参考资料:https://www.checklyhq.com/learn/headless/basics-selectors/
常用操作
根据两个class定位元素,并获取内部文本
//匹配元素:
- …
//匹配方法:使用xpath同时匹配两个class
String detail = page.innerText("//ul[contains(@class, 'parameter2') and contains(@class, 'p-parameter-list')]")
获取指定id的src属性

page.locator(“id=spec-img”).getAttribute(“src”);
获取多个元素的文本
如下图所示,需要获取所有li元素的文本: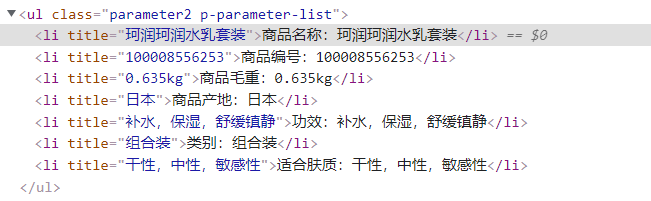
//方法1: 选中多个元素List<ElementHandle> handlers = page.querySelectorAll("//ul[contains(@class, \"parameter2\") and contains(@class, \"p-parameter-list\")]/li");log.debug("方法1:商品详细信息为:");for (int i = 0; i < handlers.size(); i++) {System.out.println(handlers.get(i).innerText());}//方法2:选中多个元素,推荐!!!List<String> detailList = page.locator("//ul[contains(@class, 'parameter2') and contains(@class, 'p-parameter-list')]/li").allInnerTexts();log.debug("方法2:商品详细信息为:[{}]", detailList);
获取多个元素,并分别调用js求值
获取到多个元素之后,每个元素要调用window.getComputedStyle(el).backgroundImage获取背景图片url
List<ElementHandle> elementHandles = page.locator("//div[contains(@id, 'J-detail-content')]/div[contains(@class, 'ssd-module-wrap')]/div").elementHandles();//访问其中某个元素elementHandles.get(1).evaluate("el=>window.getComputedStyle(el).backgroundImage");//访问全部元素List<String> imgeUrlList = new ArrayList<>(elementHandles).stream().map(x -> (String) x.evaluate("el=>window.getComputedStyle(el).backgroundImage")).collect(Collectors.toList());
获取子元素
要求:获取第二个div里面的第一个div。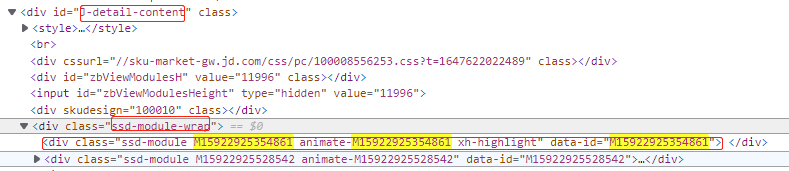
xpath代码如下:
//div[contains(@id, ‘J-detail-content’)]/div[contains(@class, ‘ssd-module-wrap’)]/div[1]
问题
如何实现/div[1]的定位?
下面的定位方式是错误的:ElementHandle elementHandle = h.querySelector("/div[1]");
Selector starting with // or .. is assumed to be an xpath selector. For example, Playwright converts ‘//html/body’ to ‘xpath=//html/body’.
也就是说,只有//和..才被认为是xpath的语法,如果是/开头,则需要自己手工指定xpath。
正确的如下:ElementHandle elementHandle = h.querySelector("xpath=/div[1]");

若有收获,就点个赞吧
0 人点赞
