| MySQL—-索引 |
|---|
索引的数据结构 B - Tree(mysql主要使用 B-tree 平衡树)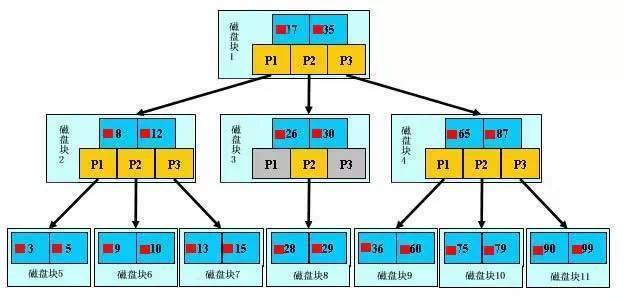
浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
b+树的查找过程
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
为什么大多数数据库索引都使用B+树来实现呢?
二叉查找树(需要满足一下属性)
1. 非叶子节点最多拥有两个子节点;
2. 非叶子节值大于左边子节点、小于右边子节点;
3. 没有值相等重复的节点;
平衡二叉树(在二叉查找树的前提下附加一个条件)
树的左右两边的层级数相差不会大于1
平衡二叉树的查找效率确实很快,但维护一颗平衡二叉树的代价是非常大的,需要1次或多次左旋和右旋来得到插入或更新后树的平衡性。
1)假如用平衡二叉树实现索引,效率已经很高了,查找一个节点所做的IO次数是这个节点所处的树的高度。所以最坏情况下,磁盘的IO次数为树的高度。
2)我们也无法把整个索引都加载到内存,并且节点数据在磁盘中不是顺序排放的。
怎样减少IO次数呢?
B树- 和 B+树
每个节点的数据多放一点,这个数据是存放在一块的,对应的是数据库中的读取的最小单位页。一次IO就可以将这些数据读取出来,虽然比较的次数有可能会增加,但是在内存中的比较和磁盘IO相比差几个数量级,整体上效率还是提高了。(一页的大小由操作系统决定,常见的页大小一般为4KB=4096字节。)
那么B树和B+树的区别在哪呢?
1. B+跟B树不同B+树的非叶子节点不保存键值对应的数据,这样使得B+树每个节点所能保存的键值大大增加;
2. B+树叶子节点保存了父节点的所有键值和键值对应的数据,每个叶子节点的键值从小到大链接;
3. B+树的根节点键值数量和其子节点个数相等;
4. B+的非叶子节点只进行数据索引,不会存实际的键值对应的数据,所有数据必须要到叶子节点才能获取到,所以每次数据查询的次数都一样;
https://juejin.im/entry/5bc1ea0a5188255c2f424209
MySQL索引实现
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
MyISAM索引实现(非聚集索引)
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
InnoDB索引实现(聚簇索引)
第一个重大区别是InnoDB的数据文件本身就是索引文件。MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:

为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。使用自增字段作为主键则是一个很好的选择:因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效。
聚簇索引:索引的叶节点指向数据非聚簇索引:索引的叶节点指向数据的引用myisam使用非聚簇索引,innodb使用聚簇索引。
查询优化
1)联合索引
如果存在一个多列索引,任何最左面的索引前缀能被优化器使用,如果列不构成索引的最左面前缀,则建立的索引将不起作用。所以联合索引的顺序不同,影响索引的选择,尽量将值少的放在前面。
如:一个多列索引为 (col1 ,col2, col3)
那么在索引在列 (col1) 、(col1 col2) 、(col1 col2 col3) 的搜索会有作用。
2)使用 is null 或 is not null
使用 is null 或is nuo null也会限制索引的使用,因为数据库并没有定义null值。如果被索引的列中有很多null,就不会使用这个索引(除非索引是一个位图索引,关于位图索引不做详细解释)。在sql语句中使用null会造成很多麻烦。
解决这个问题的办法就是:建表时把需要索引的列定义为非空(not null)。
3)使用函数
如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
select * from staff where trunc(birthdate) = ‘01-MAY-82’;
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
4)模糊查询
如果一个 Like 语句的查询条件不以通配符起始则使用索引。
如:%车 或 %车% 不使用索引。
车% 使用索引。
5)使用不等于操作符(<>, !=)
下面这种情况,即使在列dept_id有一个索引,查询语句仍然执行一次全表扫描
select from dept where staff_num <> 1000;
通过把用 or 语法替代不等号进行查询,就可以使用索引,以避免全表扫描:上面的语句改成下面这样的,就可以使用索引了。
select from dept shere staff_num < 1000 or dept_id > 1000;
SQL优化方案
1)MySQL 执行计划
当我们执行一条sql的时候,在前面加上explain。
explain select * from teacher;
ID(select语句的查询序号)
A:id值相同,表的查询顺序是从上往下顺序执行
在进行多表联查的时候,MySQL一般会选择数据量最小的表进行优先查询,而数据量大的放到最后。
B:id值不同,表的查询顺序是id值越大越优先查询(本质:在嵌套子查询时,先查内层,再查外层)
C:id值有相同有不同,先执行id值大的,剩余id相同的按顺序从上往下执行
id 表示执行的顺序,id越大越先执行,id一样的从上往下执行。
select_type 表示查询类型,通常有:
simple:表示不需要union操作或者不包含子查询的简单查询。
primary:表示最外层查询。
union:union操作中第二个及之后的查询。
dependent union:union操作中第二个及之后的查询,并且该查询依赖于外部查询。
subquery:子查询中的第一个查询。
dependent subquery:子查询中的第一个查询,并且该查询依赖于外部查询。
derived:派生表查询,既from字句中的子查询。
materialized:物化查询。
uncacheable subquery:无法被缓存的子查询,对外部查询的每一行都需要重新进行查询。
uncacheable union:union操作中第二个及之后的查询,并且该查询属于uncacheable subquery。
table 表名或者表的别名。
partitions 分区信息,非分区表为null。
type 访问类型,表示找到所查询数据的方法,也是本文重点介绍的属性。该属性的常见值如下,性能从好到差:
NULL:无需访问表或者索引,比如获取一个索引列的最大值或最小值。
system/const:当查询最多匹配一行时,常出现于where条件是=的情况。system是const的一种特殊情况,既表本身只有一行数据的情况。
eq_ref:多表关联查询时,根据唯一非空索引进行查询的情况。
ref:多表查询时,根据非唯一非空索引进行查询的情况。
range:在一个索引上进行范围查找。
index:遍历索引树查询,通常发生在查询结果只包含索引字段时。
ALL:全表扫描,没有任何索引可以使用时。这是最差的情况,应该避免。
possible_keys 表示mysql此次查询中可能使用的索引。
key 表示mysql实际在此次查询中使用的索引。
key_len 表示mysql使用的索引的长度。该值越小越好。
ref 表示连接查询的连接条件。
rows 表示mysql估计此次查询所需读取的行数。该值越小越好
2)show profiles分析SQL性能
profile 默认不开启
mysql> SHOW VARIABLES LIKE 'profiling';+---------------+-------+| Variable_name | Value |+---------------+-------+| profiling | OFF |+---------------+-------+1 row in set (0.00 sec)mysql>SET profiling=ON;mysql>SHOW VARIABLES LIKE 'profiling';
单独分析某条sql,查看某条sql的生命周期以及各占用多少时间。
SHOW PROFILE cpu, block io FOR QUERY id;
type:
ALL —显示所有的开销信息
| BLOCK IO —显示块IO相关开销
| CONTEXT SWITCHES —上下文切换相关开销
| CPU —显示CPU相关开销信息
| IPC —显示发送和接收相关开销信息
| MEMORY —显示内存相关开销信息
| PAGE FAULTS —显示页面错误相关开销信息
| SOURCE —显示和Source_function,Source_file,Source_line相关的开销信息
| SWAPS —显示交换次数相关开销的信息
主要出现问题如下:
* converting HEAP to MyISAM 查询结果太大,内存不够了往磁盘上搬了* creating tmp table 创建临时表:(1)拷贝数据到临时表。(2)用完再删。* copying to tmp table on disk 把内存中临时表复制到磁盘,危险!!!* locked
1.show profile默认是关闭的,并且开启后只存活于当前会话,也就说每次使用前都需要开启。
#2.通过show profiles查看sql语句的耗时时间,然后通过show profile命令对耗时时间长的sql语句进行诊断。
#3.注意show profile诊断结果中出现相关字段的含义,判断是否需要优化sql语句。

若有收获,就点个赞吧
0 人点赞
