一 pandas基本数据类型
1 Series类型
Pandas是数据处理中非常常用的一个库,是数据分析师、AI的工程师们必用的一个库,对这个库是否能够熟练的应用,直接关系到我们是否能够把数据处理成我们想要的样子。Pandas是基于NumPy构建的,让以NumPy为中心的应用变得更加的简单,它专注于数据处理,这个库可以帮助数据分析、数据挖掘、算法等工程师岗位的人员轻松快速的解决处理预处理的问题。比如说数据类型的转换,缺失值的处理、描述性统计分析、数据汇总等等功能。
它不仅仅包含各种数据处理的方法,也包含了从多种数据源中读取数据的方法,比如Excel、CSV等,这些我们后边会讲到,让我们首先从Pandas的数据类型开始学起。
Pandas一共包含了两种数据类型,分别是Series和DataFrame,我们先来学习一下Series类型。
Series类型就类似于一维数组对象,它是由一组数据以及一组与之相关的数据索引组成的,代码示例如下:
import pandas as pd# 实例化一个Series对象,参数是一个数组。obj = pd.Series([1, 2, 3, 4, 5, 6])print(obj)print(obj.index) # 获取索引print(obj.values) # 获取值
在打印结果中一共呈现出两列的内容:
0 11 22 33 44 55 6dtype: int64RangeIndex(start=0, stop=6, step=1)[1 2 3 4 5 6]
第一列代表索引值,第二列代表对象本身的值,第7行是对这个对象里边的值进行的说明。
关于Series类型的索引,我们是可以自己去定义的,就像这样:
# Series中的第一个参数指定对象的值,而index参数就是我们重新定义的索引。obj = pd.Series(['a', 'b', 'c', 'd', 'e'], index=[1, 2, 3, 4, 5])print(obj)print(obj[1]) # 访问到索引值为1的对象的值
声明一个Series类型,也可以采用字典的格式:
data = {'a': 100000, 'b': 20000, 'c': 30000}obj = pd.Series(data)print(obj) # 字典的key就是Series对象中的索引值,字典中的value就是Series对象中的值print(obj['a']) # 访问到索引值为a的对象的值
2 DataFrame类型
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同值的类型,数值、字符串、布尔值都可以。DataFrame 本身有行索引,也有列索引。这里需要注意一下,它是拥有列索引的,这一点是我们之前没有接触过的。
DataFrame类型可以直接想象成是我们把数据放在了Excel表格里一样,分具体的行和列,代码示例如下:
# 如果我们对96年,03年和09年选秀重新排名data = {'96年': ['科比', '艾弗森', '卡特'],'03年': ['詹姆斯', '韦德', '安东尼'],'09年': ['库里', '哈登', '格里芬'],}frame_data = pd.DataFrame(data)print(frame_data)
注意看返回内容:
96年 03年 09年0 科比 詹姆斯 库里1 艾弗森 韦德 哈登2 卡特 安东尼 格里芬
我们把0,1,2叫做行索引,把96年,03年和09年叫做列索引,我们可以使用如下代码直接访问一列的值:
print(frame_data['96年']) # 直接访问这一列的值
我们有一个根据日期自动生成索引的方法,首先我们先来生成一个日期的范围,代码如下:
import pandas as pdimport numpy as np# date_range与我们之前学习的range是类似的# periods是在我们给定的日期上往后加几天的意思dates = pd.date_range('20190701', periods=6)print(dates)
如果这个时候,我们单独来查看dates的值的话,返回的结果就是:
DatetimeIndex(['2019-07-01', '2019-07-02', '2019-07-03', '2019-07-04','2019-07-05', '2019-07-06'],dtype='datetime64[ns]', freq='D')
下面我们可以使用dates作为索引,然后声明一个DataFrame对象,代码如下:
df = pd.DataFrame(np.random.rand(6, 4), index=dates, columns=list('ABCD'))print(df)
在这行代码中第一个参数就是使用了NumPy进行一个6行4列的随机数生成,index指定了它的行索引,而columns参数指定了列索引。那么此时的df变量被打印出来的话,结果如下图: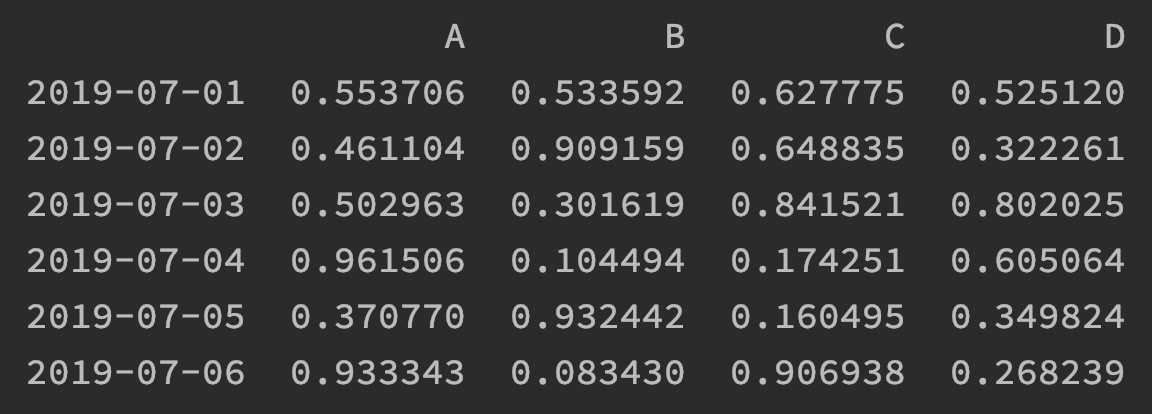
“现在我们可以专注的来练习一下如何具体的去访问DataFrame里的数据。在刚刚我们学习过访问一列的数据,现在我们来思考一下,如果我想按照行来访问数据怎么办呢?如果我们想根据行和列来同时进行数据访问,我们可以使用loc方法来完成这个操作,代码如下:
# 仅对行数据进行筛选print(df['20201012':'20201015'])# 访问其中的一个值print(df.loc["20201012", ['A']])# 对多行和多列进行筛选print(df.loc["20201012":'20201015', ['A', 'B']])
二 外部数据加载
1 csv
外部数据主要有四种:txt,Excel,csv和数据库,文本文件我们只能用最基本的Python的方式来读取,其他的接下来我们分别看一下。
如果你是非IT行业从业者的话,那么CSV格式的文件你可能并不常用,我们可以把它理解成为一个文本文件,但其特殊性主要呈现在数据与数据之间的分割符号上,除了这个特点,另外一个就是其文件的后缀名称了,是以.csv结尾的,文件如下:
虽然CSV格式的文件我们也可以使用Python中的文件读取方法,但由于其拥有格式,所以我们需要按照其格式来取,方便我们后续对数据进行处理,把取出来后的数据变成某种数据类型,这样操作起来就方便了,代码如下:
import pandas as pd# data1.csv就是文件的路径,这里可以写绝对路径也可以写相对路径data = pd.read_csv('data1.csv', header=None)print(data)print(type(data))
其中第一个参数是文件的路径,这一个我们已经清楚了。参数header就是显式的说明文件中没有头,自动帮我创建一个头吧。如果不指定参数header那么默认第一行数据就是头,也就是列索引,代码运行结果如下:
0 1 2 3 40 a b c d e1 1 2 3 4 52 6 7 8 9 10
如果你需要指定某一列来当作行索引,代码如下:
data = pd.read_csv('data1.csv', index_col='b')print(data)print(type(data))
以上结果需要你注意的是返回值的类型,全部都是DataFrame,也就是说后边我们使用到的DataFrame的方法都适合来处理这些从文件中读取出来的数据。
2 Excel
Excel的读取与csv非常类似,这里的参数sheet_name就是指定要读取哪一张表的数据,如果不指定,默认就是第一张表,具体代码如下:
data = pd.read_excel("data.xls", sheet_name="申报表")print(data)print(type(data))
需要注意的是,读取Excel文件你需要安装一个xlrd模块才可以。
3 MySQL
读取MySQL的方式也是一样的,前提是先连接数据库,具体代码如下:
import pandas as pdimport pymysqlconn = pymysql.connect(host='192.168.1.1',port=3306,user='admin',passwd='123456',db='school',use_unicode=True,charset="utf8")sql = 'select * from class'r = pd.read_sql(sql, con=conn)print(r)print(type(r))
三 日期的处理
日期格式的数据是我们在进行数据处理的时候经常遇到的一种格式,让我来看一下在Excel中的日期类的数据我们该如何处理?
现有Excel数据如下图所示: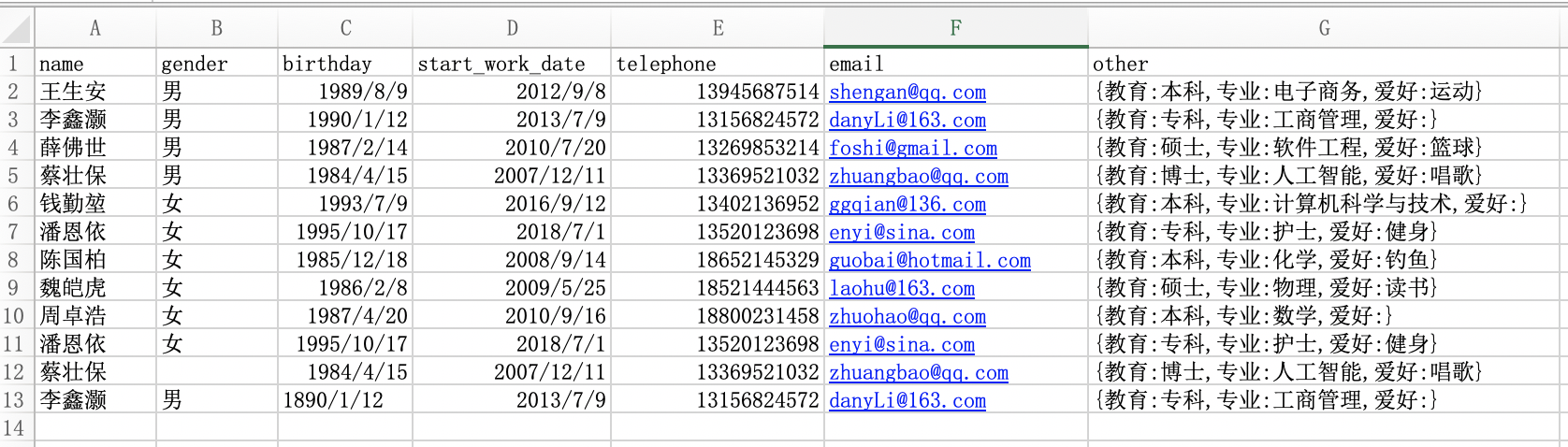
现在我们来思考几个问题:
- 如何更改手机号字段的数据类型
- 如何根据出生日期和开始工作日期两个字段更新年龄和工龄两个字段
- 如何将手机号的中间四位隐藏起来
- 如何根据邮箱信息取出邮箱域名字段
- 如何基于other字段取出每个人的专业信息
解决过程和代码如下:
import pandas as pdimport datetimedata = pd.read_excel('data2.xls')print(data)print(data.dtypes) # 查看各元素的数据类型# 1 把手机号字段改为object(字符串)类型data.telephone = data.telephone.astype('str')print(data.telephone.dtype)# 2 计算年龄和工龄now_year = datetime.datetime.now().year # 获取现在的年份,也可使用 pd.datetime.today().yearprint(now_year)bir_year = data.birthday.dt.yearprint(bir_year) # 获取生日字段的年份data['age'] = now_year - bir_year # 添加一个age字段data['work_age'] = now_year - data.start_work_date.dt.yearprint(data)# 3 隐藏手机号中间四位data.telephone = data.telephone.apply(func=lambda x: x.replace(x[3:7], '****'))print(data.telephone)# 4 取出邮箱域名data['email_domain'] = data.email.apply(func=lambda x: x.split('@')[1])print(data.email_domain)# 5 取出专业(我们使用正则来完成,也可以有别的方法)data['profession'] = data.other.str.findall('专业:(.*?),')print(data.profession)
除了能够添加字段,我也可以删除字段,代码如下:
# axis=1是指定轴1,inplace=True是真正删除
data.drop(['birthday', 'start_work_date'], axis=1, inplace=True)
print(data)
关于日期的处理方法需要多说一点,上边我们已经获取了年,我们还可以获取其他的单位。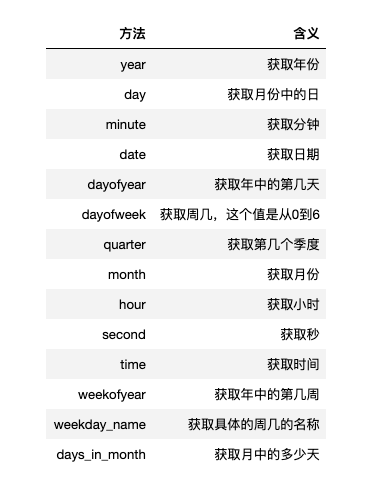
四 数据清洗的方法
1 处理重复数据
首先,我们把原有的数据集做一个简单的修改,如下图所示: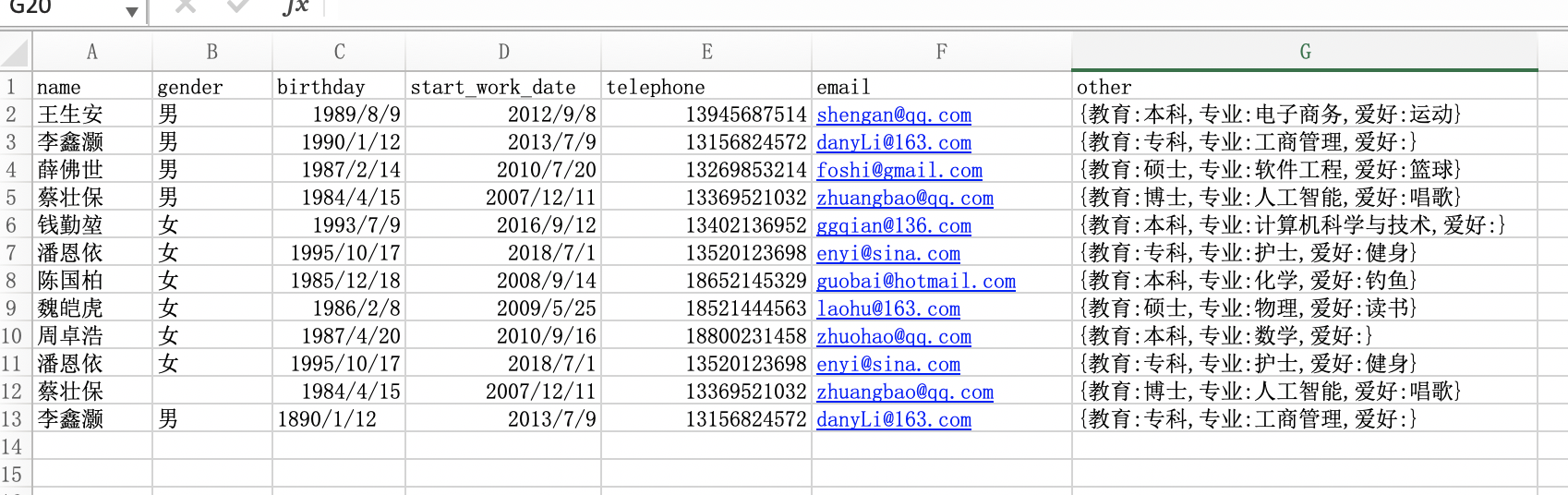
我们不需要去遍历比对,pandas有专门的方法获取到重复的数据,代码如下:
import pandas as pd
data = pd.read_excel('data.xlsx')
# 用duplicated()获取重复数据
repetition = data.duplicated()
print(repetition)
以下是返回的结果:
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 True
10 False
11 False
dtype: bool
注意这里返回结果中的行与Excel中的行不是对应的,根据返回结果我们可以看出,第9行是重复的,这里的重复数据指的是每一个字段都重复的数据。如果不重复,那么结果返回的就是False,如果重复,那么返回的就是True。对于重复数据,我们采用的处理方法一般就是删除,这个可以使用drop_duplicates()方法。
data.drop_duplicates(inplace=True) # 必须要有这个参数才能真正删除
print(data)
删除之后,你会发现索引没有变化,如需重置索引,我们使用reset_index这个方法。
# 如需重置索引,使用reset_index
data = data.reset_index(drop=True)
print(data)
2 处理缺失值
从原数据中我们可以看到,索引为10的数据,gender这一列的值为NaN,这就是代表着这个数据为空。我们可以通过isnull()方法来获取到位空的数据。
nan = data.isnull()
print(nan)
对于缺失的数据,我们有很多的处理方法,常见的处理方法有删除、和填充。如果是删除掉的话,我们可以使用df.dropna()方法,这样就把数据删除掉了。这里着重要讲解的是填充数据的方法,填充有这样几种方法:
# 向前填充,指的是用缺失值的前一个值替换
data = data.fillna(method='ffill')
print(data)
# 向后填充,指的是用缺失值的后一个值替换
data = data.fillna(method='bfill')
print(data)
# 指定值来进行替换,如果没有那么默认为男,这里也可以写一些表达式
data = data.fillna(value='男')
print(data)
3 处理异常值
关于异常值,我们通常是结合着业务来进行观察出来的。比如索引为11的数据,他的出生日期为1890/01/12,这明显是异常值。当然Pandas也提供了一些方法,供我们去观察一下是否有异常值,通常我们会通过查看信息info属性,查看描述方法describe(),或者是通过获取标准差std等方式来观察数据是否存在异常。在企业中进行数据处理时,对于异常的值,一定要和你的业务场景结合起来才有意义,就像上边的出生日期一样,放在现在肯定是异常的值了,但放在百年前,那就是正常的值。
4 透视表
接下来要讲的知识点叫做透视表,相信你一定用过Excel来统计一些数据,那么Pandas也提供了一个这样的功能,它就是具有透视表功能的函数pivot_table(),我们先来看一下这个函数的一些参数。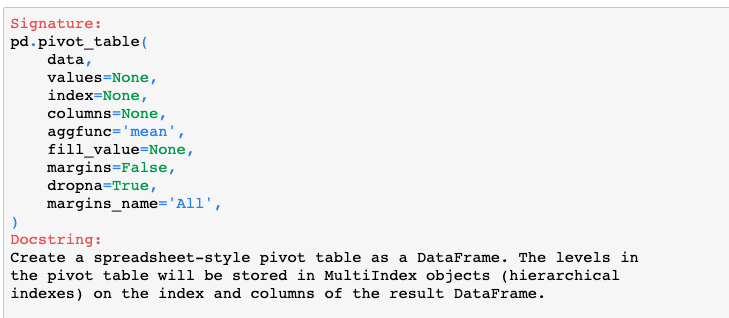
- 参数data,指的是你的数据集。
- 参数values,指的是要用来观察分析的数据值,就是Excel中的值字段。
- 参数index,指的是要行索引的数据值,就是Excel中的行字段。
- 参数columns,指的是列索引的数据值,就是Excel中的列字段。
- 参数aggfunc,指的是数据的统计函数,默认为统计平均值,也可以指定为NumPy模块中的其他统计函数。
- 参数fill_value,指的是一个标量,用来填充缺失值。
- 参数margins,布尔值,是否需要显示行或列的总计值,默认为False。
- 参数dropna,布尔值,是否删除整列为缺失的字段,默认为True。
- 参数margins_name,指定行或列的总计名称,默认为All。
现在让我们来试一下统计一下现有表中男人和女人分别的年龄和。首先我们计算出所有人的年龄。
data['age'] = pd.datetime.today().year - data.birthday.dt.year
print(data)
然后通过透视表功能计算男人和女人的年龄的总和。
import numpy as np
age_sum = pd.pivot_table(data=data, index='gender', values='age', aggfunc=np.sum)
print(age_sum)
练习:
这里有一个小练习作为巩固,练习内容已上传到文件中,可以直接下载查看,如果遇到不太会的地方,首先搜索一下,尝试自己能否独立的解决掉。
chapter7-1.zip

若有收获,就点个赞吧
0 人点赞
