作者:sudop
链接:https://www.jianshu.com/p/9e2c6a8e1b54
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
搜索Suggest需要优化问题:
- 怎么优化Suggest词库,提升Suggest词准确率
-
suggest词库获取
冷启动可以从内容中提取热词数据来解决,或者人工设置
- 挖掘搜索日志:
- 挖掘近1个月搜索日志,按照每天独立IP进行统计频次,即每个IP用户天搜索同一关键词多次只记一次,用IP过滤也有其局限性,伪IP,动态IP,局域网共享同一公网IP,都会影响到基于IP来判断用户的准确性,你也可以使用sessionId或者userId来判断
- 统计后搜索词频次之后,抽取搜索频次>100(自定阈值)的词,同时对日志数据进行清洗,过滤去除大于10个字(去除太长的长尾词),单字和符号内容
- 定时更新suggest词库中。
搜索日志里面包含大量 误输入词:
匹配:能够通过用户的输入进行前缀匹配;
- 排序:根据建议词的优先级或者搜索热度进行排序;
- 纠错:能够对用户的输入进行拼写纠错(suggest建议优先prefix匹配,不宜过多提示,因此只需提供前缀匹配,中文拼音匹配即可)
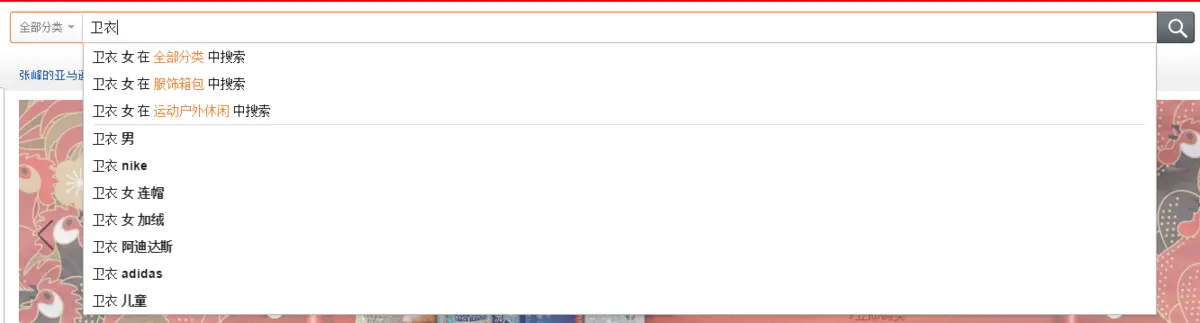
搜索时:如上图所示,可引导用户选择category,提升Suggest准确度
匹配
- “preserve_separators”: false, 这个设置为false,将忽略空格之类的分隔符
- “preserve_position_increments”: true,如果建议词第一个词是停用词,我们使用了过滤停用词的分析器,需要将此设置为false
提升响应速度
关于completion FST编码原理
如:“天上人间” 分析为:“天上人间”、“天上”、“上人”、“人间” 四个词条。 要注意这4个词条还有顺序,也就是position分别为0, 1, 2, 3。FST实际上是前缀编码,这些词被顺序串联在一起进行编码,并记录了每个词条的相对位置,编码后形如:天上人间|天上|上人|人间0 1 2 3
特别注意,这时候所有的查找都只能从0位置的“天”开始。做completion suggest的时候, 输入的词条经过分析后, 必须有相同的前缀和相对位址。 因为你的搜索用的simple analyzer,当输入”天”的时候, 分析出来的是”天” (0), 在FST里是从起始位置开始可以匹配到。其他输入“天上” “天上人” 都是从位置0开始的前缀,也都可以匹配。
但是如果你输入“上”, simple analyzer分析出来的是”上” (0), 去FST里查,第一个就不匹配,所以没结果。
为了帮助理解,针对你的例子,可以试一下如下的搜索:POST test_suggestion/_search{"suggest": {"term-suggestion": {"prefix": "天上人间 天上 上","completion": {"field": "keyword_suggestion"}}}}
你会发现,上面用空格分隔的3个词,也可以match。 原因在于搜索用的simple analyzer是用空格一类的分隔符分词的,分词结果是: 天上人间|天上|上 0 1 2,顺着FST走下去,可以做到前缀匹配。
总结来说,当使用completion suggester的时候, 不是用于完成 类似于 “关键词“这样的模糊匹配场景,而是用于完成关键词前缀匹配的。 对于汉字的处理,无需使用ik/ HanLP一类的分词器,直接使用keyword analyzer,配合去除一些不需要的stop word即可。
举个例子,做火车站站名的自动提示补全,你可能希望用户输入“上海” 或者 “虹桥” 都提示”上海虹桥火车站“ 。 如果想使用completion suggester来做,正确的方法是为”上海虹桥火车站“这个站名准备2个completion词条,分别是:
“上海虹桥火车站”
“虹桥火车站”
这样用户的输入不管是从“上海”开始还是“虹桥”开始,都可以得到”上海虹桥火车站”的提示。
- 因此想要实现completion suggest 中文拼音混合提示,需要提供三个字段,中文字段,采用standard分词,全拼字段,首字母字段,对汉字都采用standard分词,分词后对单字进行分词,确保FST索引的都是单字对应的拼音,这样应该就可以完成中英文拼音suggest
- 第一步是先采用汉字前缀匹配的结果,使用全拼匹配也可以返回结果,但是存在同音字时,weight高的同音字会覆盖原来的字,导致suggest不准确
- 第二部,当汉字匹配数量不够时,启用全拼匹配,可以达到拼音纠错补充效果,索引时只索引全拼拼音
- 第三步:正常来说首字母拼音一般匹配不到内容,此时可以使用拼音首字母匹配,索引时只索引首字母拼音
- 第四步:前面匹配的Suggest词不够时,最后也可以采用fuzzy查询进行补全
使用fuzzy模糊查询
fuzzy模糊查询是基于编辑距离算法来匹配文档。编辑距离的计算基于我们提供的查询词条和被搜索文档。
Complete suggest支持fuzzy查询,计算编辑距离对CPU消耗比较大,需要设置以下参数来限制对性能的影响:
- prefix_length 不能被 “模糊化” 的初始字符数。 大部分的拼写错误发生在词的结尾,而不是词的开始。 例如通过将 prefix_length 设置为 3 ,你可能够显著降低匹配的词项数量。
- min_length 开始进行模糊匹配的最小输入长度
- fuzzy查询只在前缀匹配数不够时启用进行补全
排序
从搜索日志挖掘的Suggest词,可以根据搜索词的搜索频次作为热度来设置weight,Suggest会根据weight来排序。
LinkedHashSet<String> returnSet = new LinkedHashSet<>();Client client = elasticsearchTemplate.getClient();SuggestRequestBuilder suggestRequestBuilder = client.prepareSuggest(elasticsearchTemplate.getPersistentEntityFor(SuggestEntity.class).getIndexName());//全拼前缀匹配CompletionSuggestionBuilder fullPinyinSuggest = new CompletionSuggestionBuilder("full_pinyin_suggest").field("full_pinyin").text(input).size(10);//汉字前缀匹配CompletionSuggestionBuilder suggestText = new CompletionSuggestionBuilder("suggestText").field("suggestText").text(input).size(size);//拼音搜字母前缀匹配CompletionSuggestionBuilder prefixPinyinSuggest = new CompletionSuggestionBuilder("prefix_pinyin_text").field("prefix_pinyin").text(input).size(size);suggestRequestBuilder = suggestRequestBuilder.addSuggestion(fullPinyinSuggest).addSuggestion(suggestText).addSuggestion(prefixPinyinSuggest);SuggestResponse suggestResponse = suggestRequestBuilder.execute().actionGet();Suggest.Suggestion prefixPinyinSuggestion = suggestResponse.getSuggest().getSuggestion("prefix_pinyin_text");Suggest.Suggestion fullPinyinSuggestion = suggestResponse.getSuggest().getSuggestion("full_pinyin_suggest");Suggest.Suggestion suggestTextsuggestion = suggestResponse.getSuggest().getSuggestion("suggestText");List<Suggest.Suggestion.Entry> entries = suggestTextsuggestion.getEntries();//汉字前缀匹配for (Suggest.Suggestion.Entry entry : entries) {List<Suggest.Suggestion.Entry.Option> options = entry.getOptions();for (Suggest.Suggestion.Entry.Option option : options) {returnSet.add(option.getText().toString());}}//全拼suggest补充if (returnSet.size() < 10) {List<Suggest.Suggestion.Entry> fullPinyinEntries = fullPinyinSuggestion.getEntries();for (Suggest.Suggestion.Entry entry : fullPinyinEntries) {List<Suggest.Suggestion.Entry.Option> options = entry.getOptions();for (Suggest.Suggestion.Entry.Option option : options) {if (returnSet.size() < 10) {returnSet.add(option.getText().toString());}}}}//首字母拼音suggest补充if (returnSet.size() == 0) {List<Suggest.Suggestion.Entry> prefixPinyinEntries = prefixPinyinSuggestion.getEntries();for (Suggest.Suggestion.Entry entry : prefixPinyinEntries) {List<Suggest.Suggestion.Entry.Option> options = entry.getOptions();for (Suggest.Suggestion.Entry.Option option : options) {returnSet.add(option.getText().toString());}}}return new ArrayList<>(returnSet);
ES setting mapping配置
{"settings": {"analysis": {"analyzer": {"prefix_pinyin_analyzer": {"tokenizer": "standard","filter": ["lowercase","prefix_pinyin"]},"full_pinyin_analyzer": {"tokenizer": "standard","filter": ["lowercase","full_pinyin"]}},"filter": {"_pattern": {"type": "pattern_capture","preserve_original": 1,"patterns": ["([0-9])","([a-z])"]},"prefix_pinyin": {"type": "pinyin","keep_first_letter": true,"keep_full_pinyin": false,"none_chinese_pinyin_tokenize": false,"keep_original": false},"full_pinyin": {"type": "pinyin","keep_first_letter": false,"keep_full_pinyin": true,"keep_original": false,"keep_none_chinese_in_first_letter": false}}}},"mappings": {"suggest": {"properties": {"id": {"type": "string"},"suggestText": {"type": "completion","analyzer": "standard","payloads": true,"preserve_separators": false,"preserve_position_increments": true,"max_input_length": 50},"prefix_pinyin": {"type": "completion","analyzer": "prefix_pinyin_analyzer","search_analyzer": "standard","preserve_separators": false,"payloads": true},"full_pinyin": {"type": "completion","analyzer": "full_pinyin_analyzer","search_analyzer": "full_pinyin_analyzer","preserve_separators": false,"payloads": true}}}}}
DSL查询语句
POST _suggest{"text": "cy","prefix_pinyin": {"completion": {"field": "prefix_pinyin","size": 10}},"full_pinyin": {"completion": {"field": "full_pinyin","size": 10}},"suggestText": {"completion": {"field": "suggestText","size": 10}}}
suggest性能优化,从之前平均响应时间5.5ms 降低到3.5ms,Suggest词更加准确

若有收获,就点个赞吧
0 人点赞
