列表
list1=['小明',18,1.70]2print(list1)# 打印出 ['小明',18,1.70]
小知识
如果想只打印出内容没有括号标点符号的可以使用元组 tuple 格式 print(tuple[0],tuple[1],tuple[2])
打印出结果 小明 18 1.70

从列表提取单个元素
students = ['小明','小红','小刚']print(students[0])# 打印出 小明
从列表提取多个元素
list2 = [5,6,7,8,9]print(list2[:])# 打印出[5,6,7,8,9]print(list2[2:])# 打印出[7,8.9] 截断前2位[5,6]冒号右边空则从左往右取到低print(list2[:2])# 打印出[5,6] 冒号左边空从第一位[5]开始取 冒号后面是2则取两位 [5,6]print(list2[1:3])#打印出[6,7] 冒号左边是1截断第1位[5] 冒号右边是3则取三位5,6,7截断5=[6,7]print(list2[2:4])#打印出[7,8] 截断第1和第2位[5,6] 取四位 5678截断56 = [7,8]
左右空,取到头;左要取,右不取
前半句:冒号左边空,就要从偏移量为0的元素开始取;右边空,就要取到列表的最后一个元素。
后半句:冒号左边数字对应的元素要拿,右边的不动
students = ['小明','小红','小刚']print(students[:2])#打印出结果 ['小明','小红'] 从左往右取两位
以下有两种方式打印出 ‘小刚’
students = ['小明','小红','小刚']print(students[2]) #小明第0位所以[2]是'小刚' [2]=第3位print(students[2:]) #截断前两位 得出 '小刚'
给列表增加/删除元素
append 添加
students = ['小明','小红','小刚']students.append('小美') #在['小明','小红','小刚']里面添加一个'小美'print(students)#打印出结果 ['小明','小红','小刚','小美']
del 删除
['小明','小红','小刚','小美']第0位 1 2 3del students[1] #删除第一位小红#打印出结果 ['小明','小刚','小美']

字典
什么是字典?
仔细看下,字典和列表有3个地方是一样的:
1.有名称;
2.要用=赋值;
3.用逗号作为元素间的分隔符。
而不一样的有两处:
1.列表外层用的是中括号[ ],字典的外层是大括号{ }
2.列表中的元素是自成一体的,而字典的元素是由一个个键值对构成的,用英文冒号连接。如’小明’:95,其中我们把’小明’叫键(key),95叫值(value)。
这里需要强调的是,字典中的键具备唯一性,而值可重复。也就是说字典里不能同时包含两个’小明’的键,但却可以有两个同为90的值
len() 函数
如果不想口算,我们可以用len()函数来得出一个列表或者字典的长度(元素个数),括号里放列表或字典名称。
同学们的成绩
students = ['小明','小红','小刚']scores = {'小明':95,'小红':90,'小刚':90}print(len(students))print(len(scores))#打印出结果 3# 3 代表有三位数值
从字典中提取元素
现在,我们尝试将小明的成绩从字典里打印出来。
这就涉及到字典的索引,和列表通过偏移量来索引不同,字典靠的是键。
scores = {'小明': 95, '小红': 90, '小刚': 90}print(scores['小明']) 打印出小明的分数#打印出结果 95
和列表相似的是要用[ ],不过因为字典没有偏移量,所以在中括号中应该写键的名称
给字典增加/删除元素
请你把小刚的成绩改成92分吧。对了,新来的小美也考了,得了85。请你对字典里进行修改和新增,然后将整个字典都打印出来。
scores = {'小明':95,'小红':90,'小刚':90}scores['小刚']=92 #修改小刚的值scores['小美']=85 #增加小美和值print(scores)#打印出结果{'小明':95,'小红':90,'小刚':92,'小美':85}
修改小刚成绩的时候,直接用赋值语句即可,del语句通常是用来删除确定不需要的键值对
总结
列表字典的不同点
# 如果==左右两边相等,值为True,不相等则为False。print(1 == 1)# 1等于1,所以值为Trueprint(1 == 2)# 1不等于2,所以为Falsestudents1 = ['小明','小红','小刚'] #列表students2 = ['小刚','小明','小红']print(students1 == students2)scores1 = {'小明':95,'小红':90,'小刚':100} #字典scores2 = {'小刚':100,'小明':95,'小红':90}print(scores1 == scores2)#打印出结果 False #列表# True #字典
为什么列表的数据对比不一样而字典一样呢?
因为列表中的数据是有序排列的,而字典中的数据是随机排列的。
而字典相比起来就显得随和很多,调动顺序也不影响。
这也是为什么两者数据读取方法会不同的原因:列表有序,要用偏移量定位;
字典无序,便通过唯一的键来取值。
列表字典的共同点
在列表和字典中,如果要修改元素,都可用赋值语句来完成。看一下代码:
list1 = ['小明','小红','小刚','小美']list1[1] = '小蓝'print(list1)#打印出结果 ['小明', '小蓝', '小刚', '小美']dict1 = {'小明':'男'}dict1['小明'] = '女'print(dict1)#打印出结果 {'小明': '女'}
字典进阶嵌套
第二个共同点 即支持任意嵌套。除之前学过的数据类型外,列表可嵌套其他列表和字典,字典也可嵌套其他字典和列表。
列表嵌套列表
先来看看第一种情况:列表嵌套列表。你在班级里成立了以四人为单位的学习小组。
这时,列表的形式可以写成:
students = [['小明','小红','小刚','小美'],['小强','小兰','小伟','小芳']]
students这个列表是由两个子列表组成的,现在有个问题是:我们要怎么把小芳取出来呢?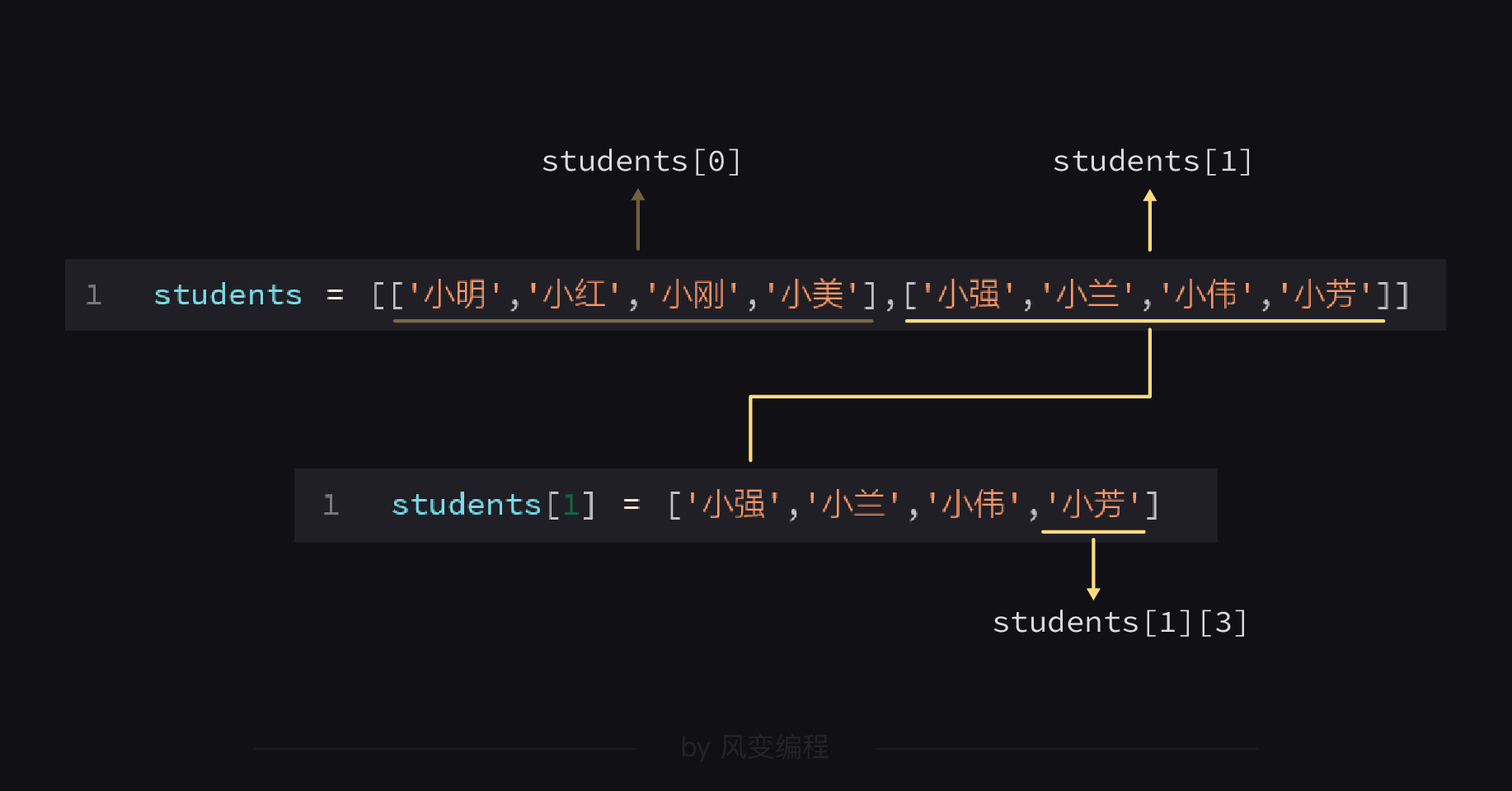
students = [['小明','小红','小刚','小美'],['小强','小兰','小伟','小芳']]print([1][3])#打印出结果 小芳
字典嵌套字典
和列表嵌套列表也是类似的,需要一层一层取出来,比如说要取出小芳的成绩,代码是这样写:
scores = {'第一组':{'小明':95,'小红':90,'小刚':100,'小美':85},'第二组':{'小强':99,'小兰':89,'小伟':93,'小芳':88}}print(scores['第二组']['小芳'])
列表和字典相互嵌套
# 最外层是大括号,所以是字典嵌套列表,先找到字典的键对应的列表,再判断列表中要取出元素的偏移量students = {'第一组':['小明','小红','小刚','小美'],'第二组':['小强','小兰','小伟','小芳']}print(students['第一组'][3])#取出'第一组'对应列表偏移量为3的元素,即'小美'# 最外层是中括号,所以是列表嵌套字典,先判断字典是列表的第几个元素,再找出要取出的值相对应的键scores = [{'小明':95,'小红':90,'小刚':100,'小美':85},{'小强':99,'小兰':89,'小伟':93,'小芳':88}]print(scores[1]['小强'])#先定位到列表偏移量为1的元素,即第二个字典,再取出字典里键为'小强'对应的值,即99。

若有收获,就点个赞吧
0 人点赞
