一 知识体系
在这一章我们将使用基础的Python库pandas,numpy,matplotlib来完成一个数据分析的小项目,推荐使用Anaconda环境下的jupter-notebook来进行练习。
二 背景介绍
这是一组航空公司用户的数据,我们希望能够从这些数据中分析出有价值的信息,数据如下。
chapter2-1.zip
三 分析方法
有关于对用户的分析,比较广泛的分析方法是使用RFM模型,其中R代表recently最近消费时间间隔,F代表frequency消费频率,M代码money消费金额。考虑到我们这个项目,如果购买了长度的打折机票和一个购买了短途的高等仓位机票的用户,虽然他们的消费金额是一样的,但是显然购买高等仓位机票的用户更有价值。于是,我们用M-mileage飞行里程和C-coefficient折扣系数来替换消费金额,并且增了L-long关系时长这样一个参数,关系时长代表入会时间。由此,我们把RFM模型修改成LRFMC模型。
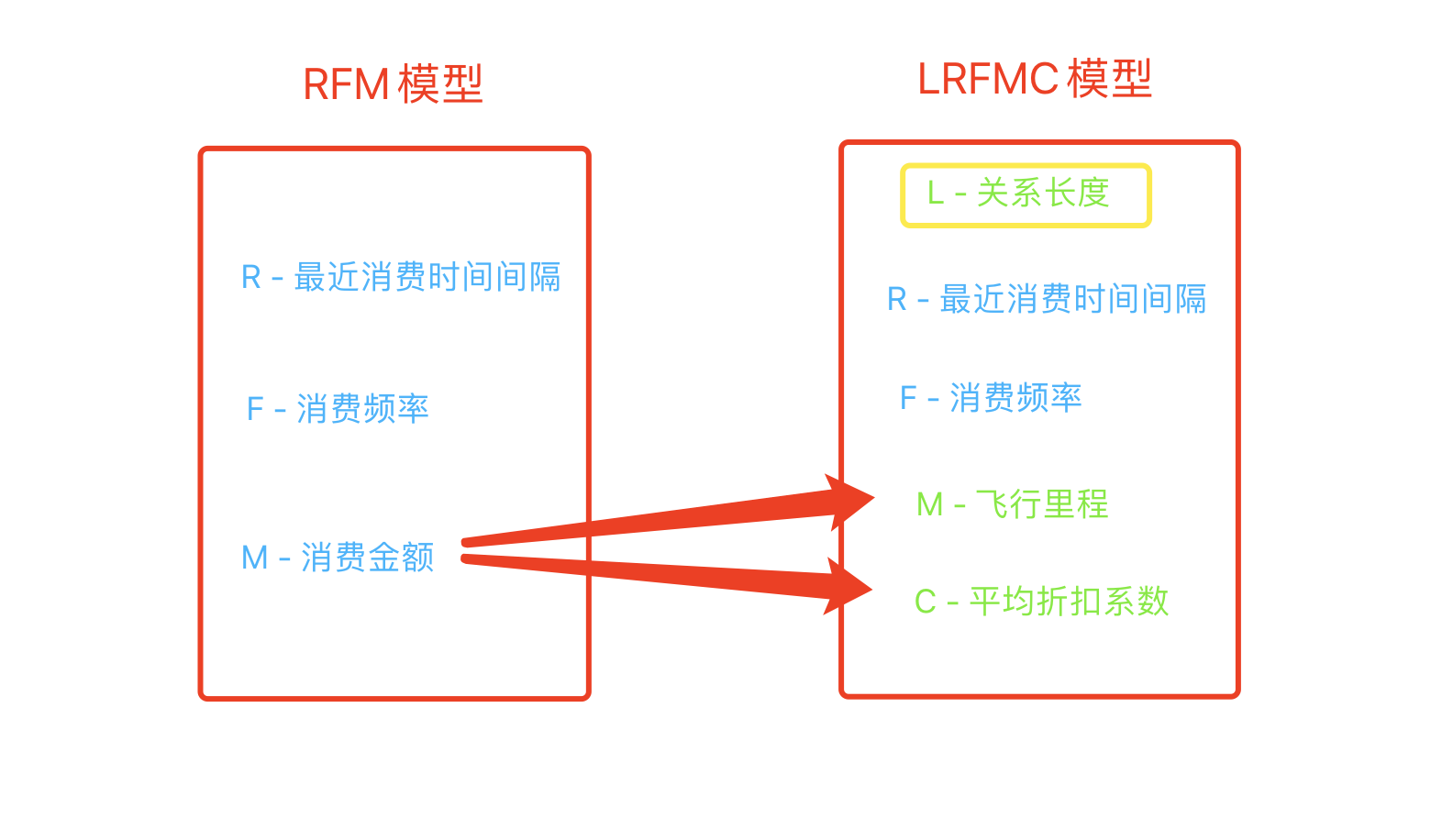
四 分析流程
回顾一下分析的流程,主要分为以下五步:
- 数据源 - 从业务系统中得到
- 数据抽取 - 抽取历史数据
- 数据探索 - 探索数据中的缺失值,异常值
- 数据预处理 - 清洗转换数据
- 数据建模 - 建立机器学习模型
- 结果反馈 - 给出策略
接下来我们要做的就是数据探索了
五 探索性分析
我们可以使用以下代码很容易找到数据中的缺失值,最大值和最小值
import pandas as pd# 1 定义文件名称datafile = 'air_data.csv' # 初始文件resultfile = 'explore.csv' # 目标文件# 2 读取文件信息data = pd.read_csv(datafile, encoding='utf-8') # 使用pd.read_csv来读取csv文件# 3 呈现文件内容explore = data.describe().T # 获取描述信息后在进行据阵转置# 4 计算空白数量explore['null'] = len(data) - explore['count']# 5 构造问题矩阵explore = explore[['null', 'max', 'min']] # 通过这个矩阵来初步观察问题# 6 修改矩阵名称explore.columns = ['空值数量', '最大值', '最小值']# 7 保存探索文件explore.to_csv(resultfile)
六 数据预处理
数据预处理主要采用数据清洗和数据变换的方法,这是构造模型的必要条件,数据清洗的原则必须是根据业务场景而定,根据业务场景,我们制定出如下规则:保留票价非零数据,或平局折扣率不为零且总飞行里程大于零的数据,然后清洗数据,具体代码如下
import numpy as npimport pandas as pd# 1 读取原始数据datafile = 'air_data.csv'cleanedfile = 'data_cleaned.csv'data = pd.read_csv(datafile)print("原始数据的形状", data.shape)# 2 删除缺失数据airline_notnull = data.loc[data['SUM_YR_1'].notnull() & data['SUM_YR_1'].notnull()]print("删除缺失数据后的形状", airline_notnull.shape)"""3 定制规则:保留票价非零数据,或平局折扣率不为零且总飞行里程大于零的数据,然后清洗数据"""index1 = airline_notnull['SUM_YR_1'] != 0 # 保留票价非零index2 = airline_notnull['SUM_YR_2'] != 0index3 = airline_notnull['SEG_KM_SUM'] > 0 # 保留飞行里程大于零index4 = airline_notnull['avg_discount'] != 0 # 保留平局折扣率不为零# 保留年龄小于100index5 = airline_notnull['AGE'] < 100# 数据整合airline = airline_notnull[(index1 | index2) & index3 & index4 & index5]print("清洗后的数据形状", airline.shape)# 保存数据airline.to_csv(cleanedfile)
七 数据变换
数据标准化处理是预处理的最后一步,就是需要把数据格式变化成模型需要的样子。
我要不断努力进去,才能在最美好的样子遇到你,希望你刚好也是如此。
# L 关系长度- LOAD_TIME - FFP_DATE
# R 最近消费时间间隔- LAST_TO_END
# F 消费频率- FLIGHT_COUNT
# M 飞行里程- SEG_KM_SUM
# C 平均折扣系数- AVG_DISCOUNT
# 数据标准化处理
import pandas as pd
import numpy as np
cleanedfile = 'data_cleaned.csv'
data = pd.read_csv(cleanedfile)
# 选取需要的属性
airline_selection = data[['LOAD_TIME', 'FFP_DATE', 'LAST_TO_END', 'FLIGHT_COUNT', 'SEG_KM_SUM', 'avg_discount']]
# 选取前五的数据
airline_selection.head()
# L的值的运算
L = pd.to_datetime(airline_selection['LOAD_TIME']) - pd.to_datetime(airline_selection['FFP_DATE'])
L.head()
# L的数据类型转化
L = L.astype('str').str.split().str[0]
L.head()
L = L.astype('int') / 30
L.head()
# 把计算完成的L与上面不需要计算的属性合并
airline_features = pd.concat([L, airline_selection.iloc[:, 2:]], axis=1)
airline_features.head()
# 修改列名
airline_features.columns = ['L','R','F','M','C']
airline_features.head()
# 标准化处理:可以理解为 (原始数值-均值)/标准差
from sklearn.preprocessing import StandardScaler
data = StandardScaler().fit_transform(airline_features)
np.savez('airline_scale.npz', data)
data[:, :5]
八 数据建模
标准化处理完成之后就是数据建模了,客户价值分析模型的构建主要分为两个部分,一是根据客户的五个指标数据对客户进行聚类分群,就是把相似的人聚集到一起,这样做的好处是后续我们可以专门对这一类人采取相同的营销策略。第二,就是结合业务对每个客户进行特征分析,对客户群体进行排名,分析客户价值,后续的策略优先服务排名靠前的重要客户。
我们使用kmeans算法来完成聚类分析,分析过程如下
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
airline_scale = np.load('airline_scale.npz')['arr_0']
k = 5 # 把相似的对象分成几类,k值就设置成几
# 构建模型
kmeans_model = KMeans(n_clusters = k, random_state=123) # random_state为随即种子
# 训练模型
fit_means = kmeans_model.fit(airline_scale)
# 获取聚类中心
kmeans_cc = kmeans_model.cluster_centers_
print(kmeans_cc) # 每一行代码五维空间中的一个点
# 获取样本类别标签
kmeans_labels = kmeans_model.labels_
print(kmeans_labels)
# 统计不同类别样本数目
r1 = pd.Series(kmeans_labels).value_counts()
# 转换数据格式
cluster_center = pd.DataFrame(kmeans_model.cluster_centers_, columns=['L','R','F','M','C'])
# 顺序重置
cluster_center.index = pd.DataFrame(kmeans_model.labels_).drop_duplicates().iloc[:,0]
print(cluster_center) # 用聚类算法,把几万个用户聚成5类
关于聚类算法,现在我们可以不必关系他的原理,后续我们会有专门的章节来讲解,现在只需要跟着我的代码,一步一步了解这个过程即可。
九 数据可视化
用纯数据的方式不利于我们观察聚类分析的结果,让我们数据可视化的方法绘制成图形来看一下吧。
import matplotlib.pyplot as plt
labels = ['L','R','F','M','C'] # 指标
legen = ['customer' + str(i + 1) for i in cluster_center.index] # 名称
lstype = ['-','--',(0,(3,5,1,5,1,5)),':','-.'] # 样式
kinds = list(cluster_center.iloc[:,0]) # 分类
kinds
# 数据闭合,雷达图需要数据闭合
cluster_center = pd.concat([cluster_center, cluster_center[['L']]], axis=1)
cluster_center
centers = np.array(cluster_center.iloc[:, 0:])
centers
# 分割圆周的长
n = len(labels)
angle = np.linspace(0,2*np.pi, n, endpoint=False)
angle = np.concatenate((angle, [angle[0]]))
angle
# 画布
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(111, polar=True)
for i in range(len(kinds)):
ax.plot(angle, centers[i], linestyle=lstype[i], linewidth=2, label=kinds[i])
ax.set_thetagrids(angle*180/np.pi, labels)
plt.title('customer type')
plt.legend(legen) # 添加图例
plt.show()
十 结合业务做分析报告
一个优秀的数据分析师的功底即将呈现的时刻到了,上面我们做的所有的工作就是为了最后这一步,如何结合业务场景分析出用户价值和后续应对策略已以及营销方案才是我们做数据分析的重中之重。
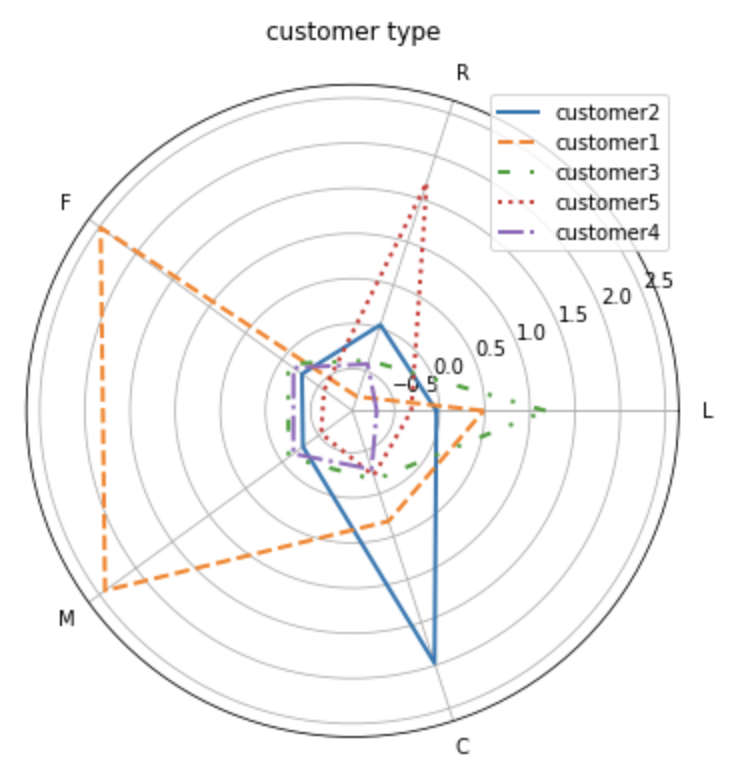
- L 关系长度- LOAD_TIME - FFP_DATE
- R 最近消费时间间隔- LAST_TO_END
- F 消费频率- FLIGHT_COUNT
- M 飞行里程- SEG_KM_SUM
- C 平均折扣系数- AVG_DISCOUNT
我们把图形和每一纬度对应的指标都放在这里,下面就和我一起根据图形来做分析。根据上面的特征分析图标说明每类用户都有显著不同的表现特征,基于这些特征的描述,我们把这些用户分为五个等级的客户类别:重要保持客户,重要发展客户,重要挽留客户,一般客户,其中每类客户类别的特征如下:
- 重要保持客户:customer1,这类客户的平均折扣率(C)较高,说明一般所乘坐航班的舱位等级较高,最近乘坐本航班(R)低,乘坐次数(F)和里程(M)最高,他们是航空公司的高价值用户,是最为理想的客户类型,对航空公司贡献最大,所占比例却小,航空公司应该优先将资源投放到他们身上,对他们进行差异化管理和一对一服务,提高这类客户的忠诚度和满意度,尽可能延长这类客户的高消费水平。
- 重要发展用户:customer2,这类客户平均折扣率最高,虽然当前价值不高,却是航空公司的潜在价值客户,要努力使这类客户增加消费,加强客户满意度,提高他们转向竞争对手的转移成本,是他们逐渐成为公司的忠诚客户。
- 重要挽留用户:customer3,这类客户入会时间最长,但其他属性都比较低。航空公司应该根据这些客户的最近消费时间,消费次数的变化情况,对其采取一定的营销手段,延长客户的生命周期。
- 一般价值用户:customer4,customer5,这类客户没有什么忠诚度可言,应该是机票打折才会购买的。
十一 补充分析
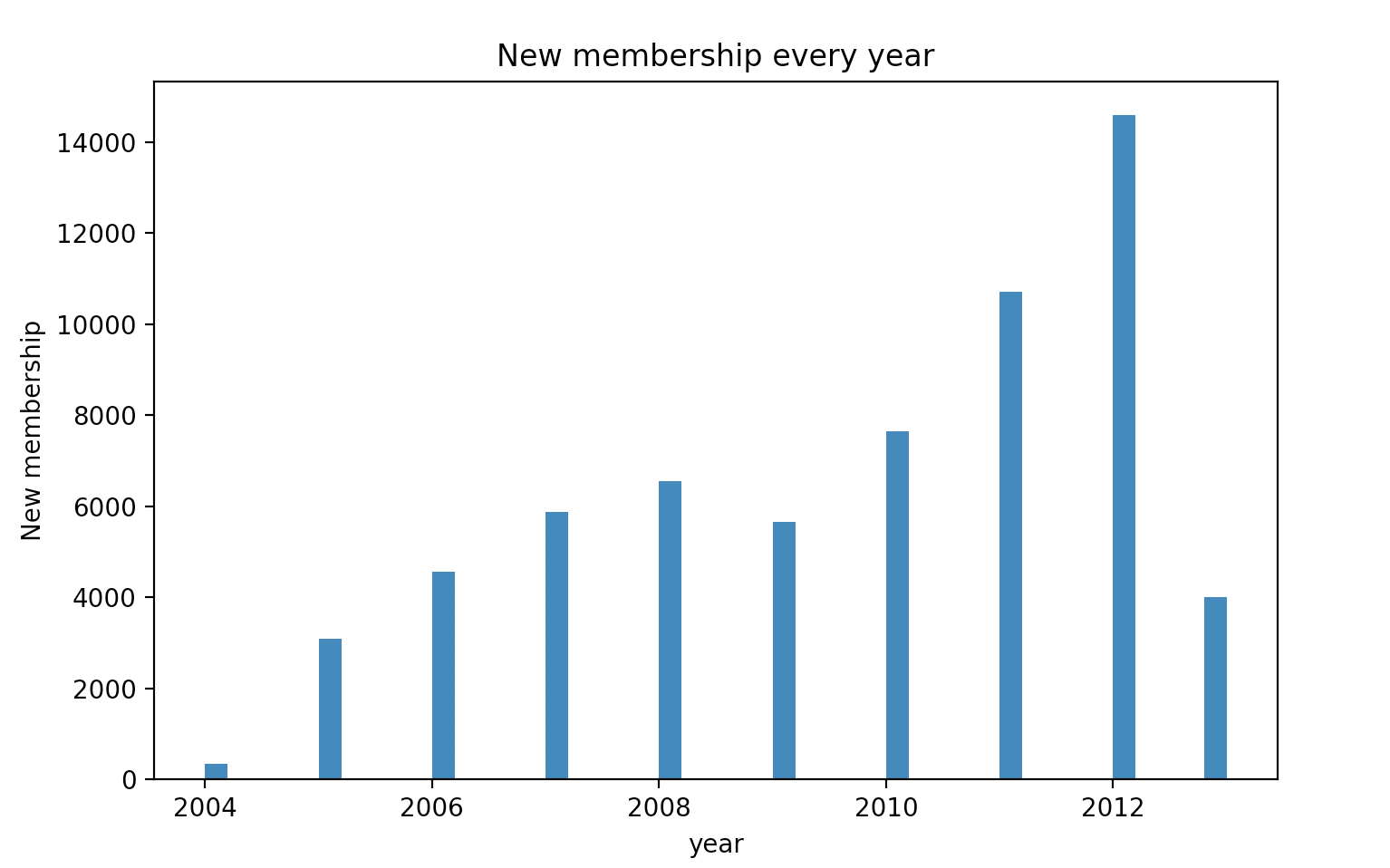
1 每年新增会员人数
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
data = pd.read_csv('air_data.csv')
ffp = data['FFP_DATE'].apply(lambda x: datetime.strptime(x, '%Y/%m/%d'))
ffp_year = ffp.map(lambda x: x.year)
fig = plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.hist(ffp_year, bins='auto')
plt.xlabel('year')
plt.ylabel('New membership')
plt.title('New membership every year')
plt.show()
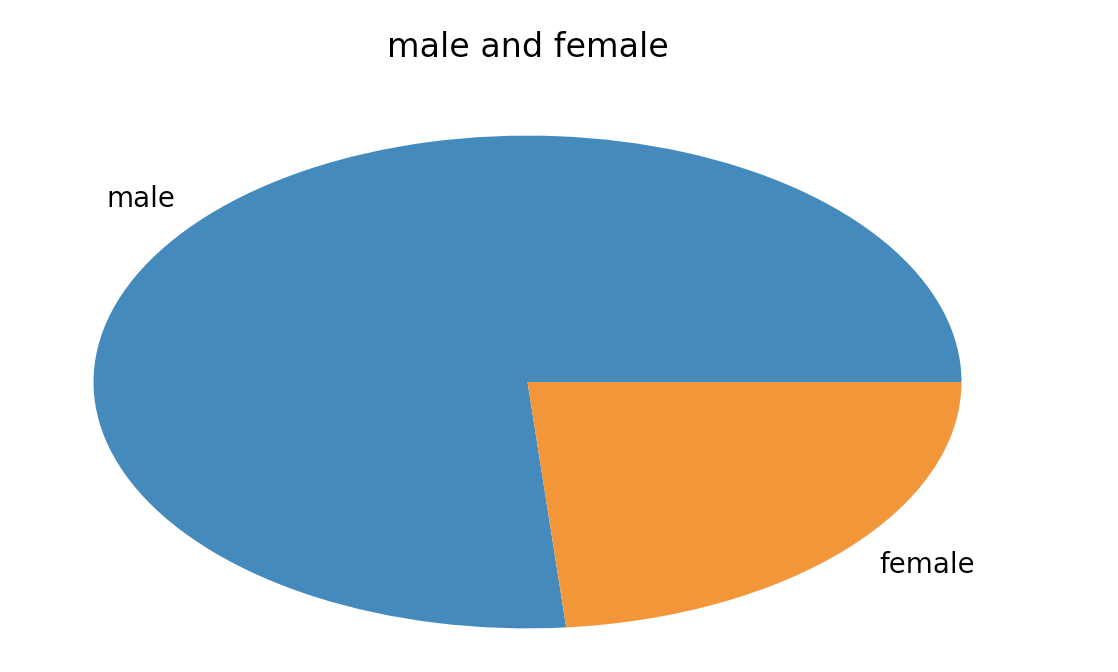
2 男女比例分析
male = pd.value_counts(data['GENDER'])['男']
female = pd.value_counts(data['GENDER'])['女']
fig = plt.figure(figsize=(7, 4))
plt.pie([male, female], labels=['male', 'female'])
plt.title('male and female')
plt.show()
结果如下图所示:
以上就是一些最为常用的图形,当然还有很多的图形等待着我们后续的学习,每一种数据总有一种图形适合去表示它,所以数据的可视化操作在数据分析以及AI领域都有非常重要的作用。相信通过这一章的学习,你一定能够掌握数据分析的整个流程,并且对数据有一个全新的认知了。

若有收获,就点个赞吧
0 人点赞
