数据库库表是对现实需求的高度抽象(实体),它包含实体基本信息、以及实体与其它实体间关系的表述。任何脱离业务、脱离具体需求的库表是没有价值的。库表设计也需要充分了解业务后,设计出来de库表才有意义。
数据库库表设计的步骤:
- 充分理解业务抽象出业务实体,描述实体具有的属性(column);
- 分析实体与实体间的关系;
- 掌握一定库表设计技巧;
数据库三大范式
第一范式
第一范式(1NF)用来确保每列的原子性,要求每列(或者每个属性值)都是不可再分的最小数据单元(也称为最小的原子单元)。
客人住宿信息
| 客人编号 | 用户名 | 地址 | 客房号 | 客房类型 | 客房价格 | 押金 | 入住时间 |
|---|---|---|---|---|---|---|---|
地址可以详细拆分为,国家省市县等等
如果业务需求中不需要拆分“地址”列,则该数据表符合第一范式。
1)删除客房号下所有数据,这会带来什么问题? 客房基础数据全部清空
2)新增一间客房,这个客房还没有住人,这会带来什么问题? 无法插入
第二范式
第二范式(2NF)在第一范式的基础上更进一层,要求表中的每列都和主键相关,即要求实体的唯一性。
客人信息表
| 客人编号 | 用户名 | 地址 | 押金 | 入住时间 | 客房号 |
|---|---|---|---|---|---|
客房信息
| 客房编号 | 客房类型 | 客房价格 | 床位数 | 客房状态 | 客房描述 |
|---|---|---|---|---|---|
第三范式
第三范式(3NF)在第二范式的基础上更进一层,第三范式是确保每列都和主键列直接相关,而不是间接相关,即限制列的冗余性。如果一个关系满足第二范式,并且除了主键以外的其他列都依赖于主键列,列和列之间不存在相互依赖关系,则满足第三范式。
| 客人编号 | 用户名 | 地址 | 押金 | 入住时间 | 客房号 |
|---|---|---|---|---|---|
客房信息表
| 客房编号 | 客房描述 | 客房类型编号 | 客房状态编号 |
|---|---|---|---|
客房类型表
| 客房类型编号 | 客房类型名称 | 客房价格 | 床位数 |
|---|---|---|---|
客房状态表
| 客房状态编号 | 客房状态 |
|---|---|
反范式
不满足范式的数据库设计,就是反范式化。
我们需要知道对于项目的最终用户来说,用户关心的是方便,清晰的数据结果。所以在设计数据库时,设计人员和客户在数据库的设计规范化和性能之间会有一定的矛盾。
上面我们通过三大范式将客房表分解出两个表,为了满足客户的需求,最终可能需要通过三个或四个表之间的连接查询,来得到客户需要的数据结果,插入数据同样如此,对于客户输入的数据,我们需要分开插入到三个或四个不同的表中。
由此可以看出,为了满足三大范式,我们的数据操作性能会受到相应的影响。
实体与实体间的关系
一对一
一对一,一般用于对主表的补充。假设A表为用户信息表,存储了用户的姓名、性别、年龄等基本信息。用户的家庭住址信息也属于用户的基本信息。我们可以选择将用户的家庭住址信息放到用户信息表,也可以单独建一张表,存储用户的家庭住址信息,以用户信息表的主键作为关联。
需不需要拆分取决:表信息的关联程度、表的字段个数限度。
一对多
一对多,是最常见的一种设计。就是 A 表的一条记录,对应 B 表的多条记录,且 A 的主键作为 B 表的外键。举几个 例子:
- 班级表 与 学生表,一个班级对应多个学生,或者多个学生对应一个班级。
- 商品表 与 图片表,一个商品对应多张图片,或者多张图片对应一个商品。
多对多
构建一张关系表将两张表进行关联,形成多对多的形式。例如:
- 老师表、学生表;一个学生可以选修多个老师的课程、同时一个老师也可以教多个学生。 ```sql —教师表 CREATE TABLE #Teacher(TeacherId int, Name nvarchar(20)); INSERT INTO #Teacher VALUES(1, ‘张老师’), (2, ‘王老师’);
—学生表 CREATE TABLE #Student(StudentId int, Name nvarchar(20)); INSERT INTO #Student VALUES(1, ‘小张’), (2, ‘小赵’);
—教师-学生关系表 CREATE TABLE #Teacher_Student(StudentId int, TeacherId int); INSERT INTO #Teacher_Student VALUES(1, 1), (1, 2),(2, 1), (2, 2);
---<a name="yyqIw"></a>### 数据库表的菜单【分类】设计:如省市关联、图书的一、二级分类<br />BookType 一级分类: 少儿、外语、计算机<br />BookClass 二级分类: 少儿[0-2岁、3-6岁、7-10岁、11-14岁、儿童文学]<br /> 外语[英语、日语、韩语、俄语、德语]<br /> 计算机[计算机理论、计算机考试、数据库、人工智能、程序设计]<br />BookInf 图书详情 : 图书信息的详细字段。。。基于以上关系:我们建表有两种方法<br /> <br />①:建立三张表 一级分类表,二级分类表、图书详情表<br />一级分类ID->作为二级分类的外键<br />二级分类ID->作为图书详情的外键<br /> <br />这一种依赖外键,实体模型也比较简单。(不再过多描述)<br />查询语句:可以采用 left join on 或者 等值连接 将二级分类的外键与一级分类的主键等值连接即可查询。②:建立两张表 一级分类和二级分类合并成一张表<br /> 图书详情表(引用TypeID为外键)<br /><br />TypeID 指一级二级分类的ID(唯一标识、主键) 序列自增从1开始。<br />TypeName 指一级二级分类的名字<br />ParentID 指二级分类所属一级分类TypeID (若为一级分类则填”0”与二级分类加以区分)<br />countNumber 指一级图书包含二级图书的个数<br /> 二级分类所包含详细图书的个数<br />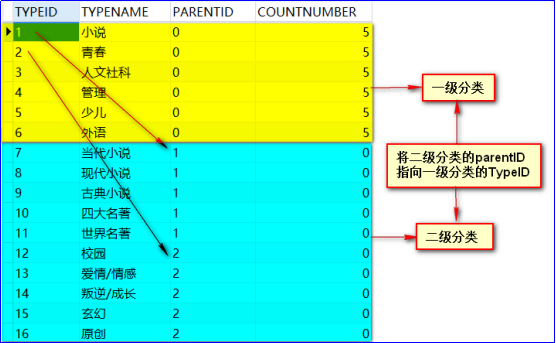<br />数据库查询一级分类信息的SQL```sqlselect typeid,typename,parentid,countnumber from t_booktype where parentid='0'
数据查询二级分类信息(利用表的自连接)
select child.typeid,child.typename,child.parentid,child.countnumberfrom t_booktype child ,t_booktype parent where child.parentid=parent.typeid
MySQL 表中存储树形结构数据
由上面设计技巧引出,如果数据层级有多级呢?简言之就像一棵树一样,我们如何存储树形的数据到数据库。
存储父节点
存储于数据库中,最简单直接的方法,就是存储每个元素的父节点ID,即parent_Id->父节点Id。这种方式方便了插入,但是在某些情况下的查询会束手无策。我们可以增加两个字段(deep,is_leaf)帮助我们更快的查询。
deep=1表示父节点,deep>1 表示子节点。
idparent_iddeep //当前树的深度is_leaf //是否叶子节点
查询所有父节点deSQL如下:
select * from tree where deep=1
查询某个父节点下的所有子节点:
select * from tree where parent_id=""
查询某个父节点下的所有后代节点
采用这种库表设计方式,这个需要依靠程序才能实现。
存储路径
将存储根结点到每个节点的路径,这种数据结构,可以一眼就看出子节点的深度。要插入自己,然后查出父节点的Path,并且把自己生成的ID更新到path中去。
如果要查询某个节点下的子节点,只需要根据path的路径去匹配,比如要查询4节点下的所有子节点。
select * from tree where path like '/1/4/%'
总结
我建议存储树形结构可以将两者结合起来。
idparent_iddeep //当前树的深度path //根路径is_leaf //是否叶子节点
MySQL 表的简化(特定场景下)
假设业务中有N多道具,比如用户首次使用某个道具触发特效。
iduser_id //用户Iditem_id //道具IDflag //是否触发过特效 0-1add_timeupdate_time
毫无疑问,上述表结构是能够满足并实现我们需求的,但是如果有100种道具,那么每个用户最终将有100条数据,数据冗余,如何简化?
解决方案:
定义道具枚举值
public enum ItemOnceFlagEnum {NONE(0),ITEM_ONE(1),//道具1ITEM_TWO(1 << 1), //道具2ITEM_Three(1 << 2), //道具3;private int code;ItemOnceFlagEnum(int code) {this.code = code;}public int getCode() {return code;}public static ItemOnceFlagEnum valueOf(int code) {ItemOnceFlagEnum[] values = ItemOnceFlagEnum.values();for (ItemOnceFlagEnum flag : values) {if (flag.getCode() == code) {return flag;}}return NONE;}}
建表
iduser_id //用户Idflag //是否触发过特效 2的0次幂、2的1次幂。。。add_timeupdate_timeuser_id设置为唯一索引
判断是否使用过某道具与添加道具使用记录
//判断是否使用过某项道具public static boolean isHasThisFlag(long flag, ItemOnceFlagEnum itemOnceFlagEnum) {return (flag & itemOnceFlagEnum.getCode()) > 0;}//添加道具使用记录public Result<Boolean> addOnceFlag(long userId, itemOnceFlagEnum flag) {ItemOnceFlagDO itemOnceFlagDO = itmeOnceFlagService.getOnceFlagMap(Collections.singletonList(userId));long calculateFlag = (Objects.isNull(blockOnceFlagDO) ? 0L : itemOnceFlagDO.getFlag()) | flag.getCode();itemOnceFlag.setFlag(calculateFlag);boolean res = itemOnceFlagService.addOrUpdateOnceFlag(itemOnceFlag);}
添加记录SQL
"INSERT INTO xxxx ( ) VALUES ( :1.userId, :1.flag ) " +" ON DUPLICATE KEY UPDATE flag = :1.flag "
某一项道具为具体2次幂值(仅能够维护2种状态,有或无),flag代表所有触发道具2次幂和。
通过 (flag & itemOnceFlagEnum.getCode())>0 判断是否有某项道具
通过 flag | temOnceFlagEnum.getCode(); 添加道具记录
MySQL 为表预留一个扩展字段
建表时,我们一般需要预留一个字段作为扩展字段,这个扩展字段类型为String,存储数据为JSON串。
iditem_namebodyadd_timeupdate_tim
如果我们需要为某一个道具增加一项附加功能或者特殊设置,添加字段的方式可以实现,但是显然不合理。(因为这是某一个道具才具有的功能或设置)
我们可以通过body字段进行扩展。
//值为1时满足{"showVipIcon":1}//值为0时不满足{"showVipIcon":0}

若有收获,就点个赞吧
0 人点赞
