本文是一个利用关键词来实现文本聚类,初步使用tf-idf来确定文章的关键词,然后利用关键词作为文章的文本内容再次形成文本的稀疏矩阵,再利用kmeans进行聚类,在聚类前可使用pca的方法对训练数据进行降维。
通过TF-IDF算法提取关键词
可以直接利用jieba分词的提取关键词功能,提取文本中的关键词,不过提取关键词,jieba提供了自定义stopword和tf-idf的模式,针对特定领域的语料,为了追求精确,需要通过语料库获取tf-idf,所以第一步就是通过语料库,获取所有词的tf-idf值,并生成文件,这里使用了gensim来完成。
生成自定义的tf-idf
首先不用说了就是引入必要的库
import jiebaimport jieba.analyseimport pandas as pdimport numpy as npfrom sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizerimport numpy as np
然后读取整个语料库,这里使用的语料库大约是300M,可以一次性读取
with open("f:/data/complaint1.txt", "r", encoding="GBK", errors='ignore') as f:texts = [filter_tags(line).replace('\n', "") for line in f.readlines()]
之后就是分词了,分词之后去除停用词,还要过滤html的标签
import redef filter_tags(htmlstr):"""# Python通过正则表达式去除(过滤)HTML标签:param htmlstr::return:"""# 先过滤CDATAre_cdata = re.compile('//<!\CDATA\[[ >]∗ //\CDATA\[[ >]∗ //\\] > ',re.I) #匹配CDATAre_script = re.compile('<\s*script[^>]*>[^<]*<\s*/\s*script\s*>', re.I)# Scriptre_style = re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>', re.I)# stylere_br = re.compile('<br\s*?/?>')# 处理换行re_h = re.compile('</?\w+[^>]*>')# HTML标签re_comment = re.compile('<!--[^>]*-->')# HTML注释s = re_cdata.sub('', htmlstr)# 去掉CDATAs = re_script.sub('', s) # 去掉SCRIPTs = re_style.sub('', s)# 去掉styles = re_br.sub('\n', s)# 将br转换为换行s = re_h.sub('', s) # 去掉HTML 标签s = re_comment.sub('', s)# 去掉HTML注释# 去掉多余的空行blank_line = re.compile('\n+')s = blank_line.sub('\n', s)s = replaceCharEntity(s) # 替换实体return sdef replaceCharEntity(htmlstr):""":param htmlstr:HTML字符串:function:过滤HTML中的标签"""CHAR_ENTITIES = {'nbsp': ' ', '160': ' ','lt': '<', '60': '<','gt': '>', '62': '>','amp': '&', '38': '&','quot': '"', '34': '"', }re_charEntity = re.compile(r'&#?(?P<name>\w+);')sz = re_charEntity.search(htmlstr)while sz:entity = sz.group() # entity全称,如>key = sz.group('name') # 去除&;后entity,如>为gttry:htmlstr = re_charEntity.sub(CHAR_ENTITIES[key], htmlstr, 1)sz = re_charEntity.search(htmlstr)except KeyError:# 以空串代替htmlstr = re_charEntity.sub('', htmlstr, 1)sz = re_charEntity.search(htmlstr)return htmlstrdef repalce(s, re_exp, repl_string):return re_exp.sub(repl_string,s)
停用词库使用了百度的词库,这里在网上有很多,可以多个一起使用,另外根据文章的特点,要手工将停用词加入,另外除了过滤html,还可以过滤数字,电话等一些无用信息,从而减少计算量提升准确率。
datasets = []stopwords = {}.fromkeys([ line.rstrip() for line in open('f:/data/baidu_stopword.txt', 'r', encoding='utf-8') ])for line in texts:segs = [word for word in jieba.lcut(line, cut_all=False) if word not in stopwords]datasets.append(segs)
下面就是通过gensim来生成tfidf的模型了
from gensim import corporafrom gensim.models import TfidfModeldct=corpora.Dictionary(datasets)corpus = [dct.doc2bow(line) for line in datasets]model = TfidfModel(corpus)
生成好模型,就需要吧语料库的中各个词,输入到jieba可以读取的tfidf自定义文件中了
dict = {}for l in model[corpus]:for w in l:if w[0] not in dict:dict[w[0]] = w[1]with open("f:/data/complaint_idf.txt.big", "w") as f:for (k, v) in dict.items():f.write(dct[k])f.write(" ")f.write(str(v))f.write("\n")
提取关键词
通过生成的自定义的tf-idf可以用来提取文章的关键词,然后利用关键词的tf-idf来形成文章的特征向量,这里首先要设定自定义的stopword库和tf-idf库,其实jieba是可以带tf-idf值返回的,这里在提取关键词后重新计算了tf-idf的表示向量,只是为了保障纯用关键词来实现聚类。
import jiebaimport jieba.analysejieba.analyse.set_stop_words("f:/data/baidu_stopword.txt")jieba.analyse.set_idf_path("f:/data/complaint_idf.txt.big");
读取语料库逐一读取文章的关键词
content = open("f:/data/complaint1.txt", 'r', encoding="GBK", errors='ignore').read()lines = content.split("\n")datasets = [jieba.analyse.extract_tags(line, topK=20, withWeight=False, allowPOS=()) for line in lines]
下面就是计算关键词的tf-idf表示向量,并生成稀疏矩阵为了kmeans等算法进行训练
from gensim import corporafrom gensim.models import TfidfModelfrom gensim.matutils import corpus2dense, corpus2cscdct=corpora.Dictionary(datasets)corpus = [dct.doc2bow(line) for line in datasets]model = TfidfModel(corpus)corpus_tfidf = model[corpus]corpus_tfidf_sparse = corpus2csc(corpus_tfidf)
通过kmeans算法进行聚类
利用kmeans实现聚类
有了上面的铺垫,到了这步就比较简单了,直接调用kmeans的方法实现聚类
from sklearn.cluster import KMeansclusters = KMeans(n_clusters=20, random_state=0).fit_predict(corpus_tfidf_sparse.T)
但是这里有两个问题,一个是分类的数量,这个很难估计,可能需要调节超参,多次训练来获取最佳值,但是语料库很大,训练量不小,看来需要找两台好机器了;另外就是没有通过降维,稀疏矩阵的训练速度非常的慢,下面考虑使用PCA来实现降维。先砍一下分类的结果如下: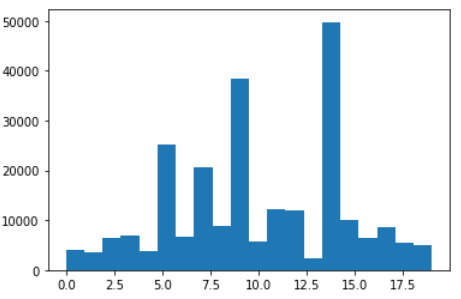
https://www.tutorialspoint.com/gensim/gensim_creating_tf_idf_matrix.htm
https://stackoverflow.com/questions/50933591/how-to-perform-kmean-clustering-from-gensim-tfidf-values

若有收获,就点个赞吧
0 人点赞
