往返时间的估计与超时
TCP 如同前面节所讲的 rdt 协议一样,它采用超时/重传机制来处理报文段的丢失问题。尽管这在概念上简单,但是当在如 TCP 这样的实际协议中实现超时/重传机制时还是会产生许多微妙的问题。也许最明显的一个问题就是超时间隔长度的设置。
显然,超时间隔必须大于该连接的往返时间(RTT),即从一个报文段发出到它被确认的时间。否则会造成不必要的重传。但是这个时间间隔到底应该是多大呢?刚开始时应如何估计往返时间呢?是否应该为所有未确认的报文段各设一个定时器?
问题竟然如此之多!我们在本节中的讨论有关 TCP 的工作以及关于管理 TCP 定时器的建议。
1. 估计往返时间
我们开始学习 TCP 定时器的管理问题,要考虑一下 TCP 是如何估计发送方与接收方之间往返时间的,这是通过如下方法完成的。
报文段的样本 RTT (表示为 SampleRTT)就是从某报文段被发出(即交给 IP)到对该报文段的确认被收到之间的时间量。大多数 TCP 的实现仅在某个时刻做一次SampleRTT 测量,而不是为每个发送的报文段测量一个 SampleRTT。这就是说,在任意时刻,仅为一个已发送的但目前尚未被确认的报文段估计 SampleRTT,从而产生一个接近每个 RTT 的新 SampleRTT 值。另外,TCP 决不为已被重传的报文段计算 SampleRTT;它仅为传输一次的报文段测量 SampleRTT。

显然,由于路由器的拥塞和端系统负载的变化,这些报文段的 SampleRTT 值会随之波动。由于这种波动,任何给定的 SampleRTT 值也许都是非典型的。因此,为了估计一个典型的 RTT,自然要采取某种对 SampleRTT 取平均的办法。TCP 维持一个 SampleRTT 均值(称为 EstimatedRTT)。 一旦获得一个新 SampleRTT时,TCP 就会根据下列公式来更新 EstimatedRTT:
.EstimatedRTT%2Ba.SampleRTT%7D%0A#card=math&code=%5Ctext%7BEstimatedRTT%3D%281-a%29.EstimatedRTT%2Ba.SampleRTT%7D%0A&id=PxpjH)

上面的公式是以编程语言的语句方式给出的,即 EstimatedRTT 的新值是由以前的 EstimatedRTT 值与 SampleRTT 新值加权组合而成的。上面的权值 值给的参考值为
,所以上面的公式就为:
.EstimatedRTT%2B0.125.SampleRTT%7D%0A#card=math&code=%5Ctext%7BEstimatedRTT%3D%281-0.125%29.EstimatedRTT%2B0.125.SampleRTT%7D%0A&id=yutlB)
除了估算 RTT 外,测量 RTT 的变化也是有价值的。RTT 的偏差被定义为 DevRTT,用于估算 SampleRTT 一般会偏离 EstimatedRTT 的程度:
%20.%20DevRTT%20%2Bb%20.%20%7C%20SampleRTT%20-%20EstimatedRTT%20%7C%7D%0A#card=math&code=%5Ctext%7BDevRTT%20%3D%20%281%20-b%29%20.%20DevRTT%20%2Bb%20.%20%7C%20SampleRTT%20-%20EstimatedRTT%20%7C%7D%0A&id=HsJ4B)
如果 SampleRTT 值波动较小,那么 DevRTT 的值就会很小;另一方面,如果波动很大,那么 DevRTT 的值就会很大。b 的推荐值为 0. 25。
2. 设置和管理重传超时间隔
假设已经给岀了 EstimatedRTT 值和 DevRTT 值,那么 TCP 超时间隔应该用什么值呢? 很明显,超时间隔应该大于等于 EstimatedRTT。否则,将造成不必要的重传。但是超时间隔也不应该比 EstimatedRTT 大太多,否则当报文段丢失时,TCP 不能很快地重传该报文段,导致数据传输时延大。
因此要求将超时间隔设为 EstimatedRTT 加上一定余量。当 SampleRTT 值波动较大时,这个余量应该大些;当波动较小时,这个余量应该小些。因此,DevRTT 值应该在这里发挥作用了。在 TCP 的确定重传超时间隔的方法中,所有这些因素都考虑到了:
可靠数据传输
前面讲过,因特网的网络层服务(IP 服务)是不可靠的。IP 不保证数据报的交付, 不保证数据报的按序交付,也不保证数据报中数据的完整性。产生差错的可能情况如下:
- 丢失:对于 IP 服务,数据报能够溢出路由器缓存而永远不能到达目的地
- 乱序:数据报也可能是乱序到达
- 损坏:数据报中的比特可能损坏(由 0 变为 1 或者相反)。
由于运输层报文段是被 IP 数据报携带着在网络中传输的,所以运输层的报文段也会遇到这些问题。
TCP 在 IP 不可靠的尽力而为服务之上创建了一种可靠数据传输服务(reliable data transfer service)。 TCP 的可靠数据传输服务确保一个进程从其接收缓存中读出的数据流是无损坏、无间隙、非冗余和按序的数据流;即该字节流与连接的另一方端系统发送出的字节流是完全相同。
在我们前面研发可靠数据传输技术时,曾假定每一个已发送但未被确认的报文段都与一个定时器相关联,这在概念上是最简单的。虽然这在理论上很好,但定时器的管理却需要相当大的开销。因此,推荐的定时器管理过程仅使用单一的重传定时器,即使有多个已发送但还未被确认的报文段。在本节中描述的 TCP 协议遵循了这种单一定时器的推荐。
我们将以两个递增的步骤来讨论 TCP 是如何提供可靠数据传输的。我们先给出一个 TCP 发送方的高度简化的描述,该发送方只用超时来恢复报文段的丢失;然后再给岀一个更全面的描述,该描述中除了使用超时机制外,还使用冗余确认技术。在接下来的讨论中,我们假定数据仅向一个方向发送,即从主机 A 到主机 B,且主机 A 在发送一个大文件。
TCP 发送文件事件
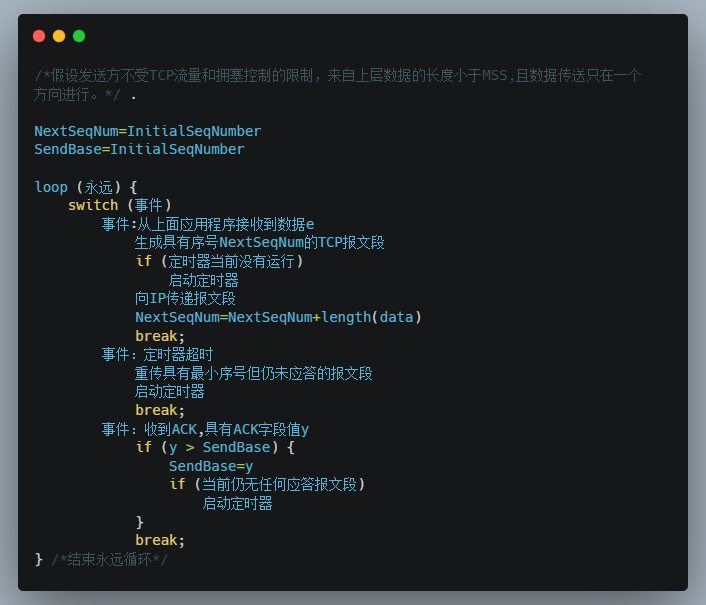
下面给岀了一个 TCP 发送方高度简化的描述。我们看到在 TCP 发送方有 3 个与发送和重传有关的主要事件:
- 从上层应用程序接收数据;
- 定时器超时;
- 收到 ACK。
// 假设发送方不受TCP流量和拥塞控制的限制,来自上层数据的长度小于MSS,// 且数据传送只在一个方向进行NextSeqNum = InitialSeqNumberSendBase = InitialSeqNumberloop (永远) {switch (事件)事件1: 从上面应用程序接收到数据e {生成具有序号NextSeqNum的TCP报文段if (定时器当前没有运行)启动定时器向IP传递报文段NextSeqNum = NextSeqNum+length(data)}事件2: 定时器超时 {重传具有最小序号但仍未答应的报文段启动定时器break;}事件3: 收到ACK,具有ACK字段值y {if (y > SendBase) {SendBase=yif (当前仍未任何答应报文段)启动定时器}break;}} // 结束永远循环
下面就详细看一下这 3 个事件
 事件1:从上面应用程序收到数据 e
事件1:从上面应用程序收到数据 e
一旦第一个主要事件发生,TCP 从应用程序接收数据,将数据封装在一个报文段中,并把该报文段交给 IP。注意到每一个报文段都包含一个序号,这个序号就是该
报文段第一个数据字节的字节流编号。
还要注意到如果定时器还没有为某些其他报文段而运行,则当报文段被传给 IP 时,TCP就启动该定时器。(将定时器想象为与最早的未被确认的报文段相关联是有帮助的),该定时器的过期间隔是 TimeoutInterval。

 事件2:超时
事件2:超时
第二个主要事件是超时。TCP 通过重传引起超时的报文段来响应超时事件。然后 TCP 重启定时器。
 事件3:收到 ACK
事件3:收到 ACK
TCP 发送方必须处理的第三个主要事件是,到达一个来自接收方的确认报文段(ACK)(更确切地说,是一个包含了有效 ACK 字段值的报文段)。当该事件发生时,TCP 将 ACK 的值 y 与它的变量 SendBase 进行比较。TCP 状态变量 SendBase 是最早未被确认的字节的序号。
因此 SendBase-1 是指接收方已正确按序接收到的数据的最后一个字节的序号,如前面指出的那样,TCP 采用累积确认,所以 y 确认了字节编号在 y 之前的所有字节都已经收到。

- 如果 y>SendBase,则该 ACK 是在确认一个或多个先前未被确认的报文段。因此发送方更新它的 SendBase 变量;
- 如果当前有未被确认的报文段,TCP 还要重新启动定时器。
1. 一些有趣的情况
我们刚刚描述了一个关于 TCP 如何提供可靠数据传输的高度简化的版本。但即使这种高度简化的版本,仍然存在着许多微妙之处。为了较好地感受该协议的工作过程,我们来看几种简单情况
- 下图描述了第一种情况

主机 A 向主机 B 发送一个报文段。假设该报文段的序号是 92,而且包含 8 字节数据。在发岀该报文段之后,主机 A 等待一个来自主机 B 的确认号为 100 的报文段。虽然 A 发出的报文段在主机 B 上被收到,但从主机 B 发往主机 A 的确认报文丢失了。在这种情况下,超时事件就会发生,主机 A 会重传相同的报文段。当然,当主机 B 收到该重传的报文段时,它将通过序号发现该报文段包含了早已收到的数据。因此,主机 B 中的 TCP 将丢弃该重传的报文段中的这些字节。
- 下图描述了第二种情况

主机 A 连续发回了两个报文段。第一个报文段序号是 92,包含 8 字节数据;第二个报文段序号是 100,包含 20 字节数据。假设两个报文段都完好无损地到达主机 B,并且主机 B 为每一个报文段分别发送一个确认。
第一个确认报文的确认号是 100,第二个确认报文的确认号是 120。现在假设在超时之前这两个报文段中没有一个确认报文到达主机 A。当超时事件发生时,主机A 重传序号 92 的第一个报文段,并重启定时器。只要第二个报文段的 ACK 在新的超时发生以前到达,则第二个报文段将不会被重传。
- 下图描述了第三种情况

在第三种也是最后一种情况,假设主机 A 与在第二种情况中完全一样,发送两个报文段。第一个报文段的确认报文在网络丢失,但在超时事件发生之前主机 A 收到一个确认号为 120 的确认报文。主机 A 因而知道主机 B 已经收到了序号为 119 及之前的所有字节;所以主机 A 不会重传这两个报文段中的任何一个。
2. 超时间隔加倍
我们现在讨论一下在大多数 TCP 实现中所做的一些修改。首先关注的是在定时器时限过期后超时间隔的长度。在这种修改中,每当超时事件发生时,如前所述,发送方 TCP 重传具有最小序号的还未被确认的报文段。
只是每次 TCP 重传时都会将下一次的超时间隔设为先前值的两倍,而不是用从 EstimatedRTT 和 DevRTT 推算出的值。例如,假设当定时器第一次过期时,与最早的未被确认的报文段相关联的 Timeoutinterval 是 0. 75 秒。TCP 就会重传该报文段,并把新的过期时间设置为 1.5 秒。如果 1.5 秒后定时器又过期了,则 TCP 将再次重传该报文段,并把过期时间设置为 3.0 秒。因此,超时间隔在每次重传后会呈指数型增长。然而,每当定时器在另两个事件(即收到上层应用的数据和收到ACK)中的任意一个启动时,Timeoutinterval 由最近的 EstimatedRTT 值与 DevRTT 值推算得到。
这种修改提供了一个形式受限的拥塞控制。定时器过期很可能是由网络拥塞引起的,即太多的分组到达源与目的地之间路径上的一台(或多台)路由器的队列中,造成分组丢失或长时间的排队时延。
在拥塞的时候,如果源持续重传分组,会使拥塞更加严重。相反,TCP 使用更文雅的方式,每个发送方的重传都是经过越来越长的时间间隔后进行的。
3. 快速重传
超时触发重传存在的问题之一是超时周期可能相对较长。当一个报文段丢失时,这种长超时周期迫使发送方延迟重传丢失的分组,因而增加了端到端时延。幸运的
是,发送方通常可在超时事件发生之前通过注意所谓冗余 ACK 来较好地检测到丢包情况。
冗余 ACK (duplicate ACK)就是再次确认某个报文段的 ACK,而发送方先前已经收到对该报文段的确认。要理解发送方对冗余 ACK 的响应,我们必须首先看一
下接收方为什么会发送冗余 ACK。
下表总结了 TCP 接收方的 ACK 生成策略
| 事件 | TCP接收方动作 |
|---|---|
| 具有所期望序号的按序报文段到达。所 有在期望序号及以前的数据都已经被确认 |
延迟的 ACK。对另一个按序报文段的到达最多等待 500ms。如果下 一个按序报文段在这个时间间隔内没有到达,则发送一个 ACK |
| 具有所期望序号的按序报文段到达。另 一个按序报文段等待 ACK 传输 |
立即发送单个累积 ACK,以确认两个按序报文段 |
| 比期望序号大的失序报文段到达。检测 出间隔 |
立即发送冗余 ACK,指示下一个期待字节的序号(其为间隔的低端 的序号) |
| 能部分或完全填充接收数据间隔的报文 段到达 |
倘若该报文段起始于间隔的低端,则立即发送 ACK |
当 TCP 接收方收到一个具有这样序号的报文段时,即其序号大于下一个所期望的、按序的报文段,它检测到了数据流中的一个间隔,这就是说有报文段丢失。这
个间隔可能是由于在网络中报文段丢失或重新排序造成的。
因为 TCP 不使用否定确认,所以接收方不能向发送方发回一个显式的否定确认。相反,它只是对已经接收到的最后一个按序字节数据进行重复确认(即产生一个冗余 ACK)即可。
因为发送方经常一个接一个地发送大量的报文段,如果一个报文段丢失,就很可能引起许多一个接一个的冗余 ACK。如果 TCP 发送方接收到对相同数据的 3 个冗余 ACK,它把这当作一种指示,说明跟在这个已被确认过 3 次的报文段之后的报文段已经丢失。
一旦收到 3 个冗余 ACK, TCP 就执行快速重传(fast retransmit),即在该报文段的定时器过期之前重传丢失的报文段。对于采用快速重传的 TCP,可用下列代
码片段代替之前谈到的 ACK 收到事件:
事件:收到ACK,具有ACK字段值yif (y > SendBase) {SendBase=yif (当前仍无任何应答报文段)启动定时器}else { // 对已经确认的报文段的一个冗余ACK对y收到的冗余ACK数加1if (对y==3收到的冗余ACK数) // TCP快速重传重新发送具有序号y的报文段}break;
前面讲过,当在如 TCP 这样一个实际协议中实现超时/重传机制时,会产生许多微妙的问题。上面的过程是在超过 20 年的 TCP 定时器使用经验的基础上演化而来的,读者应当理解实际情况确实是这样的。
4. 是回退N步还是选择重传
考虑下面这个问题来结束有关 TCP 差错恢复机制的学习:TCP 是一个 GBN 协议还是一个 SR 协议?前面讲过,TCP 确认是累积式的,正确接收但失序的报文段是不会被接收方逐个确认的。
因此,如下图所示,TCP 发送方仅需维持已发送过但未被确认的字节的最小序号(SendBase )和下一个要发送的字节的序号(NextSeqNum)。在这种意义下,TCP 看起来更像一个 GBN 风格的协议。但是 TCP 和 GBN 协议之间有着一些显著的区别。
许多 TCP 实现会将正确接收但失序的报文段缓存起来。另外考虑一下,当发送方发送的一组报文段 1, 2, …, N,并且所有的报文段都按序无差错地到达接收方时会发生的情况。
进一步假设对分组 n

对 TCP 提岀的一种修改意见是所谓的选择确认 (selective acknowledgment) 。它允许 TCP 接收方有选择地确认失序报文段,而不是累积地确认最后一个正确接收的有序报文段。当将该机制与选择重传机制结合起来使用时 (即跳过重传那些已被接收方选择性地确认过的报文段),TCP 看起来就很像我们通常的 SR 协议。因此,TCP 的差错恢复机制也许最好被分类为 GBN 协议与 SR 协议的混合体。

若有收获,就点个赞吧
0 人点赞
