1.1 背景介绍
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
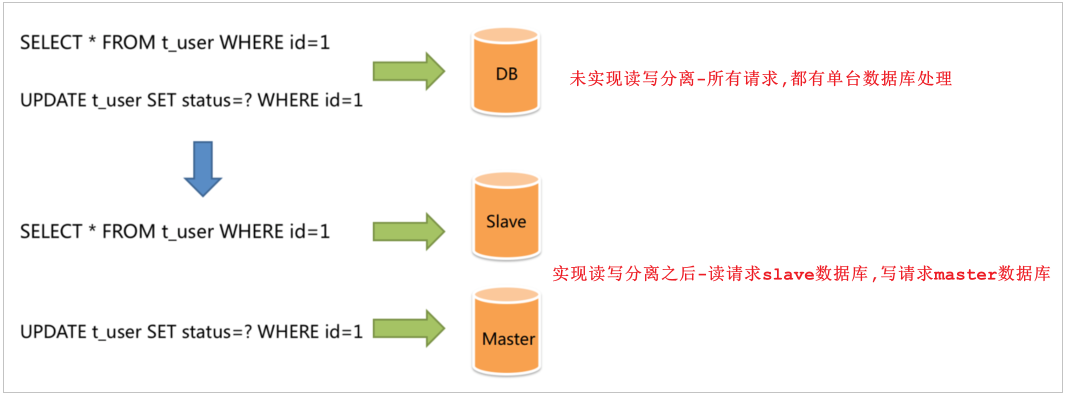
通过读写分离,就可以降低单台数据库的访问压力, 提高访问效率,也可以避免单机故障。
1.2 ShardingJDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
Sharding-JDBC具有以下几个特点:
1). 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2). 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3). 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
1.3配置
- 添加依赖:
2.在application.yml中增加数据源的配置: ```yaml spring: shardingsphere: datasource: names:<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency>
master,slave
主数据源
master:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.200.200:3306/rw?characterEncoding=utf-8username: rootpassword: root
从数据源
slave:
masterslave:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.200.201:3306/rw?characterEncoding=utf-8username: rootpassword: root
读写分离配置
load-balance-algorithm-type: round_robin #轮询最终的数据源名称
name: dataSource主库数据源名称
master-data-source-name: master从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave props: sql:show: true #开启SQL显示,默认false
3.在application.yml中增加配置```yamlspring:main:allow-bean-definition-overriding: true
该配置项的目的,就是如果当前项目中存在同名的bean,后定义的bean会覆盖先定义的。
==如果不配置该项,项目启动之后将会报错:== 
报错信息表明,在声明 org.apache.shardingsphere.shardingjdbc.spring.boot 包下的SpringBootConfiguration中的dataSource这个bean时出错, 原因是有一个同名的 dataSource 的bean在com.alibaba.druid.spring.boot.autoconfigure包下的DruidDataSourceAutoConfigure类加载时已经声明了。
而我们需要用到的是 shardingjdbc包下的dataSource,所以我们需要配置上述属性,让后加载的覆盖先加载的。
1.4测试
我们使用shardingjdbc来实现读写分离,直接通过上述简单的配置就可以了。配置完毕之后,我们就可以重启服务,通过postman来访问controller的方法,来完成用户信息的增删改查,我们可以通过debug及日志的方式来查看每一次执行增删改查操作,使用的是哪个数据源,连接的是哪个数据库。

若有收获,就点个赞吧
0 人点赞
