1、Java-Map-概述
1、Map是一个接口,也称为双列集合,它的每个元素都包含一个键对象Key和值对象Value,键和值对象之间存在一种对应关系,称为映射。public interface Map<K,V> {}2、Map中的key值可看成Set集合,是无序且不能重复的,value值可看成List,可重复,每个元素可根据索引来找,只是这个索引是以另一个对象作为索引的。3、key-value 可以是任何引用类型的数据,且key不允许重复,value可以重复,插入两个键值相同记录时,那么后插入的记录会覆盖先插入的记录并将先插入的记录返回 。/*** 当插入的key相同时,后插入的记录会覆盖掉先插入的记录,并将先插入的记录返回*/public class MapDemo {public static void main(String[] args){Map<String,String> map = new Hashtable<String,String>();String str1 = map.put("1","张三");String str2 = map.put("2","李四");String str3 = map.put("2","陈汉");System.out.println(str1);//输出:nullSystem.out.println(str2);//输出:nullSystem.out.println(str3);//输出:李四System.out.println(map);// 输出:{2=陈汉, 1=张三}}}
1-1、Java-Map-Map中的常用方法
void clear();//删除该Map对象中所有键值对;boolean containsKey(Object key);//查询Map中是否包含指定的key值;boolean containsValue(Object value);//查询Map中是否包含一个或多个value;Set entrySet();//返回map中包含的键值对所组成的Set集合,每个集合都是Map.Entry对象。Object get();//返回指定key对应的value,如果不包含key则返回null;boolean isEmpty();//查询该Map是否为空;Set keySet();//返回Map中所有key组成的集合;Collection values();//返回该Map里所有value组成的Collection。Object put(Object key,Object value);//添加一个键值对,如果集合中的key重复,则覆盖原来的键值对;void putAll(Map m);//将Map中的键值对复制到本Map中;Object remove(Object key);//删除指定的key对应的键值对,并返回被删除键值对的value,如果不存在,则返回null;boolean remove(Object key,Object value);//删除指定键值对,删除成功返回true;int size();//返回该Map里的键值对个数;
1-2、Java-Map-内部类Entry
1、Map中包括一个内部类Entry,该类封装一个键值对,常用方法:Object getKey():返回该Entry里包含的key值;Object getvalue():返回该Entry里包含的value值;Object setValue(V value):设置该Entry里包含的value值,并设置新的value值。2、源码:/*** Map内部类Entry,封装了一个键值对*/Set<Map.Entry<K, V>> entrySet();/*** Map有个内部接口:Entry,*/interface Entry<K,V> {Object getKey();//返回该Entry里包含的key值;Object getvalue();//返回该Entry里包含的value值;Object setValue(V value);//设置该Entry里包含的value值,并设置新的value值。}3、Demo/*** 例子:*/public class MapDemo1 {public static void main(String[] args){Map<String, Integer> hm = new HashMap<String, Integer>();//放入元素hm.put("Harry",23);hm.put("Jenny",24);hm.put("XiaoLi",20);System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24}System.out.println(hm.keySet());//[XiaoLi, Harry, Jenny]System.out.println(hm.values());//[20, 23, 24]Set<Map.Entry<String, Integer>> entries = hm.entrySet();for (Map.Entry<String, Integer> entry : entries) {System.out.println(entry.getKey());//XiaoLi, Harry, JennySystem.out.println(entry.getValue());//20, 23, 24entry.setValue(50); //设置该Entry中包含的value值为50System.out.println(hm);//最后为{XiaoLi=50, Harry=50, Jenny=50}}}}
1-3、Java-Map-java8新增方法
/*** Object compute(Object key,BiFurcation remappingFunction);使用remappingFunction根据原键* 值对计算一个新的value,只要新value不为null,就覆盖原value;如果新value为null则删除该键值对,如果同* 时为null则不改变任何键值对,直接返回null。*///例子public class MapDemo2 {public static void main(String[] args){Map<String, Integer> hm = new HashMap<String, Integer>();//放入元素hm.put("Harry",23);hm.put("Jenny",24);hm.put("XiaoLi",20);System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24}hm.compute("Harry",(key,value)->(Integer)value+10);System.out.println(hm);////{XiaoLi=20, Harry=33, Jenny=24}hm.compute("qwerty",(key,value)->(Integer)value+10);//Map集合没有该key时,会抛出空指针异常System.out.println(hm);//java.lang.NullPointerException}}/*** Object computeIfAbsent(Object key,Furcation mappingFunction):如果传给该方法的key参数在* Map中对应的value为null,则使用mappingFunction根据key计算一个新的结果,如果计算结果不为null,则计算* 结果覆盖原有的value,如果原Map原来不包含该Key,那么该方法可能会添加一组键值对。*///例子public class MapDemo3 {public static void main(String[] args){Map<String, Integer> hm = new HashMap<String, Integer>();//放入元素hm.put("Harry",23);hm.put("Jenny",24);hm.put("XiaoLi",20);hm.put("LiMing",null);//指定key为null则计算结果作为valuehm.computeIfAbsent("LiMing",(key)->10);System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24, LiMing=10}//如果指定key本来不存在,则添加对应键值对hm.computeIfAbsent("XiaoHong",(key)->34);System.out.println(hm);//{XiaoLi=20, Harry=23, XiaoHong=34, Jenny=24, LiMing=10}}}/*** Object computeIfPresent(Object key,BiFurcation remappingFunction):如果传给该方法的key* 参数在Map中对应的value不为null,则通过计算得到新的键值对,如果计算结果不为null,则覆盖原来的value,如* 果计算结果为null,则删除原键值对。*///例子public class MapDemo4 {public static void main(String[] args){Map<String, Integer> hm = new HashMap<String, Integer>();//放入元素hm.put("Harry",23);hm.put("Jenny",24);hm.put("XiaoLi",20);hm.put("LiMing",null);hm.computeIfPresent("Harry",(key,value)->(Integer)value*(Integer)value);System.out.println(hm);//{XiaoLi=20, Harry=529, Jenny=24, LiMing=null}}}/*** void forEach(BiConsumer action);遍历键值对。* Object getOrDefault(Object key,V defaultValue);* 获取指定key对应的value,如果key不存在则返回defaultValue;*///例子public class MapDemo5 {public static void main(String[] args){HashMap<String, Integer> hm = new HashMap<>();//放入元素hm.put("Harry",23);hm.put("Jenny",24);hm.put("XiaoLi",20);hm.put("LiMing",null);hm.forEach((key,value)-> System.out.println(key+"->"+value));/*XiaoLi->20Harry->23Jenny->24LiMing->null*/System.out.println(hm.getOrDefault("Harry",33));//23System.out.println(hm.getOrDefault("Liu",33));//33}}/*** Object merge(Object key,Object value,BiFurcation remappingFunction):该方法会先根据key参* 数获取该Map中对应的value。如果获取的value为null,则直接用传入的value覆盖原有的value,如果获取的* value不为null,则使用remappingFunction函数根据原value、新value计算一个新的结果,并用得到的结果去* 覆盖原有的value。*///例子public class MapDemo6 {public static void main(String[] args){HashMap<String, Integer> hm = new HashMap<>();//放入元素hm.put("Harry",23);hm.put("Jenny",24);hm.put("XiaoLi",20);hm.put("LiMing",null);hm.merge("LiMing",44,(key,value)->value+20);System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24, LiMing=24}hm.merge("Harry",44,(key,value)->value+10);System.out.println(hm);//{XiaoLi=20, Harry=54, Jenny=24, LiMing=24}}}/*** Object putIfAbsent(Object key,Object value);该方法会自动检测指定key对应的value是否为null,* 如果为null,则用新value去替换原来的null值。* Object replace(Object key,Object value);将key对应的value替换成新的value,如果key不存在则返回* null。* boolean replace(K key,V oldValue,V newValue);将指定键值对的value替换成新的value,如果未找到则* 返回false;* replaceAll(BiFunction Function);使用BiFunction对原键值对执行计算,并将结果作为该键值对的value* 值。*/
1-4、Java-Map-遍历
1、Map遍历的方式有4种,分别是:1-1、使用for循环/foreach循环遍历map;1-2、使用迭代器(Iterator)遍历map;[在遍历的过程中我们可以对集合中的元素进行删除。]1-3、使用keySet迭代遍历map;[效率很低,不推荐使用]1-4、使用entrySet遍历map。[性能最好]1-5、注意: Map集合不能直接使用迭代器或者foreach进行遍历。但是转成Set之后就可以使用了。(Iterable接口的所有子接口和实现类都能使用增强For循环遍历,而Map接口并不属于Iterable派系)。2、Demo:2-1、使用for循环遍历mappublic class Demo1 {public static void main(String[] args){Map<String, Integer> mapTest = new HashMap<>();//放入元素mapTest.put("Harry",23);mapTest.put("Jenny",24);mapTest.put("XiaoLi",20);mapTest.put("LiMing",null);for(Map.Entry<String, Integer> entry:mapTest.entrySet()){System.out.println(entry.getKey()+"--->"+entry.getValue());}/** XiaoLi--->20Harry--->23Jenny--->24LiMing--->null */}}2-2、使用迭代器(Iterator)遍历map;public class Demo2 {public static void main(String[] args){Map<String, Integer> mapTest = new HashMap<>();//放入元素mapTest.put("Harry",23);mapTest.put("Jenny",24);mapTest.put("XiaoLi",20);mapTest.put("LiMing",null);Set set = map.entrySet();Iterator i = set.iterator();while(i.hasNext()){Map.Entry<String, Integer> entry1=(Map.Entry<String, Integer>)i.next();System.out.println(entry1.getKey()+"=="+entry1.getValue());}/** XiaoLi--->20Harry--->23Jenny--->24LiMing--->null */}}2-3、使用keySet迭代遍历map:通过key去获取对应的value。【效率低】public class Demo3 {public static void main(String[] args){Map<String, Integer> mapTest = new HashMap<>();//放入元素mapTest.put("Harry",23);mapTest.put("Jenny",24);mapTest.put("XiaoLi",20);mapTest.put("LiMing",null);Set set = mapTest.keySet(); //得到map集合中所有的键值Iterator it = set.iterator();while(it.hasNext()){String key;Integer value;key=it.next().toString();//通过指定的键值,从map集合中获取对应的value值value=mapTest.get(key);System.out.println(key+"--"+value);}/** XiaoLi--->20Harry--->23Jenny--->24LiMing--->null */}}2-4、使用entrySet遍历map。public class Demo4 {public static void main(String[] args){Map<String, Integer> mapTest = new HashMap<>();//放入元素mapTest.put("Harry",23);mapTest.put("Jenny",24);mapTest.put("XiaoLi",20);mapTest.put("LiMing",null);String key;Integer value;//得到一个包含多个键值对元素的Set集合Set<Map.Entry<String, Integer>> entries = mapTest.entrySet();Iterator it = entries.iterator();while(it.hasNext()){Map.Entry entry = (Map.Entry)it.next();key=entry.getKey().toString();value= (Integer)entry.getValue();System.out.println(key+"===="+value);}for (Map.Entry<String, Integer> entry : mapTest.entrySet()) {System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());}/** XiaoLi====20Harry====23Jenny====24LiMing====nullkey= XiaoLi and value= 20key= Harry and value= 23key= Jenny and value= 24key= LiMing and value= null */}}
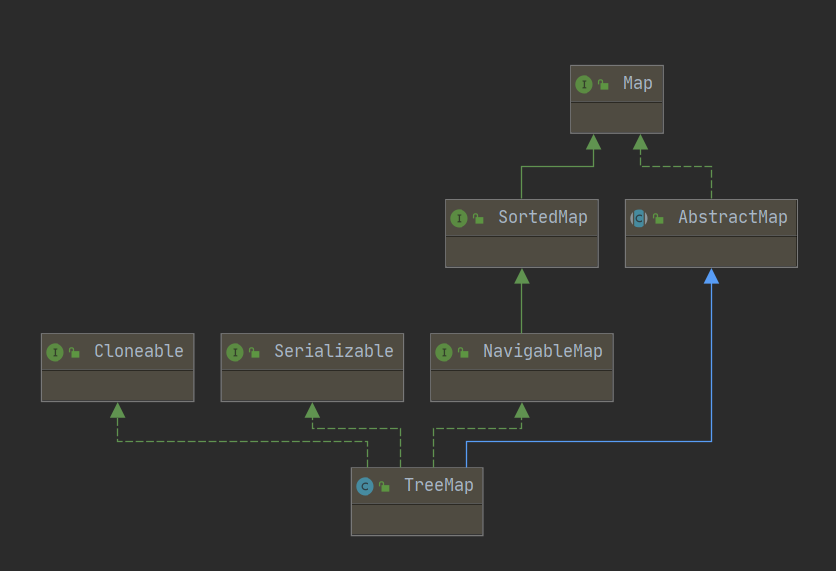
1-5、Java-Map-常用类继承结构图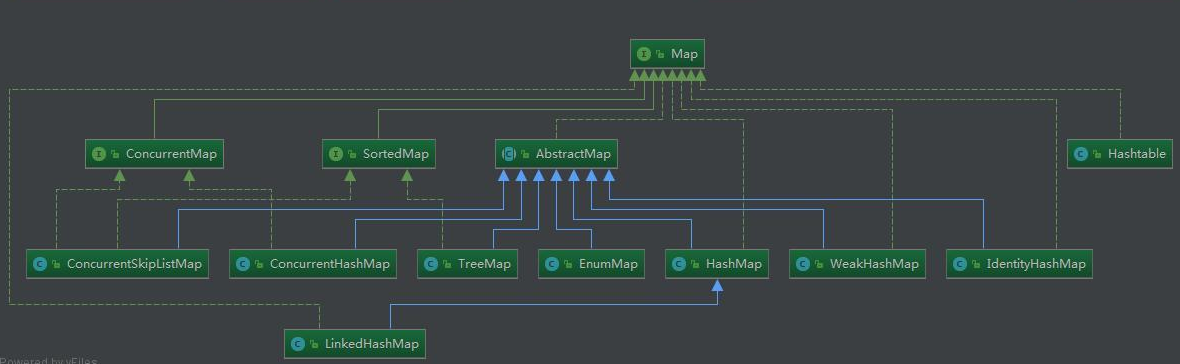
1-6、Java-Map-hashcode()|equals()-关系
1、hashcode()|equals()-关系:1-1、如果两个对象相等,那么它们的hashCode()值一定相同。这里的相等是指,通过equals()比较两个对象时返回true。1-2、如果两个对象hashCode()相等,它们并不一定相等。1-2-1、因为在散列表中,hashCode()相等,即两个键值对的哈希值相等。然而哈希值相等,并不一定能得出键值对相等。补充说一句:"两个不同的键值对,哈希值相等",这就是哈希冲突。(若要判断两个对象是否相等,除了要覆盖equals()之外,也要覆盖hashCode()函数。否则,equals()无效。)
2、Java-Map-HashMap-概述
1、HashMap-概述:1-1、HashMap是一个用于存储Key-Value键值对的集合,是一个散列表,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中。1-2、Hashmap继承自abstractmap,它的数据结构是数组和链表;1-3、HashMap是非同步的,也就意味着是非线程安装的,它的key、value都可以为null(null可以作为键,这样的键只有一个)。此外,HashMap中的映射不是有序的。1-4、HashMap 是一个利用哈希表原理来存储元素的集合。遇到冲突时,HashMap 是采用的链地址法来解决,在 JDK1.7 中,HashMap 是由 数组+链表构成的。但是在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,新增了红黑树作为底层数据结构。1-5、[容易忽视!!!]HashMap是无序的,迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。2、HashMap-继承关系:public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {}3、哈希冲突处理:3-1、采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。3-2、根据对冲突的处理方式不同,哈希表有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。Java HashMap采用的是冲突链表方式。
2-1、Java-Map-HashMap-继承关系-示意图
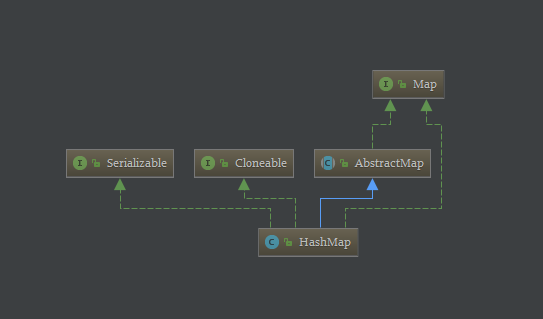
2-2、Java-Map-HashMap-工作原理
1、HashMap-相关概念1-1、HashMap中的两个重要的参数:HashMap中有两个重要的参数:初始容量大小和加载因子,初始容量大小是创建时给数组分配的容量大小,默认值为16,用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍(扩容)。1-2、在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树。2、HashMap-工作原理-简介2-1、HashMap基于哈希(hashing)原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。2-2、HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。2-3、当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。2-4、其他见源码分析......
2-3、Java-Map-HashMap-源码分析
2-4、Java-Map-HashMap-小结
1、HashMap-小结1-1、基于JDK1.8的HashMap是由数组+链表+红黑树组成,当链表长度超过 8 时会自动转换成红黑树,当红黑树节点个数小于 6 时,又会转化成链表。相对于早期版本的 JDK HashMap 实现,新增了红黑树作为底层数据结构,在数据量较大且哈希碰撞较多时,能够极大的增加检索的效率。1-2、允许 key 和 value 都为 null。key 重复会被覆盖,value 允许重复。1-3、非线程安全。1-4、无序(遍历HashMap得到元素的顺序不是按照插入的顺序)。1-5、扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。1-6、负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。1-7、哈希冲突,也叫哈希碰撞:如果两个不同的元素,通过哈希函数得出的实际存储地址相同。哈希冲突的解决方案有多种。 开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。1-8、HashMap 的Iterator 使用的是fail-fast 迭代器,当有其他线程改变了 HashMap 的结构(增加、删除、修改元素),将会抛出ConcurrentModificationException。
3、Java-Map-HashSet-概述
1、HashSet-概述1-1、HashSet是Java集合Set的一个实现类,Set是一个接口,其实现类除HashSet之外,还有TreeSet,并继承了Collection。1-2、元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。1-3、检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。2、HashSet-继承关系public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {}
3-1、Java-Map-HashSet-继承关系示意图
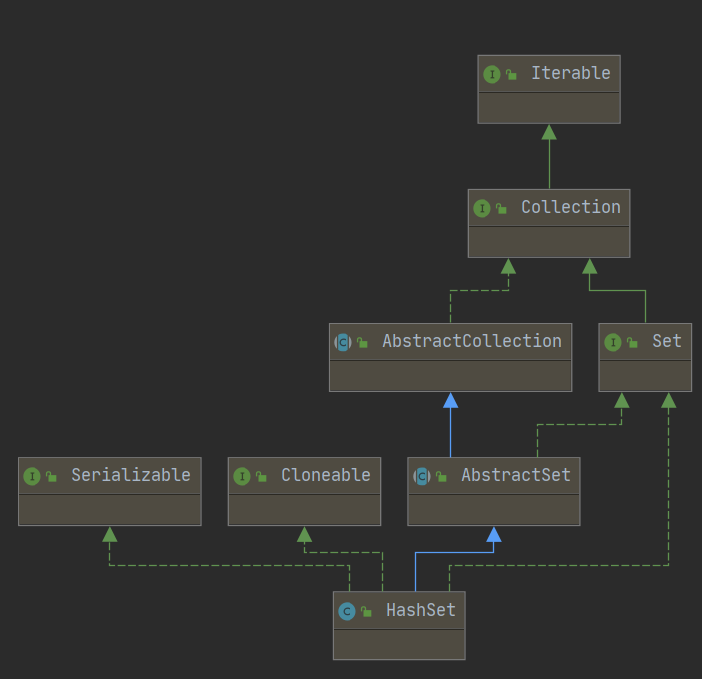
3-2、Java-Map-HashSet-实现原理
1、HashSet-实现原理-简介:1-1、是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。private transient HashMap<E,Object> map;//要与支持映射中的对象关联的伪值private static final Object PRESENT = new Object();//默认无参构造函数public HashSet() {map = new HashMap<>();}1-2、将这个类的对象放入 HashSet 中保存时,重写该类的equals(Object obj)方法和 hashCode() 方法很重要,而且这两个方法的返回值必须保持一致:当该类的两个的 hashCode() 返回值相同时,它们通过 equals() 方法比较也应该返回 true。
3-3、Java-Map-HashSet-源码分析
3-4、Java-Map-HashSet-小结
1、HashSet-小结:1-1、HashSet底层声明了一个HashMap,HashSet做了一层包装,操作HashSet里的元素时其实是在操作HashMap里的元素。
4、Java-Map-TreeSet-概述
1、TreeSet-概述:1-1、TreeSet 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。1-2、TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。1-3、TreeSet是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。1-4、TreeSet是一个有序的集合,它的作用是提供有序的Set集合。它继承了AbstractSet抽象类,实现了NavigableSet<E>,Cloneable,Serializable接口。2、TreeSet-继承关系:public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable {}
4-1、Java-Map-TreeSet-继承关系示意图
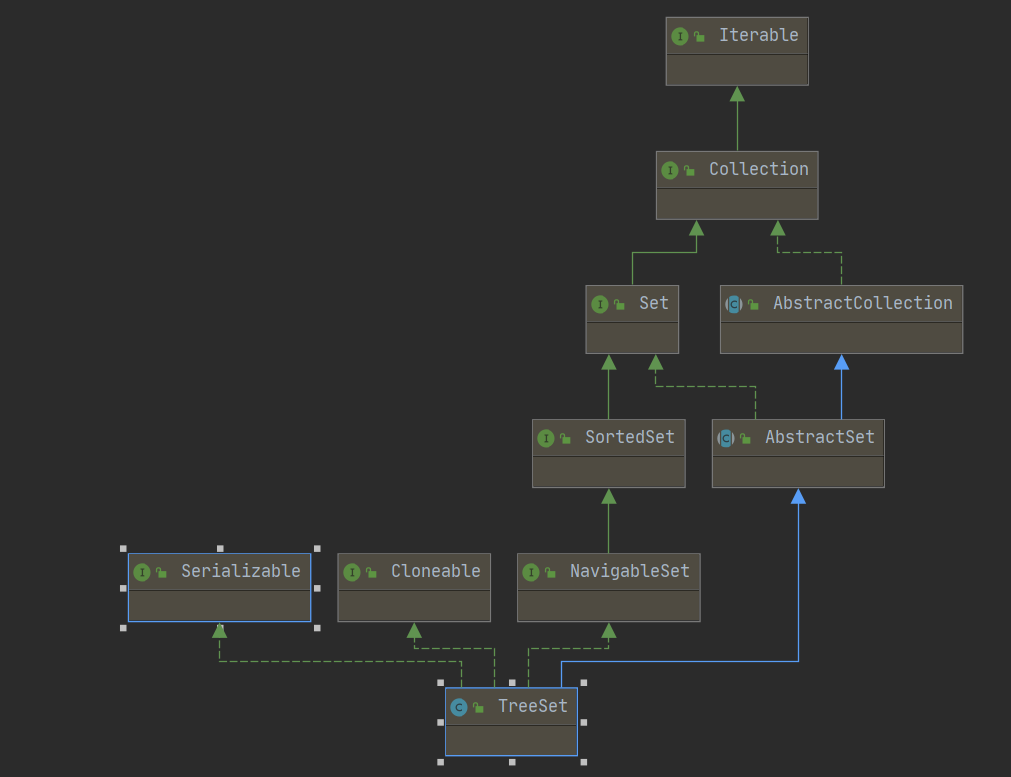
4-2、Java-Map-TreeSet-实现原理
1、TreeSet-实现原理:1-1、TreeSet存储对象的时候, 可以排序, 但是需要指定排序的算法1-2、Integer能排序(有默认顺序), String能排序(有默认顺序), 自定义的类存储的时候出现异常(没有顺序)1-3、如果想把自定义类的对象存入TreeSet进行排序, 那么必须实现Comparable接口:在类上implement Comparable,重写compareTo()方法,在方法内定义比较算法, 根据大小关系, 返回正数负数或零。1-4、在使用TreeSet存储对象的时候, add()方法内部就会自动调用compareTo()方法进行比较, 根据比较结果使用二叉树形式进行存储1-5、TreeSet是依靠TreeMap来实现的。
4-3、Java-Map-TreeSet-源码分析
4-4、Java-Map-TreeSet-用法
1、自定义对象的话,必须要告诉TreeSet如何来进行比较元素,如果不指定,就会抛出这个异常:java.lang.ClassCastExceptionpublic static void demoOne() {TreeSet<Person> ts = new TreeSet<>();ts.add(new Person("张三", 11));ts.add(new Person("李四", 12));ts.add(new Person("王五", 15));ts.add(new Person("赵六", 21));System.out.println(ts); //需要在自定义类(Person)中实现Comparable接口,并重写接口中的compareTo方法}//需要在自定义类(Person)中实现Comparable接口,并重写接口中的compareTo方法//如果将compareTo()返回值写死为0,元素值每次比较,都认为是相同的元素,这时就不再向TreeSet中插入除第一个外的新元素。所以TreeSet中就只存在插入的第一个元素。//如果将compareTo()返回值写死为1,元素值每次比较,都认为新插入的元素比上一个元素大,于是二叉树存储时,会存在根的右侧,读取时就是正序排列的。//如果将compareTo()返回值写死为-1,元素值每次比较,都认为新插入的元素比上一个元素小,于是二叉树存储时,会存在根的左侧,读取时就是倒序序排列的。public class Person implements Comparable<Person> {private String name;private int age;...public int compareTo(Person o) {return 0; //当compareTo方法返回0的时候集合中只有一个元素return 1; //当compareTo方法返回正数的时候集合会怎么存就怎么取return -1; //当compareTo方法返回负数的时候集合会倒序存储}}
4-5、Java-Map-TreeSet-小结
1、TreeSet-小结1-1、TreeSet中的元素必须实现Comparable接口并重写compareTo()方法,TreeSet判断元素是否重复 、以及确定元素的顺序 靠的都是这个方法;1-1-1、对于Java类库中定义的类,TreeSet可以直接对其进行存储,如String,Integer等,因为这些类已经实现了Comparable接口);1-1-2、对于自定义类,如果不做适当的处理,TreeSet中只能存储一个该类型的对象实例,否则无法判断是否重复。1-2、相对HashSet,TreeSet的优势是有序,劣势是相对读取慢。
5、Java-Map-TreeMap-概述
1、TreeMap-概述1-1、TreeMap 继承于AbstractMap,是一个有序的key-value集合,它是通过红黑树实现的。1-2、TreeMap 实现了NavigableMap接口,NavigableMap接口继承了SortedMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。1-3、TreeMap 实现了Cloneable接口,意味着它能被克隆。实现了java.io.Serializable接口,意味着它支持序列化。1-4、TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。1-5、TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。1-6、TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。2、TreeMap-继承关系:public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}
5-1、Java-Map-TreeMap-工作原理
1、TreeMap-工作原理:1-1、TreeMap集合是基于红黑树(Red-Black tree)的 NavigableMap实现。该集合最重要的特点就是可排序,TreeMap可以对添加进来的元素进行排序,可以按照默认的排序方式,也可以自己指定排序方式。1-2、红黑树回顾:https://www.cnblogs.com/LiaHon/p/11203229.html
5-2、Java-Map-TreeMap-继承关系-示意图
5-3、Java-Map-TreeMap-源码分析
5-4、Java-Map-TreeMap-小结
1、TreeMap-小结1-1、TreeMap底层是红黑树,能够实现该map集合有序。1-2、如果在构造方法中传递了Comparator对象,那么就以传入的对象的方法进行比较,否则,使用Comparable的.compareTo(T o)方法来比较。1-2-1、使用Comparable的.compareTo(T o)方法来比较,key不能为null,且key需要实现了Comparable接口。1-3、TreeMap是非同步的,可以使用Collections来进行封装,达到同步。1-3-1、Collections.synchronizedMap(new TreeMap<>())1-3-2、ReentrantReadWriteLock,并发锁1-4、关于红黑树的节点插入操作,首先是改变新节点,新节点的父节点,祖父节点,和新节点的颜色,能在当前分支通过节点的旋转改变的,则通过此种操作,来满足红黑书的特点。1-4-1、如果当前相关节点的旋转解决不了红黑树的冲突,则通过将红色的节点移动到根节点解决,最后在将根节点设置为黑色。
6、Java-Map-ConcurrentHashMap-概述
1、ConcurrentHashMap-概述:1-1、ConcurrentHashMap是建立在 Java 内存模型基础上的。1-2、ConcurrentHashMap,它是HashMap的一个线程安全的、支持高效并发的版本。在默认理想状态下,ConcurrentHashMap可以支持16个线程执行并发写操作及任意数量线程的读操作。1-3、ConcurrentHashMap本质上是一个Segment数组,而一个Segment实例又包含若干个桶,每个桶中都包含一条由若干个 HashEntry 对象链接起来的链表。2、ConcurrentHashMap-优点:2-1、线程安全:在并发编程中,jdk1.7的情况下使用 HashMap 可能造成死循环,而jdk1.8 中有可能会造成数据丢失。2-2、HashTable 效率非常低下。3、ConcurrentHashMap-继承关系:ConcurrentHashMap 继承了AbstractMap并实现了ConcurrentMap接口public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable {}
6-1、Java-Map-ConcurrentHashMap-继承关系-示意图
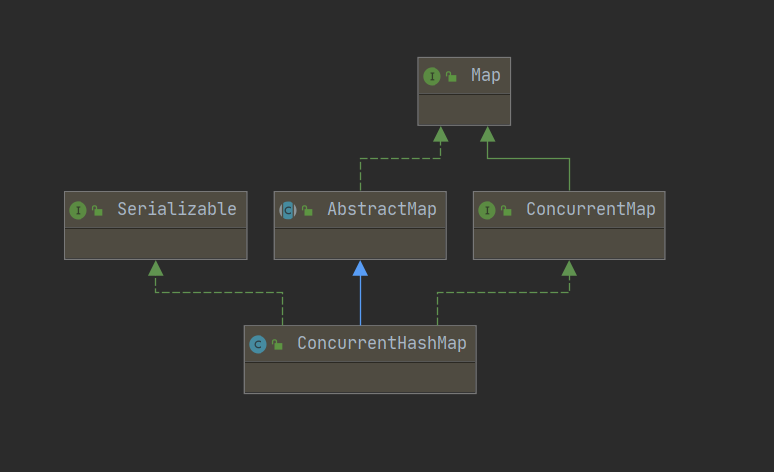
6-2、Java-Map-ConcurrentHashMap-工作原理
1、ConcurrentHashMap-工作原理:1-1、锁分离 (Lock Stripping):ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。final Segment<K,V>[] segments;1-2、不变(Immutable)和易变(Volatile):ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。static final class HashEntry<K,V> {final K key;final int hash;volatile V value;final HashEntry<K,V> next;}
6-3、Java-Map-ConcurrentHashMap-源码解析
6-4、Java-Map-ConcurrentHashMap-小结
1、ConcurrentHashMap-小结:1-1、在使用锁来协调多线程间并发访问的模式下,减小对锁的竞争可以有效提高并发性。1-1-1、减小请求同一个锁的频率。1-1-2、减少持有锁的时间。1-2、JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。1-3、jdk7中ConcurrentHashmap中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能。1-3-1、JDK1.7 版本的 ReentrantLock+Segment+HashEntry1-4、jdk8 中完全重写了concurrentHashmap,主要设计上的变化有以下几点:1-4-1、不采用segment而采用node,锁住node来实现减小锁粒度。1-4-2、设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。1-4-3、使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。1-4-4、sizeCtl的不同值来代表不同含义,起到了控制的作用。1-4-5、JDK1.8 版本中synchronized+CAS+Node+红黑树。2、JDK1.8为什么要摒弃分段锁(ReentrantLock),而采用重入锁(synchronized)?2-1、jdk1.8中锁的粒度更细了。jdk1.7中ConcurrentHashMap 的concurrentLevel(并发数)基本上是固定的。jdk1.8中的concurrentLevel是和数组大小保持一致的,每次扩容,并发度扩大一倍.2-2、红黑树的引入,对链表的优化使得 hash 冲突时的 put 和 get 效率更高2-3、获得JVM的支持 ,ReentrantLock 毕竟是 API 这个级别的,后续的性能优化空间很小。 synchronized 则是 JVM 直接支持的, JVM 能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就使得 synchronized 能够随着 JDK 版本的升级而不改动代码的前提下获得性能上的提升。
7、Java-Map-LinkedHashMap-概述
1、LinkedHashMap-概述:1-1、LinkedHashMap通过维护一个运行于所有条目的双向链表,保证了集合元素迭代的顺序,这个顺序可以是插入顺序或者访问顺序。1-2、LinkedHashMap存储数据是有序的,而且分为两种:插入顺序(默认值:accessOrder = false)和访问顺序(LRU算法-最少访问)。2、LinkedHashMap-特点:2-1、key和value都允许为空2-2、key重复会覆盖,value可以重复2-3、有序的2-4、LinkedHashMap是非线程安全的3、LinkedHashMap-基本结构:3-1、LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。3-2、LinkedHashMap的基本实现思想就是----多态。4、LinkedHashMap-应用场景:4-1、HashMap是无序的,当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMap。5、LinkedHashMap-继承关系:public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {}
7-1、Java-Map-LinkedHashMap-继承关系-示意图
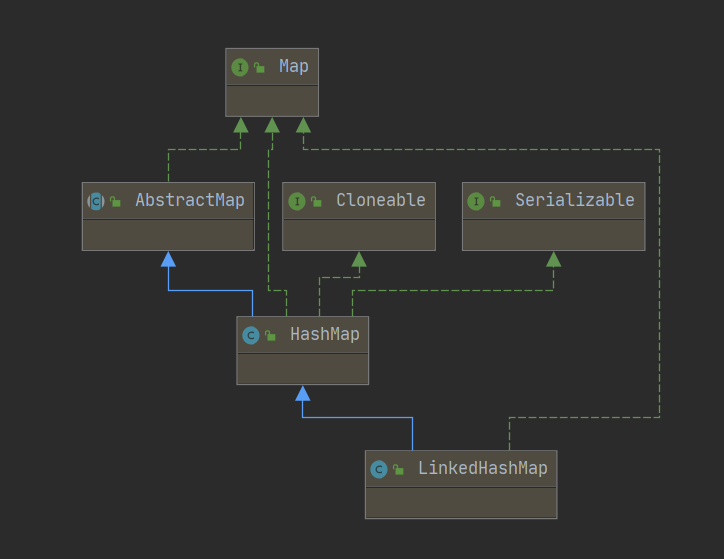
7-2、Java-Map-LinkedHashMap-源码分析
7-3、Java-Map-LinkedHashMap-小结
1、LinkedHashMap-小结:1-1、LinkedHashMap底层是HashMap,与HashMap没太大的区别,重写了部分方法,在HashMap中一些空的实现,LinkedHashMap都做了实现,扩展了HashMap类的功能。1-1-1、LlinkedHashMap的iterator也是遍历的双向链表。1-1-2、LinkedHashMap可以保存元素的插入顺序,顺序有两种方式一种是按照插入顺序排序,一种按照访问做排序。默认以插入顺序排序,性能比HashMap略低,线程也是不安全的。1-2、LinkedHashMap只有在使用三个参数的构造方法并制定accessOrder为true时,才有顺序,不指定那么和HashMap基本没什么大的区别。1-3、LinkedHashMap 在HashMap数据结构-红黑树之上,通过维护一条双向链表,实现了散列数据结构的有序遍历。
8、Java-Map-WeakHashMap-概述
1、WeakHashMap-概述:1-1、WeakHashMap功能与HashMap没什么区别,但WeakHashMap是基于弱引用的(java.lang.ref包下的弱引用WeakReference)。1-1-1、WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null,不允许重复。1-1-2、WeakHashMap的键是"弱键",对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。1-2、WeakHashMap是不同步的,非线程安全的。可以使用 Collections.synchronizedMap 方法来构造同步的 WeakHashMap。2、WeakHashMap-继承关系:public class WeakHashMap<K,V> extends AbstractMap<K,V> implements Map<K,V> {}
8-1、Java-Map-WeakHashMap-继承关系-示意图
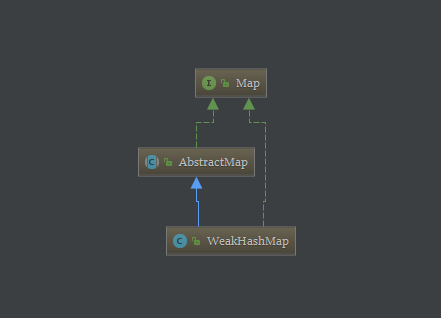
8-2、Java-Map-WeakHashMap-工作原理
1、WeakHashMap-工作原理:1-1、"弱键"的原理:通过WeakReference和ReferenceQueue实现的。 WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的"弱键"。1-2、"弱键"删除步骤:1-2-1、WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。1-2-2、当某"弱键"不再被其它对象引用,并被GC回收时。在GC回收该"弱键"时,这个"弱键"也同时会被添加到ReferenceQueue(queue)队列中。1-2-3、当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。2、WeakHashMap-使用场景:2-1、保证缓存命中率:2-1-1、整个缓存是一个key-value结构的(以键值对缓存为例),HashMap作为强引用对象在没有主动将key删除是不会被JVM回收的,这样HashMap中的对象就会越积越多直到OOM错误。2-1-2、WeakHashMap内部是通过弱引用来管理entry的,将一对key, value放入到 WeakHashMap 里并不能避免该key值被GC回收。3、WeakHashMap-应用场景:3-1、实现本地缓存:3-1-1、WeakhashMap实现一个线程安全的基于LRU本地缓存。3-1-2、也可以使用 基于 LinkedHashMap 的实现缓存工具类,基于volatile 实现LRU策略线程安全缓存。3-1-3、配合事务进行使用,存储事务过程中的各类信息,结构:WeakHashMap<String,Map<K,V>> transactionCache;3-1-3-1、key为String类型,可以用来标志区分不同的事务,起到一个事务id的作用。value是一个map,可以是一个简单的HashMap或者LinkedHashMap,用来存放在事务中需要使用到的信息。3-1-3-2、在事务开始时创建一个事务id,并用它来作为key,事务结束后,将这个强引用消除掉,这样既能保证在事务中可以获取到所需要的信息,又能自动释放掉map中的所有信息。3-1-4、在Tomcat的工具类里,有这样一种实现。基于LRU策略。package org.apache.tomcat.util.collections;public final class ConcurrentCache<K, V> {private final int size;private final Map<K, V> eden;private final Map<K, V> longterm;public ConcurrentCache(int size) {this.size = size;this.eden = new ConcurrentHashMap(size);this.longterm = new WeakHashMap(size);}public V get(K k) {V v = this.eden.get(k);if (v == null) {synchronized(this.longterm) {v = this.longterm.get(k);}if (v != null) {this.eden.put(k, v);}}return v;}public void put(K k, V v) {if (this.eden.size() >= this.size) {synchronized(this.longterm) {this.longterm.putAll(this.eden);}this.eden.clear();}this.eden.put(k, v);}}
8-3、Java-Map-WeakHashMap-源码分析
8-4、Java-Map-WeakHashMap-小结
1、WeakHashMap-小结:1-1、WeakHashMap是一个会自动清除Entry的Map。1-2、WeakHashMap的操作与HashMap完全一致。1-3、[!!!]WeakHashMap内部数据结构是数组+链表。1-4、WeakHashMap常被用作缓存。
9、Java-Map-Hashtable-概述
1、Hashtable-概述1-1、HashTable:也是一个散列表,键值对或者关联数组1-2、HashTable:其中的keyvalue键值对均为object类型,支持任何类型的键值对,每个元素都存储于DictionaryEntry对象中的键值对。键不能为空引用。1-3、查找速度快,遍历相对慢,键值不能有空指针和重复数据。2、Hashtable-继承关系:public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {}
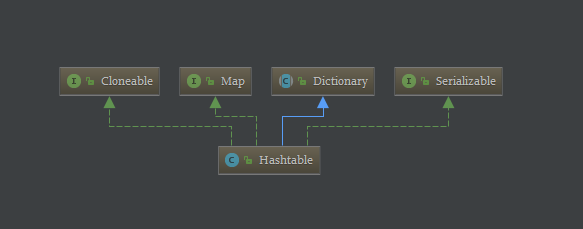
9-1、Java-Map-Hashtable-继承关系-示意图
9-2、Java-Map-Hashtable-工作原理
1、Hashtable-工作原理:1-1、Hashtable继承Dictionary类,其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的抽象父类,每个键和值都是对象。1-2、在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值对"接口。1-3、Hashtable是通过"拉链法"实现的哈希表:它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
9-3、Java-Map-Hashtable-源码分析
9-4、Java-Map-Hashtable-小结
1、Hashtable-小结:1-1、Hashtable继承的是Dictionary类,HashMap继承的是AbstractMap,但两者都实现了Map接口。1-2、在Hashtable中有类似put(null,null)的操作,编译时可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常。1-3、HashMap仅支持Iterator的遍历方式,Hashtable支持Iterator和Enumeration两种遍历方式。//通过Enumeration来遍历HashtableEnumeration<String> enu = table.keys();while(enu.hasMoreElements()) {System.out.println("Enumeration:"+table.keys()+" "+enu.nextElement());}1-4、JDK8之前的版本中,Hashtable是没有fast-fail机制的。在JDK8及以后的版本中 ,HashTable也是使用fast-fail的。if (modCount != mc)throw new ConcurrentModificationException();
10、Java-Map-EnumMap-概述
1、EnumMap-概述:1-1、EnumMap是一个用于存储 key 为枚举类型的 map,底层使用数组实现(K,V 双数组),其key必须为Enum类型,两个数组,一个数组keyUniverse存储key,另一个数组vals存储val,两个数组通过下标对应起来。1-2、所有的key都必须是单个枚举类的枚举值,创建EnumMap 时必须显示或隐式指定他对应的枚举类。EnumMap enumMap = new EnumMap<>(Season.class);1-3、EnumMap的key不允许为null,value可以为null,按照key在enum中的顺序进行保存,非线程安全。1-4、EnumMap中,是根据key 的自然顺序(枚举值在枚举类中的定义顺序) 来维护key-value的顺序。2、EnumMap-继承关系:public class EnumMap<K extends Enum<K>, V> extends AbstractMap<K, V> implements java.io.Serializable, Cloneable {}
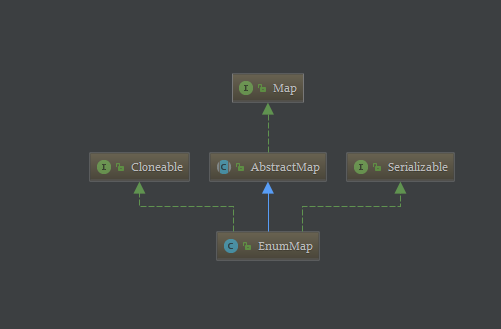
10-1、Java-Map-EnumMap-继承关系-示意图
10-2、Java-Map-EnumMap-工作原理
1、EnumMap-工作原理1-1、EnumMap是一个用于存储 key 为枚举类型的 map,底层使用数组实现(K,V 双数组),其key必须为Enum类型,两个数组,一个数组keyUniverse存储key,另一个数组vals存储val,两个数组通过下标对应起来。1-2、key 数组会在构造函数中根据 keyType 进行初始化,下面我们会看到。当 EnmumMap 的 value 为 null 时会特殊处理为一个 Object 对象。2、EnumMap-应用场景:2-1、如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。2-2、举例Demo:public static void main(String[] args) {Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);map.put(DayOfWeek.MONDAY, "星期一");map.put(DayOfWeek.TUESDAY, "星期二");map.put(DayOfWeek.WEDNESDAY, "星期三");map.put(DayOfWeek.THURSDAY, "星期四");map.put(DayOfWeek.FRIDAY, "星期五");map.put(DayOfWeek.SATURDAY, "星期六");map.put(DayOfWeek.SUNDAY, "星期日");System.out.println(map);System.out.println(map.get(DayOfWeek.MONDAY));}
10-3、Java-Map-EnumMap-源码分析
10-4、Java-Map-EnumMap-小结
1、EnumMap-小结:1-1、添加元素方法-小结1-1-1、EnmuMap 添加键值对并没有扩容操作,因为一个枚举类型到底有多少元素在代码运行阶段是确定的,在构造函数中已经对 key 数组进行了初始化与赋值,value 数组的大小也已经被确定。1-1-2、还有一个需要注意的问题,在上面的 .put()方法中只对 value 进行了处理,并没有处理 key,原因就是 key 数组在构造函数中已经被赋值了。1-2、EnumMap 存储键值对时并不会根据 key 获取对应的哈希值,enum 本身已经提供了一个 ordinal() 方法,该方法会返回具体枚举元素在枚举类中的位置(从 0 开始), 因此一个枚举元素从创建就已经有了一个唯一索引与其对应,这样就不存在哈希冲突的问题了。1-3、key 数组自从在构造函数中完成初始化之后就没有执行过增删改的操作,就算不添加任何键值对,也能根据其迭代器获取所有的 key,因为 key 在构造函数中已经被赋值。/**EnumMap 的 hasNext() 方法中对 value 做了非空判断*/public boolean hasNext() {// 循环中会略过 value 数组中为 null 的情况while (index < vals.length && vals[index] == null)index++;return index != vals.length;}
11、Java-Map-Properties-概述
1、Properties-概述1-1、Properties(Java.util.Properties),该类主要用于读取Java的配置文件,不同的编程语言有自己所支持的配置文件,配置文件中很多变量是经常改变的,为了方便用户的配置,能让用户够脱离程序本身去修改相关的变量设置。1-2、继承了Hashtable类public class Properties extends Hashtable<Object,Object> {}
11-1、Properties类-API
1、代码示例Properties pps = new Properties();//Properties ps = System.getProperties();2、在线API[http://www.matools.com/api/java7][https://tool.oschina.net/apidocs/apidoc?api=jdk-zh]
https://www.pdai.tech/md/java/collection/java-map-LinkedHashMap&LinkedHashSet.html
hashMaphttps://www.cnblogs.com/LiaHon/p/11142958.htmlhttps://www.cnblogs.com/LiaHon/p/11149644.htmlremoveTreeNode方法具体实现可参考 TreeMap原理实现及常用方法afterNodeRemoval方法具体实现可参考LinkedHashMap如何保证顺序性Float.isNaN(loadFactor)遍历树查找元素:.getTreeNode(hash, key)红黑树:https://www.cnblogs.com/LiaHon/p/11203229.htmlhttps://www.cnblogs.com/skywang12345/p/3245399.html线性时间排序https://www.cnblogs.com/shixisheng/p/6840763.html将非线程安全类包装为线程安全的类,方法:https://blog.csdn.net/yingfeng612/article/details/79903926JDK.1.2 之后,Java 对引用的概念进行了扩充,将引用分为了:强引用、软引用、弱引用、虚引用4 种。private T referent; /* Treated specially by GC */volatile ReferenceQueue<? super T> queue;对Reference和WeakReference二次散列?掩码?length必定是2的幂,所以减1后就变成了掩码,再进行与操作就能直接得到hashcode mod length的结果。h & (length-1) = h/length快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你//桶的索引是用key的hash值和0x7FFFFFFF做与运算,最后对数组长度取余//&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而 hash & 0x7FFFFFFF 后,只有符号外改变,而后面的位都不变。int index = (hash & 0x7FFFFFFF) % tab.length;Hashtable与HashMap的区别详解:https://blog.csdn.net/wangxing233/article/details/79452946?utm_source=blogxgwz5通过 JavaLangAccess 和 SharedSecrets 来获取 JVM 中对象实例

若有收获,就点个赞吧
0 人点赞
