前景:获取内存地址的方法
1、Object的hashCode()默认是返回内存地址的,但是hashCode()可以重写,所以hashCode()不能代表内存地址的不同。2、System.identityHashCode(Object)方法可以返回对象的内存地址,不管该对象的类是否重写了hashCode()方法。
1、什么是String,它是什么数据类型?
1、String-What?1-1、String是定义在 java.lang 包下的一个类。它不是基本数据类型。1-2、String是不可变的,JVM使用字符串池来存储所有的字符串对象。1-3、String源码上-分析1-3-1、String类被final关键字修饰,意味着String类不能被继承,并且它的成员方法都默认为final方法;字符串一旦创建就不能再修改。1-3-2、String类实现了Serializable、CharSequence、 Comparable接口。public final class String implements java.io.Serializable,Comparable<String>, CharSequence {}1-3-3、String实例的值是通过字符数组实现字符串存储的。private final char value[];
1.1、String被设计成不可变和不能被继承的原因[Final关键字修饰]
1、原因:1-1、String是不可变和不能被继承的(final修饰),这样设计的原因主要是为了设计考虑、效率和安全性。2、原因分析:2-1、设计考虑需要-字符串常量池的需要2-1-1、字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。假若字符串对象允许改变,那么将会导致各种逻辑错误,比如改变一个对象会影响到另一个独立对象. 严格来说,这种常量池的思想,是一种优化手段。2-2、String对象缓存HashCode2-2-1、Java中的String对象的哈希码被频繁地使用,字符串的不可变性保证了hash码的唯一性。-- private int hash;2-3、安全性:2-3-1、String被许多Java类用来当参数,如果字符串可变,那么会引起各种严重错误和安全漏洞。2-3-2、String作为核心类,很多的内部方法的实现都是本地调用的,即调用操作系统本地API,其和操作系统交流频繁,假如这个类被继承重写的话,难免会是操作系统造成巨大的隐患。2-3-3、字符串的不可变性使得同一字符串实例被多个线程共享,所以保障了多线程的安全性。而且类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。
2、几种不同的创建字符串的方式
String a = "a";String c = new String("c");String f = "f" + "g";String b = new String("a") + new String("b");String d = String.valueOf("d");String e = new StringBuilder("e").toString();String s2 = "1" + "3" + new String("1") + "4";
从上到下依次解释一下,只有明白了这几种创建的区别所在才能明白一个字符串在内存中的分布情况。
2.1、String a = “a”;
在JDK 1.7 之前,会在字符串常量池中创建对象,并返回池中的引用;在JDK 1.7 之后,在堆中创建对象,同时在字符串常量池中保存一份引用,返回池中的引用,同时也是堆中对象的引用,如果常量池中已经存在对象或者堆中对象的引用,那么则直接返回该引用。
2.2、String c = new String(“c”);
• 如果常量池中没有“c”,那么同时在堆中和常量池中创建对象,会创建两个对象,返回堆中对象的引用。• 如果常量池中有“c”,只会在堆中创建,并返回堆中对象的引用。注意:在JDK1.7之后,常量池中不在存字符串对象了,只会存对象的引用,字符串对象会创建在相应的堆中。
2.3、String f = “f” + “g”;
使用包含常量的字符串连接创建是也是常量,编译期就能确定了,直接入字符串常量池,当然同样需要判断常量池中是否已经存在”fg”字符串。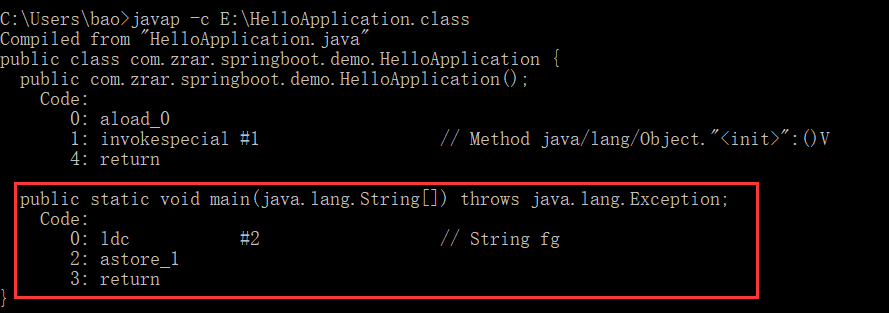
2.4、String b = new String(“a”) + new String(“b”);
可以看成先把第一种情况执行了两次。因为“+”的关系还创建了StringBuilder对象,最后StringBuilder对象调用toString()方法的时候又new了String对象并将它的引用返回给b。整个过程在堆中创建了三个String对象(“a”,”b”,”ab”),在运行时常量池中创建了两个String对象(“a”,”b”)。
注意:这里在jdk1.7之后,就应该是在堆中创建5个String对象了,然后在常量池中存其中两个对象的引用(这个是自己的理解),那两个对象也就相当于存在常量池中吗,相当于吧。
下面我们通过对应
这里我们将其用javap -c 对应的路径+class文件名反编译对应的class文件得到下面的java字节码(bytecode)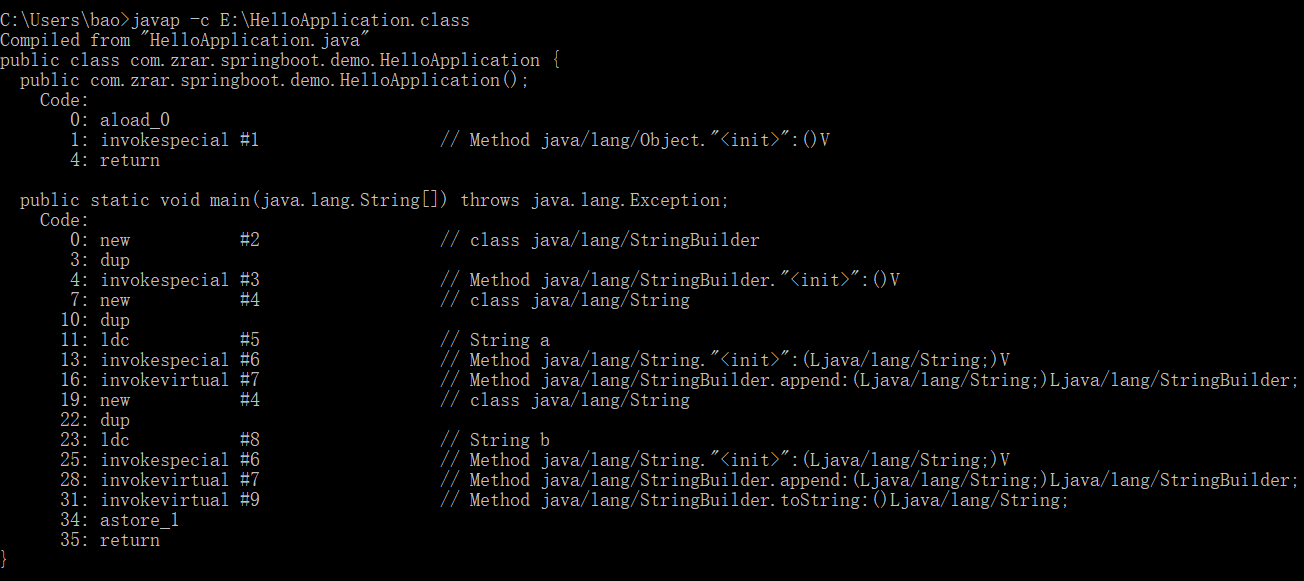
emmm,很难看懂,但是慢慢读下来我们发现
0 执行new指令在堆上分配对象的内存,对象的引用推送至操作数栈,这里就相当于new了一个StringBuilder对象吧
3 执行dup指令 复制栈顶元素,常用于复制 new 指令所生成的未经初始化的引用
4 执行invokespecial指令调用初始化方法。 注:invokespecial只能调用三类方法:
7 同0,不过这次相当于new了一个String对象
10 同3
11 执行ldc指令将”a”加载到操作数栈顶 (ldc指令描述:常量池中的常量值(int, float, string reference, object reference)入栈)。换句话说,如果常量池中没有”a”对象的引用,那么就会在堆中创建”a”对象,并把该对象的引用保存到字符串常量池中(1.7之前的话就是直接在常量池中创建”a”对象)。
13 执行String类的初始化,这里后面有个V,个人感觉就是从常量池中把”a”字符串复制过来了,下面2.7的图示上也能很好的说明。
16 调用StringBuilder方法
19 同0,不过这次相当于new了一个String对象
22 同3
23 同11,如果常量池中没有”b”对象的引用,那么就会在堆中创建”b”对象,并把该对象的引用保存到字符串常量池中(1.7之前的话就是直接在常量池中创建”b”对象)。
25 同13
28 同16
31 执行toString()方法,这里会在堆中新建一个对象(”ab”)并返回一个对象的引用
32 执行astore_1 将引用其赋值给我们定义的局部变量b
2.5、String d = String.valueOf(“d”);
相当于String d = “d”;
- 在JDK 1.7 之前,会在字符串常量池中创建对象,并返回池中的引用;
在JDK 1.7 之后,在堆中创建对象,同时在字符串常量池中保存一份引用,返回池中的引用,同时也是堆中对象的引用,如果常量池中已经存在对象或者堆中对象的引用,那么则直接返回该引用。
2.6、String e = new StringBuilder(“e”).toString();
只会在堆中创建对象String对象"e"
2.7、String s2=”1”+”3”+new String(“1”)+”4”;
网上拿过来的例子,算是对2.4的补充。
当使用“+”连接字符串中含有变量时,是在运行期才能确定的。首先连接操作最开始时如果都是字符串常量,编译后将尽可能多的字符串常量连接在一起,形成新的字符串常量参与后续的连接(可通过反编译工具jd-gui进行查看)。接下来的字符串连接是从左向右依次进行,对于不同的字符串,首先以最左边的字符串为参数创建StringBuilder对象(可变字符串对象),然后依次对右边进行append操作,最后将StringBuilder对象通过toString()方法转换成String对象(注意:中间的多个字符串常量不会自动拼接)。
实际上的实现过程为:
String s2=new StringBuilder(“13”).append(new String(“1”)).append(“4”).toString();
当使用+进行多个字符串连接时,实际上是而外产生了一个StringBuilder对象和一个String对象。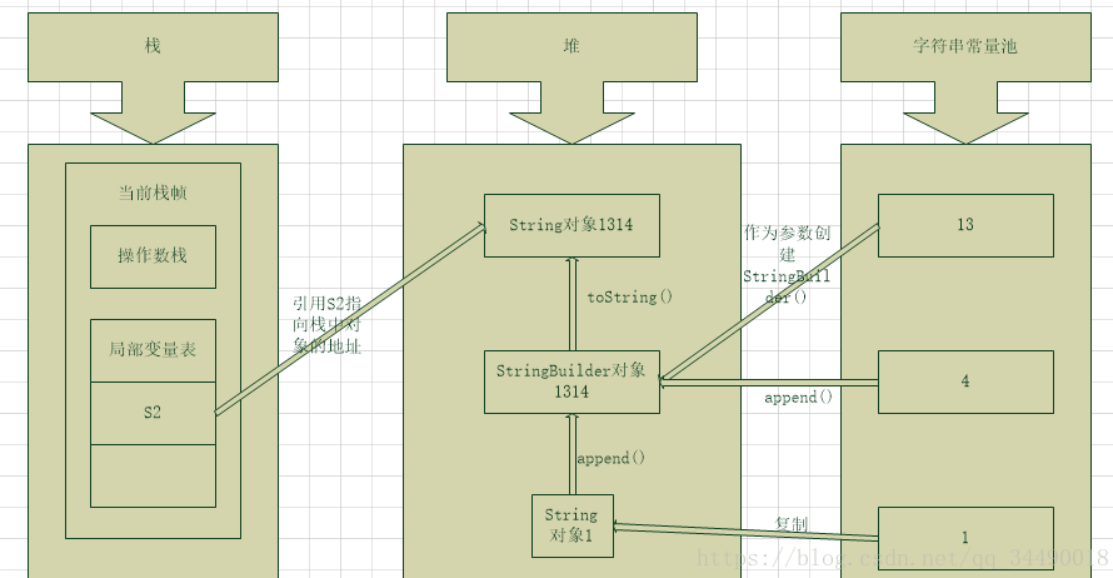
注:这里String对象1和常量池中的1 中间用复制,我想作者的意思是现在常量池中创建,而后复制一份字符串到堆中,查看2.4的字节码可知,确实应该是如此。3、intern()方法
在JDK 1.7 之前,如果常量池中含有一个字符串和当前调用方法的字符串equals相等,那么就会返回池中的字符串,如果池中没有的话,则首先在常量池中创建该字符串,然后返回引用在JDK 1.7 之后,如果常量池中含有一个字符串和当前调用方法的字符串equals相等,那么就会返回池中的字符串,如果池中没有的话,会将堆中的引用复制到常量池中,并返回这个引用。
3.1、intern()方法-案例解析:
String s3 = new String(“1”) + new String(“1”);
System.out.println(s3 == s3.intern());
JDK1.7之后,字符串常量池已经被转移至Java堆中,开发人员也对intern 方法做了一些修改。因为字符串常量池和new的对象都存于Java堆中,为了优化性能和减少内存开销,当调用 intern 方法时,如果常量池中已经存在该字符串,则返回池中字符串;否则直接存储堆中的引用,也就是字符串常量池中存储的是指向堆里的对象。所以结果为true。具体如下图: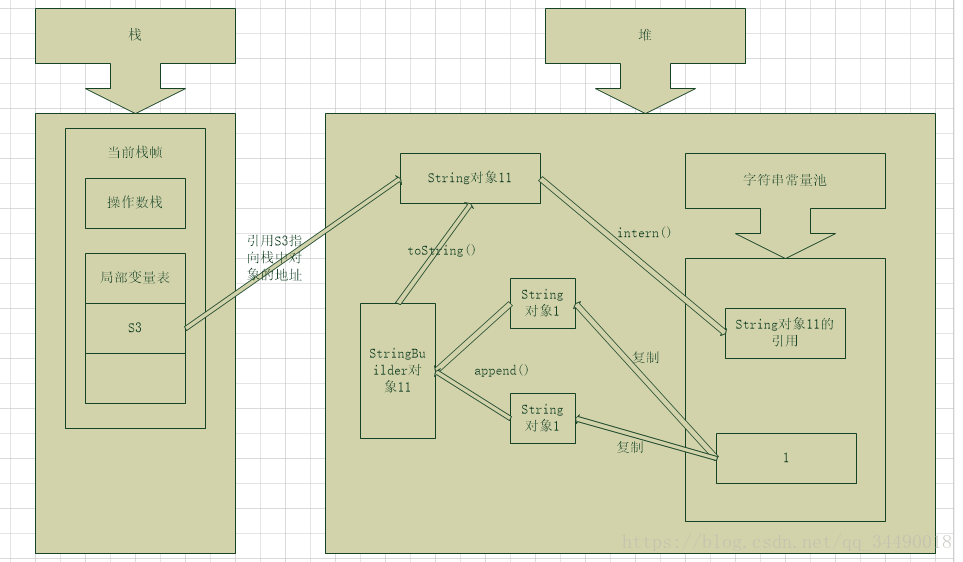
所以这个时候如果在中间加了一个String s4 = “11”;String s3 = new String("1") + new String("1");String s4 = "11";System.out.println(s3 == s3.intern());//falseSystem.out.println(s4 == s3.intern());//trueSystem.out.println(s3 == s4);//false
但是如果把String s4 = “11”; 放在s3.intern()方法的后面 就会是 true true true了
String s3 = new String("1") + new String("1");System.out.println(s3 == s3.intern());//trueString s4 = "11";System.out.println(s4 == s3.intern());//trueSystem.out.println(s3 == s4);//true
4、String典型案例[极其易混点]
4.1、关于equals和== :
1、对于==,如果作用于基本数据类型的变量(byte,short,char,int,long,float,double,boolean ),则直接比较其存储的"值"是否相等;如果作用于引用类型的变量(String),则比较的是所指向的对象的地址(即是否指向同一个对象)。2、equals方法是基类Object中的方法,因此对于所有的继承于Object的类都会有该方法。在Object类中,equals方法是用来比较两个对象的引用是否相等。对于equals方法,注意:equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;而String类对equals方法进行了重写,用来比较指向的字符串对象所存储的字符串是否相等。其他的一些类诸如Double,Date,Integer等,都对equals方法进行了重写用来比较指向的对象所存储的内容是否相等。
4.2、[细细品尝]代码示例:
public class StringTest {public static void main(String[] args) {/*** 情景一:字符串池* JAVA虚拟机(JVM)中存在着一个字符串池,其中保存着很多String对象(1.7之后他只存引用了);* 并且可以被共享使用,因此它提高了效率。* 由于String类是final的,它的值一经创建就不可改变。* 字符串池由String类维护,我们可以调用intern()方法来访问字符串池。*/String s1 = "abc";//在字符串池创建了一个对象String s2 = "abc"; //字符串pool已经存在对象“abc”(共享),所以创建0个对象,累计创建一个对象System.out.println("s1 == s2 : "+(s1==s2));//true 指向同一个对象System.out.println("s1.equals(s2) : " + (s1.equals(s2)));//true 值相等//↑------------------------------------------------------over/*** 情景二:关于new String("")*/String s3 = new String("abc");//创建了两个对象,一个存放在字符串池中,一个存在与堆区中;//↑还有一个对象引用s3存放在栈中String s4 = new String("abc");//↑字符串池中已经存在“abc”对象,所以只在堆中创建了一个对象System.out.println("s3 == s4 : "+(s3==s4));//↑false s3和s4栈区的地址不同,指向堆区的不同地址;System.out.println("s3.equals(s4) : "+(s3.equals(s4)));//↑true s3和s4的值相同System.out.println("s1 == s3 : "+(s1==s3));//↑false 存放的地区多不同,一个栈区,一个堆区System.out.println("s1.equals(s3) : "+(s1.equals(s3)));//↑true 值相同//↑------------------------------------------------------over/*** 情景三:* 由于常量的值在编译的时候就被确定(优化)了。* 在这里,"ab"和"cd"都是常量,因此变量str3的值在编译时就可以确定。* 这行代码编译后的效果等同于: String str3 = "abcd";*/String str1 = "ab" + "cd"; //1个对象String str11 = "abcd";System.out.println("str1 = str11 : "+ (str1 == str11));//true↑------------------------------------------------------over/*** 情景四:* 局部变量str2,str3存储的是存储两个拘留字符串对象(intern字符串对象)的地址。** 第三行代码原理(str2+str3):* 运行期JVM首先会在堆中创建一个StringBuilder类,* 同时用str2指向的拘留字符串对象完成初始化,* 然后调用append方法完成对str3所指向的拘留字符串的合并,* 接着调用StringBuilder的toString()方法在堆中创建一个String对象,* 最后将刚生成的String对象的堆地址存放在局部变量str4中。** 而str5存储的是字符串池中"abcd"所对应的拘留字符串对象的地址。* str4与str5地址当然不一样了。** 内存中实际上有五个字符串对象:* 三个拘留字符串对象、一个String对象和一个StringBuilder对象。*/String str2 = "ab"; //1个对象String str3 = "cd"; //1个对象String str4 = str2+str3;String str5 = "abcd";System.out.println("str4 = str5 : " + (str4==str5)); // false//↑------------------------------------------------------over/*** 情景五:* JAVA编译器对string + 基本类型/常量 是当成常量表达式直接求值来优化的。* 运行期的两个string相加,会产生新的对象的,存储在堆(heap)中*/String str6 = "b";String str7 = "a" + str6;String str67 = "ab";System.out.println("str7 = str67 : "+ (str7 == str67));//↑str6为变量,在运行期才会被解析。结果为falsefinal String str8 = "b";String str9 = "a" + str8;String str89 = "ab";System.out.println("str9 = str89 : "+ (str9 == str89));//↑str8为常量变量,编译期会被优化,结果为true//↑------------------------------------------------------over}}
5、参考资料及精品文章:
5.1、本文主要参考资料
https://blog.csdn.net/qq_34490018/article/details/82110578
5.2、面试题看这个吧
https://www.cnblogs.com/rese-t/p/8024166.html
自己记录的:https://www.yuque.com/moercheng/eig6e7/eeawz75.3、深入理解Java String类
https://blog.csdn.net/ifwinds/article/details/80849184
5.4、intern方法的介绍
https://www.cnblogs.com/feizhai/p/10196955.html
5.5、主要了解一些字节码的意思
https://zhuanlan.zhihu.com/p/107776367
自己记录的:https://www.yuque.com/moercheng/xgug88/lblrxh

若有收获,就点个赞吧
0 人点赞
