索引:就是给表中的某些常用列,定义一种快速检索数据的方式
添加索引,是数据库中针对SQL调优的最佳方案
创建普通索引
普通索引 : 字段中,可以存放重复值
//建表时,添加索引create table t_teacher(id int primary key,teacher_name varchar(20),age int,gender char(2),key idx_teacher_name (teacher_name) using btree);//表已存在,添加索引(使用最多)alter table t_teacher add index idx_teacher_name (teacher_name) using btree;
add index 索引的名字 (需要添加索引的列) using 索引类型;
创建唯一索引
唯一索引: 字段中,不能存放重复值
语法
//建表时,添加索引
create table t_teacher(id int primary key,teacher_name varchar(20),age int,gender char(2),unique key uk_teacher_name (teacher_name) using btree);
//表已存在,添加索引(使用最多)
alter table t_teacher add unique index uk_teacher_name (teacher_name) using btree;
索引的使用注意
1、在查询语句中的select 后 使用索引字段,切记:不要添加非索引字段,加了就会导致索引失效
2、在查询语句中尽量不要使用 > < >= != <> 这些符号
3、在查询语句中like 后不要直接跟随 %,例如:%张 %三% 要用就用:张%
4、组合索引中,没有按照索引类的顺序进行查询,索引也会失效
5、or 也会导致索引失效
6、索引列是个字符串,如果不加’’ 也会导致索引失效
7、使用select * 可能会导致索引失效
索引分类
btree(默认)
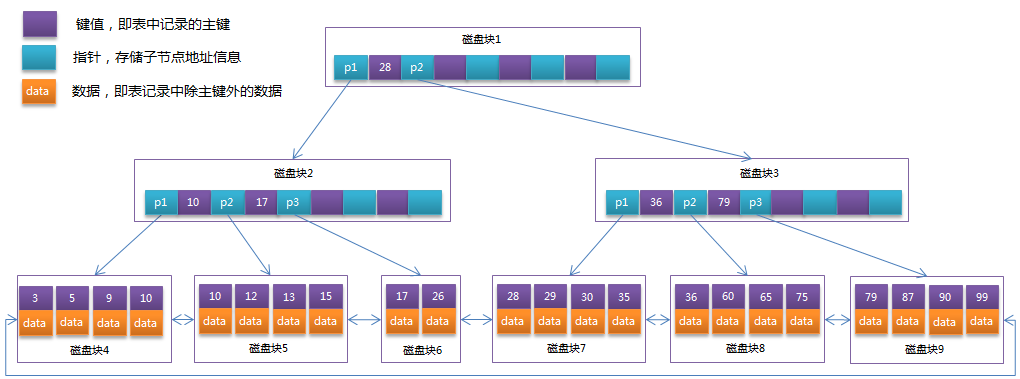
btree索引会先在【磁盘1】定义一个索引值,并把小于索引值的内容放到【p1】,大于索引值的内容放到【p2】
在【p1】中,又新增两个索引值【10】和【17】,按照相同的方法把其他索引值分类到【p1,p2,p3】
【磁盘3】也相同
到了最下层,就是具体的索引值以及对应的数据了
hash(不推荐)
hash索引是计算索引字段内容的地址值,用地址值进行查询
索引面试题
explain SQL的执行计划
说:问你的一条SQL语句,你如何知道这条SQL语句,有没有使用到索引?
回答:我们可以使用explain 查看SQL的执行计划,并且重点关注:type,possible_keys,key,rows 这几个属性
type: 主要用于描述 该语句是哪种类型的查询语句

从最好到最差依次是:
system > const > eq_ref > ref > range 代表SQL语句中使用到范围查询 > index > all
system 代表表中只有1条数据
const 代表SQL语句使用到了 主键或者唯一索引
eq_ref 代表SQL语句使用到了 主键或者唯一索引(唯一性索引扫描)
ref 代表SQL语句使用到了 普通索引(非唯一性索引扫描)
range 代表SQL语句中使用到范围查询
index 代表SQL语句只查询了索引数据,没有查询其他数据,eg: select id from 表;
all 代表 全表检索 (效率最差)
all一般如果查询较差,都需要进行索引优化
possible_keys
可能会使用到的索引
key
实际用到的索引
rows
此次使用索引查询,受影响的行数

若有收获,就点个赞吧
0 人点赞
