基本概念
节点
节点: 节点就是一个ES的实例,本质上是一个java进程
每个节点都有名字,通过配置文件配置或者启动命令 -E node.name=xx指定; 每个节点在启动后,都会分配一个UID,保存在data目录下
Coordinating Node
也就是协调节点,是指处理请求的节点
- 负责路由请求到正确的节点,例如创建索引的请求,需要路由到Master节点(创建删除)
- 所有节点默认都是 Coordinating Node
Data Node
- 可以保存数据的节点,启动默认就是数据节点,可以设置 node.data: false禁用
- 由Master Node 决定如何把分片分发到数据节点上
-
Master Node
处理创建、删除索引 等请求,决定分片被分配到哪个节点
- 维护并更新 Cluster State
Master Eligible Node 及选主流程
- Master Eligible Node是指 master的候选节点,这些节点在master故障时会参与选主流程。
- 每个节点启动后,默认就是Master Eligible Node,可以禁用:
node.master: false - 当集群内第一个Master Eligible Node启动,它会将自己选举成Mster节点
互相 Ping 对⽅,Node Id 低的会成为被选举的节点; 其他节点会加⼊集群,但是不承担 Master 节点的⻆⾊。⼀旦发现被选中的主节点丢失, 就会选举出新的 Master 节点
如何避免脑裂
限定选举条件,设置仲裁 quorum,只有当master eligible 节点数> quorum,才能进行选举
quorum=(节点总数/2)+1
分片
主分片 Primary Shard
通过主分片,将数据分布在所有节点(data node)上, 主分片数在索引创建时指定,后续默认不能修改,如果修改需要重建索引。
副本分片 Replica Shard
提高数据的可用性,通过引⼊副本分片 (Replica Shard) 提⾼数据的可⽤性。⼀旦主分⽚丢失,副本分⽚可以 Promote 成主分片。副本分片数可以动态调整。每个节点上都有完备的数据。如果不设置副本分⽚,⼀旦出现节点硬件故 障,就有可能造成数据丢失。
副本分⽚由主分⽚(Primary Shard)同步。通过⽀持增加 Replica 个数,⼀定程度可以提⾼读取的吞吐量。
3个节点,3个分片,2个副本,保证每个节点的数据是全的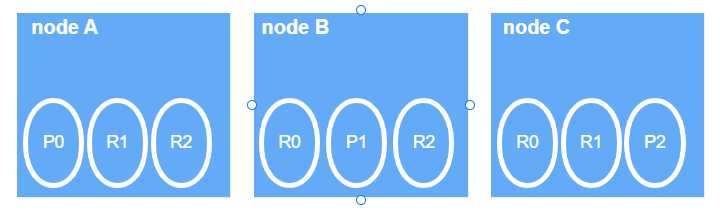
文档到分片的路由算法
shard = hash(_routing) % number_of_primary_shards
默认的 _routing 值是⽂档 id
分片的内部原理
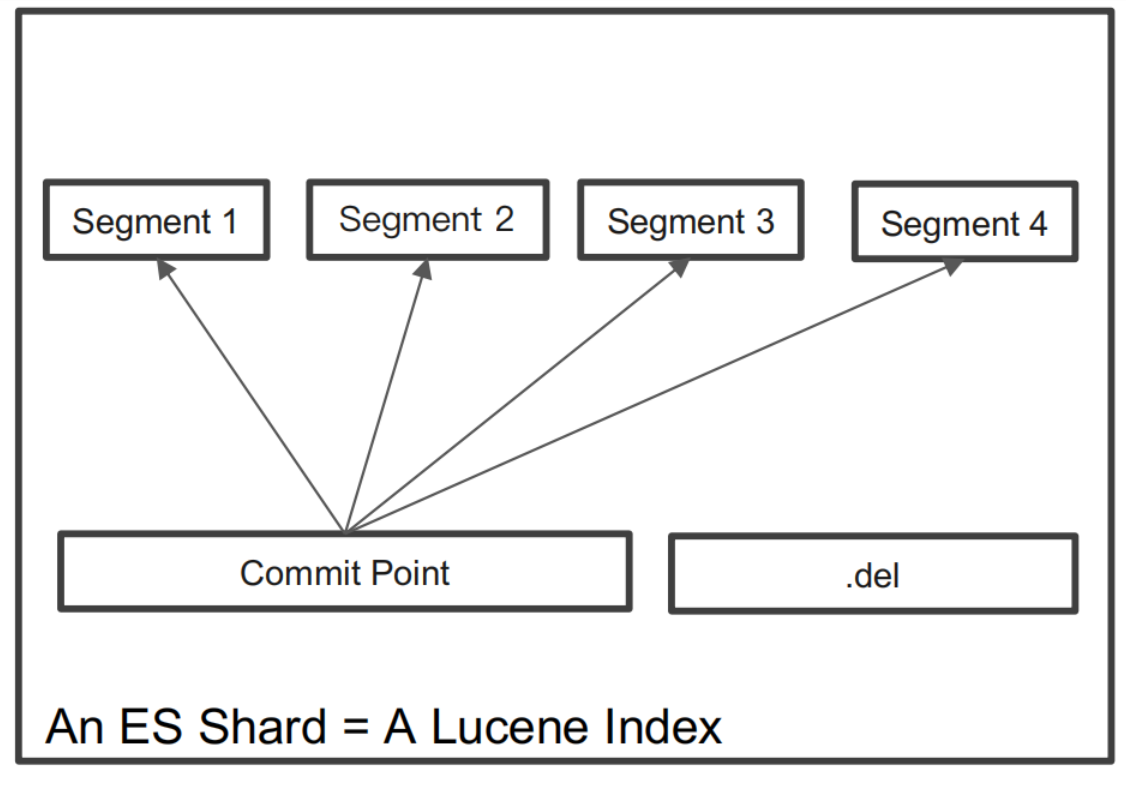
- 在Lucene中单个倒排索引文件被称为 Segment。Segment 是自包含的,不可变更的。 多个 Segments 汇总在一起,称为 Lucene 的 Index,其对应的就是 ES 中的 Shard
- 当有新⽂档写⼊时,会⽣成新 Segment,查询时会同时查询所有 Segments,并且对结果汇总。Lucene 中有⼀个⽂件,⽤来记录所有Segments 信息,叫做 Commit Point
- 删除的⽂档信息,保存在“.del”⽂件中
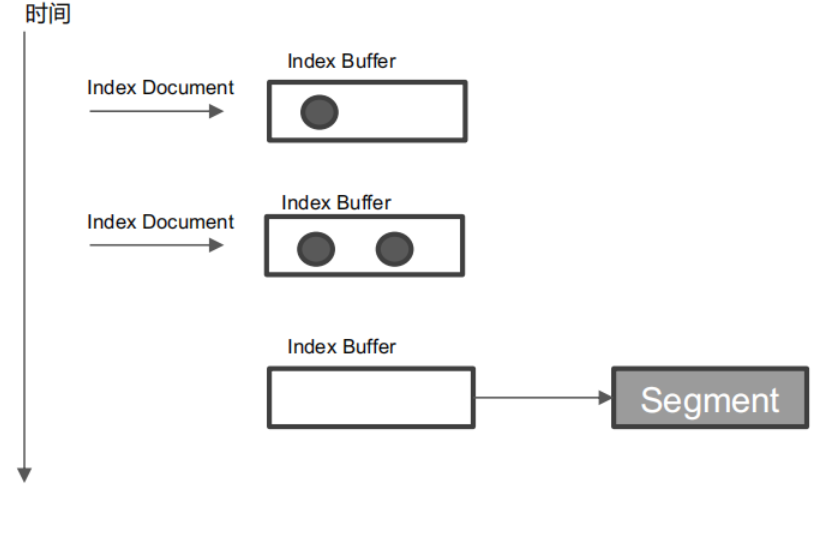
什么是refresh
- 将 Index buffer 写⼊ Segment 的过程叫Refresh。Refresh 不执⾏ fsync 操作
- Refresh 频率:默认 1 秒发⽣⼀次,可通过index.refresh_interval 配置。Refresh 后,数据就可以被搜索到了。这也是为什么Elasticsearch 被称为近实时搜索
- 如果系统有⼤量的数据写⼊,那就会产⽣很多的 Segment
- Index Buffer 被占满时,会触发 Refresh,默认值是 JVM 的 10%
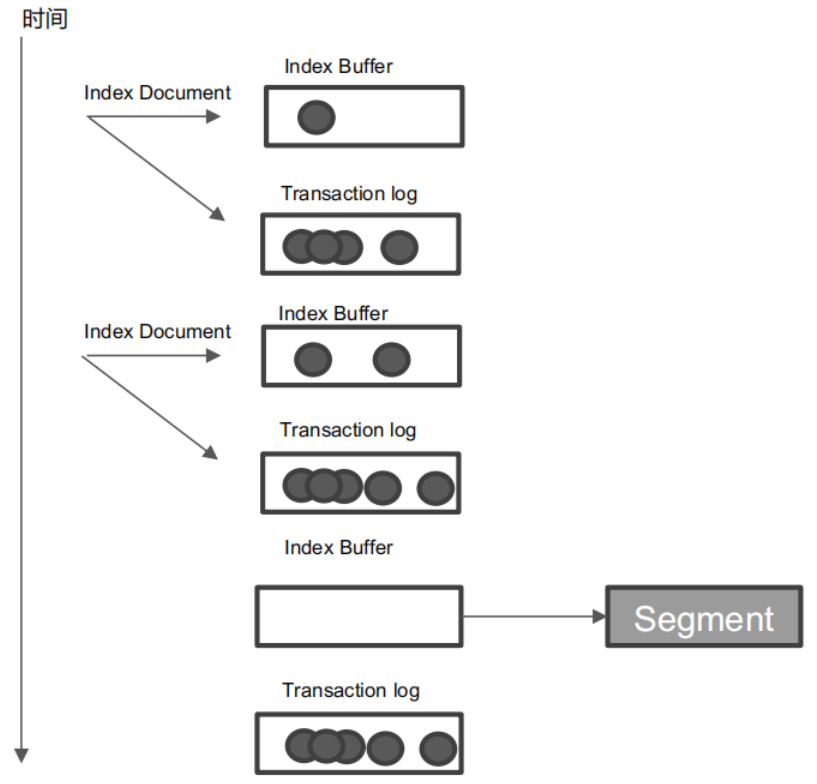
什么是Transaction Log
- Segment 写⼊磁盘的过程相对耗时,借助⽂件系统缓存,Refresh 时,先将Segment 写⼊缓存以开放查询
- 为了保证数据不会丢失。所以在 Index ⽂档时,同时写 Transaction Log,⾼版本开始,Transaction Log 默认落盘。每个分⽚有⼀个 Transaction Log
- 在 ES Refresh 时,Index Buffer 被清空,Transaction log 不会清空
什么是flush
- 调⽤ Refresh,Index Buffer 清空并且 Refresh
- 调⽤ fsync,将缓存中的 Segments写⼊磁盘
- 清空(删除)Transaction Log
- 默认 30 分钟调⽤⼀次
- Transaction Log 满 (默认 512 MB)
Merge
Segment 很多,需要被定期被合并
ES 和 Lucene 会⾃动进⾏ Merge 操作
查询原理
ES搜索分两阶段
- QUERY
-
QUERY
⽤户发出搜索请求到 ES 节点。节点收到请求后, 会以 Coordinating 节点的身份,在 6 个主副分⽚中随机选择 3 个分⽚,发送查询请求
被选中的分⽚执⾏查询,进⾏排序。然后,每个分⽚都会返回 From + Size 个排序后的⽂档 Id 和排序值 给 Coordinating 节点
FETCH
Coordinating Node 会将 Query 阶段,从从每个分⽚获取的排序后的⽂档 Id 列表,重新进⾏排序。选取 From 到 From + Size个⽂档的 Id
以 multi get 请求的⽅式,到相应的分⽚获取详细的⽂档数据
Query Then Fetch潜在问题
性能问题
每个分⽚上需要查的⽂档个数 = from + size; 最终协调节点需要处理:number_of_shard * ( from+size ) 深度分⻚
相关性算分
每个分⽚都基于⾃⼰的分⽚上的数据进⾏相关度计算。这会导致打分偏离的情况,特别是数据量很少时。相关性算分在分⽚之间是相互独⽴。当⽂档总数很少的情况下,如果主分⽚⼤于 1,主分⽚数越多 ,相关性算分会越不准
解决办法:1.主分片设置为1,数据量大不适用;
- 使用DFS Query Then Fetch,把每个分片的词频文档进行搜集,然后进行完整算分,耗费CPU和内存。性能也低
深度分页问题
Search After避免深度分页
- 不指定页数
- 只能往下翻

若有收获,就点个赞吧
0 人点赞
