不管是应付面试还是工作需要,只要集中精力逐一攻克这 20 个知识点就足够了。
10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;
10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态 规划、字符串匹配算法
掌握了这些基础的数据结构和算法,再学更加复杂的数据结构和算法,就会非常容易、非常快。
复杂度分析
时间复杂度分析
- 只关注循环执行次数最多的一段代码
- 加法法则:总复杂度等于量级最大的那段代码的复杂度
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积

对于罗列的复杂度量级,我们可以粗略地分为两类,多项式量级和非多项式量级。其中,非多项式量级只有两个:O(2 ) 和 O(n!)
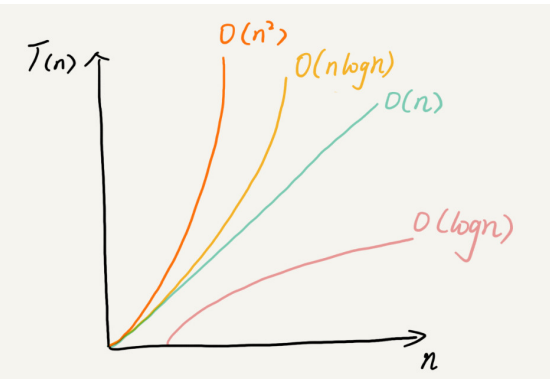
- O(logn)、O(nlogn)
```typescript i=1; while (i <= n) { i = i * 2; }
// O(log2 n)
```typescript
i=1;
while (i <= n) {
i = i * 3;
}
// O(log3 n)。
对数之间是可以互相转换的,log3n就等于log32 * log2n,所以O(log3n) = O(C * log2n),其中 C=log32 是一个常量。
基于我们前面的一个理论:在采用大 O 标记复杂度的时 候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log3n) 就等于 O(log2n)。
因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)。
空间复杂度分析
我们常见的空间复杂度就是 O(1)、O(n)、O(n ),像 O(logn)、O(nlogn) 这样的对数阶复杂度 平时都用不到。
int[] a = new int[n];
O(n)
线性表
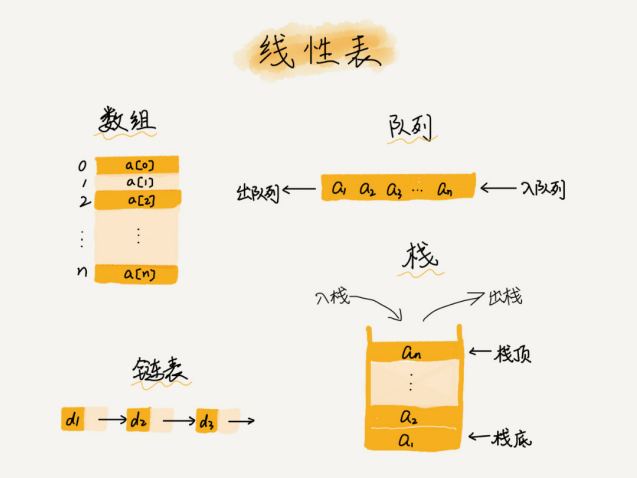
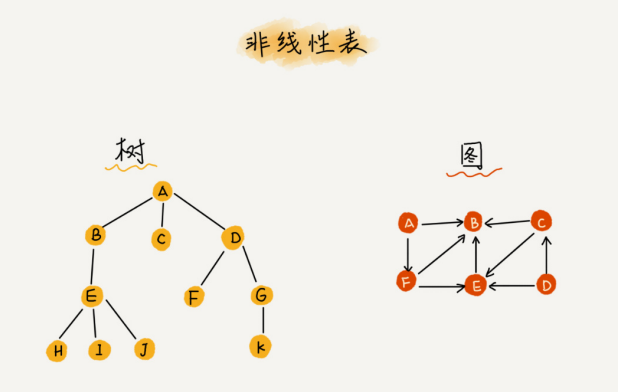
链表
技巧一:理解指针或引用的含义
指针 = 引用,指向的是地址
- 在编写链表代码的时候,我们经常会有这样的代码:
p->next=q。这行代码是说,p 结点中的 next 指针存储了 q 结点的内存地址 p->next=p->next->next。这行代码 表示,p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。技巧二:警惕指针丢失和内存泄漏
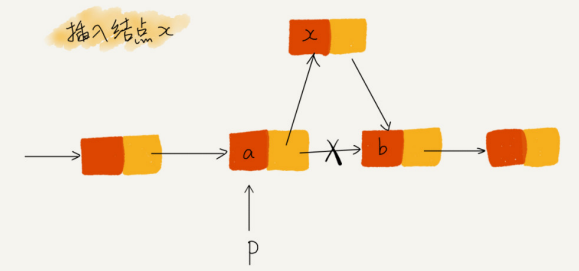
插入结点时,一定要注意操作的顺序,要先将结点 x 的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内 存泄漏
技巧三:利用哨兵简化实现难度 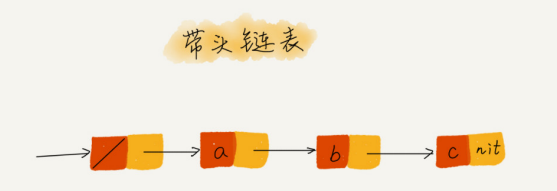
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结 点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链 表。
技巧四:重点留意边界条件处理
我经常用来检查链表代码是否正确的边界条件有这样几个:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
技巧五:举例画图,辅助思考
技巧六:多写多练,没有捷径
5 个常见的链表操作。
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
-
递归
递归写法
递归需要满足的三个条件
1. 一个问题的解可以分解为几个子问题的解
2. 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
3. 存在递归终止条件所以 n 个台阶的走法就等于先走 1 阶后,n-1 个台阶 的走法 加上先走 2 阶后,n-2 个台阶的走法。
int f(int n) { if (n == 1) return 1; if (n == 2) return 2; return f(n-1) + f(n-2); }写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将 递推公式 和 终止条件 翻译成代码。
对于递归代码,这种试图想清楚整个递和归过程的做法,实际上是进入了一个思维误区
如果一个问题 A 可以分解为若干子问题 B、C、D,你可以假设子问题 B、C、D 已经解决,在 此基础上思考如何解决问题 A。而且,你只需要思考问题 A 与子问题 B、C、D 两层之间的关系 即可,不需要一层一层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉 递归细节,这样子理解起来就简单多了。
因此,编写递归代码的关键是,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
递归常见问题及解决方案
1.警惕堆栈溢出:可以声明一个全局变量来控制递归的深度,从而避免堆栈溢出。 2.警惕重复计算:通过某种数据结构来保存已经求解过的值,从而避免重复计算。
除了堆栈溢出、重复计算这两个常见的问题。递归代码还有很多别的问题。
在时间效率上,递归代码里多了很多函数调用,当这些函数调用的数量较大时,就会积聚成一个 可观的时间成本。在空间复杂度上,因为递归调用一次就会在内存栈中保存一次现场数据,所以 在分析递归代码空间复杂度时,需要额外考虑这部分的开销
怎么将递归代码改写为非递归代码?
那是不是所有的递归代码都可以改为这种迭代循环的非递归写法呢?
笼统地讲,是的。因为递归本身就是借助栈来实现的,只不过我们使用的栈是系统或者虚拟机本 身提供的,我们没有感知罢了。如果我们自己在内存堆上实现栈,手动模拟入栈、出栈过程,这 样任何递归代码都可以改写成看上去不是递归代码的样子。
但是这种思路实际上是将递归改为了“手动”递归,本质并没有变,而且也并没有解决前面讲到 的某些问题,徒增了实现的复杂度。
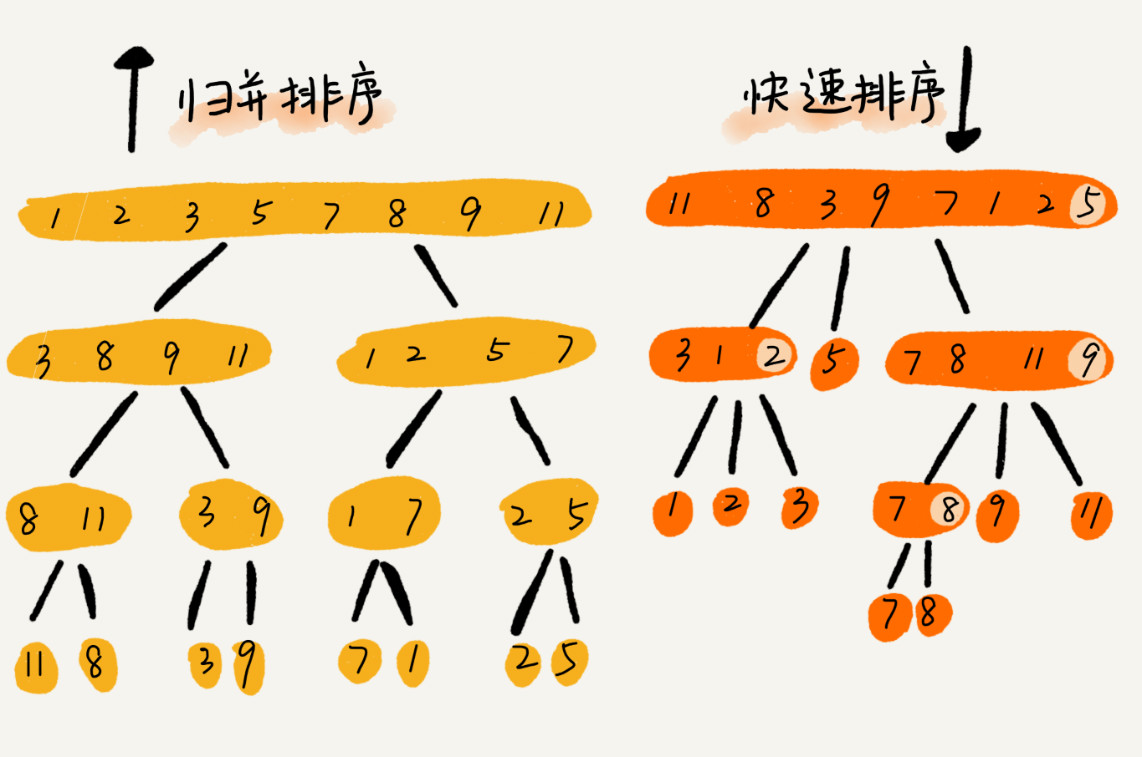
排序
二叉树
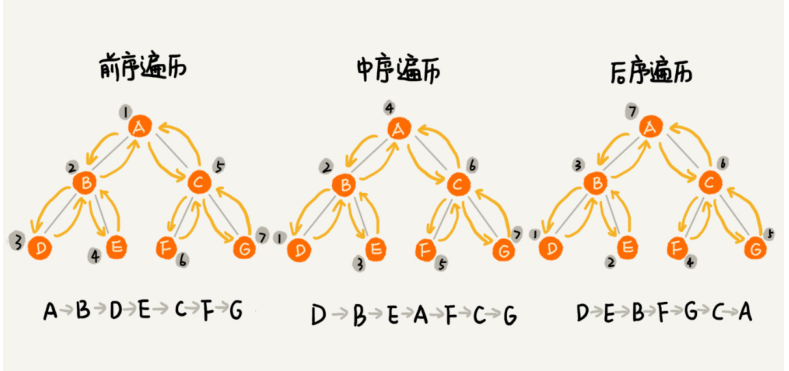
二叉查找树(Binary Search Tree)
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
红黑树
平衡二叉查找树
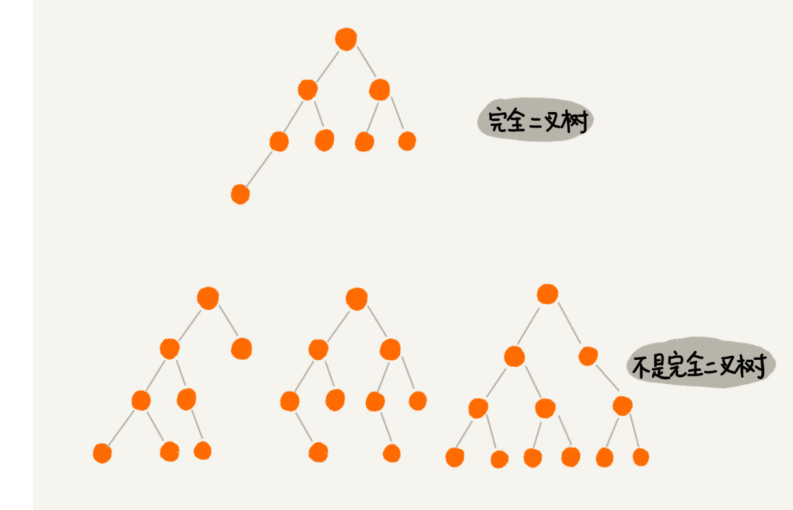
平衡二叉树的严格定义是这样的:二叉树中任意一个节点的左右子树的高度相差不能大于1。从这个定义来看,上一节我们讲的完全二叉树、满二叉树其实都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树。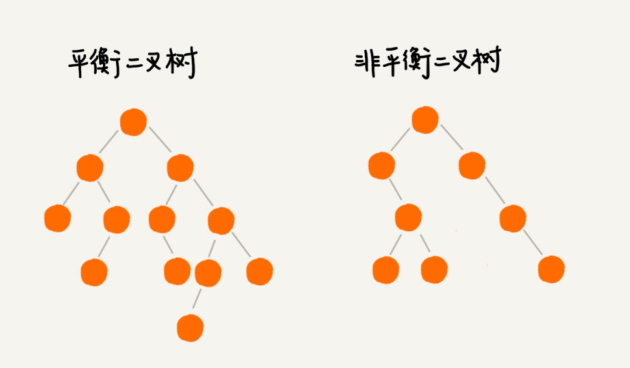
平衡二叉查找树不仅满足上面平衡二叉树的定义,还满足二叉查找树的特点。最先被发明的平衡二叉查找树是AVL 树,它严格符合我刚讲到的平衡二叉查找树的定义,即任何节点的左右子树高度相差不超过 1,是一种高度平衡的二叉查找树。
但是很多平衡二叉查找树其实并没有严格符合上面的定义(树中任意一个节点的左右子树的高度相差不能大于 1),比如我们下面要讲的红黑树,它从根节点到各个叶子节点的最长路径,有可能会比最短路径大一倍。
以,如果我们现在设计一个新的平衡二叉查找树,只要树的高度不比 log n 大很多(比如树的高度仍然是对数量级的),尽管它不符合我们前面讲的严格的平衡二叉查找树的定义,但我们仍然可以说,这是一个合格的平衡二叉查找树。
堆
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作“大顶堆”。
对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作“小顶堆”。
堆排序的过程大致分解成两个大的步骤,建堆和排序。
优先级队列,顾名思义,它首先应该是一个队列。我们前面讲过,队列最大的特性就是先进先出。不过,在优先级队列中,数据的出队顺序不是先进先出,而是按照优先级来,优先级最高的,最先出队。
如何实现一个优先级队列呢?方法有很多,但是用堆来实现是最直接、最高效的。这是因为,堆和优先级队列非常相似。一个堆就可以看作一个优先级队列。很多时候,它们只是概念上的区分而已。往优先级队列中插入一个元素,就相当于往堆中插入一个元素;从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
深度和广度优先搜索
广度优先搜索,通俗的理解就是,地毯式层层推进,从起始顶点开始,依次往外遍历。广度优先搜索需要借助队列来实现,遍历得到的路径就是,起始顶点到终止顶点的最短路径。深度优先搜索用的是回溯思想,非常适合用递归实现。
换种说法,深度优先搜索是借助栈来实现的。在执行效率方面,深度优先和广度优先搜索的时间复杂度都是O(E),空间复杂度是O(V)。
贪心算法
第一步,当我们看到这类问题的时候,首先要联想到贪心算法:
针对一组数据,我们定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。
第二步,我们尝试看下这个问题是否可以用贪心算法解决:
每次选择当前情况下,在对限制值同等贡献量的情况下,对期望值贡献最大的数据。
第三步,我们举几个例子看下贪心算法产生的结果是否是最优的。大部分情况下,举几个例子验证一下就可以了。严格地证明贪心算法的正确性,是非常复杂的,需要涉及比较多的数学推理。而且,从实践的角度来说,大部分能用贪心算法解决的问题,贪心算法的正确性都是显而易见的,也不需要严格的数学推导证明。
实际上,用贪心算法解决问题的思路,并不总能给出最优解。
从我个人的学习经验来讲,不要刻意去记忆贪心算法的原理,多练习才是最有效的学习方法
分治算法
分治算法是一种处理问题的思想,递归是一种编程技巧。
实际上,分治算法一般都比较适合用递归来实现。分治算法的递归实现中,每一层递归都会涉及这样三个操作:
- 分解:将原问题分解成一系列子问题;
- 解决:递归地求解各个子问题,若子问题足够小,则直接求解;
- 合并:将子问题的结果合并成原问题。
分治算法能解决的问题,一般需要满足下面这几个条件:
- 原问题与分解成的小问题具有相同的模式;
- 原问题分解成的子问题可以独立求解,子问题之间没有相关性,这一点是分治算法跟动态规划的明显区别,等我们讲到动态规划的时候,会详细对比这两种算法;
- 具有分解终止条件,也就是说,当问题足够小时,可以直接求解;
- 可以将子问题合并成原问题,而这个合并操作的复杂度不能太高,否则就起不到减小算法总体复杂度的效果了。
分治算法用四个字概括就是“分而治之”,将原问题划分成 n 个规模较小而结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。这个思想非常简单、好理解。
回溯算法
回溯算法本质上就是枚举,优点在于其类似于摸着石头过河的查找策略,且可以通过剪枝少走冤枉路。它可能适合应用于缺乏规律,或我们还不了解其规律的搜索场景中。

若有收获,就点个赞吧
0 人点赞
