总结
把总结放在开头,方便回顾,下面是要点
- 容量要求:已缓存但未加入流中的字节数+流中的字节数<=capacity
- 使用1个数据结构保存“已缓存但未加入流中的字节数”,我用的是Map
- value是一个string,表示一段数据
- key是一个size_t,表示这段数据的第一个字节在字节流中的序号
- 这个数据结构实际上处理的是区间合并问题
- 使用_next_index表示还未加入流中的第一个字节序号,那么总的窗口就是[_next_index, _next_index+capacity)
- Map的窗口就是[_next_index, _next_index+capacity-ByteStream.size())
- 或者也可以表示成[_next_index, _next_index+ByteStream.remaining_capacity())
- Map中保存的是在这个大区间内的不相交的若干个子区间
- push_string传进来的data,需要和Map的窗口取交集,记为[L, R),这部分数据是实际上保留下来的,准备加入Map乃至加入流中的数据
- 找出Map中所有与[L, R)相交的区间
- 若找到多个这样的区间,则实际起作用的最多是第一个和最后一个区间,中间的区间一定都是[L, R)的子区间
- 把第一个区间、最后一个区间和[L, R)按照序号合并成1个字符串,其区间记为[union_l, union_r)
- 若Map中没有区间和[L, R)相交,则[L, R)==[union_l, union_r)
- 从Map中删除所有与[L, R)相交的区间
- 将[union_l, union_r)加入Map中
- 最后按序号从小到大的顺序遍历Map,检查区间的左端点是否与_next_index相等
- 若相等,则将这个区间加入流中
- 每次遍历,都要更新_next_index,因为后面的区间虽然不相交,但是可能是连着的,也要处理
- 当然别忘了处理eof
- 如果带有eof的字节被加入流中,则调用流的end_input()
代码中使用的序号变量类型是size_t,在64位系统下,这个类型实际上是64位无符号整数
第一阶段
思路
保存乱序数据的结构:Map
- 按照Key的Index从小到大排序,C++的map默认情况下应该就会这样排序
问题:如果当前push了一个string,只能存下这个string的一部分数据怎么办?
方案一:整个数据不要了,等到它下次push再尝试- 问题:如果capacity很小,数据很大,那么这个数据永远都放不进来
- 方案二:存一部分数据进去,那么传进来的string会被拆开
Map中缓存的数据应该是有限的
- next_index+capacity-stream.size()是上界,开区间
- Map中序号最小和序号最大的这两份数据,都可能只是传进来的string的一部分
- ①序号最小的数据,如果Map中只保存了一部分,说明它前面的那部分已经被加入到流中了
- ②序号最大的数据,如果Map中只保存了一部分,说明在它保存进来的那个时刻,达到了capacity指定的上限
- ②是①的因
- 设想这样一种情况,capacity的值比较小,只有100,整个字节流只包含1个string,这个string的大小为1000
- 那么Map中从头到尾放入的数据最多只有1份,且每次只能放入这个string的一部分
算法步骤
- 传入一个string,比较它的区间端点[index, index+string.size())和Map的区间端点[next_index, next_index+capacity-stream.size())的大小关系
- 不相交的部分丢弃,相交的部分添加到Map中
- 实际上,ByteStream的remaining_capacity返回的就是capacity-stream.size()
- [a,b)和[c,d)相交的判断条件是b>c&&d>a;判断相交,则它们相交的区间是[max(a,c), min(b,d))
- 尝试将相交部分放入Map中(实际上是一个区间问题)
- 如果序号Key已经存在,则更新Value(有可能保存更多的数据部分进来)
- 如果序号Key不存在,则put
- 比较next_index和Map中的最小序号
- 如果不相等,则没有数据可以提交到流中
- 如果相等,则从Map中取出从next_index开始的连续字节,放入流中
- 问题:第三步中,如果从Map中取出数据,Map有空余容量了,还需要回到第一步吗?
- 不需要!时刻牢记,Map的容量和Stream的容量是合在一起的,在当前时刻,Stream里的数据肯定不会有人拿走(CS144明确说了不涉及多线程,即使涉及多线程,也是加锁的,别人不可能再同一时刻从Stream里取走数据)
- Map有空余容量不代表整体有空余容量
如何处理eof?
- 我设置了一个size_t类型的变量eof_index,初始值为size_t的最大值(字节流会超过size_t的最大值吗)
- 如果收到了带eof=true的string,则更新eof_index
- 如果Map已空,且eof_index不是size_t的最大值(已经被设置),且字节序号已经达到了eof_index,则调用ByteStream的end_input
代码
#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "byte_stream.hh"#include <cstdint>#include <string>#include <map>//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,//! possibly overlapping) into an in-order byte stream.class StreamReassembler {private:// Your code here -- add private members as necessary.size_t _next_index;size_t _eof_index;std::map<size_t, std::string> _unassembled_strings;size_t _unassembled_bytes;ByteStream _output; //!< The reassembled in-order byte streamsize_t _capacity; //!< The maximum number of bytespublic://! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.//! \note This capacity limits both the bytes that have been reassembled,//! and those that have not yet been reassembled.StreamReassembler(const size_t capacity);//! \brief Receive a substring and write any newly contiguous bytes into the stream.//!//! The StreamReassembler will stay within the memory limits of the `capacity`.//! Bytes that would exceed the capacity are silently discarded.//!//! \param data the substring//! \param index indicates the index (place in sequence) of the first byte in `data`//! \param eof the last byte of `data` will be the last byte in the entire streamvoid push_substring(const std::string &data, const uint64_t index, const bool eof);//! \name Access the reassembled byte stream//!@{const ByteStream &stream_out() const { return _output; }ByteStream &stream_out() { return _output; }//!@}//! The number of bytes in the substrings stored but not yet reassembled//!//! \note If the byte at a particular index has been pushed more than once, it//! should only be counted once for the purpose of this function.size_t unassembled_bytes() const;//! \brief Is the internal state empty (other than the output stream)?//! \returns `true` if no substrings are waiting to be assembledbool empty() const;};#endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "stream_reassembler.hh"#include <cmath>// Dummy implementation of a stream reassembler.// For Lab 1, please replace with a real implementation that passes the// automated checks run by `make check_lab1`.// You will need to add private members to the class declaration in `stream_reassembler.hh`template <typename... Targs>void DUMMY_CODE(Targs &&... /* unused */) {}using namespace std;StreamReassembler::StreamReassembler(const size_t capacity): _next_index(0), _eof_index(unsigned(-1)), _unassembled_strings(), _unassembled_bytes(0),_output(capacity), _capacity(capacity) {}//! \details This function accepts a substring (aka a segment) of bytes,//! possibly out-of-order, from the logical stream, and assembles any newly//! contiguous substrings and writes them into the output stream in order.void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {if (eof) {_eof_index = index+data.size();}// [index, index+string.size())// [_next_index, _next_index+capacity-stream.size())=[_next_index, _next_index+_output.remaining_capacity())if (index+data.size()>_next_index&&_next_index+_output.remaining_capacity()>index) { // 有相交的部分,或者说有可以缓存的数据size_t L = std::max(index, _next_index);size_t R = std::min(index+data.size(), _next_index+_output.remaining_capacity());auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {if (iter->first==L) {break;}iter++; // 这句话一开始漏了}if (iter==_unassembled_strings.end()) { // 没有找到,则新建_unassembled_strings.insert(map<size_t, std::string>::value_type(L, data.substr(L-index, R-L)));} else { // 找到了,则更新iter->second=data.substr(L-index, R-L);}}// 接下来比较_next_index和Map中的最小序号int toDeleteCount=0;auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {if (iter->first!=_next_index) {break;}toDeleteCount++;// 一定可以全部写入吧???因为前面计算过了_output.write(iter->second);// string toAddStr = iter->second;// size_t added = 0;// while (added<iter->second.size()) {// added+=_output.write(iter->second.substr(added, iter->second.size()-added));// }_next_index+=iter->second.size();}iter = _unassembled_strings.begin();for (int i=0; i<toDeleteCount; i++) {_unassembled_strings.erase(iter++);}if (_unassembled_strings.size()==0&&_next_index==_eof_index) {_output.end_input();}}// 返回已经缓存,但未组装到字节流中的字节个数size_t StreamReassembler::unassembled_bytes() const {size_t res=0;auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {res+=iter->second.size();}return res;}// unassembled_bytes()==0bool StreamReassembler::empty() const {return unassembled_bytes()==0;}
测试结果
- 过了一半的样例
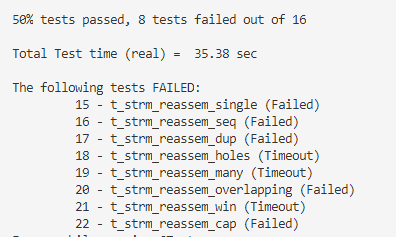
后来发现遍历Map忘记iter++,但是加上去之后测试结果没变
第二阶段
思路
保存乱序数据的结构:Map
- 按照Key的Index从小到大排序,C++的map默认情况下应该就会这样排序
问题:如果当前push了一个string,只能存下这个string的一部分数据怎么办?
- 存一部分数据进去,那么传进来的string会被拆开
- Map中缓存的数据应该是有限的
- next_index+capacity-stream.size()是上界,开区间
- Map中序号最小和序号最大的这两份数据,都可能只是传进来的string的一部分
- ①序号最小的数据,如果Map中只保存了一部分,说明它前面的那部分已经被加入到流中了
- ②序号最大的数据,如果Map中只保存了一部分,说明在它保存进来的那个时刻,达到了capacity指定的上限
- ②是①的因
- 设想这样一种情况,capacity的值比较小,只有100,整个字节流只包含1个string,这个string的大小为1000
- 那么Map中从头到尾放入的数据最多只有1份,且每次只能放入这个string的一部分
算法步骤
- 传入一个string,比较它的区间端点[index, index+string.size())和Map的区间端点[next_index, next_index+capacity-stream.size())的大小关系
- 不相交的部分丢弃,相交的部分添加到Map中
- 实际上,ByteStream的remaining_capacity返回的就是capacity-stream.size()
- [a,b)和[c,d)相交的判断条件是b>c&&d>a;判断相交,则它们相交的区间是[max(a,c), min(b,d))
- 记这里计算得到的待加入Map的字节流区间为[L, R)
- 尝试将[x, y)放入Map中(实际上是一个区间问题)
- 按顺序遍历Map,从中找出与[x, y)相交的区间,这些区间需要被标记删除
- 记这些相交的区间为[a0, b0),[a2, b2),……, [an, bn)
- 那么最终合并后的结果为[a0, b0)的部分+[L, R)+[an, bn)的部分
- 如果没有找到相交的区间,则这里得到的结果就是[L, R)
- 如果相交的区间只有一个,则注意它是[a0, b0)还是 [an, bn),也就是区分在[L, R)的左侧还是右侧
- 从Map中删除这些区间
- 将合并后的结果加入Map中
- 比较next_index和Map中的最小序号
- 如果不相等,则没有数据可以提交到流中
- 如果相等,则从Map中取出从next_index开始的连续字节,放入流中(就是key最小的那个key-value对)
- 问题:第三步中,如果从Map中取出数据,Map有空余容量了,还需要回到第一步吗?
- 不需要!时刻牢记,Map的容量和Stream的容量是合在一起的,在当前时刻,Stream里的数据肯定不会有人拿走(CS144明确说了不涉及多线程,即使涉及多线程,也是加锁的,别人不可能再同一时刻从Stream里取走数据)
- Map有空余容量不代表整体有空余容量
如何处理eof?
- 我设置了一个size_t类型的变量eof_index,初始值为size_t的最大值(字节流会超过size_t的最大值吗)
- 如果收到了带eof=true的string,则更新eof_index
- 如果Map已空,且eof_index不是size_t的最大值(已经被设置),且字节序号已经达到了eof_index,则调用ByteStream的end_input
代码
发现byte_stream的read的bug
std::string ByteStream::read(const size_t len) {string res;// 应该用一个变量保存一开始_data_q的大小size_t init_sz=_data_q.size();// i<_data_q.size()这么写不对!for (size_t i=0; i<len&&i<init_sz; i++) {res+=_data_q.front();_data_q.pop_front();_bytes_read++;}return res;}
#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "byte_stream.hh"#include <cstdint>#include <string>#include <map>#include <utility>//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,//! possibly overlapping) into an in-order byte stream.class StreamReassembler {private:// Your code here -- add private members as necessary.size_t _next_index;size_t _eof_index;std::map<size_t, std::string> _unassembled_strings;size_t _unassembled_bytes;ByteStream _output; //!< The reassembled in-order byte streamsize_t _capacity; //!< The maximum number of bytespublic://! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.//! \note This capacity limits both the bytes that have been reassembled,//! and those that have not yet been reassembled.StreamReassembler(const size_t capacity);//! \brief Receive a substring and write any newly contiguous bytes into the stream.//!//! The StreamReassembler will stay within the memory limits of the `capacity`.//! Bytes that would exceed the capacity are silently discarded.//!//! \param data the substring//! \param index indicates the index (place in sequence) of the first byte in `data`//! \param eof the last byte of `data` will be the last byte in the entire streamvoid push_substring(const std::string &data, const uint64_t index, const bool eof);//! \name Access the reassembled byte stream//!@{const ByteStream &stream_out() const { return _output; }ByteStream &stream_out() { return _output; }//!@}//! The number of bytes in the substrings stored but not yet reassembled//!//! \note If the byte at a particular index has been pushed more than once, it//! should only be counted once for the purpose of this function.size_t unassembled_bytes() const;//! \brief Is the internal state empty (other than the output stream)?//! \returns `true` if no substrings are waiting to be assembledbool empty() const;};#endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "stream_reassembler.hh"#include <cmath>#include <vector>#include <utility>#include <algorithm>#include <cstdio>#include <iostream>// Dummy implementation of a stream reassembler.// For Lab 1, please replace with a real implementation that passes the// automated checks run by `make check_lab1`.// You will need to add private members to the class declaration in `stream_reassembler.hh`template <typename... Targs>void DUMMY_CODE(Targs &&... /* unused */) {}using namespace std;StreamReassembler::StreamReassembler(const size_t capacity): _next_index(0), _eof_index(unsigned(-1)), _unassembled_strings(), _unassembled_bytes(0),_output(capacity), _capacity(capacity) {}//! \details This function accepts a substring (aka a segment) of bytes,//! possibly out-of-order, from the logical stream, and assembles any newly//! contiguous substrings and writes them into the output stream in order.void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {if (eof) {_eof_index = index+data.size();}// [index, index+string.size())// [_next_index, _next_index+capacity-stream.size())=[_next_index, _next_index+_output.remaining_capacity())if (index+data.size()>_next_index&&_next_index+_output.remaining_capacity()>index) { // 有相交的部分,或者说有可以缓存的数据size_t L = std::max(index, _next_index);size_t R = std::min(index+data.size(), _next_index+_output.remaining_capacity());std::string true_data=data.substr(L-index, R-L);size_t x=0,y=0; // 表示了Map中待删除的区间size_t union_l=0, union_r=0;bool isOverlap=false;auto iter = _unassembled_strings.begin();size_t loc=0;std::pair<size_t, std::string> first_zone, last_zone;// std::vector<std::pair<size_t, std::string>> overlapped_strings;while (iter!=_unassembled_strings.end()) {// [L, R)和[iter->first, iter->first+iter.second.size())比较if (iter->first+iter->second.size()>L&&R>iter->first) { // 相交if (!isOverlap) {isOverlap = true;x=y=loc;first_zone=make_pair(iter->first, iter->second);union_l=std::min(L, iter->first);union_r=std::max(R, iter->first+iter->second.size());} else {y++;last_zone=make_pair(iter->first, iter->second);union_r=std::max(R, iter->first+iter->second.size());}} else {if (isOverlap) {break;}}loc++;iter++;}std::string union_string;if (isOverlap) {union_string=std::string(union_r-union_l, 'a');union_string.replace(L-union_l, R-L, true_data);union_string.replace(first_zone.first-union_l, first_zone.second.size(), first_zone.second);if (y>x) {union_string.replace(last_zone.first-union_l, last_zone.second.size(), last_zone.second);}} else {union_l=L;union_r=R;union_string=true_data;}if (isOverlap) {iter = _unassembled_strings.begin();loc=0;while (iter!=_unassembled_strings.end()) {if (loc>=x&&loc<=y) {_unassembled_strings.erase(iter++);} else {iter++;}loc++;}}std::cout<<"【"<<union_l<<","<<union_r<<"】"<<"******"<<std::endl;_unassembled_strings.insert(map<size_t, std::string>::value_type(union_l, union_string));}// 接下来比较_next_index和Map中的最小序号int toDeleteCount=0;auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {if (iter->first!=_next_index) {break;}toDeleteCount++;// 一定可以全部写入吧???因为前面计算过了_output.write(iter->second);// string toAddStr = iter->second;// size_t added = 0;// while (added<iter->second.size()) {// added+=_output.write(iter->second.substr(added, iter->second.size()-added));// }_next_index+=iter->second.size();// bug1: 这里没有iter++}iter = _unassembled_strings.begin();for (int i=0; i<toDeleteCount; i++) {_unassembled_strings.erase(iter++);}if (_unassembled_strings.size()==0&&_next_index==_eof_index) {_output.end_input();std::cout<<"****** called _output.end_input(), unassembled_bytes(): "<<unassembled_bytes()<<std::endl;// std::cout<<"****** _output.eof(): "<<_output.eof()<<std::endl;// std::cout<<"****** empty(): "<<empty()<<std::endl;std::cout<<"****** _output.input_ended(): "<<_output.input_ended()<<std::endl;}std::cout<<"****** new _next_index: "<<_next_index<<std::endl;std::cout<<"****** remaining: "<<_output.remaining_capacity()<<std::endl;// std::cout<<"****** _output.read(): "<<_output.peek_output(8)<<std::endl;// std::cout<<"****** _output"}// 返回已经缓存,但未组装到字节流中的字节个数size_t StreamReassembler::unassembled_bytes() const {size_t res=0;// for (size_t i=0; i<_unassembled_strings.size(); i++) {// res+=_unassembled_strings[i].second.size();// }auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {res+=iter->second.size();// bug2: 这里没有iter++;}return res;}// unassembled_bytes()==0bool StreamReassembler::empty() const {return unassembled_bytes()==0;}
测试结果

到这里git commit一下
两个bug都是没有写iter++
如果在第一阶段的代码中添加上述两处iter++,测试结果如下
其中1个样例如下
很显然是遗漏了1个字节
第三阶段(通过测试)
就是第二阶段的代码,加上两处iter++
#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "byte_stream.hh"#include <cstdint>#include <string>#include <map>#include <utility>//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,//! possibly overlapping) into an in-order byte stream.class StreamReassembler {private:// Your code here -- add private members as necessary.size_t _next_index;size_t _eof_index;std::map<size_t, std::string> _unassembled_strings;size_t _unassembled_bytes;ByteStream _output; //!< The reassembled in-order byte streamsize_t _capacity; //!< The maximum number of bytespublic://! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.//! \note This capacity limits both the bytes that have been reassembled,//! and those that have not yet been reassembled.StreamReassembler(const size_t capacity);//! \brief Receive a substring and write any newly contiguous bytes into the stream.//!//! The StreamReassembler will stay within the memory limits of the `capacity`.//! Bytes that would exceed the capacity are silently discarded.//!//! \param data the substring//! \param index indicates the index (place in sequence) of the first byte in `data`//! \param eof the last byte of `data` will be the last byte in the entire streamvoid push_substring(const std::string &data, const uint64_t index, const bool eof);//! \name Access the reassembled byte stream//!@{const ByteStream &stream_out() const { return _output; }ByteStream &stream_out() { return _output; }//!@}//! The number of bytes in the substrings stored but not yet reassembled//!//! \note If the byte at a particular index has been pushed more than once, it//! should only be counted once for the purpose of this function.size_t unassembled_bytes() const;//! \brief Is the internal state empty (other than the output stream)?//! \returns `true` if no substrings are waiting to be assembledbool empty() const;};#endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "stream_reassembler.hh"#include <cmath>#include <vector>#include <utility>#include <algorithm>#include <cstdio>#include <iostream>// Dummy implementation of a stream reassembler.// For Lab 1, please replace with a real implementation that passes the// automated checks run by `make check_lab1`.// You will need to add private members to the class declaration in `stream_reassembler.hh`template <typename... Targs>void DUMMY_CODE(Targs &&... /* unused */) {}using namespace std;StreamReassembler::StreamReassembler(const size_t capacity): _next_index(0), _eof_index(unsigned(-1)), _unassembled_strings(), _unassembled_bytes(0),_output(capacity), _capacity(capacity) {}//! \details This function accepts a substring (aka a segment) of bytes,//! possibly out-of-order, from the logical stream, and assembles any newly//! contiguous substrings and writes them into the output stream in order.void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {if (eof) {_eof_index = index+data.size();}// [index, index+string.size())// [_next_index, _next_index+capacity-stream.size())=[_next_index, _next_index+_output.remaining_capacity())if (index+data.size()>_next_index&&_next_index+_output.remaining_capacity()>index) { // 有相交的部分,或者说有可以缓存的数据size_t L = std::max(index, _next_index);size_t R = std::min(index+data.size(), _next_index+_output.remaining_capacity());std::string true_data=data.substr(L-index, R-L);size_t x=0,y=0; // 表示了Map中待删除的区间size_t union_l=0, union_r=0;bool isOverlap=false;auto iter = _unassembled_strings.begin();size_t loc=0;std::pair<size_t, std::string> first_zone, last_zone;// std::vector<std::pair<size_t, std::string>> overlapped_strings;while (iter!=_unassembled_strings.end()) {// [L, R)和[iter->first, iter->first+iter.second.size())比较if (iter->first+iter->second.size()>L&&R>iter->first) { // 相交if (!isOverlap) {isOverlap = true;x=y=loc;first_zone=make_pair(iter->first, iter->second);union_l=std::min(L, iter->first);union_r=std::max(R, iter->first+iter->second.size());} else {y++;last_zone=make_pair(iter->first, iter->second);union_r=std::max(R, iter->first+iter->second.size());}} else {if (isOverlap) {break;}}loc++;iter++;}std::string union_string;if (isOverlap) {union_string=std::string(union_r-union_l, 'a');union_string.replace(L-union_l, R-L, true_data);union_string.replace(first_zone.first-union_l, first_zone.second.size(), first_zone.second);if (y>x) {union_string.replace(last_zone.first-union_l, last_zone.second.size(), last_zone.second);}} else {union_l=L;union_r=R;union_string=true_data;}if (isOverlap) {iter = _unassembled_strings.begin();loc=0;while (iter!=_unassembled_strings.end()) {if (loc>=x&&loc<=y) {_unassembled_strings.erase(iter++);} else {iter++;}loc++;}}std::cout<<"【"<<union_l<<","<<union_r<<"】"<<"******"<<std::endl;_unassembled_strings.insert(map<size_t, std::string>::value_type(union_l, union_string));}// 接下来比较_next_index和Map中的最小序号int toDeleteCount=0;auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {if (iter->first!=_next_index) {break;}toDeleteCount++;// 一定可以全部写入吧???因为前面计算过了_output.write(iter->second);// string toAddStr = iter->second;// size_t added = 0;// while (added<iter->second.size()) {// added+=_output.write(iter->second.substr(added, iter->second.size()-added));// }_next_index+=iter->second.size();iter++;}iter = _unassembled_strings.begin();for (int i=0; i<toDeleteCount; i++) {_unassembled_strings.erase(iter++);}if (_unassembled_strings.size()==0&&_next_index==_eof_index) {_output.end_input();std::cout<<"****** called _output.end_input(), unassembled_bytes(): "<<unassembled_bytes()<<std::endl;// std::cout<<"****** _output.eof(): "<<_output.eof()<<std::endl;// std::cout<<"****** empty(): "<<empty()<<std::endl;std::cout<<"****** _output.input_ended(): "<<_output.input_ended()<<std::endl;}std::cout<<"****** new _next_index: "<<_next_index<<std::endl;std::cout<<"****** remaining: "<<_output.remaining_capacity()<<std::endl;// std::cout<<"****** _output.read(): "<<_output.peek_output(8)<<std::endl;// std::cout<<"****** _output"}// 返回已经缓存,但未组装到字节流中的字节个数size_t StreamReassembler::unassembled_bytes() const {size_t res=0;// for (size_t i=0; i<_unassembled_strings.size(); i++) {// res+=_unassembled_strings[i].second.size();// }auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {res+=iter->second.size();iter++;}return res;}// unassembled_bytes()==0bool StreamReassembler::empty() const {return unassembled_bytes()==0;}

第四阶段
- 在刚开始写Lab2时,发现TCPReceiver需要用到我在StreamReassembler中设置的私有变量_next_index
- 但是实验文档强调了不能修改公有接口,所以我开始思考StreamReassembler中是否有必要设置_next_index这个私有成员变量
- 实际上,ByteStream有一个接口是size_t bytes_written() const;
- 这个接口返回了流中写入了多少数据,实际上就是流的下一个字节序号
- 也就是我一开始设置的_next_index
所以我打算去掉_next_index,为了使改动最小化,我将类成员_next_index改为next_index,即去掉了前面的下划线
- 类的方法中没有一处用到了next_index
- 在StreamReassembler::push_substring的开头,定义局部变量_next_index,取值为_output.bytes_written()
潜在的问题:在StreamReassembler::push_substring的最后,我假设_output.write一定会成功,且一定能够把所有字节加进去 ```cpp
ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
include “byte_stream.hh”
include
include
include
include
//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,
//! possibly overlapping) into an in-order byte stream.
class StreamReassembler {
private:
// Your code here — add private members as necessary.
size_t next_index;
size_t _eof_index;
std::map
ByteStream _output; //!< The reassembled in-order byte streamsize_t _capacity; //!< The maximum number of bytes
public:
//! \brief Construct a StreamReassembler that will store up to capacity bytes.
//! \note This capacity limits both the bytes that have been reassembled,
//! and those that have not yet been reassembled.
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes into the stream.//!//! The StreamReassembler will stay within the memory limits of the `capacity`.//! Bytes that would exceed the capacity are silently discarded.//!//! \param data the substring//! \param index indicates the index (place in sequence) of the first byte in `data`//! \param eof the last byte of `data` will be the last byte in the entire streamvoid push_substring(const std::string &data, const uint64_t index, const bool eof);//! \name Access the reassembled byte stream//!@{const ByteStream &stream_out() const { return _output; }ByteStream &stream_out() { return _output; }//!@}//! The number of bytes in the substrings stored but not yet reassembled//!//! \note If the byte at a particular index has been pushed more than once, it//! should only be counted once for the purpose of this function.size_t unassembled_bytes() const;//! \brief Is the internal state empty (other than the output stream)?//! \returns `true` if no substrings are waiting to be assembledbool empty() const;
};
endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
include “stream_reassembler.hh”
include
include
include
include
include
include
// Dummy implementation of a stream reassembler.
// For Lab 1, please replace with a real implementation that passes the
// automated checks run by make check_lab1.
// You will need to add private members to the class declaration in stream_reassembler.hh
template
using namespace std;
StreamReassembler::StreamReassembler(const size_t capacity) : next_index(0), _eof_index(unsigned(-1)), _unassembled_strings(), _unassembled_bytes(0), _output(capacity), _capacity(capacity) {
}
//! \details This function accepts a substring (aka a segment) of bytes, //! possibly out-of-order, from the logical stream, and assembles any newly //! contiguous substrings and writes them into the output stream in order. void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) { if (eof) { _eof_index = index+data.size(); }
size_t _next_index=_output.bytes_written();// [index, index+string.size())// [_next_index, _next_index+capacity-stream.size())=[_next_index, _next_index+_output.remaining_capacity())if (index+data.size()>_next_index&&_next_index+_output.remaining_capacity()>index) { // 有相交的部分,或者说有可以缓存的数据size_t L = std::max(index, _next_index);size_t R = std::min(index+data.size(), _next_index+_output.remaining_capacity());std::string true_data=data.substr(L-index, R-L);size_t x=0,y=0; // 表示了Map中待删除的区间size_t union_l=0, union_r=0;bool isOverlap=false;auto iter = _unassembled_strings.begin();size_t loc=0;std::pair<size_t, std::string> first_zone, last_zone;// std::vector<std::pair<size_t, std::string>> overlapped_strings;while (iter!=_unassembled_strings.end()) {// [L, R)和[iter->first, iter->first+iter.second.size())比较if (iter->first+iter->second.size()>L&&R>iter->first) { // 相交if (!isOverlap) {isOverlap = true;x=y=loc;first_zone=make_pair(iter->first, iter->second);union_l=std::min(L, iter->first);union_r=std::max(R, iter->first+iter->second.size());} else {y++;last_zone=make_pair(iter->first, iter->second);union_r=std::max(R, iter->first+iter->second.size());}} else {if (isOverlap) {break;}}loc++;iter++;}std::string union_string;if (isOverlap) {union_string=std::string(union_r-union_l, 'a');union_string.replace(L-union_l, R-L, true_data);union_string.replace(first_zone.first-union_l, first_zone.second.size(), first_zone.second);if (y>x) {union_string.replace(last_zone.first-union_l, last_zone.second.size(), last_zone.second);}} else {union_l=L;union_r=R;union_string=true_data;}if (isOverlap) {iter = _unassembled_strings.begin();loc=0;while (iter!=_unassembled_strings.end()) {if (loc>=x&&loc<=y) {_unassembled_strings.erase(iter++);} else {iter++;}loc++;}}// std::cout<<"【"<<union_l<<","<<union_r<<"】"<<"******"<<std::endl;_unassembled_strings.insert(map<size_t, std::string>::value_type(union_l, union_string));}// 接下来比较_next_index和Map中的最小序号int toDeleteCount=0;auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {if (iter->first!=_next_index) {break;}toDeleteCount++;// 一定可以全部写入吧???因为前面计算过了_output.write(iter->second);// string toAddStr = iter->second;// size_t added = 0;// while (added<iter->second.size()) {// added+=_output.write(iter->second.substr(added, iter->second.size()-added));// }_next_index+=iter->second.size();iter++;}iter = _unassembled_strings.begin();for (int i=0; i<toDeleteCount; i++) {_unassembled_strings.erase(iter++);}if (_unassembled_strings.size()==0&&_next_index==_eof_index) {_output.end_input();// std::cout<<"****** called _output.end_input(), unassembled_bytes(): "<<unassembled_bytes()<<std::endl;// std::cout<<"****** _output.eof(): "<<_output.eof()<<std::endl;// std::cout<<"****** empty(): "<<empty()<<std::endl;// std::cout<<"****** _output.input_ended(): "<<_output.input_ended()<<std::endl;}// std::cout<<"****** new _next_index: "<<_next_index<<std::endl;// std::cout<<"****** remaining: "<<_output.remaining_capacity()<<std::endl;// std::cout<<"****** _output.read(): "<<_output.peek_output(8)<<std::endl;// std::cout<<"****** _output"
}
// 返回已经缓存,但未组装到字节流中的字节个数 size_t StreamReassembler::unassembled_bytes() const { size_t res=0; // for (size_t i=0; i<_unassembled_strings.size(); i++) { // res+=_unassembled_strings[i].second.size(); // } auto iter = _unassembled_strings.begin(); while (iter!=_unassembled_strings.end()) { res+=iter->second.size(); iter++; } return res; }
// unassembled_bytes()==0 bool StreamReassembler::empty() const { return unassembled_bytes()==0; }
<a name="ydbF6"></a># 第五阶段- 引入Lab4的代码后,新增了测试,Lab1又有样例没过,经过DEBUG,发现是我对空串的处理没有做好。- 如果push_strings传入的是一个空串,我可能会把空串放入**_unassembled_strings**这个Map中,然后就一直留在Map中了。- 需要修改的地方有两处,一个是判断data.size()>0,才进行把它加入**_unassembled_strings**的操作。- 由于可能传入一个带着eof标志的空串,所以当前这次操作可能只是更新eof- 更新了eof,可能整个流的组装就结束了,所以最后的代码逻辑也需要运行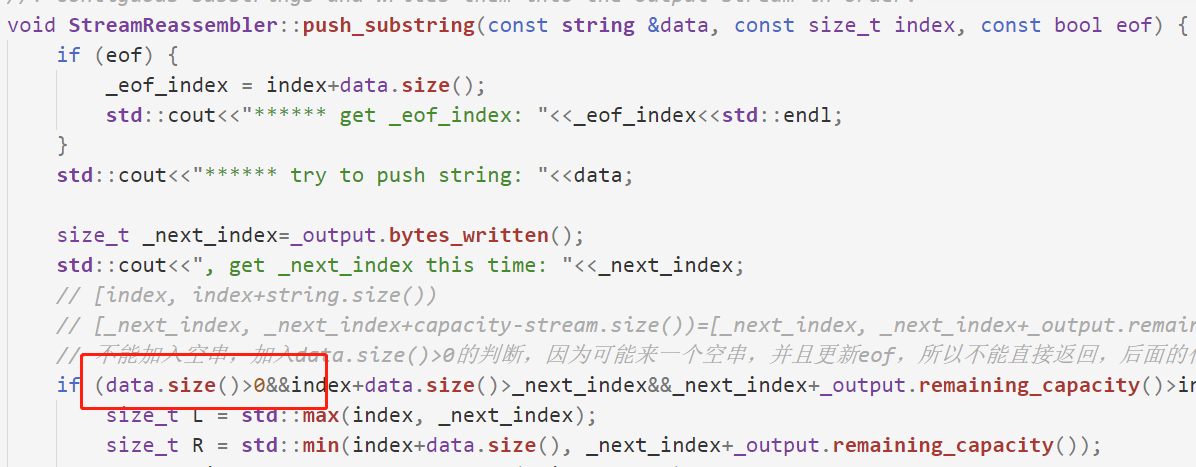- 修改了最后调用_output.end_input()的判断条件- 之前是`_unassembled_strings.size()==0`,这个条件不精确- 应该改成`unassembled_bytes()==0`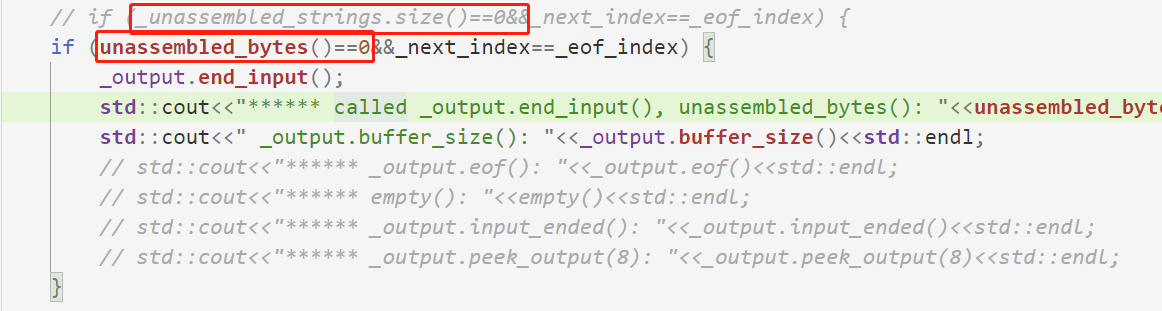下面是修改后的代码```cpp#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "byte_stream.hh"#include <cstdint>#include <string>#include <map>#include <utility>//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,//! possibly overlapping) into an in-order byte stream.class StreamReassembler {private:// Your code here -- add private members as necessary.size_t next_index;size_t _eof_index;std::map<size_t, std::string> _unassembled_strings;size_t _unassembled_bytes;ByteStream _output; //!< The reassembled in-order byte streamsize_t _capacity; //!< The maximum number of bytespublic://! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.//! \note This capacity limits both the bytes that have been reassembled,//! and those that have not yet been reassembled.StreamReassembler(const size_t capacity);//! \brief Receive a substring and write any newly contiguous bytes into the stream.//!//! The StreamReassembler will stay within the memory limits of the `capacity`.//! Bytes that would exceed the capacity are silently discarded.//!//! \param data the substring//! \param index indicates the index (place in sequence) of the first byte in `data`//! \param eof the last byte of `data` will be the last byte in the entire streamvoid push_substring(const std::string &data, const uint64_t index, const bool eof);//! \name Access the reassembled byte stream//!@{const ByteStream &stream_out() const { return _output; }ByteStream &stream_out() { return _output; }//!@}//! The number of bytes in the substrings stored but not yet reassembled//!//! \note If the byte at a particular index has been pushed more than once, it//! should only be counted once for the purpose of this function.size_t unassembled_bytes() const;//! \brief Is the internal state empty (other than the output stream)?//! \returns `true` if no substrings are waiting to be assembledbool empty() const;};#endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH#include "stream_reassembler.hh"#include <cmath>#include <vector>#include <utility>#include <algorithm>#include <cstdio>#include <iostream>// Dummy implementation of a stream reassembler.// For Lab 1, please replace with a real implementation that passes the// automated checks run by `make check_lab1`.// You will need to add private members to the class declaration in `stream_reassembler.hh`template <typename... Targs>void DUMMY_CODE(Targs &&... /* unused */) {}using namespace std;StreamReassembler::StreamReassembler(const size_t capacity): next_index(0), _eof_index(unsigned(-1)), _unassembled_strings(), _unassembled_bytes(0),_output(capacity), _capacity(capacity) {std::cout<<"****** StreamReassembler created"<<std::endl;}//! \details This function accepts a substring (aka a segment) of bytes,//! possibly out-of-order, from the logical stream, and assembles any newly//! contiguous substrings and writes them into the output stream in order.void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {if (eof) {_eof_index = index+data.size();std::cout<<"****** get _eof_index: "<<_eof_index<<std::endl;}std::cout<<"****** try to push string: "<<data;size_t _next_index=_output.bytes_written();std::cout<<", get _next_index this time: "<<_next_index;// [index, index+string.size())// [_next_index, _next_index+capacity-stream.size())=[_next_index, _next_index+_output.remaining_capacity())// 不能加入空串,加入data.size()>0的判断,因为可能来一个空串,并且更新eof,所以不能直接返回,后面的代码还要运行if (data.size()>0&&index+data.size()>_next_index&&_next_index+_output.remaining_capacity()>index) { // 有相交的部分,或者说有可以缓存的数据size_t L = std::max(index, _next_index);size_t R = std::min(index+data.size(), _next_index+_output.remaining_capacity());std::string true_data=data.substr(L-index, R-L);std::cout<<", pushed: "<<true_data;size_t x=0,y=0; // 表示了Map中待删除的区间size_t union_l=0, union_r=0;bool isOverlap=false;auto iter = _unassembled_strings.begin();size_t loc=0;std::pair<size_t, std::string> first_zone, last_zone;// std::vector<std::pair<size_t, std::string>> overlapped_strings;while (iter!=_unassembled_strings.end()) {// [L, R)和[iter->first, iter->first+iter.second.size())比较if (iter->first+iter->second.size()>L&&R>iter->first) { // 相交if (!isOverlap) {isOverlap = true;x=y=loc;first_zone=make_pair(iter->first, iter->second);union_l=std::min(L, iter->first);union_r=std::max(R, iter->first+iter->second.size());} else {y++;last_zone=make_pair(iter->first, iter->second);union_r=std::max(R, iter->first+iter->second.size());}} else {if (isOverlap) {break;}}loc++;iter++;}std::string union_string;if (isOverlap) {union_string=std::string(union_r-union_l, 'a');union_string.replace(L-union_l, R-L, true_data);union_string.replace(first_zone.first-union_l, first_zone.second.size(), first_zone.second);if (y>x) {union_string.replace(last_zone.first-union_l, last_zone.second.size(), last_zone.second);}} else {union_l=L;union_r=R;union_string=true_data;}if (isOverlap) {iter = _unassembled_strings.begin();loc=0;while (iter!=_unassembled_strings.end()) {if (loc>=x&&loc<=y) {_unassembled_strings.erase(iter++);} else {iter++;}loc++;}}// std::cout<<"【"<<union_l<<","<<union_r<<"】"<<"******"<<std::endl;_unassembled_strings.insert(map<size_t, std::string>::value_type(union_l, union_string));}// 接下来比较_next_index和Map中的最小序号int toDeleteCount=0;auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {if (iter->first!=_next_index) {break;}toDeleteCount++;// 一定可以全部写入吧???因为前面计算过了_output.write(iter->second);// string toAddStr = iter->second;// size_t added = 0;// while (added<iter->second.size()) {// added+=_output.write(iter->second.substr(added, iter->second.size()-added));// }_next_index+=iter->second.size();iter++;}iter = _unassembled_strings.begin();for (int i=0; i<toDeleteCount; i++) {_unassembled_strings.erase(iter++);}std::cout<<", buffer size now: "<<_output.buffer_size();std::cout<<", _next_index now: "<<_next_index;std::cout<<", unassembled_bytes now: "<<unassembled_bytes();std::cout<<", _unassembled_strings.size(): "<<_unassembled_strings.size()<<std::endl;// if (_unassembled_strings.size()==0&&_next_index==_eof_index) {if (unassembled_bytes()==0&&_next_index==_eof_index) {_output.end_input();std::cout<<"****** called _output.end_input(), unassembled_bytes(): "<<unassembled_bytes();std::cout<<" _output.buffer_size(): "<<_output.buffer_size()<<std::endl;// std::cout<<"****** _output.eof(): "<<_output.eof()<<std::endl;// std::cout<<"****** empty(): "<<empty()<<std::endl;// std::cout<<"****** _output.input_ended(): "<<_output.input_ended()<<std::endl;// std::cout<<"****** _output.peek_output(8): "<<_output.peek_output(8)<<std::endl;}// std::cout<<"****** new _next_index: "<<_next_index<<std::endl;// std::cout<<"****** remaining: "<<_output.remaining_capacity()<<std::endl;// std::cout<<"****** _output.read(): "<<_output.peek_output(8)<<std::endl;// std::cout<<"****** _output"}// 返回已经缓存,但未组装到字节流中的字节个数size_t StreamReassembler::unassembled_bytes() const {size_t res=0;// for (size_t i=0; i<_unassembled_strings.size(); i++) {// res+=_unassembled_strings[i].second.size();// }auto iter = _unassembled_strings.begin();while (iter!=_unassembled_strings.end()) {res+=iter->second.size();iter++;}return res;}// unassembled_bytes()==0bool StreamReassembler::empty() const {return unassembled_bytes()==0;}

若有收获,就点个赞吧
0 人点赞
