架构与历史
mysql逻辑架构
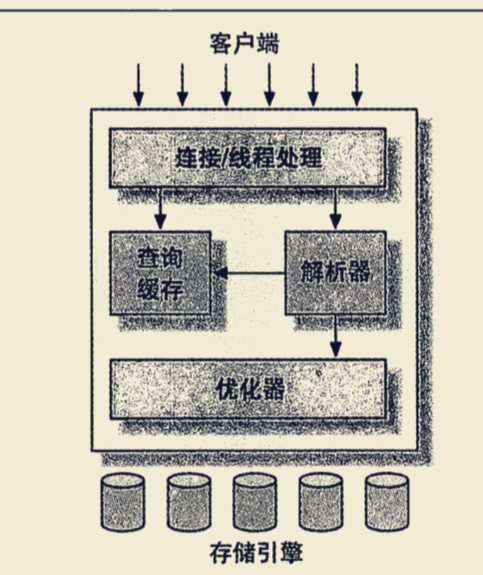
分层解析:
最上层的服务并不是 MySQL所独有的,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。比如连接处理、授权认证、安全等等。
第二层架构是 MySQL比较有意思的部分。大多数 MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等
第三层包含了存储引擎。存储引擎负责 MySQL中数据的存储和提取。和GNU/Liux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含几十个底层函数,用于执行诸如“开始一个事务”或者“根据主键提取一行记录”等操作。但存储引擎不会去解析SQL(InnoDB是一个例外,它会解析外键定义,因为 MySQL服务器本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
链接管理与安全性
每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个单独的线程中执行,该线程只能轮流在某个CPU核心或者CPU中运行。服务器会负责缓存线程,因此不需要为每一个新建的连接创建或者销毁线程。
MySQL55或者更新的版本提供了一个API,支持线程池( Thread- Pooling)插件,可以使用池中少量的线程来服务大量的连接。
优化与执行
MySQL会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询、决定表的读取顺序,以及选择合适的索引等。
用户可以通过特殊的关键字提示(hint)优化器,影响它的决策过程。也可以请求优化器解释( explain)优化过程的各个因素,使用户可以知道服务器是如何进行优化决策的,并提供一个参考基准,便于用户重构査询和 schema、修改相关配置,使应用尽可能高效运行。
优化器并不关心表使用的是什么存储引擎,但存储引擎对于优化査询是有影响的。优化器会请求存储引擎提供容量或某个具体操作的开销信息,以及表数据的统计信息等。例如,某些存储引擎的某种索引,可能对一些特定的查询有优化。
对于 SELECT语句,在解析査询之前,服务器会先检查查询缓存( Query Cache),如果能够在其中找到对应的查询,服务器就不必再执行查询解析、优化和执行的整个过程,而是直接返回查询缓存中的结果集。
并发控制
无论何时,只要有多个查询需要在同一时刻修改数据,都会产生并发控制的问题。
讨论 MySQL在两个层面的并发控制:服务器层与存储引擎层。
读写锁
共享锁( shared lock)和排他锁( exclusive lock),也叫读锁( read lock)和写锁( write lock)
读锁是共享的,或者说是相互不阻塞的。多个客户在同一时刻可以同时读取同一个资源,而互不干扰。但不允许其他事物修改数据。
写锁则是排他的,也就是说一个写锁会阻塞其他的写锁和读锁,这是出于安全策略的考虑,只有这样,才能确保在给定的时间里,只有一个用户能执行写入,并防止其他用户读取正在写入的同资源。
锁粒度
一种提高共享资源并发性的方式就是让锁定对象更有选择性。尽量只锁定需要修改的部分数据,而不是所有的资源。更理想的方式是,只对会修改的数据片进行精确的锁定。任何时候,在给定的资源上,锁定的数据量越少,则系统的并发程度越高,只要相互之间不发生冲突即可。
问题是加锁也需要消耗资源。锁的各种操作,包括获得锁、检査锁是否已经解除、释放锁等,都会增加系统的开销。
所谓的锁策略,就是在锁的开销和数据的安全性之间寻求平衡,这种平衡当然也会影响到性能。
表锁
表锁是 MySQL中最基本的锁策略,并且是开销最小的策略。表锁非常类似于前文描述的邮箱加锁机制:它会锁定整张表。一个用户在对表进行写操作(插入、删除、更新等)前,需要先获得写锁,这会阻塞其他用户对该表的所有读写操作。只有没有写锁时,其他读取的用户才能获得读锁,读锁之间是不相互阻塞的。
写锁也比读锁有更高的优先级,因此一个写锁请求可能会被插入到读锁队列的前面(写锁可以插入到锁队列中读锁的前面,反之读锁则不能插入到写锁的前面)
服务器会为诸如 ALTER TABLE之类的语句使用表锁,而忽略存储引擎的锁机制。
InnoDB和MYISAM支持表锁。服务器层面也支持表锁。
**
行锁
行级锁可以最大程度地支持并发处理(同时也带来了最大的锁开销)。
InnoDB支持行锁,MYISAM不支持行锁,服务器层面也不支持行锁,行级锁只在存储引擎层实现。服务器层完全不了解存储引擎的锁实现。
事物
事务就是一组原子性的SQL査询,或者说一个独立的工作单元。
也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。
事物特性:ACID > 原子性(atomIcity)、一致性( consistency)、隔离性( isolation)和持久性( durability)。
(具体概念不多做介绍)
事务处理过程中额外的安全性,也会需要数据库系统做更多的额外工作。如果有的业务不需要事物,可以选择非事务型的存储引擎(例如:MYISAM存储引擎),可以获得更高的性能。
隔离级别
较低级别的隔离通常可以执行更高的并发,系统的开销也更低。 每种存储引擎实现的隔离级别不尽相同。
四种隔离级别:READ UNC0 MMITTED(RM)(未提交读)、READ COMMITTED(RC)(提交读)、REPEATABLE READ(RR)(可重复读)、SERIALIZABLE(可串行化)。
不同的隔离级别解决的问题:
死锁
死锁是指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就可能会产生死锁。
多个事务同时锁定同一个资源时,也会产生死锁。
例如: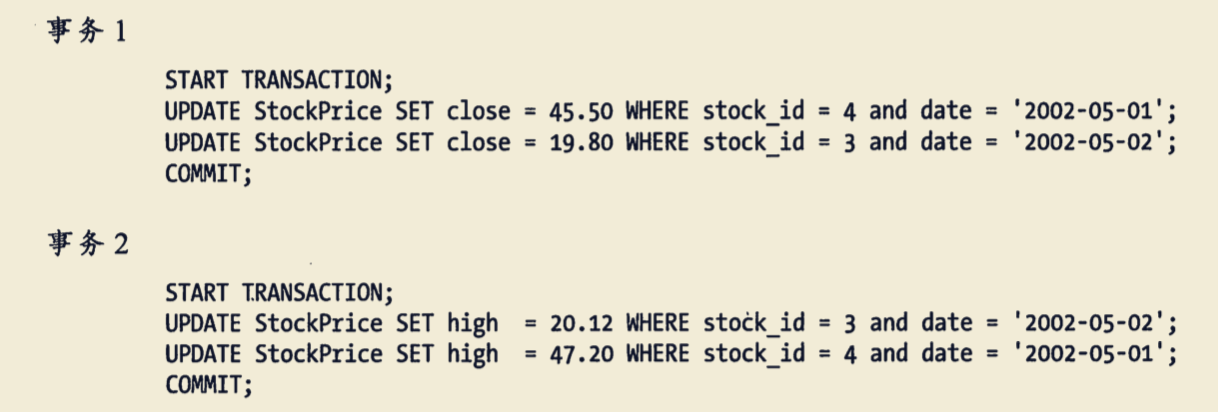
如果凑巧,两个事务都执行了第一条 UPDATE语句,更新了一行数据,同时也锁定了该行数据,接着每个事务都尝试去执行第二条 UPDATE语句,却发现该行已经被对方锁定,然后两个事务都等待对方释放锁,同时又持有对方需要的锁,则陷入死循环。除非有外部因素介入才可能解除死锁。
数据库系统实现了各种死锁检测和死锁超时机制。
InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚(这是相对比较简单的死锁回滚算法)
锁的行为和顺序是和存储引擎相关的。
死锁的产生有双重原因:有些是因为真正的数据冲突,这种情况通常很难避免。但有些则完全是由于存储引擎的实现方式导致的。
事务日志
事务日志可以帮助提高事务的效率。
innodb事务日志包括redo log和undo log。redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作。
redo log是InnoDB存储引擎层的日志,又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。 undo log记录的是修改前的数据,可提供回滚操作。还提供了MVCC。
(具体可自查资料)
mysql中的事务
Mysql中我们最常用的事务型存储引擎:InnoDB。(MYISAM不支持事务)
有一些命令,在执行之前会强制执行C0MMIT提交当前的活动事务。典型的例子在数据定义语言(DDL)中,如果是会导致大量数据改变的操作,比如 ALTER TABLE,就是如此。另外还有LOCK TABLES等其他语句也会导致同样的结果。
在事务中混合使用存储引擎
MySQL服务器层不管理事务,事务是由下层的存储引擎实现的。
在同一个事务中使用多种存储引擎是不可靠的。
如果该事务需要回滚,非事务型的表上的变更就无法撤销,这会导致数据库处于不致的状态,这种情况很难修复,事务的最终结果将无法确定。
隐式和显式锁定
InnoDB采用的是两阶段锁定协议( two-phase locking protocol)。
隐式锁定:在事务执行过程中,随时都可以执行锁定,锁只有在执行COMMIT或者ROLLBACK的时候才会释放,并且所有的锁是在同一时刻被释放。
显式锁定:通过特定的语句进行加锁。(例如:SELECT ….. LOCK IN SHARE MODE; SELECT…. FOR UPDATE,者不属于SQL的规范,应尽量避免使用)。
MySQL也支持L0 CK TABLES和UNL0 CK TABLES语句,这是在服务器层实现的,和存储引擎无关。在使用MYISAM存储引擎时可能会用到,但是在InnoDB存储引擎下使用会影响性能。他们有用途,但不能替代事务处理,还是应该选择事务型存储引擎。
多版本并发控制 (MVCC)
MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制( MVCC)。
可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。
MVCC的实现,是通过保存数据在某个时间点的快照来实现的。也就是说,不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
InnodB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的(具体实现可自查,这里不做多介绍)。
MVCC只在 REPEATABLE READ (可重复读)和 READ COMMTED(读已提交)两个隔离级别下工作。其他两个隔离级别都和MCC不兼容,因为 READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而 SERIALIZABLE则会对所有读取的行都加锁。
主要作用:在快照读的情况下解决幻读的问题。而当前读的情况下,使用的是行锁+间隙锁解决了幻读。
快照读读取的是Undo Log日志。当前读读取的是实时数据(数据库)。
MYSQL的存储引擎
InnoDB存储引擎
是 MySQL的默认事务型引擎,也是最重要、使用最广泛的存储引擎。
InnodB采用MVCC来支持高并发,并且实现了四个标准的隔离级别。其默认级别是REPEATABLE READ(可重复读),并且通过间隙锁(next- key locking)策略防止幻读的出现。间隙锁使得 InnoDe不仅仅锁定査询涉及的行,还会对索引中的间隙进行锁定,以防止幻影行的插入。
快照度采用MVCC解决幻读。当前读采用行锁+间隙锁解决幻读
InnoDB表是基于聚簇索引建立的。(MYISAM是基于稀疏索引建立的)
聚簇索引对主键查询有很高的性能。不过它的二级索引( secondary index,非主键索引)中必须包含主键列,所以如果主键列很大的话,其他的所有索引都会很大。
MYISAM存储引擎
MySQL51及之前的版本, MyISAM是默认的存储引擎。不支持事务和行锁。崩溃后无法恢复 。
特性:
- 加锁与并发:对整张表加锁。读到的所有表加共享锁,写入时加排他锁。在表有读取查询的同时 ,也可以往表中插入新数据(被称为并发插入)。
- 修复:可以手工或者自动执行检查和修复操作。执行表的修复可能导致一些数据丢失,而且修复操作是非常慢的。可以通过 CHECK TABLE mytable检查表的错误,如果有错误可以通过执行 REPAIR TABLE mytable进行修复。
- 索引特性:MyIsAM也支持全文索引,这是一种基于分词创建的索引。
MYISAM压缩表
如果表在创建并导入数据以后,不会再进行修改操作,那么这样的表或许适合采用MyISAM压缩表。(常量表和日志表)
可以使用 myisampack对 MyIsAM表进行压缩(也叫打包pack)。压缩表不能进行直接修改(可解压后修改,再次压缩)。压缩表可以极大地减少磁盘
空间占用,因此也可以减少磁盘I/O,从而提升查询性能。压缩表也支持索引,但索引也是只读的。
以现在的硬件能力,对大多数应用场景,读取压缩表数据时的解压带来的开销影响并不大,而减少I/O带来的好处则要大得多。压缩时表中的记录是独立压缩的,所以读取单行的时候不需要去解压整个表(甚至也不解压行所在的整个页面)。
MYISAM性能
MyISAM引擎设计简单,数据以紧密格式存储,所以在某些场景下的性能很好。MyISAM有一些服务器级别的性能扩展限制,比如对索引键缓冲区( key cache)的Mutex锁, MariaDB基于段( segment)的索引键缓冲区机制来避免该问题。但 MyISAM最典型的性能问题还是表锁的问题,如果你发现所有的查询都长期处于“ Locked”状态,那么毫无疑问表锁就是罪魁祸首。
选择合适引擎
大部分情况下, InnoDB都是正确的选择。
除非需要用到某些 InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择 InnoDB引擎。
如果要用到全文索引,建议优先考虑 InnoDB加上 Sphinx的组合,而不是使用支持全文索引的 MyISAM。
除非万不得已,否则建议不要混合使用多种存储引擎,否则可能带来一系列复杂的问题,以及一些潜在的bug和边界问题。
如果应用需要不同的存储引擎,请先考虑以下几个因素:
事务
如需事务,InnoDB是最好的选择。如不需事务,并且主要是 SELECT和 INSERT操作,可选择MYISAM。
备份
如可定期关闭服务器进行数据备份,因素可忽略。如需要在线热备份,InnoDB是最好选择。
崩溃恢复
MyISAM崩溃后发生损坏的概率比 InnoDB要高很多,而且恢复速度也要慢。考虑事务,最好选择InnoDB。
如果搞不清楚使用哪个存储引擎,InnoDB是最好的选择。
大数据量
什么样的数据量算大?我们创建或者管理的很多 InnoDe数据库的数据量在3~5TB之间,或者更大,这是单台机器上的量,不是一个分片( shard)的量。
在这样的数据量下,如果釆用 MyISAM,崩溃后的恢复就是一个噩梦。
如果数据量继续增长到10TB以上的级别,可能就需要建立数据仓库。 Infobright是MySQL数据仓库最成功的解决方案。也有一些大数据库不适合 Infobright,却可能适合TokuDA。
转换表的引擎
有很多种方法可以将表的存储引擎转换成另外一种引擎。每种方法都有其优点和缺点。
- ALTER TABLE

适合任何存储引擎。问题是执行时间长。
将数据从原表复制到一张新的表中,在复制期间可能会消耗系统所有的I/O能力,同时原表上会加上读锁。所以,在繁忙的表上执行此操作要特别小心。(可手工进行表的复制)
如果转换表的存储引擎,将会失去和原引擎相关的所有特性。
导出和导入
可使用工具将数据导出到文件,然后修改语句中的存储引擎设置,再次导入数据,注意修改表名,表名不能重复。更要注意语句中的DROP TABLE语句,不然可能会将造成数据丢失。
创建和查询
综合了第一种方法的高效和第二种方法的安全。
先创建一个新的存储引擎的表,然后利用 INSERT… SELECT语法来导数据。
数据量不大的话,这样做工作得很好。如果数据量很大,则可以考虑做分批处理,针对每一段数据执行事务提交操作,以避免大事务产生过多的undo。
pt- online- schema- change的工具可以比较简单、方便地执行上述过程,避免手工操作可能导致的失误和烦琐。
MYSQL基准测试
基准测试( benchmark)是 MySQL新手和专家都需要掌握的一项基本技能。简单地说,基准测试是针对系统设计的一种压力测试。通常的目标是为了掌握系统的行为。但也有其他原因,如重现某个系统状态,或者是做新硬件的可靠性测试。本章将讨论MySQL和基于 MySQL的应用的基准测试的重要性、策略和工具。sysbench是一款非常优秀的 MySQL基准测试工具。
为什么需要基准测试
基准测试是唯一方便有效的、可以学习系统在给定的工作负载下会发生什么的方法。
基准测试可以在系统实际负载之外创造一些虚构场景进行测试。
(具体:https://gitee.com/meader/sharefiles/raw/master/uPic/0IIKUO.png | https://gitee.com/meader/sharefiles/raw/master/uPic/izcD79.png)
基准测试的一个主要问题在于其不是真实压力的测试。(https://gitee.com/meader/sharefiles/raw/master/uPic/AoDNhl.png | https://gitee.com/meader/sharefiles/raw/master/uPic/qX9fZJ.png | https://gitee.com/meader/sharefiles/raw/master/uPic/DkfUwE.png)
基准测试的策略
- 针对整个系统的整体测试
- 单独测试 MySQL
这两种策略也被称为集成式(fu- -stack)以及单组件式( single- component)基准测试。
https://gitee.com/meader/sharefiles/raw/master/uPic/8OHy6K.png
https://gitee.com/meader/sharefiles/raw/master/uPic/S1Aj1N.png
(基准测试看的晕乎乎,先忽略)
服务器性能剖析
最常碰到的三个性能相关的服务请求是:如何确认服务器是否达到了性能最佳的状态、找出某条语句为什么执行不够快,以及诊断被用户描述成“停顿”、“堆积”或者“卡死”的某些间歇性疑难故障。
性能优化简介
我们将性能定义为完成某件任务所需要的时间度量,换句话说,性能即响应时间,这是一个非常重要的原则。 通过任务和时间来衡量性能。
数据库服务器的目的是执行SQL语句,所以它关注的任务是查询或者语句。数据库服务器的性能用查询的响应时间来度量,单位是每个查询花费的时间。
性能优化并不是降低CPU的利用率,有时候优化后CPU的利用率反而上升了,对资源的利用率上升了,查询的相应时间能够体现优化后新歌能是不是变得更好。所有CPU的利用率上升不一定是坏事,但也有时候也是坏事,比如某个查询索引失效,导致CPU上升,这是有问题的。
提高每秒的查询量是对吞吐量的优化。
如果目标是降低响应时间,就需要理解服务器执行查询为什么会需要这么多时间,然后去减少或者消除那些对获得查询结果来说不必要的工作。(搞清楚时间花在了哪里)
性能优化原则
- 完成某件任务所需要的时间度量
- 无法测量就无法有效地优化
合适的测量范围是说只测量需要优化的活动。有两种比较常见的情况会导致不合适的测量:
- 在错误的时间启动和停止测量。
- 测量的是聚合后的信息,而不是目标活动本身
完成一项任务所需要的时间可以分成两部分:执行时间和等待时间。
优化执行时间:最好的办法是通过测量定位不同的子任务花费的时间,然后优化去掉一些子任务、降低子任务的执行频率或者提升子任务的效率。
优化等待时间:而优化任务的等待时间则相对要复杂一些,因为等待有可能是由其他系统间接影响导致,任务之间也可能由于争用磁盘或者CPU资源而相互影响。
如何判断测量是正确的:https://gitee.com/meader/sharefiles/raw/master/uPic/HqXcqd.png
通过性能剖析进行优化
性能剖析一般有两个步骤:
- 测量任务所花费的时间;
- 然后对结果进行统计和排序,将重要的任务排到前面。
在任务开始时启动计时器,在任务结束时停止计时器,然后用结束时间减去启动时间得到响应时间。
基于执行时间的分析是什么任务执行的时间最长。
基于等到时间的分析是判断任务是在什么地方被阻塞时间最长。
理解性能剖析
性能剖析确实的重要信息
值得优化的查询
1> 一些只占总响应时间比重很小的查询不值得优化。
2> 优化成本大于收益的查询不值得优化。异常情况
执行次数很少,但执行慢,占用总的响应时间比重不明显的查询需要优化
丢失的时间
剖析工具可能会丢失时间。总的执行时间与实际执行时间有差,就是存在时间丢失,丢失的是什么时间不得而知。只是测量工具的问题。
更重要的缺失
无法在更高层次的堆栈中进行交互式的分析。
对应用程序进行性能剖析
应用程序导致性能瓶颈可能的因素:
- 外部资源。比如调用外部的WEB服务或者搜索引擎
- 应用处理大量的数据。比如一个超大的XML文件
- 在循环中执行昂贵的操作。比如滥用正则表达式
- 使用抵消的算法。比如使用暴力搜索算法。
MYSQL的问题没有那么复杂,一款应用程序的剖析工具即可。
性能剖析本身会导致服务器变慢吗?
要看性能剖析带来的回报有多大。如果带来的回报为5,而服务器的损失为10,则会带来麻烦。反之则是有好处的。
如果性能剖析能够为带来10%的性能优化,就是值得的。
剖析MYSQL查询
对查询进行剖析有两种方式
- 剖析服务器负载
- 剖析单条查询
剖析服务器负载
服务器端的剖析很有价值,因为在服务器端可以有效地审计效率低下的查询。
降低服务器的负载也可以推迟或者避免升级更昂贵硬件的需求。
捕获 My SQL的查询到日志文件中
在 MySQL的当前版本中,慢査询日志是开销最低、精度最高的测量查询时间的工具。如果还在担心开启慢查询日志会带来额外的IO开销,那大可以放心。我们在IO密集型场景做过基准测试,慢查询日志带来的开销可以忽略不计(实际上在CPU密集型场景的影响还稍微大一些)。更需要担心的是日志可能消耗大量的磁盘空间。如果长期开启慢查询日志,注意要部署日志轮转( log rotation)工具。或者不要长期启用慢査询日志,只在需要收集负载样本的期间开启即可。
分析查询日志
不要直接打开整个慢查询日志进行分析,这样做只会浪费时间和金钱。首先应该生成个剖析报告,如果需要,则可以再查看日志中需要特别关注的部分。自顶向下是比较好的方式,否则有可能像前面提到的,反而导致业务的逆优化。
建议使用pt- query- digest分析 MySQL查询日志。
强烈建议大家从现在起就利用慢查询日志捕获服务器上的所有查询,并且进行分析
不要直接打开整个慢查询日志进行分析,这样做只会浪费时间和金钱。首先应该生成个剖析报告,如果需要,则可以再查看日志中需要特别关注的部分。自顶向下是比较好的方式,否则有可能像前面提到的,反而导致业务的逆优化。
剖析单条查询
在定位到需要优化的单条查询后,可以针对此查询“钻取”更多的信息,确认为什么会花费这么长的时间执行,以及需要如何去优化。
使用 show profiles;
查询剖析工具,默认是关闭的,可通过 set profiling = 1; 命令开启。
执行 show profile for query 1; 1为query_id,查看每个步骤花费的时间: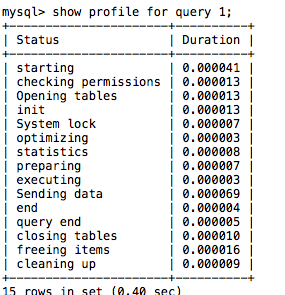
发送数据很难优化节省多少数据。
使用show status;
返回一些计数器,可以显示某些活动如读索引的频繁程度。
SHOW STATUS本身也会创建一个临时表
使用性能剖析
https://gitee.com/meader/sharefiles/raw/master/uPic/xwSnUr.png
https://gitee.com/meader/sharefiles/raw/master/uPic/rBCSyv.png
诊断间歇性问题
尽量不要使用试错的方式来解决问题。这种方式有很大的风险,因为结果可能变得更坏。
列举了我们认为已经解决的一些间歇性数据库性能问题的实际案例:
https://gitee.com/meader/sharefiles/raw/master/uPic/g0dTpM.png
有些问题确实是数据库的原因,也有些不是
单条查询问题还是服务器问题
如何判断是单条查询问题还是服务器问题呢?
- 使用 SHOW GLOBAL STATUS
https://gitee.com/meader/sharefiles/raw/master/uPic/1hse9G.png
https://gitee.com/meader/sharefiles/raw/master/uPic/iJqOfY.png
- 使用 SHOW PROCESSLIST
https://gitee.com/meader/sharefiles/raw/master/uPic/IFDe2w.png
https://gitee.com/meader/sharefiles/raw/master/uPic/tJX4bs.png
https://gitee.com/meader/sharefiles/raw/master/uPic/Usv5Sg.png
使用 SHOW PROCESSLIST命令时,在尾部加上\G可以垂直的方式输出结果https://gitee.com/meader/sharefiles/raw/master/uPic/iMVUQD.png
https://gitee.com/meader/sharefiles/raw/master/uPic/6NWSGO.png
- 使用日志查询
如果要通过查询日志发现问题,需要开启慢查询日志并在全局级别设置Long_ querytime为0,并且要确认所有的连接都采用了新的设置。这可能需要重置所有连接以使新的全局设置生效;如果因为某些原因,不能设置慢查询日志记录所有的查询,也可以通过 tcpdump和ptquery- digest工具来模拟替代。要注意找到吞吐量突然下降时间段的日志。查询是在完成阶段才写入到慢査询日志的,所以堆积会造成大量查询处于完成阶段,直到阻塞其他查询的资源占用者释放资源后,其他的查询才能执行完成。这种行为特征的一个好处是,当遇到吞吐量突然下降时,可以归咎于吞吐量下降后完成的第一个查询(有时候也不一定是第一个査询。当某些査询被阻塞时,其他查询可以不受影响继续运行,所以不能完全依赖这个经验)。
https://gitee.com/meader/sharefiles/raw/master/uPic/zCDuSy.png
https://gitee.com/meader/sharefiles/raw/master/uPic/T2CAXx.png
- 理解发现的问题
可视化的数据最具有说服力。
我们建议诊断问题时先使用前两种方法: SHOW STATUS和 SHOW PROCESSLIST。
捕获诊断数据
在开始之前,需要搞清楚两件事
- 一个可靠且实时的“触发器”,也就是能区分什么时候问题出现的方法。
- 一个收集诊断数据的工具。
诊断触发器
在问题出现时能够捕获数据的基础。
https://gitee.com/meader/sharefiles/raw/master/uPic/xZBbNC.png
其他剖析工具
- 使用 USER STATIST|CS表
https://gitee.com/meader/sharefiles/raw/master/uPic/20210703-182800-0120.png
https://gitee.com/meader/sharefiles/raw/master/uPic/20210703-181901-0125.png
- 使用 strace
https://gitee.com/meader/sharefiles/raw/master/uPic/20210703-180302-0636.png
https://gitee.com/meader/sharefiles/raw/master/uPic/20210703-183802-0250.png
总结
知识点:
- 我们认为定义性能最有效的方法是响应时间。
- 如果无法测量就无法有效地优化,所以性能优化工作需要基于高质量、全方位及完整的响应时间测量
- 测量的最佳开始点是应用程序,而不是数据库。即使问题出在底层的数据库,借助良好的测量也可以很容易地发现问题
- 大多数系统无法完整地测量,测量有时候也会有错误的结果。但也可以想办法绕过些限制,并得到好的结果(但是要能意识到所使用的方法的缺陷和不确定性在哪里)
- 完整的测量会产生大量需要分析的数据,所以需要用到剖析器。这是最佳的工具,可以帮助将重要的问题冒泡到前面,这样就可以决定从哪里开始分析会比较好。
- ·剖析报告是一种汇总信息,掩盖和丢弃了太多细节。而且它不会告诉你缺少了什么,所以完全依赖剖析报告也是不明智的
- 有两种消耗时间的操作:工作或者等待。大多数剖析器只能测量因为工作而消耗的时间,所以等待分析有时候是很有用的补充,尤其是当CPU利用率很低但工作却直无法完成的时候。
- 优化和提升是两回事。当继续提升的成本超过收益的时候,应当停止优化
- 注意你的直觉,但应该只根据直觉来指导解决问题的思路,而不是用于确定系统的问题。决策应当尽量基于数据而不是感觉
https://gitee.com/meader/sharefiles/raw/master/uPic/20210703-181109-0533.png
https://gitee.com/meader/sharefiles/raw/master/uPic/20210703-180810-0537.png

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}