MySQL 语句的执行顺序
MySQL的语句一共分为11步,最先执行的总是FROM操作,最后执行的是LIMIT操作。其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入,只是这些虚拟的表对用户来说是透明的,但是只有最后一个虚拟的表才会被作为结果返回。如果没有在语句中指定对应的操作,那么将会跳过相应的步骤。
(7) SELECT(8) DISTINCT <select_list>(1) FROM <left_table>(3) <join_type> JOIN <right_table>(2) ON <join_condition>(4) WHERE <where_condition>(5) GROUP BY <group_by_list>(6) HAVING <having_condition>(9) ORDER BY <order_by_condition>(10) LIMIT <limit_number>
下面我们来具体分析一下查询处理的每一个阶段
- FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
- ON: 对虚表VT1进行ON筛选,只有那些符合
的行才会被记录在虚表VT2中。 - JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
- WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合
的记录才会被插入到虚拟表VT4中。 - GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
- CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
- HAVING: 对虚拟表VT6应用having过滤,只有符合
的记录才会被 插入到虚拟表VT7中。 - SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
- DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
- ORDER BY: 将虚拟表VT9中的记录按照
进行排序操作,产生虚拟表VT10. - LIMIT: 取出指定行的记录,产生虚拟表VT11, 并将结果返回。
MySQL批量插入唯一索引避免报错的方法
(一)导入差异数据,忽略重复数据,Insert IGNORE INTO的使用
insert ignore into
当插入数据时,如出现错误时,如重复数据,将不返回错误,只以警告形式返回。所以使用ignore请确保语句本身没有问题,否则也会被忽略掉。
(二)导入并覆盖重复数据,REPLACE INTO 的使用
如果存在primary or unique相同的记录,则先删除掉。再插入新记录。
MySQL UNION用法
MySQL允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并或复合查询。
什么时候需要使用组合查询?
在单个查询中从不同的表返回类似结构的数据;
对单个表执行多个查询,按单个查询返回数据。
SELECT vend_id,prod_id,prod_price FROM products WHERE prod_price <= 5 OR vend_id IN (1001,1002);UnionSELECT vend_id,prod_id,prod_price FROM products WHERE prod_price <= 5 UNIONSELECT vend_id,prod_id,prod_price FROM products WHERE vend_id IN (1001,1002);
UNION指示MySQL执行两条SELECT语句,并把输出组合成单个查询结果集。
UNION规则
UNION必须由两条以上的SELECT语句组成,语句之间用关键字UNION分割。
UNION中的每个查询必须包含相同的列、表达式或聚集函数(各个列不需要以相同的次序列出)。
列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型。
如果取出来的数据不需要去重,使用UNION ALL。
注意:如果直接用如下sql语句是会报错:Incorrect usage of UNION and ORDER BY。
SELECT * FROM t1 WHERE username LIKE 'l%' ORDER BY score ASCUNIONSELECT * FROM t1 WHERE username LIKE 'm%' ORDER BY score ASC
因为union在没有括号的情况下只能使用一个order by,所以报错。
这个语句修改方法。如下:
SELECT * FROM t1 WHERE username LIKE 'l%'UNIONSELECT * FROM t1 WHERE username LIKE 'm%' ORDER BY score ASC
该sql的意思就是先union,然后对整个结果集进行order by。
count(*)与count(列名)的区别
*
count()对行的所有数目进行计算,包含NULL值的行。
count(column)对特定的列的值具有的行数进行计算,不包含NULL值的行。
count(1)的结果和count(*)的结果是一样的。
DROP TABLE、TRUNCATE TABLE和DELETE的区别
**
TRUNCATE TABLE和DELETE都可以删除整个数据库表的记录。
1.DELETE
DML语言
可以回退
可以有条件的删除
DELETE FROM 表名 WHERE 条件
2.TRUNCATE TABLE
DDL语言
无法回退
默认所有的表内容都删除
删除速度比delete快
TRUNCATE TABLE 表名
3.DROP TABLE
用于删除表(表的结构、属性以及索引也会被删除);
DROP TABLE 表名
**
INNER JOIN、LEFT JOIN、RIGHT JOIN之间de区别

sql的left join 、right join 、inner join之间的区别
-left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
-right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
-inner join(等值连接) 只返回两个表中联结字段相等的行
case when语句
SQL语法
—简单Case函数
CASE 列名WHEN 条件值1 THEN 选项1WHEN 条件值2 THEN 选项2……ELSE 默认值END
—Case搜索函数
CASEWHEN 条件1 THEN 选项1WHEN 条件2 THEN 选项2……ELSE 默认值END
这两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。
Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
CaseWhen应用
1)根据单个条件显示一个值
SELECTSTUDENT_NAME,(CASE WHEN score < 60 THEN '不及格'WHEN score >= 60 AND score < 80 THEN '及格'WHEN score >= 80 THEN '优秀'ELSE '异常' END) AS REMARKFROMTABLE
根据分数的大小,我门可以返回成绩的类型。【不及格、及格、优秀】
CASE sexWHEN '1' THEN '男'WHEN '2' THEN '女'ELSE '其他' END
2)根据条件统计值 【经典行转列,并配合聚合函数做统计】
查询男女人数分别有多少。
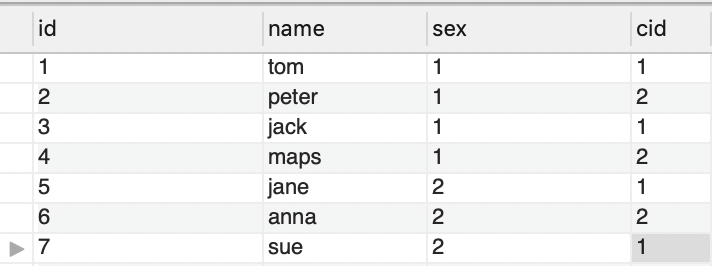
select sum(case when sex='1' then 1 else 0 end) as '男' ,sum(case when sex='2' then 1 else 0 end) as '女'from student;
我们也可以使用两个select语句,然后union联合一下。
3)分组统计
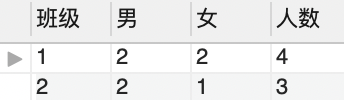
查询每个班,总共有多少人,男女人数分别有多少。【按班分组】
select cid as '班级', sum(case when sex='1' then 1 else 0 end) as '男' ,sum(case when sex='2' then 1 else 0 end) as '女' ,count(cid) as '人数'from student group by cid;
4)批量更新
更新,所有男生班级统一一班,女生统一二班。
update student set cid=(case when sex='1' then 1when sex='2' then 2 end) where sex in('1','2');
效果图

简单Case函数只能实现相等条件判断,Case搜索函数适合复杂条件判断,比如大于、小于等
distinct关键字
**
表格的基础数据
| id | value |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | c |
| 5 | e |
| 5 | f |
表中的value字段有重复,如果想筛选去重,使用select distinct语句如下:
SELECT DISTINCT value FROM xxx;
结论一:SELECT DISTINCT + 单字段,可实现对该字段去重
SELECT DISTINCT id, value FROM xxx;
得到结果:
| id |value
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | e
| 5 | f
结论二:**SELECT DISTINCT + 多字段,可实现对输入字段合并去重(只有多字段完全相同才会被“去重”的效果)**
SELECT id, DISTINCT value FROM xxx;
SQL运行报错
结论三:SELECT +字段 + DISTINCT + 字段,SQL错误,DISTINCT必须放在开头。
解决方案:group by
SELECT id, max(value) FROM xxx GROUP BY id
结论四:当DISTINCT无法满足只对单字段去重,并希望结果中显示对应的多字段内容的时候,可以用group by函数实现。但要注意希望在结果中显示的非去重目标字段,需要对它们分别添加筛选条件的函数或方法,否则sql语句会报错。

若有收获,就点个赞吧
0 人点赞
