- 1、集合和数组-比较
- 2、确保一个集合不能被修改?
- 3、迭代器 Iterator
- 4、如何实现数组和 List 之间的转换?
- 5、为什么 ArrayList 的 elementData 加上 transient 修饰?
- 6、HashSet 的实现原理?
- 7、HashMap实现原理?
- 8、HashMap|Hashtable|ConcurrentHashMap原理与区别
- 9、Collections.sort和Arrays.sort的实现原理
- 10、哪些集合类是线程安全的?哪些不安全?
- 11、快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
- 12、ArrayList 的扩容机制
- 13、ArrayList与LinkedList的区别
1、集合和数组-比较
1、数组声明了它容纳的元素的类型,而集合不声明。2、数组是静态的,一个数组实例具有固定的大小,一旦创建了就无法改变容量了。而集合是可以动态扩展容量,可以根据需要动态改变大小,集合提供更多的成员方法,能满足更多的需求。3、数组的存放的类型只能是一种(基本类型/引用类型),集合存放的类型可以不是一种(不加泛型时添加的类型是Object)[基本数据类型需使用其对应的包装类]。4、数组无法判断其中实际存有多少元素,length只告诉了array的容量。5、数组是java语言中内置的数据类型,是线性排列的,执行效率或者类型检查都是最快的。
2、确保一个集合不能被修改?
1、很容易想到用final关键字进行修饰,final修饰词-知识回顾:1-1、final关键字可以修饰类,方法,成员变量,1-2、final修饰的类不能被继承,final修饰的方法不能被重写,final修饰的成员变量必须初始化值。1-3、如果这个成员变量是基本数据类型,表示这个变量的值是不可改变的,如果说这个成员变量是引用类型,则表示这个引用的地址值是不能改变的,但是这个引用所指向的对象里面的内容还是可以改变的。2、前提知识点:2-1、集合(map,set,list…)都是引用类型,所以我们如果用final修饰的话,集合里面的内容还是可以修改的。3、采用Collections包下的unmodifiableMap方法,3-1、通过这个方法返回的map,是不可以修改的。他会报 java.lang.UnsupportedOperationException错。3-2、Collections包也提供了对list和set集合的方法。3-2-1、ollections.unmodifiableList(List)3-2-2、ollections.unmodifiableSet(Set)4、代码示例List<String> list = new ArrayList<>();list. add("x");Collection<String> clist = Collections. unmodifiableCollection(list);clist. add("y"); // 运行时此行报错System. out. println(list. size());
3、迭代器 Iterator
1、迭代器 Iterator -概述1-1、Iterator 接口提供遍历任何 Collection 的接口。我们可以从一个 Collection 中使用迭代器方法来获取迭代器实例。迭代器取代了 Java 集合框架中的 Enumeration,迭代器允许调用者在迭代过程中移除元素。1-2、Iterator-特点1-2-1、只能单向遍历。1-2-2、可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。1-3、代码示例List<String> list = new ArrayList<>();Iterator<String> it = list. iterator();while(it. hasNext()){String obj = it. next();System. out. println(obj);}————————————————2、如何边遍历边移除 Collection 中的元素?2-1、使用 Iterator.remove() 方法Iterator<Integer> it = list.iterator();while(it.hasNext()){*// do something*it.remove();}3、Iterator 和 ListIterator 有什么区别?3-1、Iterator 可以遍历 Set 和 List 集合,而 ListIterator 只能遍历 List。3-2、Iterator 只能单向遍历,而 ListIterator 可以双向遍历(向前/后遍历)。3-3、ListIterator 实现 Iterator 接口,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
3.1、如何边遍历边移除 Collection 中的元素?
2、如何边遍历边移除 Collection 中的元素?2-1、使用 Iterator.remove() 方法Iterator<Integer> it = list.iterator();while(it.hasNext()){*// do something*it.remove();}
3.2、Iterator 和 ListIterator 有什么区别?
3、Iterator 和 ListIterator 有什么区别?3-1、Iterator 可以遍历 Set 和 List 集合,而 ListIterator 只能遍历 List。3-2、Iterator 只能单向遍历,而 ListIterator 可以双向遍历(向前/后遍历)。3-2-1、ListIterator遍历可以是逆向的,因为有previous()和hasPrevious()方法3-3、ListIterator 实现 Iterator 接口,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。3-3-1、ListIterator可以定位当前的索引位置,因为有nextIndex()和previousIndex()方法。3-3-2、ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历。3-3-3、ListIterator有add()方法,可以向List添加对象,而Iterator却不能。
3.3、comparable 和 comparator的区别?
1、comparable接口实际上是出自java.lang包,它有一个 compareTo(Object obj)方法用来排序1-1、源码示例public interface Comparable<T> {}2、comparator接口实际上是出自 java.util 包,它有一个compare(Object obj1, Object obj2)方法用来排序2-1、源码示例@FunctionalInterfacepublic interface Comparator<T> {}3、需要对一个集合使用自定义排序时,我们就要3-1、重写compareTo方法或compare方法3-2、使用两个参数版的Collections.sort().
4、如何实现数组和 List 之间的转换?
1、数组转 List:使用 Arrays.asList(array) 进行转换。2、List 转数组:使用 List 自带的 toArray() 方法。【返回值只能是 Object[] 类,强转其他类型可能有问题】
5、为什么 ArrayList 的 elementData 加上 transient 修饰?
private transient Object[] elementData;1、原因分析:1-1、transient 的作用是说不希望 elementData 数组被序列化,重写了 writeObject 实现:private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{int expectedModCount = modCount;s.defaultWriteObject();s.writeInt(elementData.length);for (int i=0; i<size; i++)s.writeObject(elementData[i]);if (modCount != expectedModCount) {throw new ConcurrentModificationException();}1-2、每次序列化时,先调用 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小。
6、HashSet 的实现原理?
1、HashSet 的实现原理?1-1、HashSet 是基于 HashMap 实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为PRESENT。1-2、相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。2、HashSet如何检查重复?HashSet是如何保证数据不可重复的?2-1、向HashSet 中add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equles 方法比较。HashSet 中的add ()方法会使用HashMap 的put()方法。2-1-1、HashMap的put方法的返回值为null或者value。如果put成功的话返回null,如果put失败的话,说明put的key已经存在了,就会返回已经存在该key的value值。private static final Object PRESENT = new Object();public boolean add(E e) {//PRESENT是一个至始至终都相同的虚值return map.put(e, PRESENT)==null;}2-1-2、底层是调用了了HashMap的remove方法,我们知道hashmap的remove方法会返回该key对应的value值。public boolean remove(Object o) {return map.remove(o)==PRESENT;}3、Object PRESENT的作用:3-1、HashMap底层的value保存的都是null的话,那么remove成功或者是失败都会返回null,这时候就会出现与add同样无法区分的问题,无法区分remove是成功还是失败了!3-1-1、源码示例private static final Object PRESENT = new Object();public boolean add(E e) {//PRESENT是一个至始至终都相同的虚值return map.put(e, PRESENT)==null;}public boolean remove(Object o) {return map.remove(o)==PRESENT;}
6.1、HashSet如何检查并保证数据不可重复?
2、HashSet如何检查重复?HashSet是如何保证数据不可重复的?2-1、向HashSet 中add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equles 方法比较。HashSet 中的add ()方法会使用HashMap 的put()方法。2-1-1、HashMap的put方法的返回值为null或者value。如果put成功的话返回null,如果put失败的话,说明put的key已经存在了,就会返回已经存在该key的value值。private static final Object PRESENT = new Object();public boolean add(E e) {//PRESENT是一个至始至终都相同的虚值return map.put(e, PRESENT)==null;}2-1-2、底层是调用了了HashMap的remove方法,我们知道hashmap的remove方法会返回该key对应的value值。public boolean remove(Object o) {return map.remove(o)==PRESENT;}
6.2、HashSet中 Object PRESENT的作用
3、Object PRESENT的作用:3-1、HashMap底层的value保存的都是null的话,那么remove成功或者是失败都会返回null,这时候就会出现与add同样无法区分的问题,无法区分remove是成功还是失败了!3-1-1、源码示例private static final Object PRESENT = new Object();public boolean add(E e) {//PRESENT是一个至始至终都相同的虚值return map.put(e, PRESENT)==null;}public boolean remove(Object o) {return map.remove(o)==PRESENT;}
7、HashMap实现原理?
1、HashMap实现原理-概述1-1、基于哈希表/散列表的Map接口的非同步[线程不安全]实现。此实现提供所有可选的映射操作,并允许使用null值和null键。HashMap储存的是键值对,HashMap很快。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。1-2、数组[内部实现数组是Node[]数组]+链表/红黑树2、链表转红黑树的优点2-1、从原来的O(n)到O(logn)3、JDK1.8之前采用的是拉链法。3-1、拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。3-2、
7.1、Map-jdk1.7与jdk1.8比较
1、JDK1.8主要解决或优化了一下问题:1-1、resize 扩容优化1-1-1、当Map中元素总数超过Entry数组的75%,触发扩容操作1-1-2、jdk1.7中是先扩容后插入新值的,jdk1.8中是先插值再扩容1-2、引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考1-3、解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。2、Map-jdk1.7与jdk1.8比较:2-1、存放数据的规则2-1-1、jdk1.7、无冲突时,存放数组;冲突时,存放链表2-1-2、jdk1.8、无冲突时,存放数组;冲突 & 链表长度 < 7:存放单链表;冲突 & 链表长度 >= 7:树化并存放红黑树。【红黑树转换是链表节点大于7且数组长度大于64,小于64进行扩容】2-2、插入数据方式2-2-1、头插法(先讲原位置的数据移到后1位,再插入数据到该位置)。2-2-2、尾插法(直接插入到链表尾部/红黑树)。
7.2、HashMap的put方法的具体流程?
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}//实现Map.put和相关方法/**1.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;2.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向6,如果table[i]不为空,转向3;3.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向4,这里的相同指的是hashCode以及equals;4.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向5;5.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;6.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 步骤①:tab为空则创建// table未初始化或者长度为0,进行扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 步骤②:计算index,并对null做处理// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// 桶中已经存在元素else {Node<K,V> e; K k;// 步骤③:节点key存在,直接覆盖value// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 将第一个元素赋值给e,用e来记录e = p;// 步骤④:判断该链为红黑树// hash值不相等,即key不相等;为红黑树结点// 如果当前元素类型为TreeNode,表示为红黑树,putTreeVal返回待存放的node, e可能为nullelse if (p instanceof TreeNode)// 放入树中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 步骤⑤:该链为链表// 为链表结点else {// 在链表最末插入结点for (int binCount = 0; ; ++binCount) {// 到达链表的尾部//判断该链表尾部指针是不是空的if ((e = p.next) == null) {// 在尾部插入新结点p.next = newNode(hash, key, value, null);//判断链表的长度是否达到转化红黑树的临界值,临界值为8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//链表结构转树形结构treeifyBin(tab, hash);// 跳出循环break;}// 判断链表中结点的key值与插入的元素的key值是否相等if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 相等,跳出循环break;// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表p = e;}}//判断当前的key已经存在的情况下,再来一个相同的hash值、key值时,返回新来的value这个值if (e != null) {// 记录e的valueV oldValue = e.value;// onlyIfAbsent为false或者旧值为nullif (!onlyIfAbsent || oldValue == null)//用新值替换旧值e.value = value;// 访问后回调afterNodeAccess(e);// 返回旧值return oldValue;}}// 结构性修改++modCount;// 步骤⑥:超过最大容量就扩容// 实际大小大于阈值则扩容if (++size > threshold)resize();// 插入后回调afterNodeInsertion(evict);return null;}
7.2.1、HashMap的put方法-执行流程-示意图
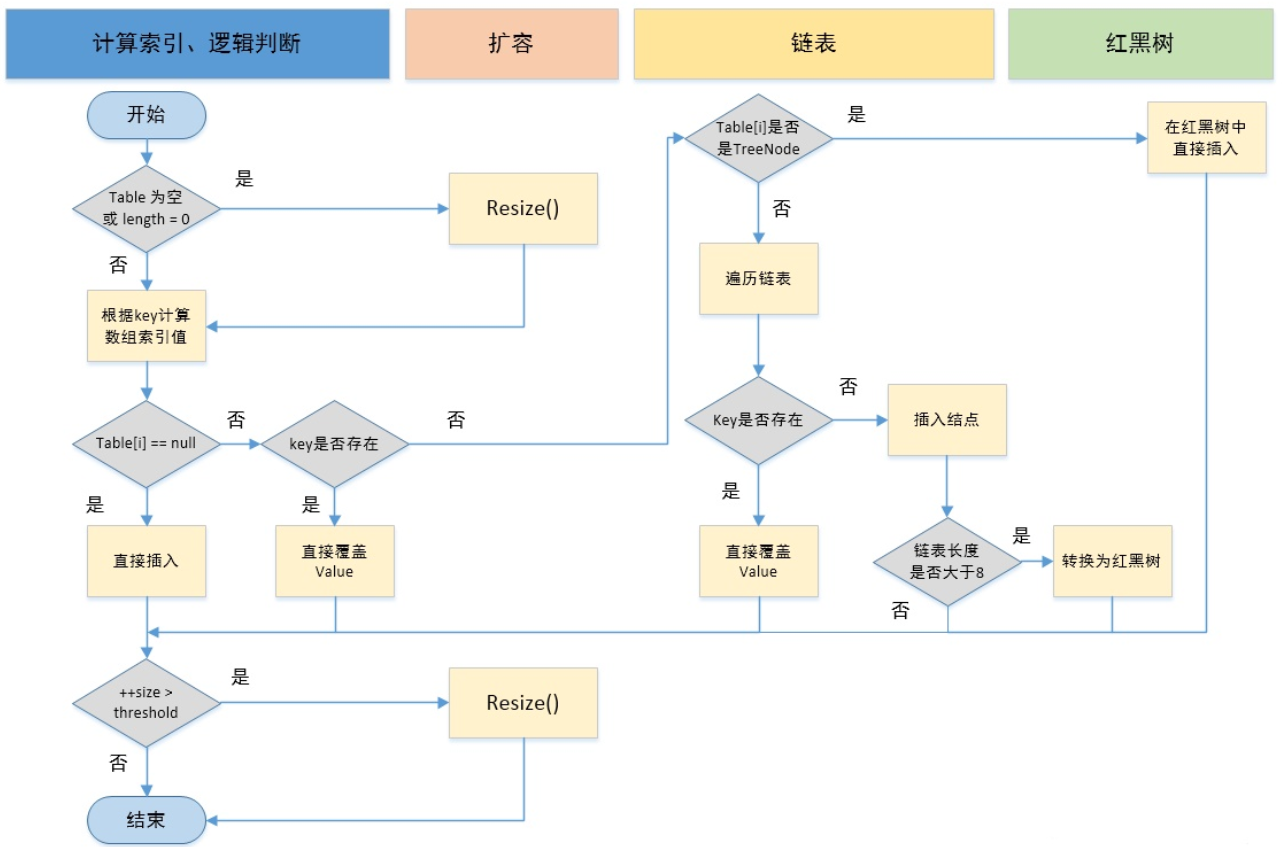
7.3、HashMap是怎么解决哈希冲突的?
1、什么是哈希冲突/碰撞?1-1、当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞)。2、哈希冲突/碰撞-解决方式2-1、链地址法/拉链法的方式可以解决哈希冲突2-1-1、本质:数组+链表的形式来解决。put执行首先判断table[i]位置,如果为空就直接插入,不为空判断和当前值是否相等,相等就覆盖,如果不相等的话,判断是否是红黑树节点,如果不是,就从table[i]位置开始遍历链表,相等覆盖,不相等插入。2-1-2、将拥有相同哈希值的对象组织成一个链表放在hash值所对应的bucket下[只是单纯的用hashCode取余来获取对应的bucket]。2-2、相比在1.7中的4次位运算,5次异或运算(9次扰动),在1.8中,只进行了1次位运算和1次异或运算(2次扰动);2-2-1、源码:static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}2-3、在jdk1.8中,如果链表长度大于8且节点数组长度大于64的时候,就把链表下所有的节点转为红黑树。3、HashMap是使用了哪些方法来有效解决哈希冲突的:3-1. 使用链地址法(使用散列表)来链接拥有相同hash值的数据;3-2. 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;3-3. 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;
7.4、HashMap为什么不直接使用hashCode()处理后的哈希值直接作为table的下标?
1、原因:1-1、hashCode()方法返回的是int整数类型,其范围为-(2 ^ 31)~(2 ^ 31 - 1),约有40亿个映射空间,而HashMap的容量范围是在16(初始化默认值)~2 ^ 30,HashMap通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;2、解决办法32-1、HashMap自己实现了自己的hash()方法,通过两次扰动使得它自己的哈希值高低位自行进行异或运算,降低哈希碰撞概率也使得数据分布更平均;2-2、在保证数组长度为2的幂次方的时候,使用hash()运算之后的值与运算(&)(数组长度 - 1)来获取数组下标的方式进行存储;2-2-1、这样一来是比取余操作更加有效率,2-2-2、二来也是因为只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length,2-2-3、三来解决了"哈希值与数组大小范围不匹配"的问题;
7.5、HashMap 的长度为什么是2的幂次方?
1、原因1-1、为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。1-2、源码:.putVal()方法中if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {//......}1-3、采用二进制位操作 &,相对于%能够提高运算效率1-3-1、取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作1-3-2、 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;
7.6、为什么说HashMap是线程不安全的?
1、在接近临界点时,若此时两个或者多个线程进行put操作,都会进行resize(扩容)和reHash(在接近临界点时,若此时两个或者多个线程进行put操作,都会进行resize(扩容)和reHash(为key重新计算所在位置),而reHash在并发的情况下可能会形成链表环。为key重新计算所在位置),而reHash在并发的情况下可能会形成链表环。2、在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,3、是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
7.7、HashMap 链表和红黑树互转条件
1、HashMap 链表转红黑树条件1-1、一个是链表长度大于等于7:是为了作为缓冲,可以有效防止链表和树频繁转换。static final int TREEIFY_THRESHOLD = 8;if (binCount >= TREEIFY_THRESHOLD - 1){treeifyBin(tab, hash);}1-2、一个是数组长度到64,数组长度小于64则进行扩容,否则转红黑树static final int MIN_TREEIFY_CAPACITY = 64;final void treeifyBin(Node<K,V>[] tab, int hash) {if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {//.......}}2、HashMap 红黑树转链表条件2-1、当链表中节点数量小于等于UNTREEIFY_THRESHOLD[6]时,红黑树会转成链表。2-2、源码示例:static final int UNTREEIFY_THRESHOLD = 6;if (lc <= UNTREEIFY_THRESHOLD)tab[index] = loHead.untreeify(map);}
8、HashMap|Hashtable|ConcurrentHashMap原理与区别
8.1、ConcurrentHashMap 和 Hashtable 的区别
1、底层数据结构:1-1、JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,1-2、JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。1-3、Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;2、实现线程安全的方式(重要):2-1、在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。)2-2、到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;2-3、Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。3、继承关系不同3-1、Hashtable继承自Dictionary 类,实现了Map接口-- public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>,Cloneable, java.io.Serializable {}3-2、ConcurrentHashMap继承AbstractMap,实现了CocurrentMap接口-- public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>implements ConcurrentMap<K,V>, Serializable {}
8.2、HashMap和ConcurrentHashMap的原理与区别
1、继承关系不同1-1、HashMap继承自AbstractMap类,实现了Map接口-- public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>,Cloneable, Serializable {}1-2、ConcurrentHashMap继承AbstractMap,实现了CocurrentMap接口-- public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>implements ConcurrentMap<K,V>, Serializable {}2、底层数据结构-细节上-不同2-1、jdk1.7:2-1-1、ConcurrentHashMap由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。-- Segment 数组,存放数据时首先需要定位到具体的 Segment 中。-- final Segment<K,V>[] segments;-- Segment 是 ConcurrentHashMap 的一个内部类: Segment 继承于 ReentrantLock,包含一个Entry<K,V>结构,其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。static final class Segment<K,V> extends ReentrantLock implements Serializable {//HashMap 中的 HashEntry 作用一样,真正存放数据的桶transient volatile HashEntry<K,V>[] table;//......}2-2、jdk1.8:2-2-1、放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点。-- Node<K,V>transient volatile Node<K,V>[] table;-- CASstatic final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);}-- SynchronizedNode<K,V> fsynchronized (f) {//......}2-2-2、因为红黑树在旋转过程中,会改变root节点,所以ConcurrentHashMap加了个treeBin对象,其hash值为-2,所以才可以根据数组下标的hash>=0判断其为链表。-- 源码示例//treeBin对象:在垃圾箱的顶部使用的树状物static final class TreeBin<K,V> extends Node<K,V> {//.putVal()方法中else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2; // 代表链表长度if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}
8.3、HashMap和Hashtable的区别
1、HashMap、Hashtable的区别1-1、继承的父类不同:1-1-1、HashMap 继承自AbstractMap 类;而HashTable 继承自Dictionary 类1-2、key和value是否允许null值1-2-1、HashMap 允许Key/Value 都为null,Hashtable的Key/Value 都不允许为null。1-3、线程安全性不同1-3-1、Hashtable 中的方法是Synchronized的,而HashMap中的方法在缺省情况下是非Synchronized的。应该使用 Collections.synchronizedMap 方法"来包装"该映射。-- Map m = Collections.synchronizedMap(new HashMap(...));1-4、是否提供contains方法1-4-1、HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。1-4-2、Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。1-5、遍历方式的内部实现上不同1-5-1、Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。-- 代码示例Enumeration enumkey = hash.keys() ;while(enumkey.hasMoreElements()){String str=(String)enumkey.nextElement();System.out.println("--------"+str);System.out.println("========="+hash.get( str));if("1".equals(hash.get( str))){hash.remove( str);}}1-6、内部实现使用的数组初始化和扩容方式不同1-6-1、HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。1-6-2、Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。1-7、计算index下标方法不同1-7-1、Hashtable计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length1-7-2、HashMap计算index方法:index = hash & (tab.length – 1)
9、Collections.sort和Arrays.sort的实现原理
1、Collections.sort是对list进行排序,Arrays.sort是对数组进行排序。2、Collections.sort-底层实现2-1、Collections.sort方法调用了list.sort方法2-1-1、源码示例public static <T> void sort(List<T> list, Comparator<? super T> c) {list.sort(c);}@SuppressWarnings({"unchecked", "rawtypes"})default void sort(Comparator<? super E> c) {Object[] a = this.toArray();Arrays.sort(a, (Comparator) c);ListIterator<E> i = this.listIterator();for (Object e : a) {i.next();i.set((E) e);}}3、Arrays.sort底层实现:JDK1.73-1、legacyMergeSort(a),归并排序,3-2、ComparableTimSort.sort():即Timsort排序。3-2-1、结合了合并排序(merge.sort)和插入排序(insertion sort)而得出的排序方法。
10、哪些集合类是线程安全的?哪些不安全?
1、线程安全类Vector:比Arraylist多了个同步化机制。Vector是扩展1倍Hashtable:比Hashmap多了个线程安全。ConcurrentHashMap:是一种高效但是线程安全的集合。Stack:栈,也是线程安全的,继承于Vector。2、非线程安全类HashmapArraylist:在底层数组不够用时在原来的基础上扩展0.5倍,即 扩容至原来的1.5倍LinkedList:底层数据结构是双向链表,具体看源码HashSetTreeSetTreeMap
11、快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
1、快速失败1-1、在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。2、安全失败2-1、采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。2-1-1、在java.util.concurrent 并发包的集合,如 ConcurrentHashMap, CopyOnWriteArrayList等,默认为都是安全失败的。
12、ArrayList 的扩容机制
1、在底层数组不够用时在原来的基础上扩展0.5倍,即 扩容至原来的1.5倍。2、ArrayList 的扩容机制本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。3、ArrayList 的默认大小是 10 个元素private static final int DEFAULT_CAPACITY = 10;4、源码public boolean add(E e) {//扩容ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}private void ensureCapacityInternal(int minCapacity) {ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {//如果传入的是个空数组则最小容量取默认容量与minCapacity之间的最大值if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;}private void ensureExplicitCapacity(int minCapacity) {modCount++;// 如果最小需要空间比elementData的内存空间要大,则需要扩容// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity);}private void grow(int minCapacity) {// 获取elementData数组的内存空间长度int oldCapacity = elementData.length;// 扩容至原来的1.5倍int newCapacity = oldCapacity + (oldCapacity >> 1);//校验容量是否够if (newCapacity - minCapacity < 0)newCapacity = minCapacity;//若预设值大于默认的最大值,检查是否溢出if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 调用Arrays.copyOf方法将elementData数组指向新的内存空间//并将elementData的数据复制到新的内存空间elementData = Arrays.copyOf(elementData, newCapacity);}
13、ArrayList与LinkedList的区别
1、ArrayList与LinkedList的继承关系1-1、ArrayList的继承关系public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {}1-2、LinkedList的继承关系public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}2、ArrayList与LinkedList的区别2-1、ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。2-2、ArrayList随机访问集合元素上有较好的性能(RandomAccess接口),LinkedList插入、删除数据效率高。2-3、存储:LinkedList比ArrayList更占内存,因为LinkedList每一个节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向下一个元素。2-4、查找:ArrayList随机访问元素的时间复杂度为o(1);LinkedList查找某个元素的时间复杂度是o(n)。2-5、都具有:有序,允许存null值,允许重复值可以; list存储的类型是object,null属于object类型。

若有收获,就点个赞吧
0 人点赞
