一、基本信息
JDK1.8版本,内部使用数组+链表/红黑树。
底层数组,默认大小:16(必须是2的次方,如果传入的数字不是2的次方,则使用大于传入值,最接近的2的次方值,由计算hash槽位算法决定),扩容因子:0.75。每次扩容为原来的2倍 。
0.75是时间和空间上一个均衡。(太小会导致频繁扩容,导致空间浪费;太大会导致大量hash冲突,导致太多链表,导致访问效率下降)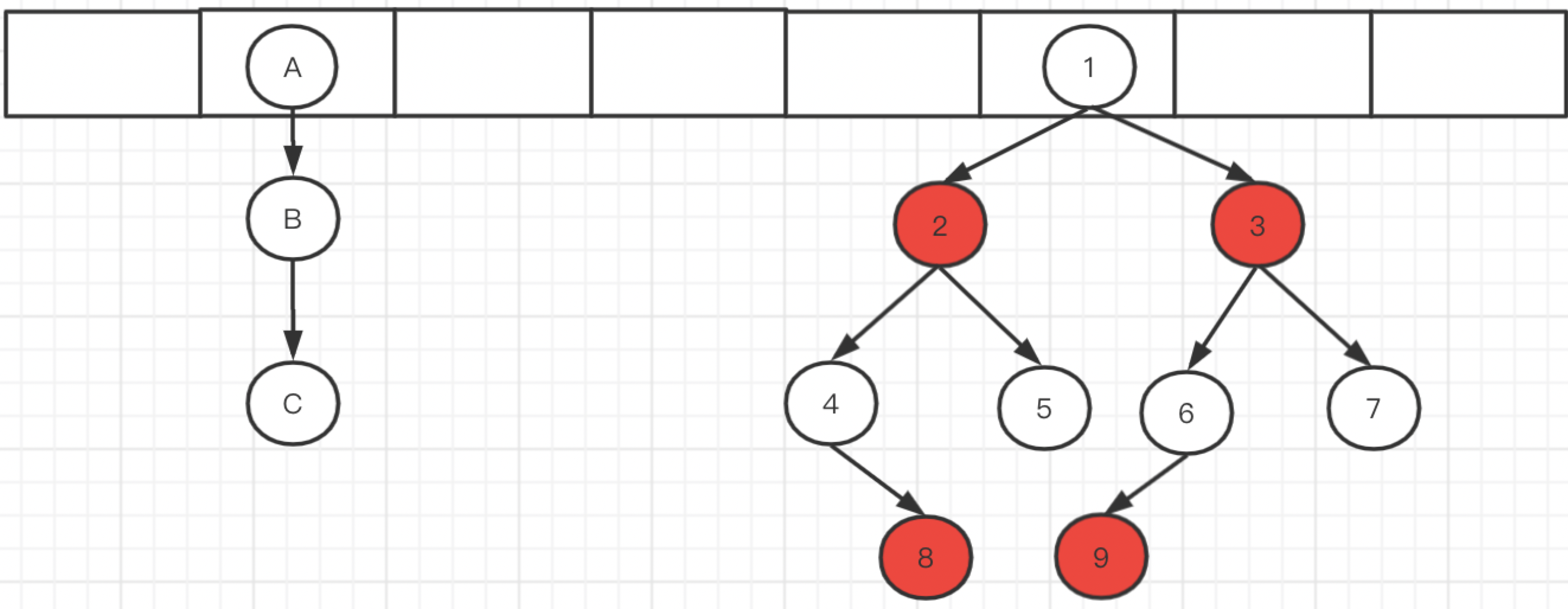
链表转红黑树条件:链表长度>8&底层数组存储元素>=64
红黑树退化链表条件:红黑树节点<6
数据插入过程
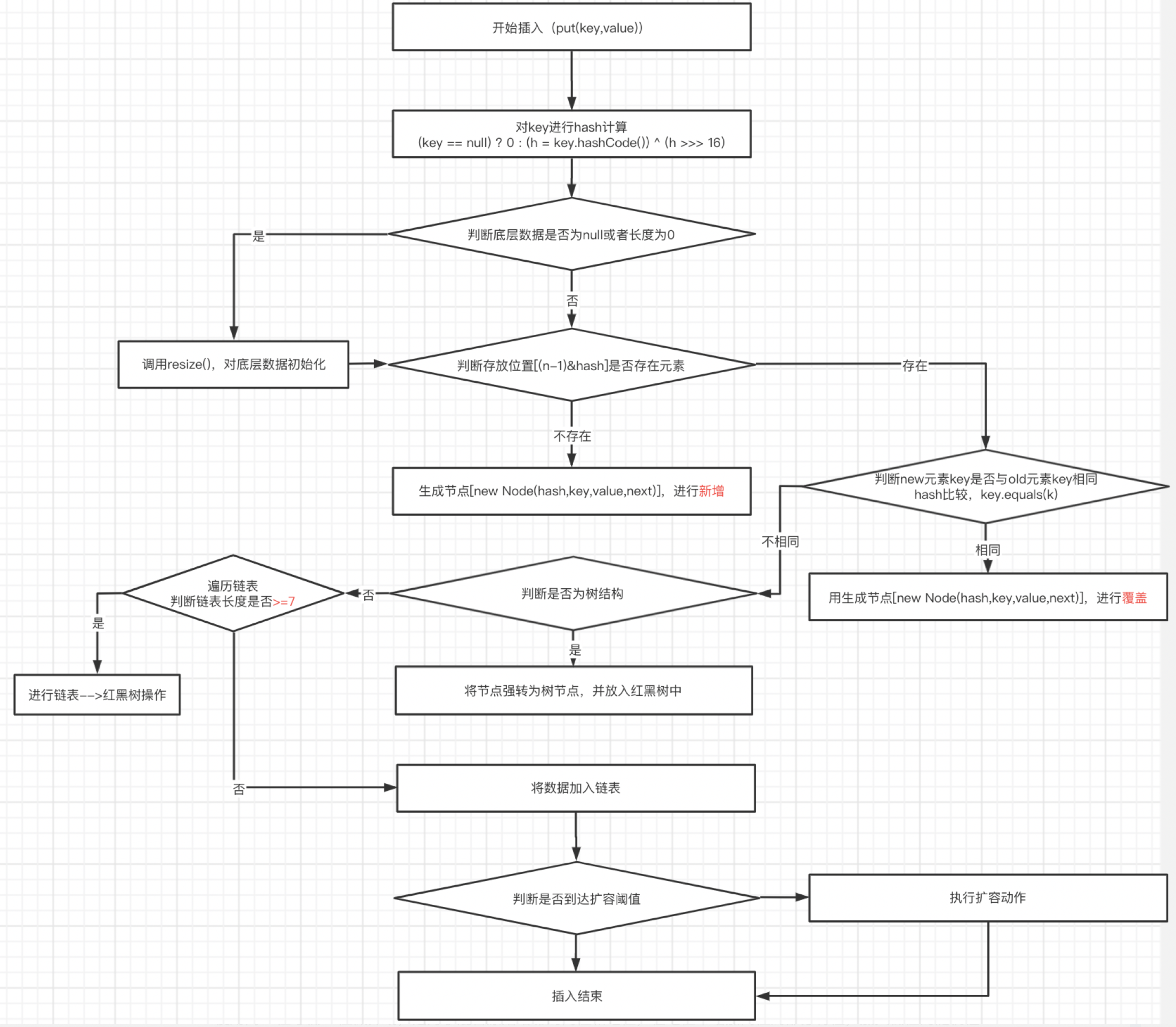
1.8版本hash函数
(key ==null) ?0: (h= key.hashCode()) ^ (h>>>16)
使用高16位与低16位做异或,是为了混合原始哈希的高位和地位,在地位中增加高位的部分特征,加大低位的随机性
1.8的四点优化
1. 数组+链表改成了数组+链表或红黑树;1. 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;1. 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑(高低位指针使用),位置不变或索引+旧容量大小;1. 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
1.8Hashap仍然存在问题
//在第一次put时,进行初始化底层数组final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//1.a线程执行到这里,让出cup,//2.b线程执行赋值操作,tab[i] = newNode(hash, key, value, null),//3.a线程获得cpu,执行赋值将b线程数据覆盖(发生覆盖前提条件a、b线程操作元素,hash值要一样,才能覆盖到同一槽位)if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;//多线程时,出现同时扩容。if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
LinkedHashMap保持有序的方法
LinkedHashMap内部维护了一个单链表,有头尾节点,同时LinkedHashMap节点Entry内部除了继承HashMap的Node属性,还有before 和 after用于标识前置节点和后置节点。可以实现按插入的顺序或访问顺序排序。

若有收获,就点个赞吧
0 人点赞
