- 1.特殊符号
- 2.通配符
- 3.基础正则表达式
- 2]. $ 以 ….结尾的 行
- 3]. ^$ 空行 这一行中没有任何的符号
- 4]. 点 ) 任意一个字符 不包含空行
-o 表示 grep 的执行过程 正则每次匹配到了什么?
找出文件中以点结尾的行 - 5]. 撬棍 ) 转义符号 脱掉马甲,打回原形
\n 表示回车换行 - 6]. * 前一个字符连续出现了 0 次或 1 次以上 >=0
- 7]. .* 所有字符 所有符号 所有 (并且)
正则中表示连续出现 或 所有的时候 贪婪性 有多少匹配多少
练习:找出文件中以 m 开头的行并 且以 m 结尾的行 - 8]. [] 中括号 [abc] 相当于是一个字符 找出包含 a 或 b 或 c 的行
- 9]. [^] [^abc] 排除 a 或 b 或 c 的内容
- 4.扩展正则表达式
- 1]. 前一个符号连续出现了 1 次或多次
- 2]. | 或者
练习:取出’oldboy|linux’ - 3]. () 括号中的内容相当于是一个整体 后向引用(反向引用)
- 4]. o{n,m} 前一个字符连续出现了至少 n 次,最多 m 次。
o{n} 前一个字符连续出现了 n 次
o{n,} 前一个字符连续出现 了至少 n 次
o{,m} 前一个字符连续出现了最多 m 次 - 5]. ? 表示前一个字符连续出现 0 次或 1 次
- 5.正则表达式总结
1.特殊符号
‘’ 所见即所得,吃啥吐啥
“” 特殊符号会被解析运行
`` ==== $() 先运行里面的命令 把结果留下
重定向符号 先清空文件的内容 然后追加文件的最后<br />>> 追加重定向 追加文件的最后<br />2> 错误重定向 只有错误的信息 才会通过这个漏洞进入文件中<br />2>> 错误追加重定向
~ 当前用户的家目录
root ~ /root
oldboy ~ /home/oldboy
! 查找并运行历史命令
!awk 包含awk 的命令 最近的一条运行
history |grep awk
# 注释
root 用户的命令提示符
$ 取出变量的内容
awk $取某一列的内容
普通用户的命令提示符
* 所有 任何东西
\ 撬棍 转义字符
&& 前一个命令执行成功然后在执行后一个命令
ifdown eth0 && ifup eth0
|| 前一个命令支持失败了再执行后面的命令
[root@oldboyedu ~]# eco && echo ok # 第一个命令没找到,没有执行第二个命令。
-bash: eco: command not found
[root@oldboyedu ~]# eco || echo ok # 第一个命令没找到,执行第二个命令。
-bash: eco: command not found
ok
2.通配符
通配符是用来查找文件的。 以.txt 结尾的文件 .txt .log
2.1*:所有,任意
找出文件名包含oldboy 的文件
环境准备:
[root@oldboyedu ~]# mkdir -p /oldboy/
[root@oldboyedu ~]# cd /oldboy/
[root@oldboyedu oldboy]# touch oldboy.txt oldboy oldboyfile oldboy.awk eduoldboy
找出指定的文件:
[root@oldboyedu oldboy]# find /oldboy/ -type f -name "oldboy" # 找oldboy文件。
/oldboy/oldboy
[root@oldboyedu oldboy]# find /oldboy/ -type f -name "*oldboy" # 找以oldboy结尾的文件。
/oldboy/oldboy
/oldboy/eduoldboy
[root@oldboyedu oldboy]# find /oldboy/ -type f -name "*oldboy*" # 找含有oldboy的文件。
/oldboy/oldboy.awk
/oldboy/oldboyfile
/oldboy/oldboy
/oldboy/oldboy.txt
/oldboy/oldboy.txt-hard
/oldboy/eduoldboy
2.2 {}:生成序列
[root@oldboyedu oldboy]# echo {1..6}
1 2 3 4 5 6
[root@oldboyedu oldboy]# echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@oldboyedu oldboy]# echo {01..10}
01 02 03 04 05 06 07 08 09 10
[root@oldboyedu oldboy]# echo stu{01..10}
stu01 stu02 stu03 stu04 stu05 stu06 stu07 stu08 stu09 stu10
通过 {} 进行备份
[root@oldboyedu01-nb oldboy]# echo A{B,C}
AB AC
[root@oldboyedu01-nb oldboy]# echo A{,C}
A AC
[root@oldboyedu01-nb oldboy]# echo oldboy.txt{,.bak}
oldboy.txt oldboy.txt.bak
[root@oldboyedu01-nb oldboy]# touch oldboy.txt
[root@oldboyedu01-nb oldboy]# cp oldboy.txt{,.bak} # 把oldboy.txt 复制为oldboy.txt.bak
[root@oldboyedu01-nb oldboy]# ls l oldboy.txt*
-rw r r ----. 2 root root 29 Oct 18 07:42 oldboy.txt
-rw r r 1 root root 29 Oct 18 07:42 oldboy.txt.bak
-rw r r ----. 2 root root 29 Oct 18 07:42 oldboy.txt hard
lrwxrwxrwx 1 root root 10 Oct 17 09:27 oldboy.txt soft --> oldboy.txt
3.基础正则表达式
1) 什么是正则?为何使用它?
通过符号表示文字内容。提高效率,省事。
支持正则表达式 :Linux 三剑客 grep sed awk
练习:识别身份证号码
[root@oldboyedu oldboy]# cat id.txt # 环境准备。
110000197907030484
110ddd197902181654
110000198510204911
110000197908083836
11000019860ddd9605
110000199410252806
110000199003296713
110000197510314892
110000198209062811
110asdf98209062811
11000019820dddd811
110000198209062811
110000198307170496
110000198909149301
110000198810098735
110000199007021063
11000019781119429X
110000199103081090
110000198aa0300201
[root@oldboyedu oldboy]# egrep "^[0-9X]+$" id.txt # 过滤出身份证号码
110000197907030484
110000198510204911
110000197908083836
110000199410252806
110000199003296713
110000197510314892
110000198209062811
110000198209062811
110000198307170496
110000198909149301
110000198810098735
110000199007021063
11000019781119429X
110000199103081090
2) 使用正则的时候注意事项
#1] 正则表达式是按照行进行处理的
#2] 禁止使用中文符号
#3] 给 grep 和 egrep 配置别名
cat >>/etc/profile<<EOF # 给grap设置别名。
alias grep='grep --color=auto'
alias egrep='egrep --color=auto'
EOF
source /etc/profile # 使配置生效。
# 再次使用grep,egrep的时候,会将过滤出来的内容自动添加上颜色。
3) 正则表达式与通配符区别
用途 匹配的内容 支持的命令
通配符————用来匹配查找文件名 .txt .log 以 .txt .log 结尾的文件,大部分命令都可以使用
正则—————在文件中匹配查找内容 包含 oldboy 的行,Linux 三剑客:grep,sed,awk
4) 正则表达式分类
基础正则 ^ $ . * [] [^] basic regular expression BRE grep sed awk
扩展正则 | + {} () ? extended regular expression ERE grep -E/egrep sed -r awk
5) 准备环境
cat oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
6) 基础正则
#1]. ^ 以…. 开头的行
[root@oldboyedu oldboy]# grep '^m' oldboy.txt # 找出以m开头的行。
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
2]. $ 以 ….结尾的 行
[root@oldboyedu oldboy]# grep 'm$' oldboy.txt # 找出以m结尾的行。
my blog is http://oldboy.blog.51cto.com
3]. ^$ 空行 这一行中没有任何的符号
[root@oldboyedu oldboy]# grep '^$' oldboy.txt
排除文件中的空行
[root@oldboyedu oldboy]# grep -v '^$' oldboy.txt
4]. 点 ) 任意一个字符 不包含空行
-o 表示 grep 的执行过程 正则每次匹配到了什么?
找出文件中以点结尾的行
[root@oldboyedu oldboy]# grep '\.$' oldboy.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
5]. 撬棍 ) 转义符号 脱掉马甲,打回原形
\n 表示回车换行
6]. * 前一个字符连续出现了 0 次或 1 次以上 >=0
[root@oldboyedu oldboy]# grep '0*' oldboy.txt
am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
Linux正则表达式之问题 1:为何会取出 000 而不是 00 和 0 0 0 0?
因为正则在表示 连 续出现的时候表现出贪婪性,有多少吃多少,有多少匹配多少。
Linux正则表达式之问题 2:为何使用 ‘0‘ 会把整个文件的内容都显示出来?
#A表示
连续出现了 0 次 A ==== 什么也没有,就会把整个文件的内容都显示出来
A连续出现了 1 次以上 A
7]. .* 所有字符 所有符号 所有 (并且)
正则中表示连续出现 或 所有的时候 贪婪性 有多少匹配多少
练习:找出文件中以 m 开头的行并 且以 m 结尾的行
[root@oldboyedu oldboy]# grep '^m.*m$' oldboy.txt
my blog is http://oldboy.blog.51cto.com
8]. [] 中括号 [abc] 相当于是一个字符 找出包含 a 或 b 或 c 的行
[root@oldboyedu oldboy]# grep '[abc]' oldboy.txt
am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my god ,i am not oldbey,but OLDBOY!
[root@oldboyedu oldboy]# grep '[a-zA-Z0-9]' oldboy.txt
练习3: 以 m 或 n 或 o 开头的 并且以 m 或 g 结尾的行
[root@oldboyedu oldboy]# grep '^[mno].*[mg]$' oldboy.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
[root@oldboyedu oldboy]# grep '^[m,n,o].*[mg]$' oldboy.txt
# 逗号只表示逗号,多个逗号也只表示一个。
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
9]. [^] [^abc] 排除 a 或 b 或 c 的内容
[root@oldboyedu oldboy]# grep '[^abc]' oldboy.txt
# 基础正则小结
##1)) ^ $ ^$ . . []
##2)) grep grep -o
4.扩展正则表达式
扩展正则: + | () {} ?
1]. 前一个符号连续出现了 1 次或多次
[root@oldboyedu oldboy]# egrep '0' oldboy.txt
my qq num is 49000448.
not 4900000448.
[root@oldboyedu oldboy]# egrep '0+' oldboy.txt
my qq num is 49000448.
not 4900000448.
[root@oldboyedu oldboy]# egrep '0+' oldboy.txt -o
000
00000
[root@oldboyedu oldboy]# egrep '0' oldboy.txt -o
0
0
0
...
把文件中连续出现的小写字母取出来
[root@oldboyedu oldboy]# egrep '[a-z]+' oldboy.txt
am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
# 去除杂质
[root@oldboyedu oldboy]# egrep '[a-z]+' oldboy.txt -o
am
oldboy
teacher
teach
...
小结:
1. 可以把连续的东西通过正则取出来
2. 一般与 配合
2]. | 或者
练习:取出’oldboy|linux’
[root@oldboyedu oldboy]# egrep 'oldboy|linux' oldboy.txt
am oldboy teacher!
I teach linux.
my blog is http://oldboy.blog.51cto.com
[root@oldboyedu oldboy]# egrep 'oldboy|linux' oldboy.txt -o
oldboy
linux
oldboy
Linux 正则表达式之问题 3 ::[] 与 | 区别
都可以表示或者 [abc] a|b|c
区别:
1.[] 基础正则 扩展正则
2.[] 表示的是单个字符或者 单个字符的或多个字符的都可
[a z] oldboy|linux
3]. () 括号中的内容相当于是一个整体 后向引用(反向引用)
[root@oldboyedu oldboy]# egrep 'oldb(o|e)y' oldboy.txt
am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
先乘除再加减,有括号的先算括号里面的。
后向引用,反 向引用
sed ,把你想要的内容先保护起来(通过小括号),然后再使用他。
.*表示所有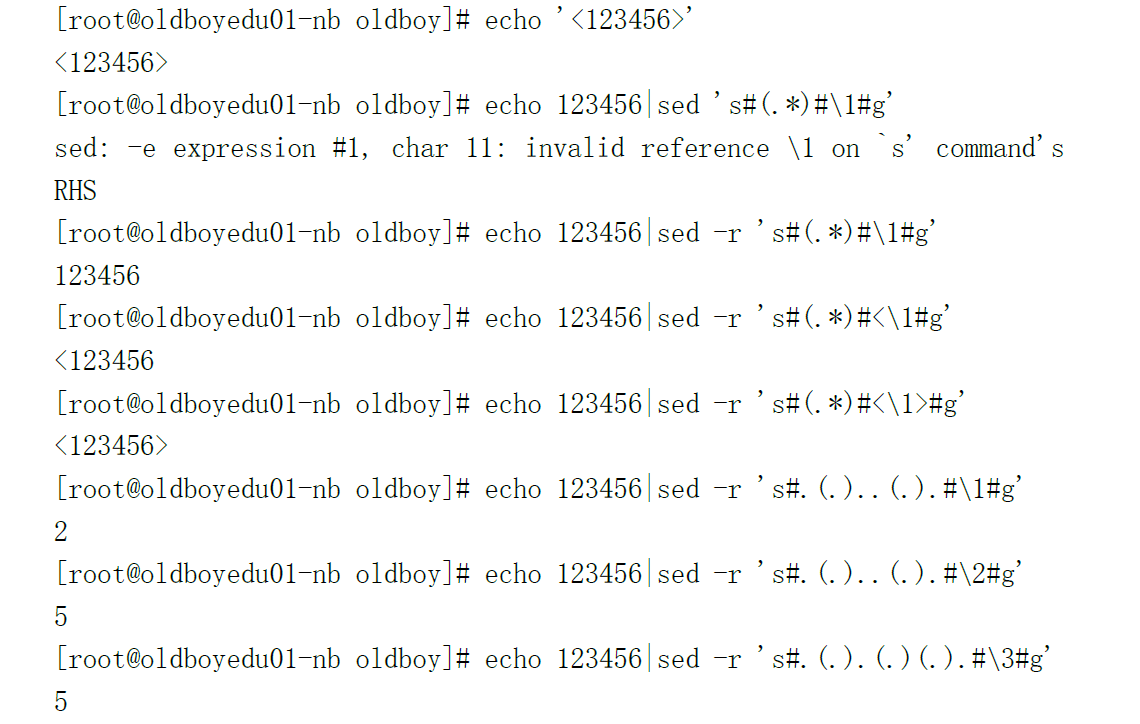
4]. o{n,m} 前一个字符连续出现了至少 n 次,最多 m 次。
o{n} 前一个字符连续出现了 n 次
o{n,} 前一个字符连续出现 了至少 n 次
o{,m} 前一个字符连续出现了最多 m 次
[root@oldboyedu oldboy]# egrep '0{1,4}' oldboy.txt
my qq num is 49000448.
not 4900000448.
[root@oldboyedu oldboy]# egrep '0{1,4}' oldboy.txt -o
000
0000
0
# 0数字出现3-4次
[root@oldboyedu oldboy]# egrep '0{3,4}' oldboy.txt
my qq num is 49000448.
not 4900000448.
[root@oldboyedu oldboy]# egrep '0{3,4}' oldboy.txt -o
000
0000
# 0-9数字出现8次以上
[root@oldboyedu oldboy]# egrep '[0-9]{8,}' oldboy.txt
my qq num is 49000448.
not 4900000448.
[root@oldboyedu oldboy]# egrep '[0-9]{8,}' oldboy.txt -o
49000448
4900000448
5]. ? 表示前一个字符连续出现 0 次或 1 次
[root@oldboyedu oldboy]# egrep 'ol?d' oldboy.txt
am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@oldboyedu oldboy]# egrep 'ol?d' oldboy.txt -o
old
old
od
old
5.正则表达式总结
连续出现、重复
=0
+ >=1
? 0 1
{n,m} >=n <=m
{n} ==n
其他
. 任意一个字符
[abc] 一个整体 相当于是一个字符
[a z] [0 9] [A Z]
[^abc] 排除
| 或者
() 后向引用 反向引用 先保护再使用
.* 所有
^$ 空行
- 基础正则与扩展正则区别
支持基础正则 基础 + 扩展
grep egrep === grep -E
sed sed -r
awk awk

若有收获,就点个赞吧
0 人点赞
