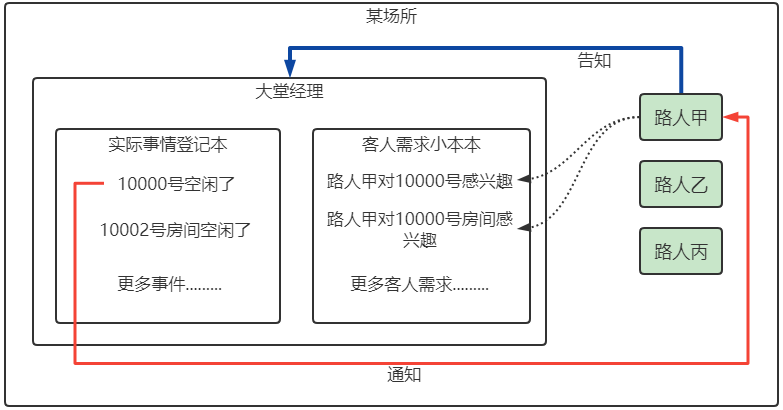 。
。
NIO 三大核心组件
NIO有三大核心组件:Selector选择器、Channel管道、buffer缓冲区。
Selector
Selector 的英文含义是“选择器”,也可以称为为“轮询代理器”、“事件订阅器”、“channel 容器管理机”都行。
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器(Selectors),然后使用一个单独的线程来操作这个选择器,进而“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
应用程序将向Selector对象注册需要它关注的Channel,以及具体的某一个Channel会对哪些IO事件感兴趣。Selector中也会维护一个“已经注册的Channel”的容器。
Channels
通道,被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。那么既然是和操作系统进行内容的传递,那么说明应用程序可以通过通道读取数据,也可以通过通道向操作系统写数据,而且可以同时进行读写。
- 所有被 Selector(选择器)注册的通道,只能是继承了 SelectableChannel 类的子类。
- ServerSocketChannel:应用服务器程序的监听通道。只有通过这个通道,应用程序才能向操作系统注册支持“多路复用IO”的端口监听。同时支持 UDP 协议和 TCP 协议。
- ScoketChannel:TCP Socket 套接字的监听通道,一个 Socket 套接字对应了一个
客户端IP:端口到服务器IP:端口的通信连接。
通道中的数据总是要先读到一个 Buffer,或者总是要从一个 Buffer 中写入。
buffer 缓冲区
我们前面说过 JDK NIO 是面向缓冲的。Buffer 就是这个缓冲,用于和 NIO 通道进行交互。数据是从通道读入缓冲区,从缓冲区写入到通道中的。以写为例,应用程序都是将数据写入缓冲,再通过通道把缓冲的数据发送出去,读也是一样,数据总是先从通道读到缓冲,应用程序再读缓冲的数据。
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存(其实就是数组)。这块内存被包装成 NIO Buffer 对象,并提供了一组方法,用来方便的访问该块内存。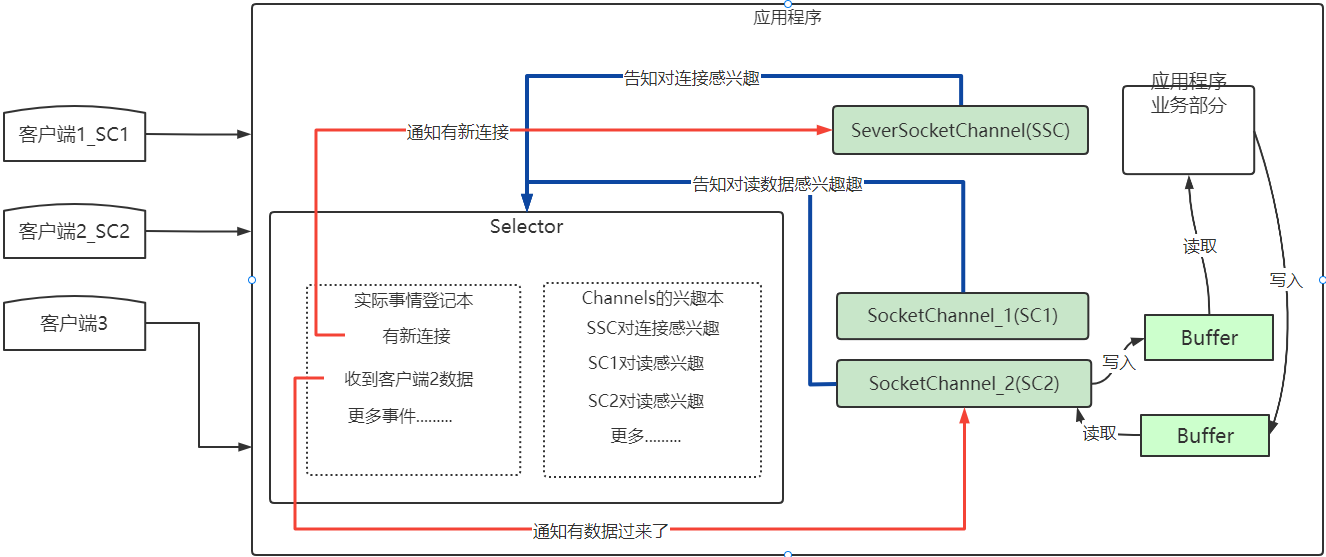
实现代码: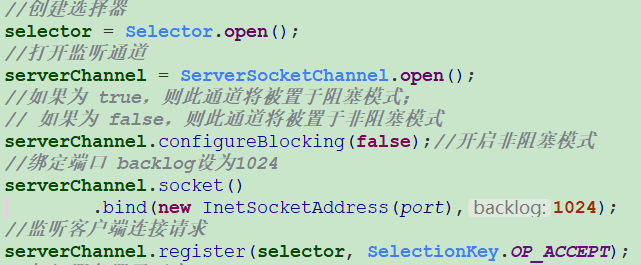
Selector 对象是通过调用静态工厂方法 open() 来实例化的,通过 ServerSocketChannel 的 open() 可以打开监听通道
Selector selector = Selector.open();ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
要实现 Selector 管理 Channel,需要将 channel 注册到相应的 Selector 上,如下:
serverSocketChannel.configureBlocking(false); // 开启非阻塞模式SelectionKey key = serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT); // 对连接事件感兴趣
通过调用通道的 register() 方法会将它注册到一个选择器上。与 Selector 一起使用时,Channel 必须处于非阻塞模式下,否则将抛出IllegalBlockingModeException 异常,这意味着不能将 FileChanne l与 Selector 一起使用,因为 FileChannel 不能切换到非阻塞模式,而套接字通道都可以。另外通道一旦被注册,将不能再回到阻塞状态,此时若调用通道的 configureBlocking(true) 将抛出 BlockingModeException 异常。
register() 方法的第二个参数是“interest 集合”,表示选择器所关心的通道操作,它实际上是一个表示选择器在检查通道就绪状态时需要关心的操作的比特掩码。比如一个选择器对通道的 read 和 write 操作感兴趣,那么选择器在检查该通道时,只会检查通道的 read 和 write 操作是否已经处在就绪状态。
具体的操作类型和通道上能被支持的操作类型前面已经讲述过。
如果 Selector 对通道的多操作类型感兴趣,可以用“位或”操作符来实现:int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
同时一个 Channel 仅仅可以被注册到一个 Selector 一次, 如果将 Channel 注册到 Selector 多次, 那么其实就是相当于更新 SelectionKey 的 interest set。
通过 SelectionKey 可以判断 Selector 是否对 Channel 的某种事件感兴趣,比如
int interestSet = selectionKey.interestOps();boolean isInterestedInAccept = (interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT;
通过 SelctionKey 对象的 readyOps() 来获取相关通道已经就绪的操作。它是 interest 集合的子集,并且表示了 interest 集合中从上次调用 select() 以后已经就绪的那些操作。JAVA 中定义几个方法用来检查这些操作是否就绪,比如:selectionKey.isAcceptable();
同时,通过 SelectionKey 可以取出这个 SelectionKey 所关联的 Selector 和 Channel。
如果我们要取消关联关系,怎么办?SelectionKey 对象的 cancel() 方法来取消特定的注册关系。
在实际的应用中,我们还可以为 SelectionKey 绑定附加对象,在需要的时候取出。
// 方式一SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);// 方式二selectionKey.attach(theObject);
取出这个附加对象,通过:Object attachedObj = key.attachment();
- 在实际运行中,我们通过 Selector 的 select() 方法可以选择已经准备就绪的通道(这些通道包含你感兴趣的的事件)。
下面是 Selector 几个重载的 select() 方法:
- select():阻塞到至少有一个通道在你注册的事件上就绪了。
- select(long timeout):和 select() 一样,但最长阻塞事件为 timeout 毫秒。
- selectNow():非阻塞,立刻返回。
select() 方法返回的 int 值表示有多少通道已经就绪,是自上次调用 select() 方法后有多少通道变成就绪状态。
一旦调用 select() 方法,并且返回值不为 0 时,则可以通过调用 Selector 的 selectedKeys() 方法来访问已选择键集合。Set selectedKeys = selector.selectedKeys();
这个时候,循环遍历 selectedKeys 集中的每个键,并检测各个键所对应的通道的就绪事件,再通过 SelectionKey 关联的 Selector 和 Channel 进行实际的业务处理。
注意每次迭代末尾的 keyIterator.remove() 调用。Selector 不会自己从已选择键集中移除 SelectionKey 实例。必须在处理完通道时自己移除,否则的话,下次该通道变成就绪时,Selector 会再次将其放入已选择键集中。
重要概念 SelectionKey
什么是 SelectionKey
SelectionKey 是一个抽象类,表示 selectableChannel 在 Selector 中注册的标识。每个 Channel 向 Selector 注册时,都将会创建一个 SelectionKey。SelectionKey 将 Channel 与 Selector 建立了关系,并维护了 channel 事件。
可以通过 cancel 方法取消键,取消的键不会立即从 selector 中移除,而是添加到 cancelledKeys 中,在下一次 select 操作时移除它。所以在调用某个 key 时,需要使用 isValid 进行校验.
SelectionKey 类型和就绪条件
在向 Selector 对象注册感兴趣的事件时,JAVA NIO 共定义了四种:OP_READ、OP_WRITE、OP_CONNECT、OP_ACCEPT(定义在 SelectionKey 中),分别对应读、写、请求连接、接受连接四种网络 Socket 操作。
| 操作类型 | 就绪条件及说明 |
|---|---|
| OP_READ | 当操作系统读缓冲区有数据可读时就绪。并非时刻都有数据可读,所以一般需要注册该操作,仅当有就绪时才发起读操作,有的放矢,避免浪费 CPU。 |
| OP_WRITE | 当操作系统写缓冲区有空闲空间时就绪。一般情况下写缓冲区都有空闲空间,小块数据直接写入即可,没必要注册该操作类型,否则该条件不断就绪浪费 CPU;但如果是写密集型的任务,比如文件下载等,缓冲区很可能满,注册该操作类型就很有必要,同时注意写完后取消注册。 |
| OP_CONNECT | 当 SocketChannel.connect() 请求连接成功后就绪。该操作只给客户端使用。 |
| OP_ACCEPT | 当接收到一个客户端连接请求时就绪。该操作只给服务器使用。 |
服务端和客户端分别感兴趣的类型
ServerSocketChannel 和 SocketChannel 可以注册自己感兴趣的操作类型,当对应操作类型的就绪条件满足时 OS 会通知 channel,下表描述各种 Channel 允许注册的操作类型,Y 表示允许注册,N 表示不允许注册,其中服务器 SocketChannel 指由服务器 ServerSocketChannel.accept() 返回的对象。
| OP_READ | OP_WRITE | OP_CONNECT | OP_ACCEPT | |
|---|---|---|---|---|
| 服务器(ServerSocketChannel) | N | N | N | Y |
| 服务器(SocketChannel) | Y | Y | N | N |
| 客户端(SocketChannel) | Y | Y | Y | N |
服务器启动 ServerSocketChannel,关注 OP_ACCEPT 事件,
客户端启动 SocketChannel,连接服务器,关注 OP_CONNECT 事件
服务器接受连接,启动一个服务器的 SocketChannel,这个 SocketChanne l可以关注 OP_READ、OP_WRITE 事件,一般连接建立后会直接关注OP_READ 事件
客户端这边的客户端 SocketChannel 发现连接建立后,可以关注 OP_READ、OP_WRITE 事件,一般是需要客户端需要发送数据了才关注 OP_READ 事件
连接建立后客户端与服务器端开始相互发送消息(读写),根据实际情况来关注 OP_READ、OP_WRITE 事件。
public class NioServer {public static void main(String[] args) {NioServerHandle nioServerHandle = new NioServerHandle(Const.DEFAULT_PORT);new Thread(nioServerHandle, "Server").start();}}
public class NioServerHandle implements Runnable {private volatile boolean started;private ServerSocketChannel serverSocketChannel;private Selector selector;/*** 构造方法** @param port 指定要监听的端口号*/public NioServerHandle(int port) {try {/* 创建选择器的实例 */selector = Selector.open();/* 创建ServerSocketChannel的实例 */serverSocketChannel = ServerSocketChannel.open();/* 设置通道为非阻塞模式 */serverSocketChannel.configureBlocking(false);/* 绑定端口 */serverSocketChannel.socket().bind(new InetSocketAddress(port));/* 注册事件,表示服务端只关心客户端连接 */serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);started = true;System.out.println("服务器已启动,端口号:" + port);} catch (IOException e) {e.printStackTrace();}}@Overridepublic void run() {while (started) {try {/* 获取当前有哪些事件 */selector.select(1000);/* 获取事件的集合 */Set<SelectionKey> selectionKeys = selector.selectedKeys();Iterator<SelectionKey> iterator = selectionKeys.iterator();while (iterator.hasNext()) {SelectionKey key = iterator.next();/* 我们必须首先将处理过的 SelectionKey 从选定的键集合中删除。如果我们没有删除处理过的键,那么它仍然会在主集合中以一个激活的键出现,这会导致我们尝试再次处理它。*/iterator.remove();handleInput(key);}} catch (IOException e) {e.printStackTrace();}}}/* 处理事件的发生 */private void handleInput(SelectionKey key) throws IOException {if (key.isValid()) {/* 处理新接入的客户端的请求 */if (key.isAcceptable()) {/* 获取关心当前事件的 Channel,只有 ServerSocketChannel 会关心 OP_ACCEPT 事件*/ServerSocketChannel ssc = (ServerSocketChannel) key.channel();/* 接受连接 */SocketChannel sc = ssc.accept();System.out.printf("========== 建立 %s 连接 =========\n", sc.getRemoteAddress());sc.configureBlocking(false);/* 关注读事件 */sc.register(selector, SelectionKey.OP_READ);}/* 处理对端的发送的数据 */if (key.isReadable()) {SocketChannel sc = (SocketChannel) key.channel();/* 创建ByteBuffer,开辟一个缓冲区 */ByteBuffer buffer = ByteBuffer.allocate(1024);/* ⭐️ 从通道里读取数据,然后写入buffer */int readBytes = sc.read(buffer);if (readBytes > 0) {/* 将缓冲区当前的 limit 设置为 position, position = 0,用于后续对缓冲区的读取操作 */buffer.flip();/* 根据缓冲区可读字节数创建字节数组 */byte[] bytes = new byte[buffer.remaining()];/* 将缓冲区可读字节数组复制到新建的数组中 */buffer.get(bytes);String message = new String(bytes, StandardCharsets.UTF_8);System.out.println("服务器收到消息:" + message);/* 处理数据 */String result = Const.response(message);/*发送应答消息*/doWrite(sc, result);} else if (readBytes < 0) {/* 取消特定的注册关系 */key.cancel();/* 关闭通道 */sc.close();}}}}/* 发送应答消息 */private void doWrite(SocketChannel sc, String message) throws IOException {byte[] bytes = message.getBytes();ByteBuffer buffer = ByteBuffer.allocate(bytes.length);buffer.put(bytes);buffer.flip();// ⭐️ 从 buffer 读取数据,写往 SocketChannelsc.write(buffer);}public void stop() {started = false;}}
public class NioClient {private static NioClientHandle nioClientHandle;public static void start() {nioClientHandle = new NioClientHandle(Const.DEFAULT_SERVER_IP, Const.DEFAULT_PORT);new Thread(nioClientHandle, "client").start();}public static void main(String[] args) throws Exception {start();Scanner scanner = new Scanner(System.in);while (true) {// 向服务器发送消息nioClientHandle.sendMsg(scanner.next());}}}
public class NioClientHandle implements Runnable {private String host;private int port;private volatile boolean started;private Selector selector;private SocketChannel socketChannel;public NioClientHandle(String ip, int port) {this.host = ip;this.port = port;try {/* 创建选择器的实例 */selector = Selector.open();/* 创建 ServerSocketChannel的实例 */socketChannel = SocketChannel.open();/* 设置通道为非阻塞模式 */socketChannel.configureBlocking(false);started = true;System.out.println("客户端已启动");} catch (IOException e) {e.printStackTrace();}}@Overridepublic void run() {try {// 连接服务端doConnect();} catch (IOException e) {e.printStackTrace();System.exit(1);}//循环遍历selectorwhile (started) {try {// 无论是否有读写事件发生,selector 每隔 1s 被唤醒一次selector.select(1000);// 获取当前有哪些事件可以使用Set<SelectionKey> keys = selector.selectedKeys();// 转换为迭代器Iterator<SelectionKey> it = keys.iterator();SelectionKey key = null;while (it.hasNext()) {key = it.next();/* 我们必须首先将处理过的 SelectionKey 从选定的键集合中删除。如果我们没有删除处理过的键,那么它仍然会在主集合中以一个激活的键出现,这会导致我们尝试再次处理它。*/it.remove();try {// 处理事件handleInput(key);} catch (Exception e) {if (key != null) {key.cancel();if (key.channel() != null) {key.channel().close();}}}}} catch (Exception e) {e.printStackTrace();System.exit(1);}}// selector 关闭后会自动释放里面管理的资源if (selector != null) {try {selector.close();} catch (Exception e) {e.printStackTrace();}}}//具体的事件处理方法private void handleInput(SelectionKey key) throws IOException {// 检查 key 是否是无效的:比如已经删除了if (key.isValid()) {// 获得关心当前事件的 channelSocketChannel sc = (SocketChannel) key.channel();// 如果是:连接事件if (key.isConnectable()) {if (sc.finishConnect()) {// 连接成功后,注册 OP_READ 事件socketChannel.register(selector, SelectionKey.OP_READ);} else System.exit(1);}// 如果是:有数据可读事件if (key.isReadable()) {// 创建 ByteBuffer,并开辟一个 1M 大小的缓冲区ByteBuffer buffer = ByteBuffer.allocate(1024);// 读取请求码流,返回读取到的字节数int readBytes = sc.read(buffer);//读取到字节,对字节进行编解码if (readBytes > 0) {// 将缓冲区当前的 limit 设置为 position, position = 0// 用于后续对缓冲区的读取操作buffer.flip();// 根据缓冲区可读字节数创建字节数组byte[] bytes = new byte[buffer.remaining()];// 将缓冲区可读字节数组复制到新建的数组中buffer.get(bytes);String result = new String(bytes, StandardCharsets.UTF_8);System.out.println("客户端收到服务端消息:" + result);}// 链路已经关闭,释放资源// 当 readBytes < 0 表示连接已经关闭// 因为有数据当话 readBytes 要么 = 0,要么 > 0else if (readBytes < 0) {key.cancel();sc.close();}}}}private void doConnect() throws IOException {/*因为 socketChannel 是非阻塞的所以当 socketChannel.connect 执行完后:1、TCP 的三次握手可能还没有完成,所以需要关注 OP_CONNECT 事件2、TCP 的三次握手也完成了,那么就需要关注 OP_READ 事件*/if (socketChannel.connect(new InetSocketAddress(host, port))) {socketChannel.register(selector, SelectionKey.OP_READ);} else {socketChannel.register(selector, SelectionKey.OP_CONNECT);}}// 写数据对外暴露的 APIpublic void sendMsg(String message) throws Exception {doWrite(socketChannel, message);}private void doWrite(SocketChannel channel, String message) throws IOException {// 将消息编码为字节数组byte[] bytes = message.getBytes();// 根据数组容量创建 ByteBufferByteBuffer writeBuffer = ByteBuffer.allocate(bytes.length);// 将字节数组复制到缓冲区writeBuffer.put(bytes);// flip 操作writeBuffer.flip();// 发送缓冲区的字节数组/* 关心事件和读写网络并不冲突 */channel.write(writeBuffer);}public void stop() {started = false;}}
附录:Buffer 详解
重要属性
capacity
作为一个内存块,Buffer有一个固定的大小值,也叫“capacity”.你只能往里写capacity个byte、long,char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。
position
当你写数据到Buffer中时,position表示当前能写的位置。初始的position值为0.当一个byte、long等数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity – 1.
当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
limit
在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。
当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
Buffer 的分配
要想获得一个 Buffer 对象首先要进行分配。 每一个 Buffer 类都有 allocate 方法(可以在堆上分配,也可以在直接内存上分配)。
分配 48 字节 capacity 的 ByteBuffer 的例子:ByteBuffer buf = ByteBuffer.allocate(48);
分配一个可存储 1024 个字符的 CharBuffer 的例子:CharBuffer buf = CharBuffer.allocate(1024);
wrap方法:把一个 byte 数组或 byte 数组的一部分包装成 ByteBuffer:
ByteBuffer wrap(byte [] array)
ByteBuffer wrap(byte [] array, int offset, int length)
直接内存
HeapByteBuffer 与 DirectByteBuffer,在原理上,前者可以看出分配的 buffer 是在 heap 区域的,其实真正 flush 到远程的时候会先拷贝到直接内存,再做下一步操作;在 NIO 的框架下,很多框架会采用 DirectByteBuffer 来操作,这样分配的内存不再是在 java heap 上,经过性能测试,可以得到非常快速的网络交互,在大量的网络交互下,一般速度会比 HeapByteBuffe r要快速好几倍。
直接内存(Direct Memory):并不是虚拟机运行时数据区的一部分,也不是 Java 虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用,而且也可能导致 OutOfMemoryError 异常出现。
NIO 可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里面的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
直接内存(堆外内存)与堆内存比较
- 直接内存申请空间耗费更高的性能,当频繁申请到一定量时尤为明显
- 直接内存 IO 读写的性能要优于普通的堆内存,在多次读写操作的情况下差异明显
Buffer 的读写
向 Buffer 中写数据
写数据到Buffer有两种方式:
- 读取 Channel 写到 Buffer:
int bytesRead = inChannel.read(buf); // read into buffer. 通过 Buffer 的 put() 方法写到 Buffer 里:
buf.put(127);flip() 方法
flip 方法将 Buffer 从写模式切换到读模式。调用 flip() 方法会将 position 设置为 0,并将 limit 设置成之前 position 的值。
换句话说,position 现在用于标记读的位置,limit 表示之前写进了多少个 byte、char 等, 现在能读取多少个 byte、char 等。从 Buffer 中读取数据
从 Buffer 中读取数据有两种方式:
从 Buffer 读取数据写入到 Channel:
int bytesWritten = inChannel.write(buf);使用 get() 方法从 Buffer 中读取数据:
byte aByte = buf.get();使用 Buffer 读写数据常见步骤
写入数据到 Buffer
- 调用 flip() 方法
- 从 Buffer 中读取数据
- 调用 clear() 方法或者 compact() 方法,准备下一次的写入
当向 buffer 写入数据时,buffer 会记录下写了多少数据。一旦要读取数据,需要通过 flip() 方法将 Buffer 从写模式切换到读模式。在读模式下,可以读取之前写入到 buffer 的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用 clear() 或 compact() 方法。clear() 方法会清空整个缓冲区。compact() 方法只会清除已经读过的数据。
其他常用操作
绝对读写
put(int index, byte b):绝对写,向 byteBuffer 底层的 bytes 中下标为 index 的位置插入 byte b,不改变 position 的值。get(int index):属于绝对读,读取 byteBuffer 底层的 bytes 中下标为 index 的 byte,不改变 position 的值。
rewind() 方法
Buffer.rewind() 将 position 设回 0,所以你可以重读 Buffer 中的所有数据。limit 保持不变,仍然表示能从 Buffer 中读取多少个元素(byte、char等)。
clear() 与 compact() 方法
一旦读完 Buffer 中的数据,需要让 Buffer 准备好再次被写入。可以通过 clear() 或 compact() 方法来完成。
如果调用的是 clear() 方法,position 将被设回 0,limit 被设置成 capacity 的值。换句话说,Buffer 被清空了。Buffer 中的数据并未清除,只是这些标记告诉我们可以从哪里开始往 Buffer 里写数据。
如果 Buffer 中有一些未读的数据,调用 clear() 方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。
如果 Buffer 中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用 compact() 方法。
compact() 方法将所有未读的数据拷贝到 Buffer 起始处。然后将 position 设到最后一个未读元素正后面。limit 属性依然像 clear() 方法一样,设置成capacity。现在 Buffer 准备好写数据了,但是不会覆盖未读的数据。
mark() 与 reset() 方法
通过调用 Buffer.mark() 方法,可以标记 Buffer 中的一个特定 position。之后可以通过调用 Buffer.reset() 方法恢复到这个 position。例如:
buffer.mark(); // call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); // set position back to mark.
equals() 与 compareTo() 方法
可以使用 equals() 和 compareTo() 方法两个Buffer。
equals()
当满足下列条件时,表示两个 Buffer 相等:
- 有相同的类型(byte、char、int等)。
- Buffer 中剩余的 byte、char 等的个数相等。
- Buffer 中所有剩余的 byte、char 等都相同。
如你所见,equals 只是比较 Buffer 的一部分,不是每一个在它里面的元素都比较。实际上,它只比较 Buffer 中的剩余元素。
compareTo() 方法
compareTo() 方法比较两个 Buffer 的剩余元素(byte、char 等), 如果满足下列条件,则认为一个 Buffer “小于” 另一个 Buffer:
- 第一个不相等的元素小于另一个 Buffer 中对应的元素 。
- 所有元素都相等,但第一个 Buffer 比另一个先耗尽(第一个Buffer的元素个数比另一个少)
Buffer 方法总结
| limit(), limit(10) | 其中读取和设置这4个属性的方法的命名和jQuery中的val(),val(10)类似,一个负责get,一个负责set | | —- | —- | | reset() | 把position设置成mark的值,相当于之前做过一个标记,现在要退回到之前标记的地方 | | clear() | position = 0;limit = capacity;mark = -1; 有点初始化的味道,但是并不影响底层byte数组的内容 | | flip() | limit = position;position = 0;mark = -1; 翻转,也就是让flip之后的position到limit这块区域变成之前的0到position这块,翻转就是将一个处于存数据状态的缓冲区变为一个处于准备取数据的状态 | | rewind() | 把position设为0,mark设为-1,不改变limit的值 | | remaining() | return limit - position;返回limit和position之间相对位置差 | | hasRemaining() | return position < limit返回是否还有未读内容 | | compact() | 把从position到limit中的内容移到0到limit-position的区域内,position和limit的取值也分别变成limit-position、capacity。如果先将positon设置到limit,再compact,那么相当于clear() | | get() | 相对读,从position位置读取一个byte,并将position+1,为下次读写作准备 | | get(int index) | 绝对读,读取byteBuffer底层的bytes中下标为index的byte,不改变position | | get(byte[] dst, int offset, int length) | 从position位置开始相对读,读length个byte,并写入dst下标从offset到offset+length的区域 | | put(byte b) | 相对写,向position的位置写入一个byte,并将postion+1,为下次读写作准备 | | put(int index, byte b) | 绝对写,向byteBuffer底层的bytes中下标为index的位置插入byte b,不改变position | | put(ByteBuffer src) | 用相对写,把src中可读的部分(也就是position到limit)写入此byteBuffer | | put(byte[] src, int offset, int length) | 从src数组中的offset到offset+length区域读取数据并使用相对写写入此byteBuffer |
附录:BIO 实战-手写 RPC 框架
为什么要有RPC?
我们最开始开发的时候,一个应用一台机器,将所有功能都写在一起,比如说比较常见的电商场景,服务之间的调用就是我们最熟悉的普通本地方法调用。
随着我们业务的发展,我们需要提示性能了,我们会怎么做?将不同的业务功能放到线程里来实现异步和提升性能,但本质上还是本地方法调用。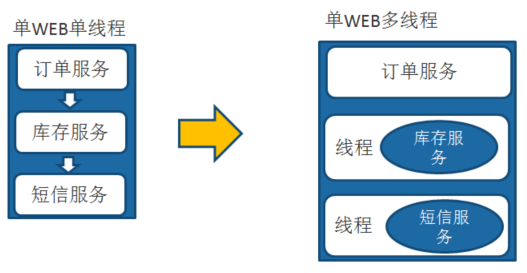
但是业务越来越复杂,业务量越来越大,单个应用或者一台机器的资源是肯定背负不起的,这个时候,我们会怎么做?将核心业务抽取出来,作为独立的服务,放到其他服务器上或者形成集群。这个时候就会请出 RPC,系统变为分布式的架构。
为什么说千万级流量分布式、微服务架构必备的 RPC 框架?和 LocalCall 的代码进行比较,因为引入 RPC 框架对我们现有的代码影响最小,同时又可以帮我们实现架构上的扩展。现在的开源 RPC 框架,有什么?Dubbo,gRPC 等等
当服务越来越多,各种 RPC 之间的调用会越来越复杂,这个时候我们会引入中间件,比如说 MQ、缓存,同时架构上整体往微服务去迁移,引入了各种比如容器技术 Docker,DevOps 等等。最终会变为如图所示来应付千万级流量,但是不管怎样,RPC 总是会占有一席之地。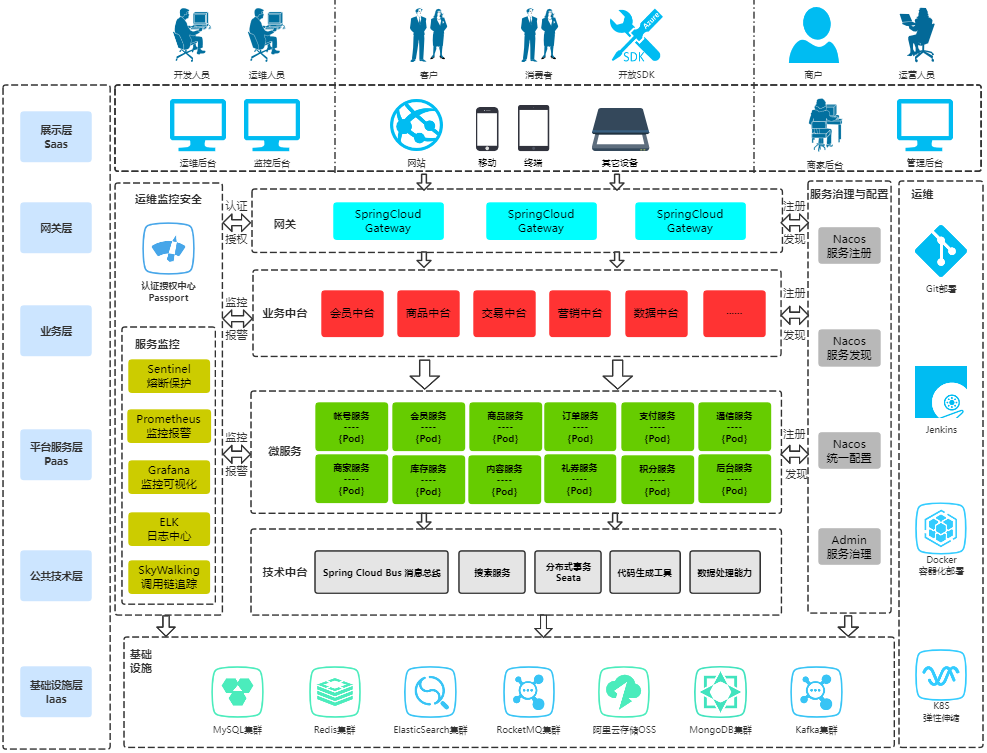
什么是 RPC?
RPC(Remote Procedure Call,远程过程调用),它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络的技术。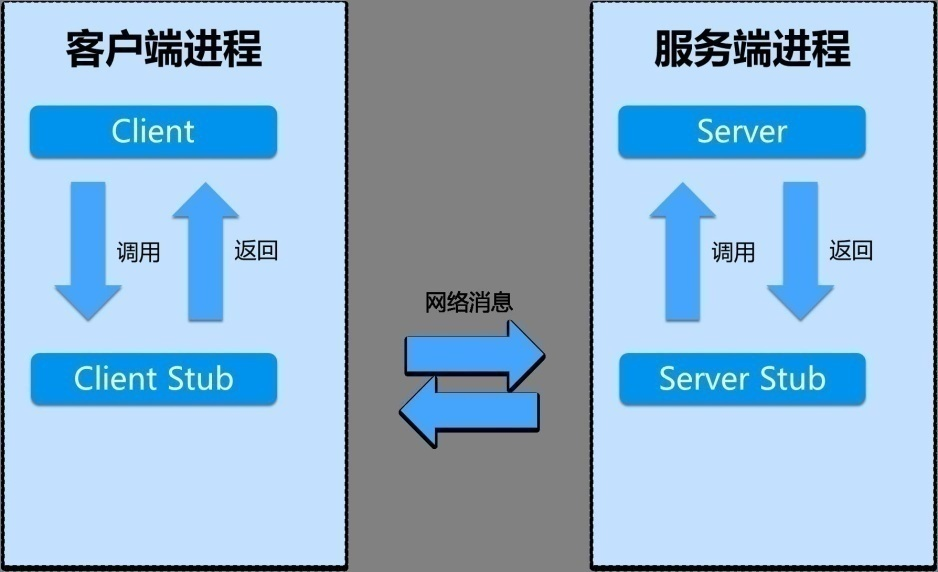
一次完整的 RPC 同步调用流程:
- 服务消费方(client)以本地调用方式调用客户端存根;
- 什么叫客户端存根?就是远程方法在本地的模拟对象,一样的也有方法名,也有方法参数,client stub 接收到调用后负责将方法名、方法的参数等包装,并将包装后的信息通过网络发送到服务端;
- 服务端收到消息后,交给代理存根在服务器的部分后进行解码为实际的方法名和参数
- server stub 根据解码结果调用服务器上本地的实际服务;
- 本地服务执行并将结果返回给 server stub;
- server stub 将返回结果打包成消息并发送至消费方;
- client stub 接收到消息,并进行解码;
- 服务消费方得到最终结果。
RPC 框架的目标就是要中间步骤都封装起来,让我们进行远程方法调用的时候感觉到就像在本地方法调用一样。
RPC 和 HTTP
RPC 字面意思就是远程过程调用,只是对不同应用间相互调用的一种描述,一种思想。具体怎么调用?实现方式可以是最直接的 TCP 通信,也可以是 HTTP 方式,在很多的消息中间件的技术书籍里,甚至还有使用消息中间件来实现 RPC 调用的,我们知道的 dubbo 是基于 TCP 通信的,gRPC 是 Google 公布的开源软件,基于最新的 HTTP 2.0 协议,底层使用到了 Netty 框架的支持。所以总结来说,RPC 和 HTTP 是完全两个不同层级的东西,他们之间并没有什么可比性。
实现RPC框架
实现RPC框架需要解决的那些问题
代理问题
代理本质上是要解决什么问题?要解决的是被调用的服务本质上是远程的服务,但是调用者不知道也不关心,调用者只要结果,具体的事情由代理的那个对象来负责这件事。既然是远程代理,当然是要用代理模式了。
代理(Proxy)是一种设计模式,即通过代理对象访问目标对象。这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。那我们这里额外的功能操作是干什么,通过网络访问远程服务。
JDK 的代理有两种实现方式:静态代理和动态代理。
序列化问题
序列化问题在计算机里具体是什么?我们的方法调用,有方法名,方法参数,这些可能是字符串,可能是我们自己定义的 Java 的类,但是在网络上传输或者保存在硬盘的时候,网络或者硬盘并不认得什么字符串或者 javabean,它只认得二进制的 01 串,怎么办?要进行序列化,网络传输后要进行实际调用,就要把二进制的 01 串变回我们实际的 Java 的类,这个叫反序列化。Java 里已经为我们提供了相关的机制 Serializable。
通信问题
我们在用序列化把东西变成了可以在网络上传输的二进制的 01 串,但具体如何通过网络传输?使用 JDK 为我们提供的 BIO。
登记的服务实例化
登记的服务有可能在我们的系统中就是一个名字,怎么变成实际执行的对象实例,当然是使用反射机制。
反射机制是什么?
反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
反射机制能做什么
反射机制主要提供了以下功能:
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法;
- 在运行时调用任意一个对象的方法;
- 生成动态代理。

若有收获,就点个赞吧
0 人点赞
