一、缓存失效问题
1. 缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。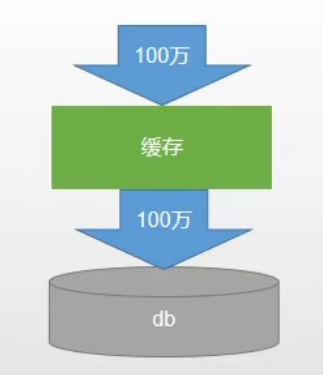
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决方式: 缓存空结果、并且设置短的过期时间。
1.1 示例代码
如下代码,当大并发量访问缓存中不存在对应的数据的key时,全部请求同时会去调用数据库查询,可能会导致数据库宕机。
public Map<String, List<Catelog2Vo>> getCatalogJson2() {ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();String catalogJson = ops.get("catalogJson");// 1、先查询缓存if (StringUtils.isEmpty(catalogJson)) {System.out.println("缓存不命中...查询数据库...");//2、缓存中没有数据,查询数据库Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDbWithRedissonLock();return catalogJsonFromDb;}System.out.println("缓存命中...直接返回...");//转为指定的对象Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson,new TypeReference<Map<String, List<Catelog2Vo>>>(){});return result;}
2. 缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB 瞬时压力过重雪崩。 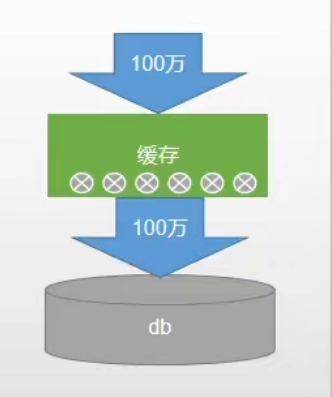
解决方式: 原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
3. 缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问, 是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所 有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决方式: 加锁
3.1 示例代码
3.1.1 本地锁
这里使用本地锁解决单体应用下,大并发访问时缓存击穿的问题,需要注意的是,第一次访问时若缓存中不存在数据,需要去数据库查询,查询到结果则要将其存入缓存中再返回数据,访问数据库以及存入缓存的操作要在同步代码块中一同执行,否则会出现问题。如:在查询完数据库后就释放掉锁,这时候还没来得及将查到的数据缓存下来,下一个请求获取到锁之后发现缓存中没有对应的数据,会再次查询数据库,失去了加锁的意义。
/*** 从数据库查询并封装数据::本地锁* @return*/public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithLocalLock() {// //如果缓存中有就用缓存的// Map<String, List<Catelog2Vo>> catalogJson = (Map<String, List<Catelog2Vo>>) cache.get("catalogJson");// if (cache.get("catalogJson") == null) {// //调用业务// //返回数据又放入缓存// }//只要是同一把锁,就能锁住这个锁的所有线程//1、synchronized (this):SpringBoot所有的组件在容器中都是单例的。//TODO 本地锁:synchronized,JUC(Lock),在分布式情况下,想要锁住所有,必须使用分布式锁synchronized (this) {//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询return getDataFromDb();}}private Map<String, List<Catelog2Vo>> getDataFromDb() {//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询String catalogJson = stringRedisTemplate.opsForValue().get("catalogJson");if (!StringUtils.isEmpty(catalogJson)) {//缓存不为空直接返回Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {});return result;}System.out.println("查询了数据库");/*** 将数据库的多次查询变为一次*/List<CategoryEntity> selectList = this.baseMapper.selectList(null);//1、查出所有分类//1、1)查出所有一级分类List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);//封装数据Map<String, List<Catelog2Vo>> parentCid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {//1、每一个的一级分类,查到这个一级分类的二级分类List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());//2、封装上面的结果List<Catelog2Vo> catelog2Vos = null;if (categoryEntities != null) {catelog2Vos = categoryEntities.stream().map(l2 -> {Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName().toString());//1、找当前二级分类的三级分类封装成voList<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());if (level3Catelog != null) {List<Catelog2Vo.Category3Vo> category3Vos = level3Catelog.stream().map(l3 -> {//2、封装成指定格式Catelog2Vo.Category3Vo category3Vo = new Catelog2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());return category3Vo;}).collect(Collectors.toList());catelog2Vo.setCatalog3List(category3Vos);}return catelog2Vo;}).collect(Collectors.toList());}return catelog2Vos;}));//3、将查到的数据放入缓存,将对象转为jsonString valueJson = JSON.toJSONString(parentCid);stringRedisTemplate.opsForValue().set("catalogJson", valueJson, 1, TimeUnit.DAYS);return parentCid;}
当服务采用分布式部署方式,经过网关做负载均衡访问,我们会发现在并发环境下访问,分布式集群中的每个单体应用都可能会去访问数据库,此时我们使用的本地锁就失去了它的作用,这时我们就要进一步采用分布式锁来达到分布式环境下的问题解决效果。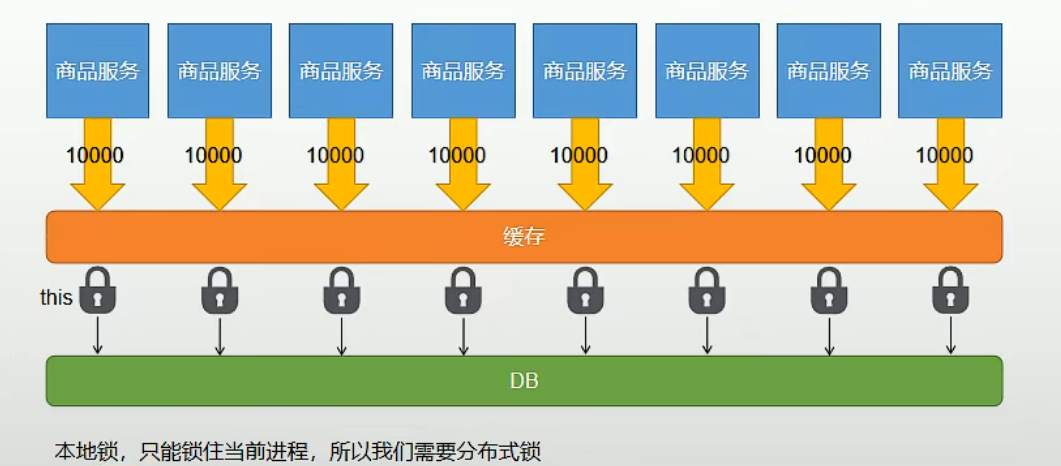
3.1.2 分布式锁
为了解决本地锁在分布式环境下失效的问题,我们需要采用分布式锁。
分布式原理就是借助一个外界的标识,判定此资源的占用状态,可以通过数据库存储,也可以使用redis存储,相对来说redis性能更好,且可以通过lua脚本的方式实现多种原子性操作。
1. 初步加分布式锁
下面通过使用redis的setnx命令,来实现分布式锁的创建。
我们在redis中设置了锁的标识:
- 当设置不成功时,说明有其他线程拿到了锁,在执行业务逻辑,这时候需要做自旋操作,等待锁的获取。- 当设置成功时,说明获取到了锁,则可以执行对应的业务逻辑。
/*** 从数据库查询并封装数据::分布式锁* @return*/public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {//1、占分布式锁。去redis占坑Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "1111");if (lock) {Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();stringRedisTemplate.delete("lock"); // 删除锁return dataFromDb;} else {System.out.println("获取分布式锁失败...等待重试...");//加锁失败...重试机制//休眠一百毫秒try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); }return getCatalogJsonFromDbWithRedisLock(); //自旋的方式}}
2. 给分布式锁加过期时间
上述实现方式中,存在一个问题:当一个线程占用了此分布式锁,在执行业务代码的过程中出现了错误,不能够正确执行解锁的操作(删除分布式锁),这时候就会出现锁永久性被占用的情况,导致死锁发生,以后的同业务逻辑都无法再正常获取到此分布式锁。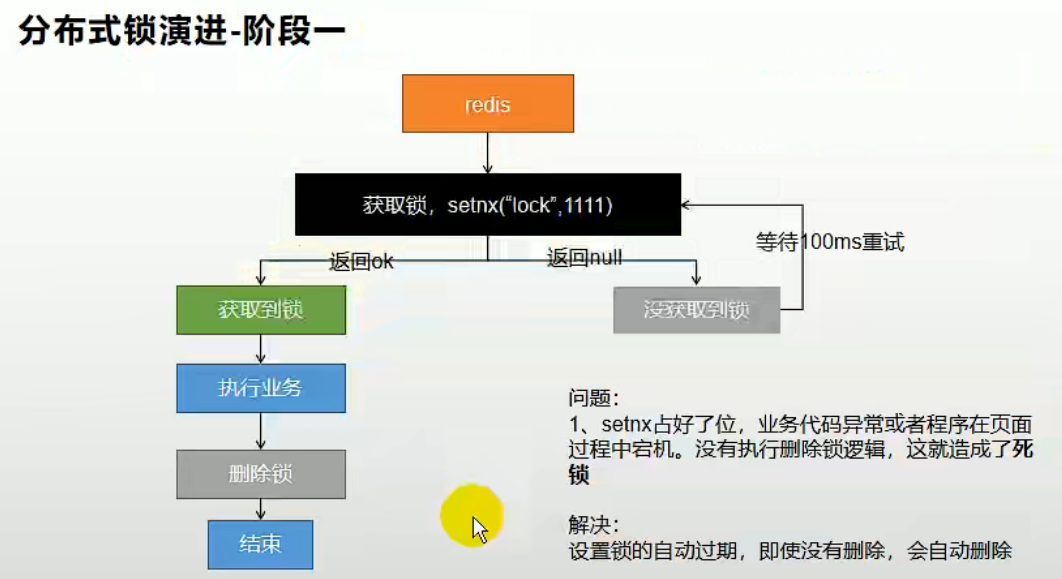
所以我们需要借助于redis的键的过期时间来,避免此种情况的发生。但此时同样存在问题,当设置完分布式之后,在刚要给此锁配置过期时间时,代码出现错误,此时仍旧没有成功给锁加上过期时间,又重复了上种情况可能发生的问题: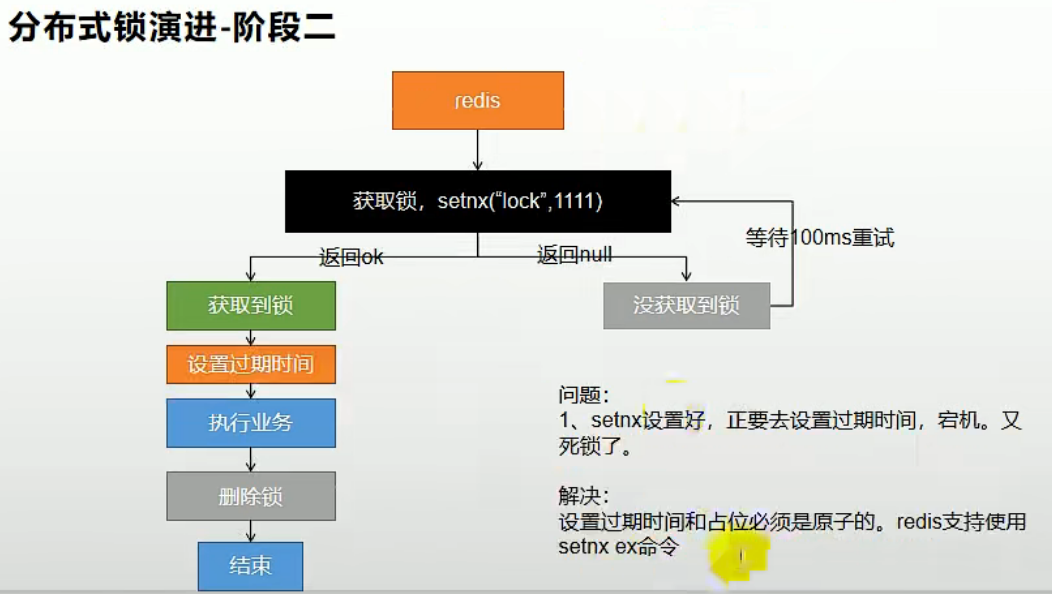
这时,我们可以采用redis的setnx ex命令,来实现原子的执行设置分布式锁以及配置过期时间这两步操作:
/*** 从数据库查询并封装数据::分布式锁* @return*/public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {//1、占分布式锁。去redis占坑Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "1111", 300, TimeUnit.SECONDS);if (lock) {Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();stringRedisTemplate.delete("lock");return dataFromDb;} else {System.out.println("获取分布式锁失败...等待重试...");//加锁失败...重试机制//休眠一百毫秒try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); }return getCatalogJsonFromDbWithRedisLock(); //自旋的方式}}
3. 配置专属的分布式锁
解决了分布式锁解锁异常的问题,我们还需要注意到,当业务逻辑执行时间较长时,超过了锁的过期时间,这时候锁自己就过期清除了,此时若业务代码执行完成,接着要进行解锁操作,注意,若在锁过期的时候其他线程获取到了锁开始执行业务代码,那么上一个线程要执行的解锁操作会把后一个线程的锁给误解掉,导致后续的一系列问题出现。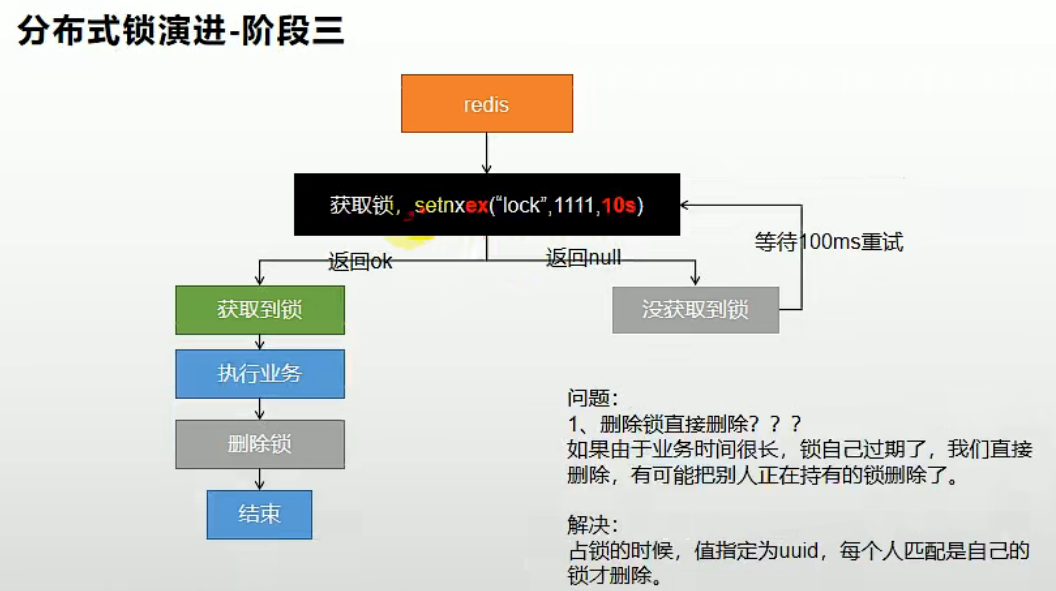
所以我们需要通过给锁的键对应的值配置成专属于本线程的特定值,在做解锁操作的时候,先判断此时锁的值是否还是加锁时候的,如果是的话才执行解锁操作。
/*** 从数据库查询并封装数据::分布式锁* @return*/public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {//1、占分布式锁。去redis占坑String uuid = UUID.randomUUID().toString();Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);if (lock) {Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();//先去redis查询下保证当前的锁是自己的//获取值对比,对比成功删除=原子性 lua脚本解锁String lockValue = stringRedisTemplate.opsForValue().get("lock");if (uuid.equals(lockValue)) {//删除我自己的锁stringRedisTemplate.delete("lock");}return dataFromDb;} else {System.out.println("获取分布式锁失败...等待重试...");//加锁失败...重试机制//休眠一百毫秒try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); }return getCatalogJsonFromDbWithRedisLock(); //自旋的方式}}
此时,我们就在表面上解决了误删其他线程锁的问题,此时还未真正结束,我们需要注意到一个问题,当我们获取锁的值的操作和解锁操作分为两步进行时,当我们发起请求查询到锁值,发现结果匹配,准备再次发请求去做解锁操作前,此锁到了过期时间而过期了,很巧的是其他线程同时获取到锁加锁成功,这时当前一个线程执行解锁操作,同样会误解开其他线程的锁,导致问题出现。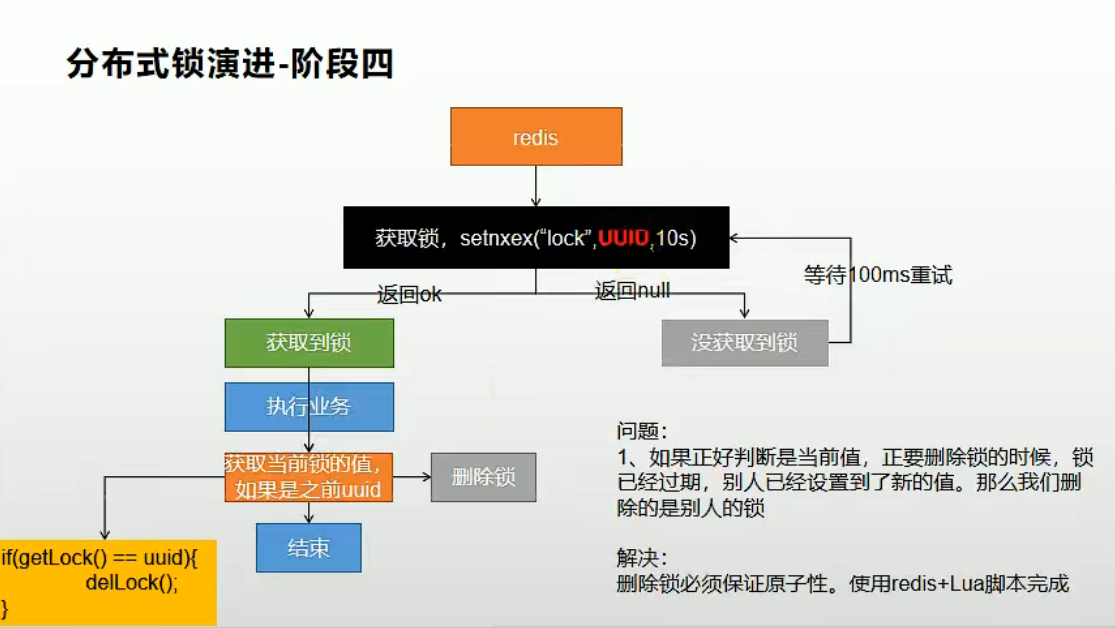
所以,我们做锁值的查询操作与解锁操作,同样是要作为一个原子操作来一次性完成的。不巧的是,redis并没有相关的命令来供我们便捷操作,这时候就需要借助于lua脚本来编写脚本,通过redis执行lua脚本来实现此原子性操作。
/*** 从数据库查询并封装数据::分布式锁* @return*/public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {//1、占分布式锁。去redis占坑 设置过期时间必须和加锁是同步的,保证原子性(避免死锁)String uuid = UUID.randomUUID().toString();Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid,300,TimeUnit.SECONDS);if (lock) {System.out.println("获取分布式锁成功...");Map<String, List<Catelog2Vo>> dataFromDb = null;try {//加锁成功...执行业务dataFromDb = getDataFromDb();} finally {String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";//删除锁stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);}return dataFromDb;} else {System.out.println("获取分布式锁失败...等待重试...");//加锁失败...重试机制//休眠一百毫秒try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); }return getCatalogJsonFromDbWithRedisLock(); //自旋的方式}}
二、缓存一致性问题
使用缓存的过程中,我们会遇到修改数据的情况,这时候修改数据库以及缓存中的数据会存在数据不一致的问题。这时我们要想办法来保证两者之间保持一致。
2.1 解决方式
2.1.1 方式一:双写模式
我们在修改完数据库的值之后,同时要修改缓存中的数据,是两者保持一致。
但是即便是修改的时候,同时更新数据库和缓存中的数据,仍然可能会出现数据不一致的情况:
比如,一个线程修改了数据库之后,还没来得及往缓存中更新,另一个就修改了数据库数据,并同时优先更新了缓存中的数据,这时等到第一个线程来更新此缓存时,就会导致数据的不一致出现,这种方式可能存在脏数据,当数据稳定、缓存过期后,重新加载到缓存中,才能达到数据的最终一致性。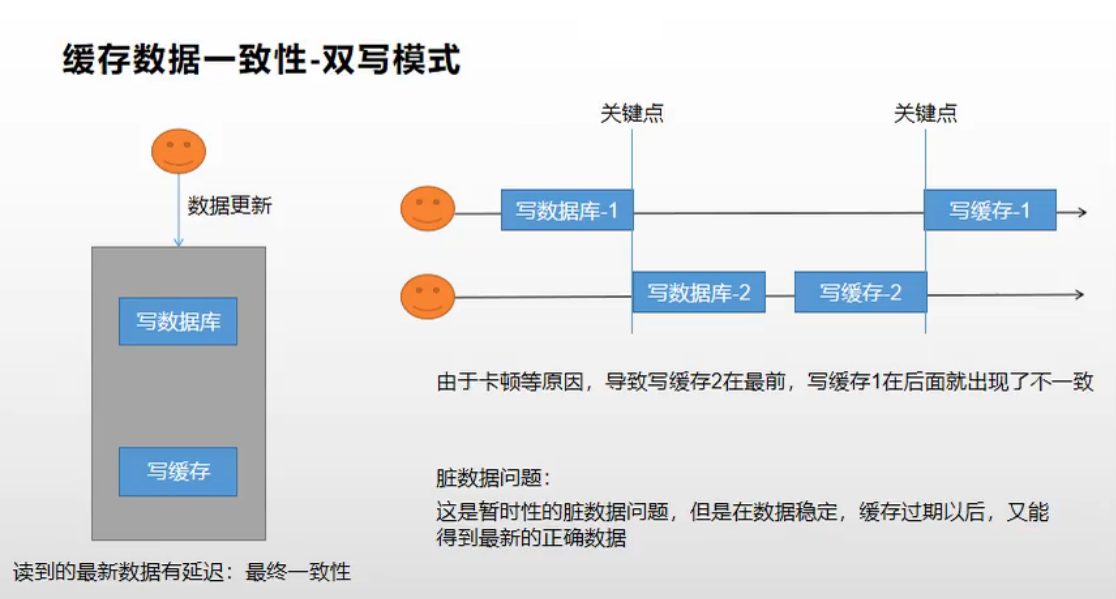
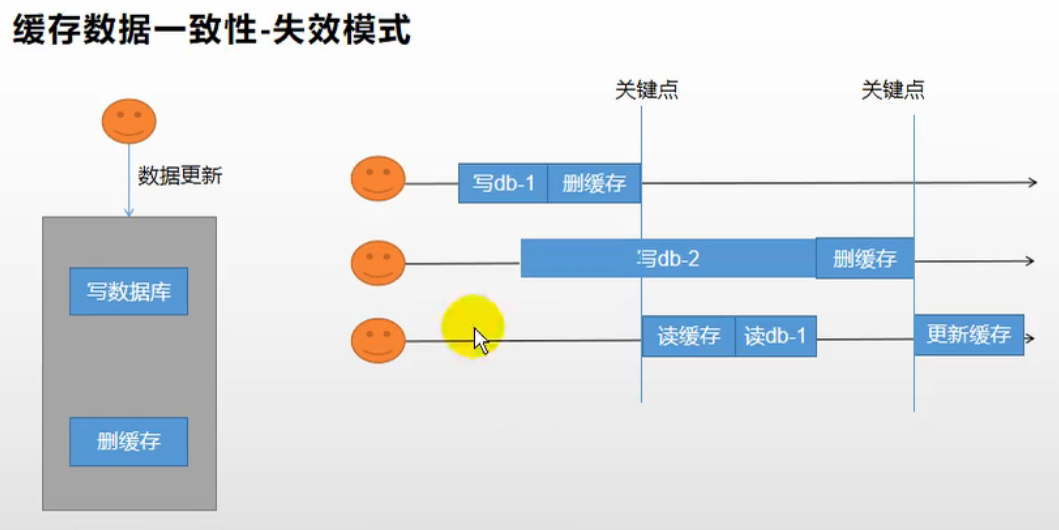
2.1.2 方式二:失效模式
这种方式是指,当数据库的数据出现变更时,就将缓存中对应的数据删除,让下次请求同样的数据时直接去数据库去读取最新的数据。
但是这种方式同样存在问题,当数据库数据变更之后,线程一发起缓存删除的操作,这时候线程二也变更数据,同时做了删除缓存的操作,当缓存二的删缓存操作还未执行时,线程三突然来读取缓存,这时候就读取到了不正确的数据。
2.2 一致性解决方案
无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数
据加上过期时间,每隔一段时间触发读的主动更新即可
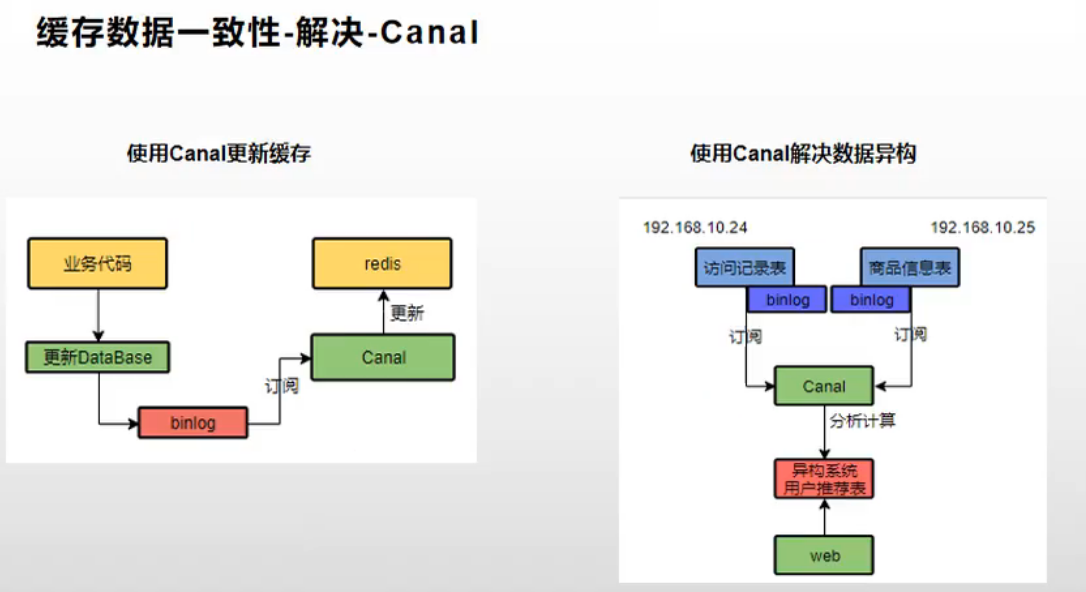
- 如果是菜单,商品介绍等基础数据,也可以去使用cana订阅binlog的方式。
- 缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 通过加锁保证并发读写,写写的时候按顺序排好队。读读无所调。所以适合使用读写锁。(业务不
关心脏数据,允许临时脏数据可忽略);
总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,
保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性。
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。

若有收获,就点个赞吧
0 人点赞
