同样的参数设置,效果不稳定的原因:对初始的簇中心敏感,不同的选取方式会得到不同的结果
解决方法:
- 保持k值不变进行多次聚类,利用聚类效果评价指标CH、DB、轮廓系数,Gap statistic等选择出聚类效果最佳的一次再计算 | | 指标 | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | 140 | 150 | 160 | 170 | 180 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | | resnet20 | CH | 1.220 | 0.305 | 1.365 | 2.331 | 2.331 | 2.220 | 2.129 | 1.137 | 1.144 | 0.506 | 0.055 | 0.537 | 1.871 | 1.717 | | | | 0.780 | 0.447 | 0.209 | 2.331 | 2.331 | 2.220 | 1.220 | 0.311 | 0.383 | 0.506 | 1.220 | 0.654 | 0.632 | 0.109 | | | | 0.780 | 1.220 | 0.084 | 1.280 | 1.088 | 0.780 | 1.507 | 2.000 | 1.719 | 3.066 | 2.113 | 2.530 | 2.271 | 2.113 | | | | 0.780 | 2.113 | 2.898 | 3.652 | 0.825 | 1.849 | 2.474 | 2.995 | 2.626 | 0.923 | 1.447 | 1.905 | 1.721 | 2.113 | | | | 2.658 | 2.113 | 3.066 | 1.088 | 0.011 | 0.699 | 1.507 | 2.113 | 1.088 | 0.866 | 0.833 | 1.280 | 1.133 | 1.558 | | | SH | 1.220 | 0.305 | 0.209 | 0.030 | 0.209 | 1.121 | 1.220 | 2.053 | 1.298 | 1.292 | 1.816 | 1.220 | 1.162 | 1.165 | | | | 2.985 | 1.389 | 0.044 | 2.331 | 1.447 | 0.311 | 0.311 | 0.311 | 0.253 | 0.209 | 0.616 | 1.158 | 0.687 | 0.664 | | | | 0.617 | 1.056 | 0.084 | 0.081 | 1.220 | 1.220 | 1.130 | 0.464 | 0.451 | 0.209 | 0.672 | 0.030 | 0.496 | 0.353 | | | | 2.780 | 3.862 | 3.146 | 2.530 | 3.285 | 2.780 | 2.474 | 2.947 | 3.395 | 3.066 | 3.447 | 3.811 | 3.517 | 3.255 | | | | 0.780 | 2.113 | 0.329 | 1.373 | 0.209 | 1.220 | 0.394 | 0.305 | 1.088 | 1.637 | 2.113 | 1.905 | 1.679 | 1.517 |
❌这些普通的指标并不能选出对于这个任务而言最好的聚类情况
根源在于用于聚类的这些数据很散,同样的参数设置,对于cifar10_resnet20_onehot_refine聚类,下面三次聚类的结果完全不一样,边缘那些特别散的点都是那些预测结果与原模型预测结果相差较多的变异模型,他们在图中的表现就是少而散。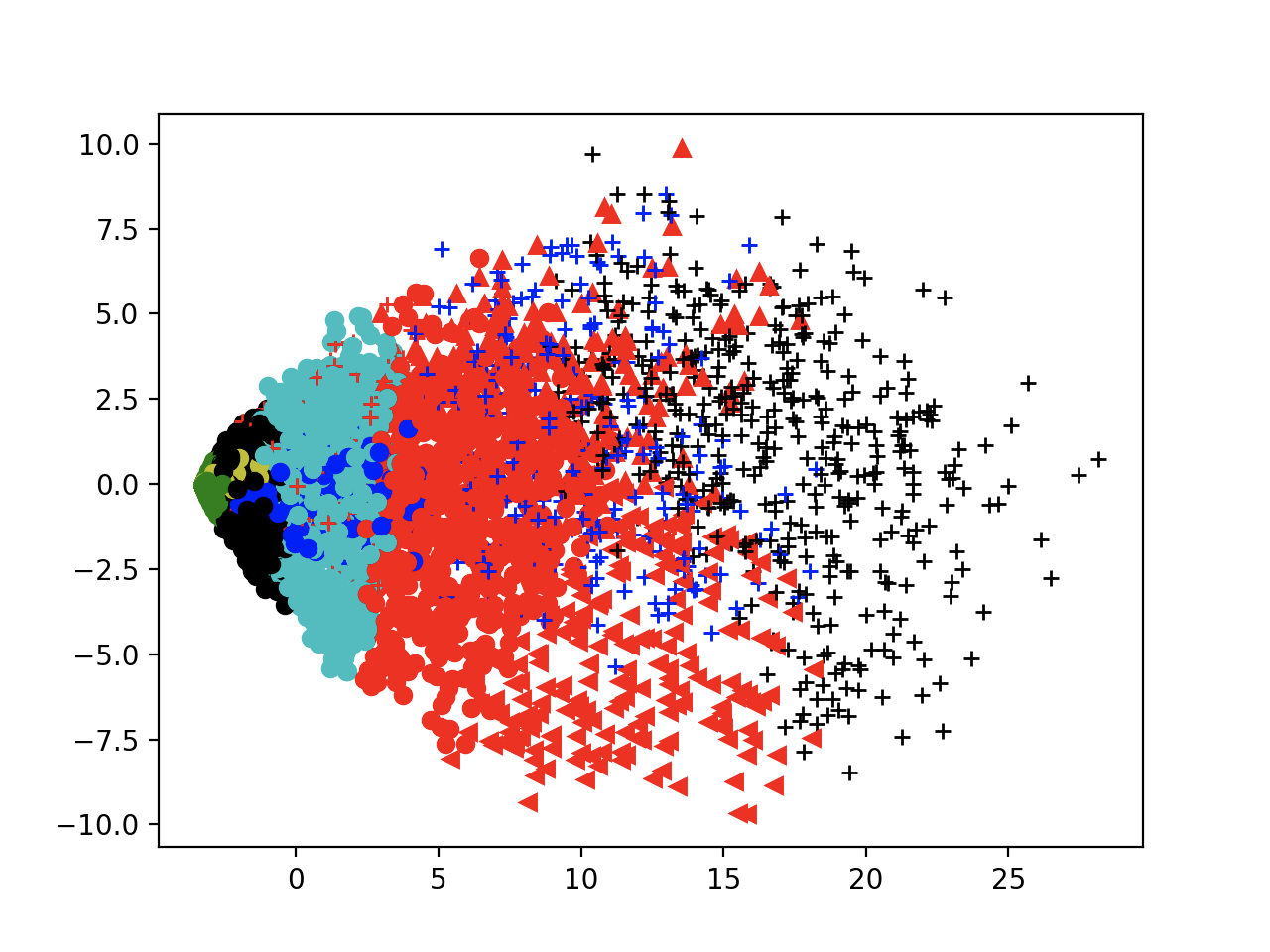
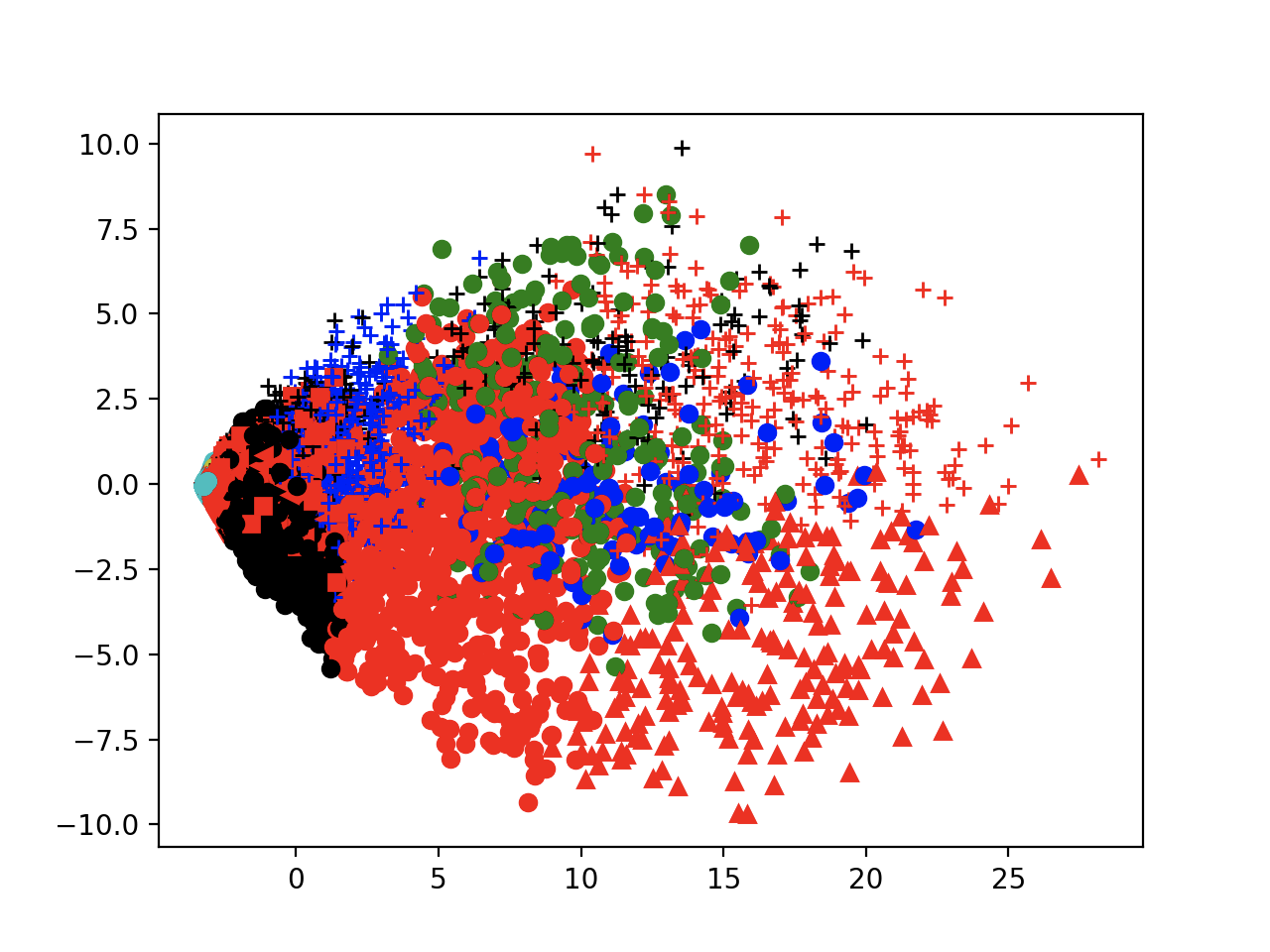

对于cifar10_resnet20_var2_scale聚类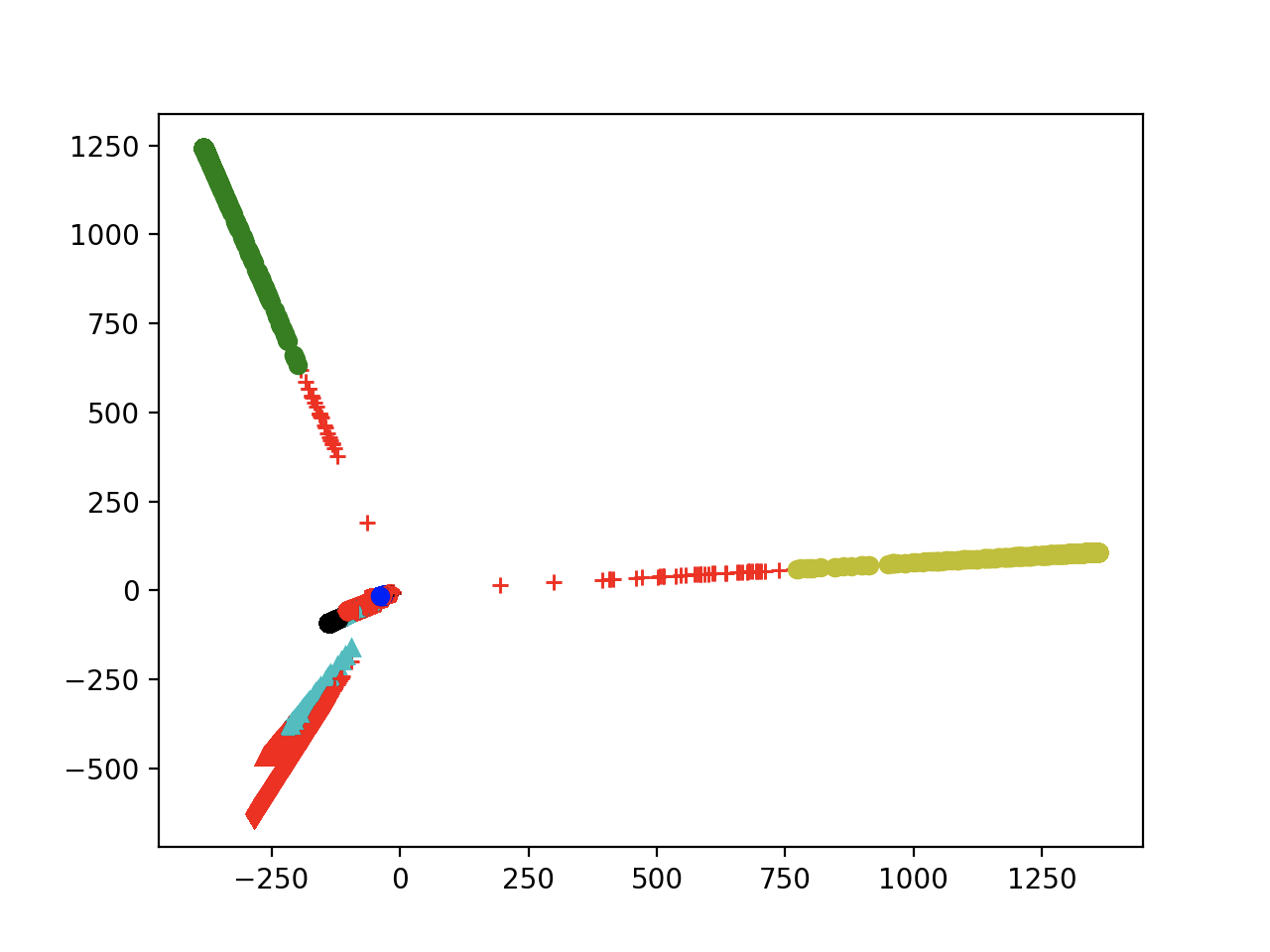

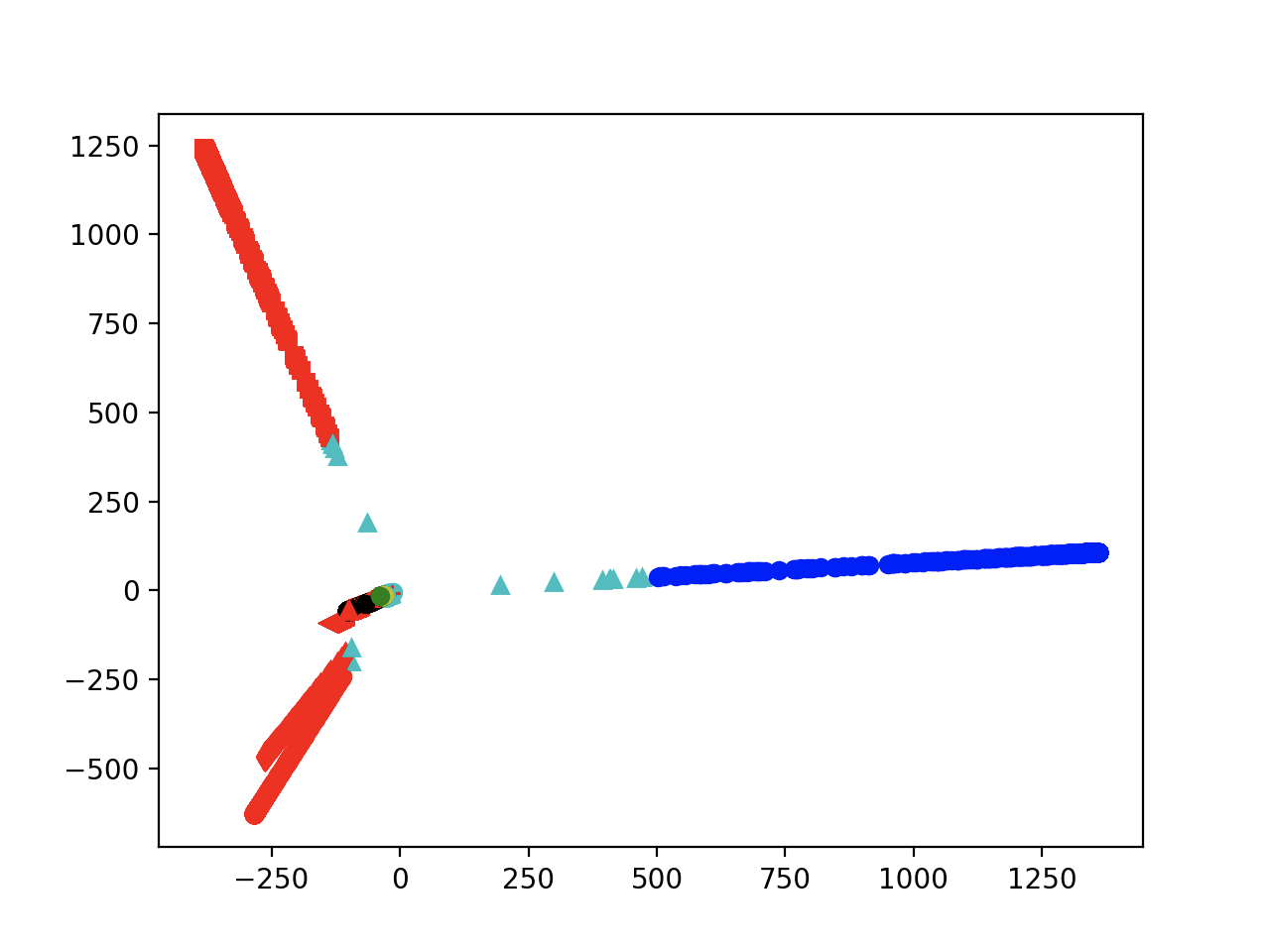
- 将200-2000的范围更改为200-1000去重(exp2)
好像并没有本质的变化,直观来看,这种数据应该更适合基于密度的聚类
效果好:
效果差:
效果一般:
- 重回HDBSCAN聚类
min_cluster_size=80, min_samples=4
HDBSCAN在聚类的时候没有任何的随机性,几乎所有的揭错样本都会被分到-1这个类里(size最大的类,lenet1、lenet4、lenet5、vgg16也都是这种情况),随机性来源于样本的选择方法,没有办法选择合适数量的正确样本和揭错样本才导致效果不好。这样随机选择其实一定意义上也就是SRS,只不过样本少了。
利用HDBSCAN聚完类之后其实可以默认除了从-1中会选取揭错样本,从其他类中选取的都是正确样本
散点图分布 😷😷😷: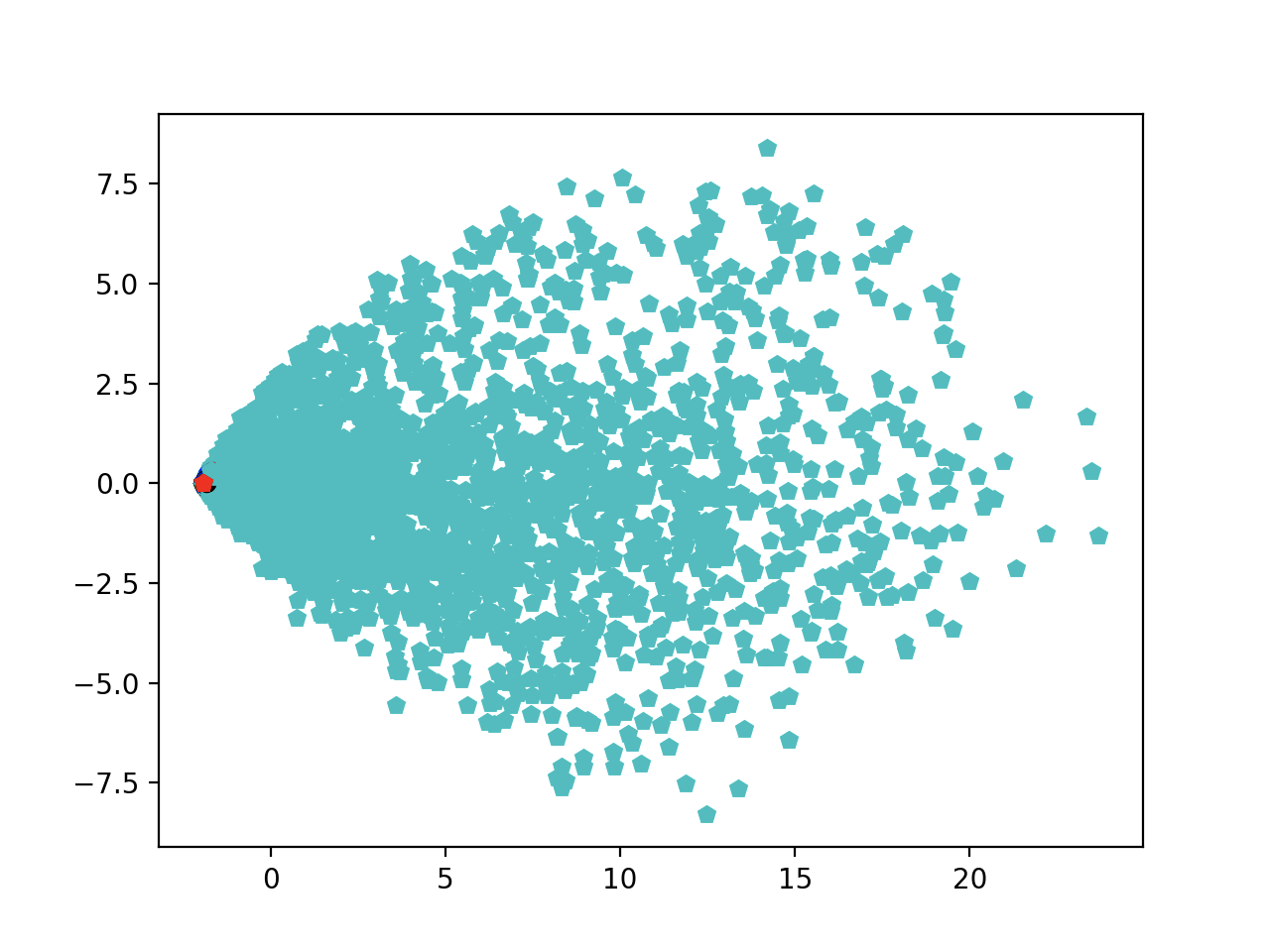
🌟在对所有样本进行一次HDBSCAN聚类之后可以对-1类的样本进行二次HDBSCAN聚类❌
二次聚类的时候已经已经不能再将它们分开
🌟在对所有样本进行一次HDBSCAN聚类之后可以对-1类的样本进行二次KMEANS(或者其他方法)聚类❌
如果用KMeans,那聚出来的每一簇的准确率都差不多即正确样本和揭错样本的比例估计都差不多,下图是在上面一张图的基础上标记出了揭错样本。如果普通的聚类,不能稳定地找到相同比例的正确样本和错误样本。

若有收获,就点个赞吧
0 人点赞
