在本节中,我们再次来学习 TCP。我们之前学习过,TCP 为运行在不同主机上的两个进程之间提供了可靠传输服务。TCP 的另一个关键部分就是其拥塞控制机制。
如在前一节所指出,TCP 必须使用端到端拥塞控制而不是使网络辅助的拥塞控制,因为 IP 层不向端系统提供显式的网络拥塞反馈。
TCP拥塞控制的3个问题
TCP 所采用的方法是让每一个发送方根据所感知到的网络拥塞程度来限制其能向连接发送流量的速率。如果一个 TCP 发送方感知从它到目的地之间的路径上没什么拥塞,则 TCP 发送方增加其发送速率;如果发送方感知沿着该路径有拥塞,则发送方就会降低其发送速率。但是这种方法提出了三个问题。
- 一个 TCP 发送方如何限制它向其连接发送流量的速率呢?
- 一个 TCP 发送方如何感知从它到目的地之间的路径上存在拥塞呢?
- 当发送方感知到端到端的拥塞时,采用何种算法来改变其发送速率呢?
 问题1:TCP 发送方是如何限制向其连接发送流量的?
问题1:TCP 发送方是如何限制向其连接发送流量的?
我们首先分析一下 TCP 发送方是如何限制向其连接发送流量的。之前在《流量控制》我们看到,TCP 连接的每一端都是由一个接收缓存、一个发送缓存和几个变量(LastByteRead、rwnd 等)组成。运行在发送方的 TCP 拥塞控制机制跟踪一个额外的变量,即拥塞窗口(congestion window)。

拥塞窗口表示为 cwnd,它对一个 TCP 发送方能向网络中发送流量的速率进行了限制。特别是,在一个发送方中未被确认的数据量不会超过 cwnd 与 rwnd 中的最小值,即
为了关注拥塞控制(与流量控制形成对比),我们后面假设 TCP 接收缓存足够大,以至可以忽略接收窗口的限制 (rwnd 趋于无穷大);因此在发送方中未被确认的数据量仅受限于 cwnd。我们还假设发送方总是有数据要发送,即在拥塞窗口中的所有报文段要被发送。
上面的约束限制了发送方中未被确认的数据量,因此间接地限制了发送方的发送速率。为了理解这一点,我们来考虑一个丢包和发送时延均可以忽略不计的连接。因此粗略地讲,在每个往返时间(RTT)的起始点,上面的限制条件允许发送方向该连接发送 cwnd 个字节的数据,在该 RTT 结束时发送方接收对数据的确认报文。因此,该发送方的发送速率大概是 cwnd/RTT 字节/秒。通过调节 cwnd 的值,发送方因此能调整它向连接发送数据的速率。
 问题2:TCP 发送方使用 TCP 丢包事件来感知它到目的地之间的路径存在拥塞
问题2:TCP 发送方使用 TCP 丢包事件来感知它到目的地之间的路径存在拥塞
我们接下来考虑 TCP 发送方是如何感知在它与目的地之间的路径上出现了拥塞的。我们将一个 TCP 发送方的 “丢包事件” 定义为:要么出现超时,要么收到来自接收方的 3 个冗余 ACK。当出现过度的拥塞时,在沿着这条路径上的一台(或多台)路由器的缓存会溢出,引起一个数据报(包含一个 TCP 报文段)被丢弃。丢弃的数据报接着会引起发送方的丢包事件(要么超时或收到 3 个冗余 ACK),发送方就认为在发送方到接收方的路径上出现了拥塞的指示。
考虑了拥塞检测问题后,我们接下来考虑网络没有拥塞这种更为乐观的情况,即没有出现丢包事件的情况。在此情况下,在 TCP 的发送方将收到对于以前未确认报文段的确认。如我们将看到的那样,TCP 将这些确认的到达作为一切正常的指示,即在网络上传输的报文段正被成功地交付给目的地,并使用确认来增加窗口的长度(及其传输速率)。
注意到如果确认以相当慢的速率到达(例如,如果该端到端路径具有高时延或包含一段低带宽链路),则该拥塞窗口将以相当慢的速率增加。在另一方面,如果确认以高速率到达, 则该拥塞窗口将会更为迅速地增大。因为 TCP 使用确认来触发(或计时)增大它的拥塞窗口长度,TCP 被说成是自计时(self-clocking)的。
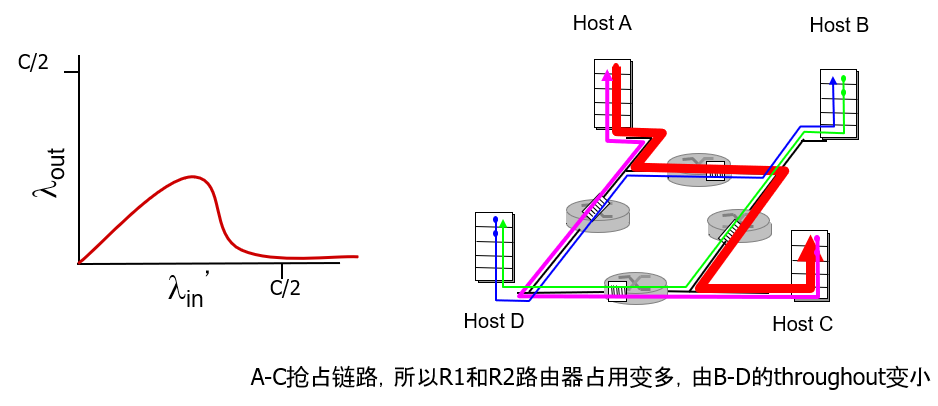
给定调节 cwnd 值以控制发送速率的机制,关键的问题依然存在:TCP 发送方怎样确定它应当发送的速率呢?如果众多 TCP 发送方总体上发送太快,它们能够拥塞网络,导致我们看到如下图所示的拥塞崩溃。
 问题3:当发送方感知到端到端的拥塞时,采用何种算法来改变其发送速率呢?
问题3:当发送方感知到端到端的拥塞时,采用何种算法来改变其发送速率呢?
事实上,为了应对在较早 TCP 版本下观察到的因特网拥塞崩溃,就研发了如下版本的 TCP。然而,如果 TCP 发送方过于谨慎,发送太慢,它们不能充分利用网络的带宽;这就是说,TCP 发送方能够以更高的速率发送而不会使网络拥塞。那么 TCP 发送方如何确定它们的发送速率,既使得网络不会拥塞,与此同时又能充分利用所有可用的带宽? TCP 发送方是显式地协作,或存在一种分布式方法使 TCP 发送方能够仅基于本地信息设置它们的发送速率? TCP 使用下列指导性原则回答这些问题:
- 一个丢失的报文段表意味着拥塞,因此当丢失报文段时应当降低 TCP 发送方的速率。从拥塞控制的观点看,该问题是 TCP 发送方应当如何减小它的拥塞窗口长度,即减小其发送速率,以应对这种推测的丢包事件。
- 一个确认报文段指示该网络正在向接收方交付发送方的报文段,因此,当对先前未确认报文段的确认到达时,能够增加发送方的速率。确认的到达被认为是一切顺利的隐含指示,即报文段正从发送方成功地交付给接收方,因此该网络不拥塞。拥塞窗口长度因此能够增加。
- 带宽探测。给定 ACK 指示源到目的地路径无拥塞,而丢包事件指示路径拥塞,TCP 调节其传输速率的策略是增加其速率以响应到达的 ACK,除非岀现丢包事件,此时才减小传输速率。因此,为探测拥塞开始出现的速率,TCP 发送方增加它的传输速率,从该速率后退,进而再次开始探测,看看拥塞开始速率是否发生了变化。TCP 发送方的行为也许类似于要求(并得到)越来越多糖果的孩子,直到最后告知他/她 “不行! ”,孩子后退一点,然后过一会儿再次开始提出请求。注意到网络中没有明确的拥塞状态信令,即 ACK 和丢包事件充当了隐式信号,并且每个 TCP 发送方根据异步于其他 TCP 发送方的本地信息而行动。
TCP拥塞控制算法解决上述问题
概述了 TCP 拥塞控制后,现在是我们考虑广受赞誉的 TCP 拥塞控制算法(TCP congestion control algorithm)细节的时候了,该算法包括 3 个主要部分:
- 慢启动;
- 拥塞避免;
- 快速恢复。
慢启动和拥塞避免是 TCP 的强制部分,两者的差异在于对收到的 ACK 做出反应时增加 cwnd 长度的方式。我们很快将会看到慢启动比拥塞避免能更快地增
加 cwnd 的长度(不要被名称所迷惑!)。快速恢复是推荐部分,对 TCP 发送方并非是必需的。
慢启动
当一条 TCP 连接开始时,cwnd 的值通常初始置为一个 MSS 的较小值,这就使得初始发送速率大约为 MSS/RTT。例如,如果 MSS = 500 字节且 RtT = 200ms,则
得到的初始发送速率大约只有 20kbps。由于对 TCP 发送方而言,可用带宽可能比 MSS/RTT大得多,TCP 发送方希望迅速找到可用带宽的数量。因此,在慢启动(slow-start)状态,cwnd 的值以 1 个MSS开始并且每当传输的报文段首次被确认就增加1个MSS。
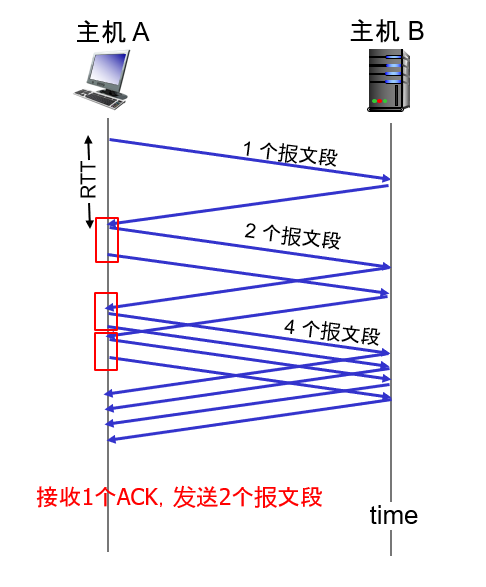
在上图所示的例子中,TCP 向网络发送第一个报文段并等待一个确认。当该确认到达时,TCP 发送方将拥塞窗口增加一个 MSS,并发送出两个最大长度的报文段。这两个报文段被确认,则发送方对每个确认报文段将拥塞窗口增加一个 MSS,使得拥塞窗口变为 4 个 MSS,并这样下去。这一过程每过一个 RTT,发送速率就翻番。因此,TCP 发送速率起始慢,但在慢启动阶段以指数增长。
但是,何时结束这种指数增长呢?慢启动对这个问题提供了几种答案。
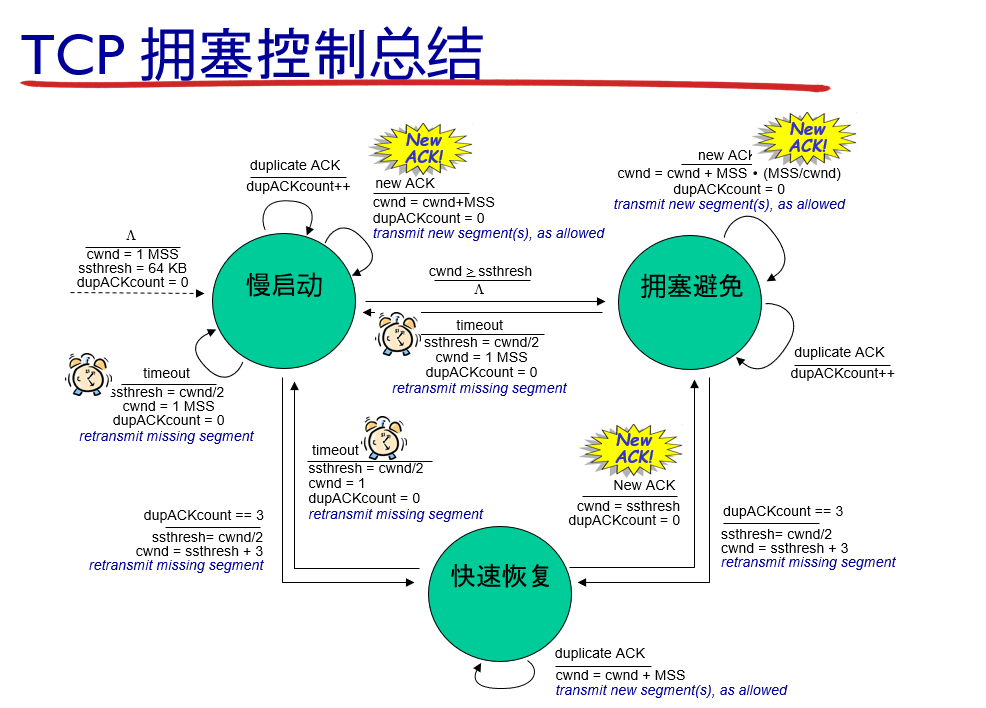
- 首先,如果存在一个由超时指示的丢包事件(即拥塞),TCP 发送方将 cwnd 设置为 1 并重新开始慢启动过程。它还将第二个状态变量的值 ssthresh (”慢启动阈值” 的速记)设置为 cwnd/2,即当检测到拥塞时将 ssthresh 置为拥塞窗口值的一半。
- 慢启动结束的第二种方式是直接与 ssthresh 的值相关联。因为当检测到拥塞时 ssthresh 设为 cwnd 的值一半,当到达或超过 ssthresh 的值时,继续使 cwnd 翻番可能有些鲁莽。因此,当 cwnd 的值等于 ssthresh 时,结束慢启动并且 TCP 转移到拥塞避免模式。我们将会看到,当进入拥塞避免模式时,TCP 更为谨慎地增加 cwnd。
- 最后一种结束慢启动的方式是,如果检测到 3 个冗余 ACK,这时 TCP 执行一种快速重传并进入快速恢复状态
慢启动中的 TCP 行为总结在下图中的 TCP 拥塞控制的 FSM 描述中。
拥塞避免
一旦进入拥塞避免状态,cwnd 的值大约是上次遇到拥塞时的值的一半,即距离拥塞可能并不遥远!因此,TCP 无法每过一个 RTT 再将 cwnd 的值翻番,而是采用了一种较为保守的方法,每个 RTT 只将 cwnd 的值增加一个 MSS。这能够以几种方式完成。
一种通用的方法是对于 TCP 发送方无论何时到达一个新的确认,就将 cwnd 增加一个 MSS ( MSS/cwnd)字节。例如,如果 MSS 是 1460 字节并且 cwnd 是 14600 字节,则在一个 RTT 内发送 10 个报文段。每个到达 ACK (假定每个报文段一个 ACK)增加 1/10MSS 的拥塞窗口长度,因此在收到对所有 10 个报文段的确认后,拥塞窗口的值将增加了一个 MSS。
但是何时应当结束拥塞避免的线性增长(每 RTT 1 MSS)呢?当出现超时时,TCP 的拥塞避免算法行为相同。与慢启动的情况一样,cwnd 的值被设置为 1 个 MSS,当丢包事件出现时,ssthresh 的值被更新为 cwnd 值的一半。然而,前面讲过丢包事件也能由一个三个冗余 ACK 事件触发。在这种情况下,网络继续从发送方向接收方交付报文段(就像由收到冗余 ACK 所指示的那样)。因此 TCP 对这种丢包事件的行为,相比于超时指示的丢包, 应当不那么剧烈:TCP 将 cwnd 的值减半(为使测量结果更好,计及已收到的 3 个冗余的 ACK 要加上 3 个 MSS),并且当收到 3 个冗余的 ACK,将 ssthresh 的值记录为 cwnd 的值的一半。接下来进入快速恢复状态。
快速恢复
在快速恢复中,对于引起 TCP 进入快速恢复状态的缺失报文段,对收到的每个冗余的 ACK, cwnd 的值增加一个 MSS。最终,当对丢失报文段的一个 ACK 到达时,TCP 在降低 cwnd 后进入拥塞避免状态。如果出现超时事件,快速恢复在执行如同在慢启动和拥塞避免中相同的动作后,迁移到慢启动状态:当丢包事件出现时,cwnd 的值被设置为 1 个 MSS,并且 ssthresh 的值设置为 cwnd 值的一半。
快速恢复是 TCP 推荐的而非必需的构件。有趣的是,一种称为 TCP Tahoe 的 TCP 早期版本,不管是发生超时指示的丢包事件,还是发生 3 个冗余 ACK 指示的丢包事件,都无条件地将其拥塞窗口减至 1 个 MSS,并进入慢启动阶段。TCP 的较新版本 TCP Reno,则综合了快速恢复。
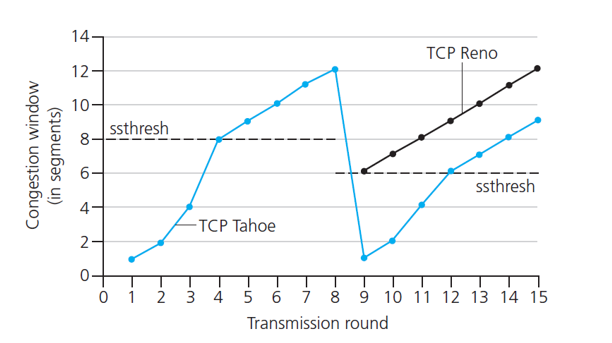
上图显示了 Reno 版 TCP 与 Tahoe 版 TCP 的拥塞控制窗口的演化情况。在该图中,阈值初始等于 8 个 MSS。在前 8 个传输回合,Tahoe 和 Reno 采取了相同的动作。
拥塞窗口在慢启动阶段以指数速度快速爬升,在第 4 轮传输时到达了阈值。然后拥塞窗口以线性速度爬升,直到在第 8 轮传输后出现 3 个冗余 ACK。注意到当该丢包事件发生时,拥塞窗口值为 12xMSS。于是 ssthresh 的值被设置为 0. 5 x cwnd = 6 x MSS。在 TCP Reno下,拥塞窗口被设置为 cwnd = 9MSS,然后线性地增长。在 TCP Tahoe 下,拥塞窗口被设置为 1 个 MSS,然后呈指数增长,直至到达 ssthresh 值为止,在这个点它开始线性增长。
TCP拥塞控制:回顾
在深入了解慢启动、拥塞避免和快速恢复的细节后,现在有必要退回来回顾一下全局。忽略一条连接开始时初始的慢启动阶段,假定丢包由 3 个冗余的 ACK 而不是超时指示,TCP 的拥塞控制是:每个 RTT 内 cwnd 线性(加性)增加 1MSS,然后出现 3 个冗余 ACK 事件时 cwnd 减半(乘性减)。因此,TCP 拥塞控制常常被称为加性增、乘性减(Additive- Increase, Multiplicative- Decrease, AIMD)拥塞控制方式。
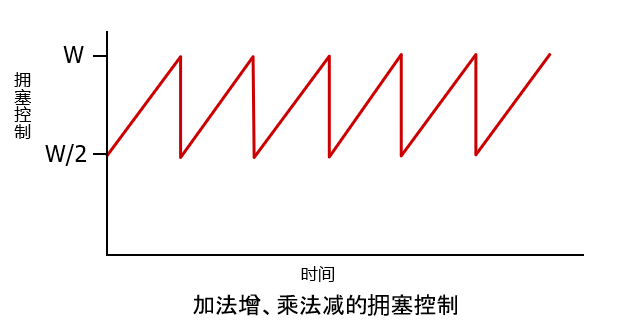
AIMD 拥塞控制引发了在上图中所示的 “锯齿” 行为,这也很好地图示了我们前面 TCP 检测带宽时的直觉,即 TCP 线性地增加它的拥塞窗口长度(因此增加其传输速率),直到出现 3 个冗余 ACK 事件。然后以 2 个因子来减少它的拥塞窗口长度,然后又开始了线性增长,探测是否还有另外的可用带宽。
TCP AIMD 算法基于大量的工程见解和在运行网络中的拥塞控制经验而开发。在 TCP 研发后的十年,理论分析显示 TCP 的拥塞控制算法用做一种分布式异步优化算法,使得用户和网络性能的几个重要方面被同时优化。
对TCP吞吐量的宏观描述
给岀 TCP 的锯齿状行为后,自然要考虑一个长存活期的 TCP 连接的平均吞吐量(即平均速率)可能是多少。在这个分析中,我们将忽略在超时事件后出现的慢启动阶段。(这些阶段通常非常短,因为发送方很快就以指数增长离开该阶段。)在一个特定的往返间隔内,TCP 发送数据的速率是拥塞窗口与当前 RTT 的函数。当窗口长度是 字节,且当前往返时间是 RTT 秒时,则 TCP 的发送速率大约是 w/RTT。于是,TCP 通过每经过 1 个 RTT 将
增加 1 个 MSS 探测出额外的带宽,直到一个丢包事件发生为止。当一个丢包事件发生时,用
表示
的值。假设在连接持续期间 RTT 和
几乎不变,那么 TCP 的传输速率在
#card=math&code=W%2F%282%5Ctimes%20RTT%29&id=VhiSi) 到
之间变化。
这些假设导出了 TCP 稳态行为的一个高度简化的宏观模型。当速率增长至 时,网络丢弃来自连接的分组;然后发送速率就会减半,进而每过一个 RTT 就发送速率增加 MSS/RTT,直到再次达到
为止。这一过程不断地自我重复。因为 TCP 吞吐量(即速率)在两个极值之间线性增长,所以我们有
通过这个高度理想化的 TCP 稳态动态性模型, 我们可以推出一个将连接的丢包率与可用带宽联系起来的有趣表达式。
经高带宽路径的TCP
认识到下列事实是重要的:TCP 拥塞控制已经演化了多年并仍在继续演化。以往对因特网有益的东西(那时大量的 TCP 连接承载的是 SMTP、FTP 和 Telnet 流量),不一定对当今 HTTP 主宰的因特网或具有难以想象的服务的未来因特网还是有益的。
TCP 继续演化的需求能够通过考虑网格和云计算应用所需要的高速 TCP 连接加以阐述。例如,考虑一条具有 1500 字节报文段和 100ms RTT 的 TCP 连接,假定我们要通过这条连接以 10Gbps 速率发送数据。
我们注意到使用上述 TCP 吞吐量公式,为了取得 10Gbps 吞吐量,平均拥塞窗口长度将需要是 83333 个报文段。
对如此大量的报文段,使我们相当关注这 83333 个传输中的报文段也许会丢失。在丢失的情况下,将会出现什么情况呢?或者以另一种方式说,这些传输的报文段能以何种比例丢失,使得在下图中列出的 TCP 拥塞控制算法仍能取得所希望的 10Gbps 速率?
下面这个公式,是计算一条连接的平均吞吐量的第 2 种方法,该公式作为丢包率(L)、往返时间(RTT)和最大报文段长度(MSS)的函数:
使用该公式,我们能够看到,为了取得 10Gbps 的吞吐量,今天的 TCP 拥塞控制算法仅能容忍 2x10-10 的报文段丢失概率(或等价地说,对每 5000000000 个报文段有一个丢包),这是一个非常低的值。
公平性
考虑 K 条 TCP 连接,每条都有不同的端到端路径,但是都经过一段传输速率为 R bps 的瓶颈链路。(所谓瓶颈链路,是指对于每条连接,沿着该连接路径上的所有其他段链路都不拥塞,而且与该瓶颈链路的传输容量相比,它们都有充足的传输容量)。
假设每条连接都在传输一个大文件,而且无 UDP 流量通过该段瓶颈链路。如果每条连接的平均传输速率接近 R/K,即每条连接都得到相同份额的链路带宽,则认为该拥塞控制机制是公平的。
TCP 的 AIMD 算法公平吗?尤其是假定可在不同时间启动并因此在某个给定的时间点可能具有不同的窗口长度情况下,对这些不同的 TCP 连接还是公平的吗?TCP 趋于在竞争的多条 TCP 连接之间提供对一段瓶颈链路带宽的平等分享,下面我们来看一下。
我们考虑有两条 TCP 连接共享一段传输速率为 R 的链路的简单例子,如下图中所示。
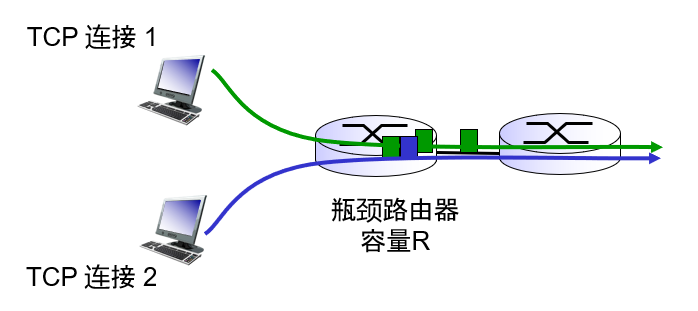
我们将假设这两条连接有相同的 MSS 和 RTT(这样如果它们有相同的拥塞窗口长度,就会有相同的吞吐量),它们有大量的数据要发送,且没有其他 TCP 连接
或 UDP 数据报穿越该段共享链路。我们还将忽略 TCP 的慢启动阶段,并假设 TCP 连接一直按 CA 模式(AIMD)运行。下图描绘了两条 TCP 连接实现的吞吐量情况。
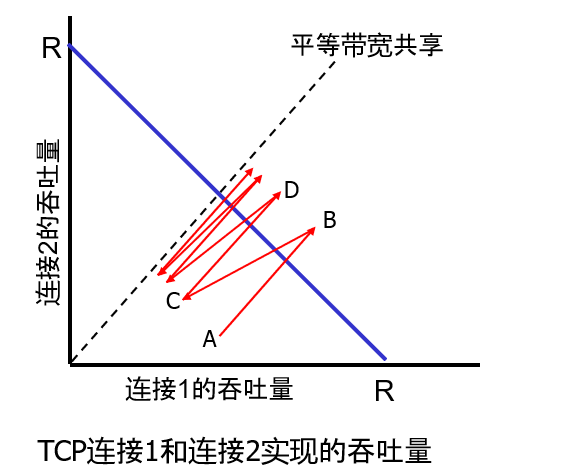
如果 TCP 要在这两条 TCP 连接之间平等地共享链路带宽,那么实现的吞吐量曲线应当是从原点沿45°。方向的箭头向外辐射(平等带宽共享)。理想情况是,两
个吞吐量的和应等于尺。(当然,每条连接得到相同但容量为 0 的共享链路容量并非我们所期望的情况!)所以我们的目标应该是使取得的吞吐量落在上图中平等带宽共享曲线与全带宽利用曲线的交叉点附近的某处。
假定 TCP 窗口长度是这样的,即在某给定时刻,连接 1 和连接 2 实现了由上图中 A 点所指明的吞吐量。因为这两条连接共同消耗的链路带宽量小于 R,所以无丢包事件发生,根据 TCP 的拥塞避免算法的结果,这两条连接每过一个 RTT 都要将其窗口增加 1 个 MSS。因此,这两条连接的总吞吐量就会从 A 点开始沿 45° 线前行(两条连接都有相同的增长)。最终,这两条连接共同消耗的带宽将超过 R,最终将发生分组丢失。假设连接 1 和连接 2 实现 B 点指明的吞吐量时,它们都经历了分组丢失。
连接 1 和连接 2 于是就按二分之一减小其窗口。所产生的结果实现了 C 点指明的吞吐量,它正好位于始于 B 点止于原点的一个向量的中间。因为在 C 点,共同消耗的带宽小于 R,所以这两条连接再次沿着始于 C 点的 45° 线增加其吞吐量。最终,再次发生丢包事件,如在 D 点,这两条连接再次将其窗口长度减半,如此等等。
你应当搞清楚这两条连接实现的带宽最终将沿着平等带宽共享曲线在波动。还应该搞清楚无论这两条连接位于二维空间的何处,它们最终都会收敛到该状态!虽然此时我们做了许多理想化的假设,但是它仍然能对解释为什么 TCP 会导致在多条连接之间的平等共享带宽这个问题提供一个直观的感觉。
在理想化情形中,我们假设仅有 TCP 连接穿过瓶颈链路,所有的连接具有相同的 RTT 值,且对于一个主机—目的地对而言只有一条 TCP 连接与之相关联。实践中,这些条件通常是得不到满足的,客户—服务器应用因此能获得非常不平等的链路带宽份额。特别是,已经表明当多条连接共享一个共同的瓶颈链路时,那些具有较小 RTT 的连接能够在链路空闲时更快地抢到可用带宽(即较快地打开其拥塞窗口),因而将比那些具有较大 RTT 的连接享用更高的吞吐量。
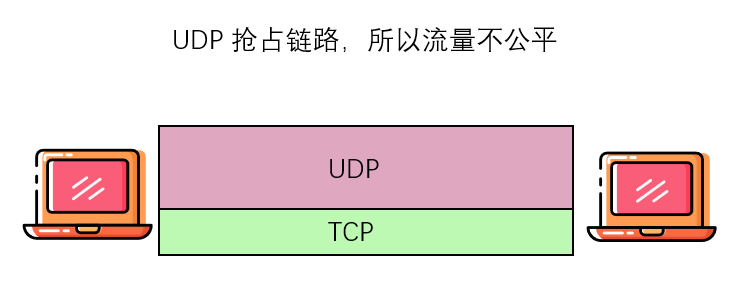
公平性和UDP
我们刚才已经看到,TCP 拥塞控制是如何通过拥塞窗口机制来调节一个应用程序的传输速率的。许多多媒体应用如因特网电话和视频会议,经常就因为这种特定原因而不在TCP 上运行,因为它们不想其传输速率被扼制,即使在网络非常拥塞的情况下。相反,这些应用宁可在 UDP 上运行,UDP 是没有内置的拥塞控制的。
当运行在 UDP 上时,这些应用能够以恒定的速率将其音频和视频数据注入网络之中并且偶尔会丢失分组,而不愿在拥塞时将其发送速率降至“公平”级别并且不丢失任何分组。
从 TCP 的观点来看,运行在 UDP 上的多媒体应用是不公平的,因为它们不与其他连接合作,也不适时地调整其传输速率。因为 TCP 拥塞控制在面临拥塞增加(丢包)时,将降低其传输速率,而 UDP 源则不必这样做,UDP 源有可能压制 TCP 流量。当今的一个主要研究领域就是开发一种因特网中的拥塞控制机制,用于阻止UDP 流量不断压制直至中断因特网吞吐量的情况。
公平性和并行TCP连接
即使我们能够迫使 UDP 流量具有公平的行为,但公平性问题仍然没有完全解决。这是因为我们没有什么办法阻止基于 TCP 的应用使用多个并行连接。例如,Web 浏览器通常使用多个并行 TCP 连接来传送一个 Web 页中的多个对象。(多条连接的确切数目可以在多数浏览器中进行配置。)当一个应用使用多条并行连接时,它占用了一条拥塞链路中较大 比例的带宽。
举例来说,考虑一段速率为 R 且支持 9 个在线 客户—服务器应用的链路,每个应用使用一条 TCP 连接。如果一个新的应用加入进来,也使用一条 TCP 连接,则每个应用得到差不多相同的传输速率 R/10。但是如果这个新的应用这次使用了 11个并行 TCP 连接,则这个新应用就不公平地分到超过 R/2 的带宽。Web 流量在因特网中是非常普遍的,所以多条并行连接并非不常见。
明确拥塞通告:网络辅助拥塞控制
自 20 世纪 80 年代后期慢启动和拥塞避免开始标准化以来,TCP 已经实现了端到端拥塞控制的形式:一个 TCP 发送方不会收到来自网络层的明确拥塞指示,而是通过观察分组丢失来推断拥塞。
最近,对于 IP 和 TCP 的扩展方案已经提出并已经实现和部署,该方案允许网络明确向 TCP 发送方和接收方发出拥塞信号。这种形式的网络辅助拥塞控制称为明确拥塞通告(Explicit Congestion Notification, ECN)。如下图所示,涉及了 TCP 和 IP 协议。
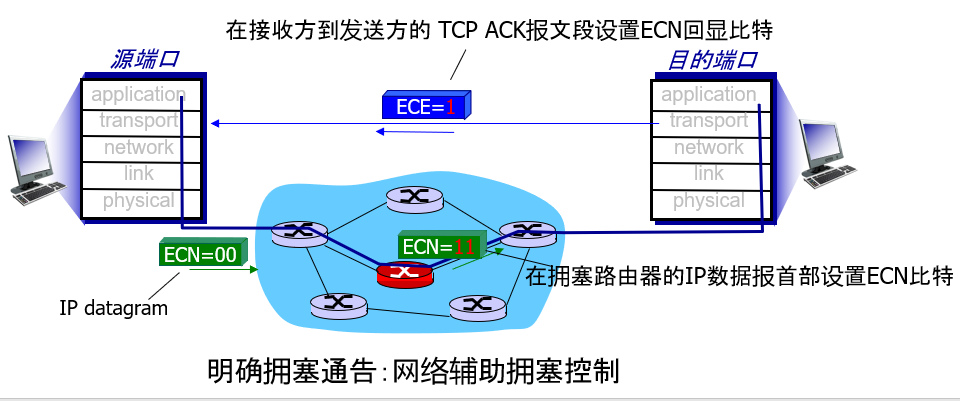
在网络层,IP 数据报首部的服务类型字段中的两个比特(总的说来,有四种可能的值)被用于 ECN。路由器所使用的一种 ECN 比特设置指示该路由器正在历经拥塞。该拥塞指示则由被标记的 IP 数据报所携带,送给目的主机,再由目的主机通知发送主机,如 上图所示。
RFC 3168没有提供路由器拥塞时的定义;该判断是由路由器厂商所做的配置选择,并且由网络操作员决定。然而,RFC 3168推荐仅当拥塞持续不断存在时才设置
ECN 比特。发送主机所使用的另一种 ECN 比特设置通知路由器发送方和接收方是 ECN 使能的,因此能够对于 ECN 指示的网络拥塞采取行动。
如上图所示,当接收主机中的 TCP 通过一个接收到的数据报收到了一个 ECN 拥塞指示时,接收主机中的 TCP 通过在接收方到发送方的 TCP ACK 报文段中设置 ECE(明确拥塞通告回显)比特,通知发送主机中的 TCP 收到拥塞指示。
接下来,,TCP 发送方通过减半拥塞窗口对一个具有 ECE 拥塞指示的 ACK 做出反应,就像它对丢失报文段使用快速重传做出反应一样,并且在下一个传输的 TCP 发送方到接收方的报文段首部中对 CWR (拥塞窗口缩减)比特进行设置。
除了 TCP 以外的其他运输层协议也可以利用网络层发送 ECN 信号。数据报拥塞控制协议(Datagram Congestion Control Protocol, DCCP)提供了一 种低开销、控制拥塞的类似 UDP 不可靠服务,该协议利用了 ECN。DCTCP(数据中心TCP)是一种专门为数据中心网络设计的TCP版本,也利用了 ECN。

若有收获,就点个赞吧
0 人点赞
