微博、微信、LinkedIn 这些社交软件的用户和用户关系是怎么存储的呢?在微博中,两个人可以互相关注;在微信中,两个人可以互加好友,这些情况用数组或者链表,树之类的存储结构效率是很低下的,而且复杂。
图的概念
无向图
下图是一般情况下无向图的表示:包括顶点和边。
就拿微信举例子吧。我们可以把每个用户看作一个顶点。如果两个用户之间互加好友,那就在两者之间建立一条边。所以,整个微信的好友关系就可以用一张图来表示。其中,每个用户有多少个好友,对应到图中,就叫作顶点的度(degree),就是跟顶点相连接的边的条数。
有向图
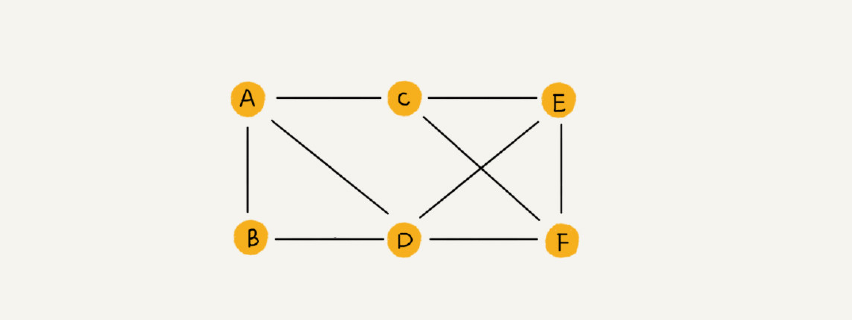
微博的情况和微信还不一样,微博里,A可以关注B,但是B没有关注A。这时候就可以用有向图来表示。如下图所示
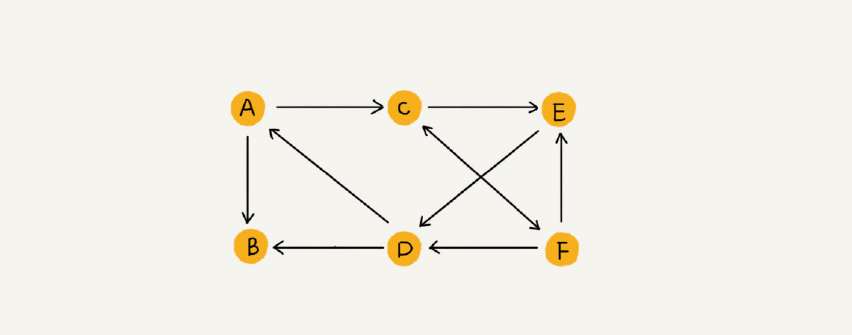
无向图中有“度”这个概念,表示一个顶点有多少条边。在有向图中,我们把度分为入度(In-degree)和出度(Out-degree)
顶点的入度,表示有多少条边指向这个顶点;顶点的出度,表示有多少条边是以这个顶点为起点指向其他顶点。对应到微博的例子,入度就表示有多少粉丝,出度就表示关注了多少人。
带权图
带权图是连接两个顶点的边是有权重的,例如QQ,可以显示好友之间的亲密度。(也可以看做为顶点之间的距离)。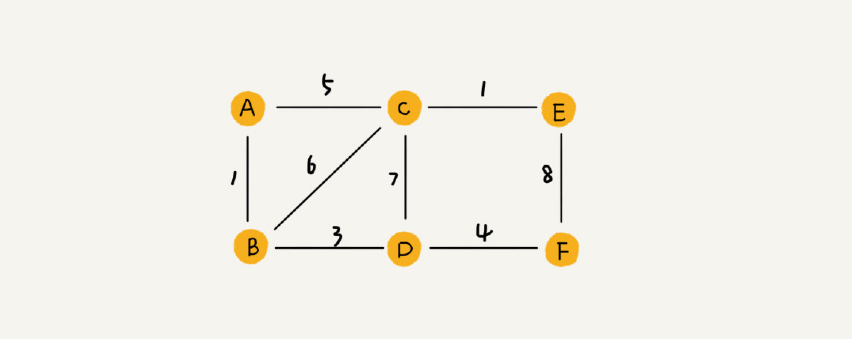
图的存储
邻接矩阵
图最直观的一种存储方法就是,邻接矩阵(Adjacency Matrix)。
邻接矩阵的底层依赖一个二维数组。对于无向图来说,如果顶点i 与顶点j 之间有边,我们就将A[i][j] 和A[j][i] 标记为1;对于有向图来说,如果顶点i 到顶点j 之间,有一条箭头从顶点i 指向顶点j 的边,那我们就将A[i][j] 标记为1。同理,如果有一条箭头从顶点j 指向顶点i 的边,我们就将A[j][i] 标记为1。对于带权图,数组中就存储相应的权重。
一起看看各种图在邻接矩阵存储下是什么样的: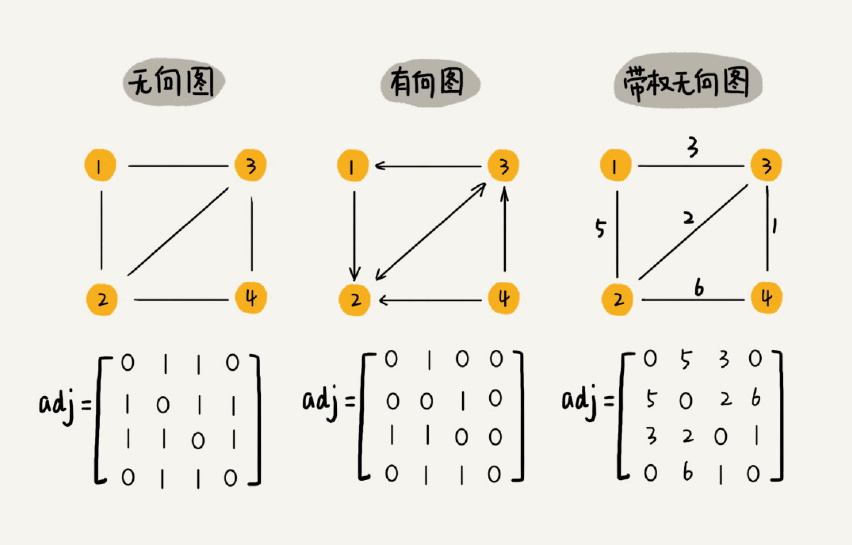
用邻接矩阵来表示一个图,虽然简单、直观,但是比较浪费存储空间。为什么这么说呢? 对于无向图来说,如果A[i][j] 等于1,那A[j][i] 也肯定等于1。实际上,我们只需要存储一个就可以了。也就是说,无向图的二维数组中,如果我们将其用对角线划分为上下两部分,那我们只需要利用上面或者下面这样一半的空间就足够了,另外一半白白浪费掉了。还有,如果我们存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
但这也并不是说,邻接矩阵的存储方法就完全没有优点。首先,邻接矩阵的存储方式简单、直接,因为基于数组,所以在获取两个顶点的关系时,就非常高效。其次,用邻接矩阵存储图的另外一个好处是方便计算。这是因为,用邻接矩阵的方式存储图,可以将很多图的运算转换成矩阵之间的运算。比如求解最短路径问题时会提到一个Floyd-Warshall 算法,就是利用矩阵循环相乘若干次得到结果。
邻接表存储方法
针对上面邻接矩阵比较浪费内存空间的问题,我们来看另外一种图的存储方法,邻接表(Adjacency List)。
下图是图的邻接表存储,乍一看,邻接表是不是有点像散列表?每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。另外我需要说明一下,图中画的是一个有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。对于无向图来说,也是类似的,不过,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点,你可以自己画下。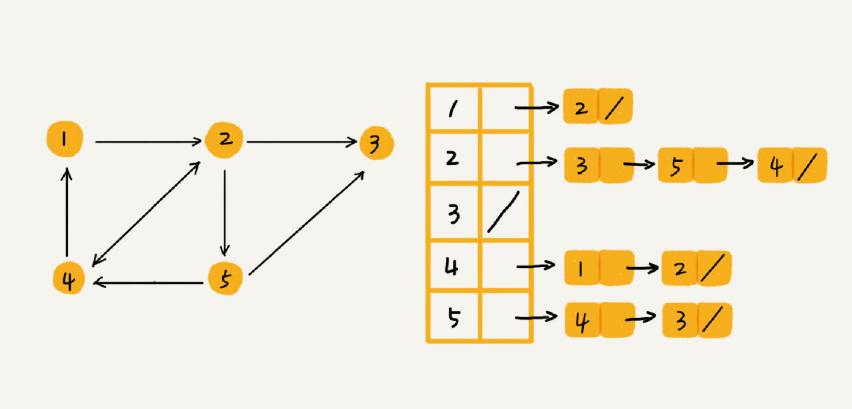
邻接矩阵存储起来比较浪费空间,但是使用起来比较节省时间。相反,邻接表存储起来比较节省空间,但是使用起来就比较耗时间。
就像图中的例子,如果我们要确定,是否存在一条从顶点2 到顶点4 的边,那我们就要遍历顶点2 对应的那条链表,看链表中是否存在顶点4。而且,我们前面也讲过,链表的存储方式对缓存不友好。所以,比起邻接矩阵的存储方式,在邻接表中查询两个顶点之间的关系就没那么高效了。
关于如何存储一个图,前面我们讲到两种主要的存储方法,邻接矩阵和邻接表。因为社交网络是一张稀疏图,使用邻接矩阵存储比较浪费存储空间。所以,这里我们采用邻接表来存储。不过,用一个邻接表来存储这种有向图是不够的。我们去查找某个用户关注了哪些用户非常
容易,但是如果要想知道某个用户都被哪些用户关注了,也就是用户的粉丝列表,是非常困难的。基于此,我们需要一个逆邻接表。邻接表中存储了用户的关注关系,逆邻接表中存储的是用户的被关注关系。对应到图上,邻接表中,每个顶点的链表中,存储的就是这个顶点指向的顶点,逆邻接表中,每个顶点的链表中,存储的是指向这个顶点的顶点。如果要查找某个用户关注了哪些用户,我们可以在邻接表中查找;如果要查找某个用户被哪些用户关注了,我们从逆邻接表中查找。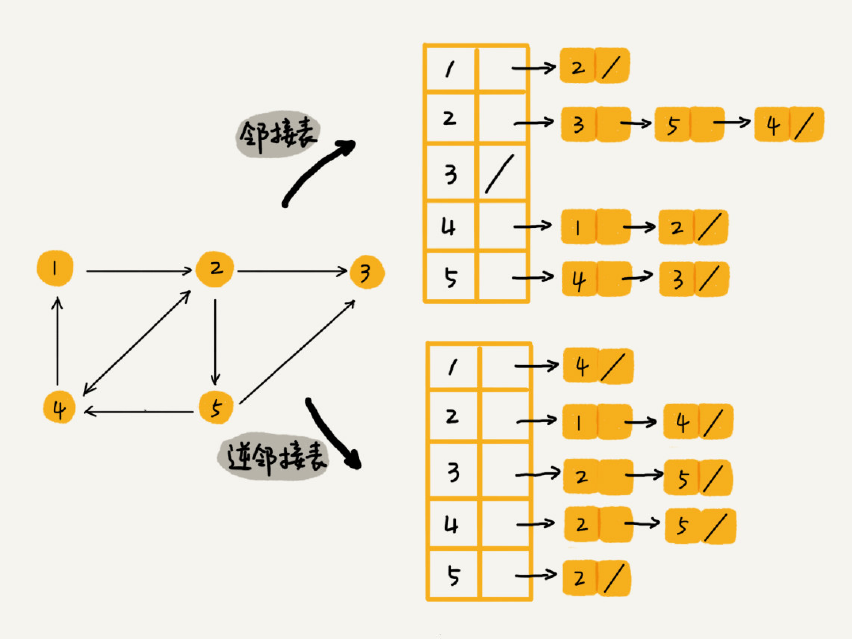
基础的邻接表不适合快速判断两个用户之间是否是关注与被关注的关系,所以我们选择改进版本,将邻接表中的链表改为支持快速查找的动态数据结构。选择哪种动态数据结构呢?红黑树、跳表、有序动态数组还是散列表呢?因为我们需要按照用户名称的首字母排序,分页来获取用户的粉丝列表或者关注列表,用跳表这种结构再合适不过了。这是因为,跳表插入、删除、查找都非常高效,时间复杂度是O(logn),空间复杂度上稍高,是O(n)。最重要的一点,跳表中存储的数据本来就是有序的了,分页获取粉丝列表或关注列表,就非常高效。如果对于小规模的数据,比如社交网络中只有几万、几十万个用户,我们可以将整个社交关系存储在内存中,上面的解决思路是没有问题的。但是如果像微博那样有上亿的用户,数据规模太大,我们就无法全部存储在内存中了。这个时候该怎么办呢?
我们可以通过哈希算法等数据分片方式,将邻接表存储在不同的机器上。你可以看下面这幅图,我们在机器1 上存储顶点1,2,3 的邻接表,在机器2 上,存储顶点4,5 的邻接表。逆邻接表的处理方式也一样。当要查询顶点与顶点关系的时候,我们就利用同样的哈希算法,先定位顶点所在的机器,然后再在相应的机器上查找。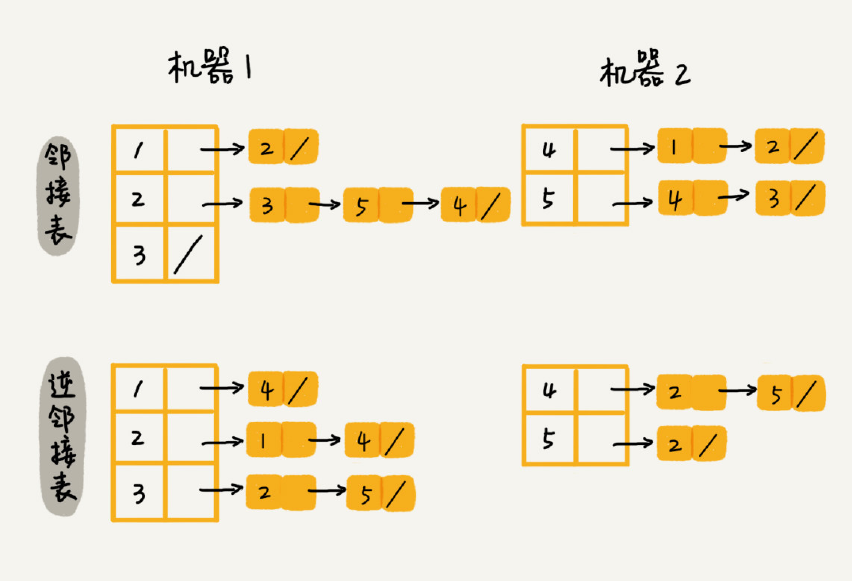
除此之外,我们还有另外一种解决思路,就是利用外部存储(比如硬盘),因为外部存储的存储空间要比内存会宽裕很多。数据库是我们经常用来持久化存储关系数据的,所以我这里介绍一种数据库的存储方式。我用下面这张表来存储这样一个图。为了高效地支持前面定义的操作,我们可以在表上建立多个索引,比如第一列、第二列,给这两列都建立索引。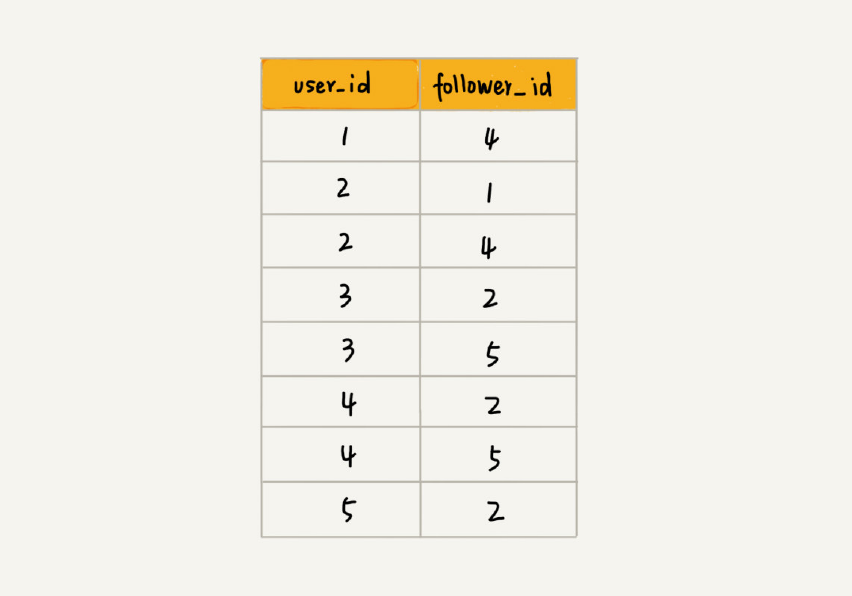
内容小结
今天我们学习了图这种非线性表数据结构,关于图,你需要理解这样几个概念:无向图、有向图、带权图、顶点、边、度、入度、出度。除此之外,我们还学习了图的两个主要的存储方式:邻接矩阵和邻接表。邻接矩阵存储方法的缺点是比较浪费空间,但是优点是查询效率高,而且方便矩阵运算。邻接表存储方法中每个顶点都对应一个链表,存储与其相连接的其他顶点。尽管邻接表的存储方式比较节省存储空间,但链表不方便查找,所以查询效率没有邻接矩阵存储方式高。针对这个问题,邻接表还有改进升级版,即将链表换成更加高效的动态数据结构,比如平衡二叉查找树、跳表、散列表等。

若有收获,就点个赞吧
0 人点赞
