Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into “regression” and “classification” problems.
In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function.
In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house “sells for more or less than the asking price.” Here we are classifying the houses based on price into two discrete categories.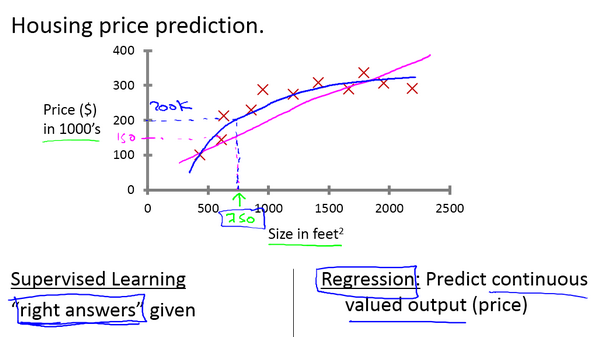
Example 2:
(a) Regression - Given a picture of a person, we have to predict their age on the basis of the given picture
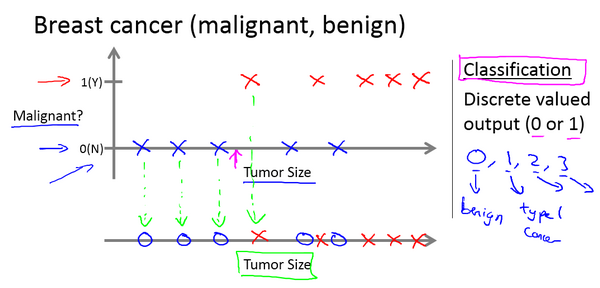
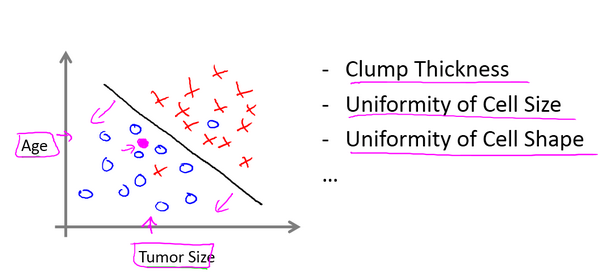
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
所谓监督学习(Supervised Learning),就是基于标记数据的学习。
本问题举了两个例子,一个回归问题(Regression),房屋的价格与面积的关系,是连续数据上的模型构建问题;
另一个分类问题(Classification),肿瘤是否恶性与肿瘤大小的关系,是离散数据上的问题。

若有收获,就点个赞吧
0 人点赞
