Flink1.13.6 连接 Hadoop3.1.3的 Yarn 提交任务 依赖
bin/flink run \-t yarn-per-job \-d \-p 5 \-Dyarn.application.queue=default \-Drest.flamegraph.enabled=true \-Djobmanager.memory.process.size=1024mb \-Dtaskmanager.memory.process.size=2048mb \-Dtaskmanager.numberOfTaskSlots=2 \-c com.hao.flink.tuning.UvDemo \/opt/module/flink-1.13.6/jar/flink-turn-1.0-SNAPSHOT.jar
利用Flink UI Web 定位
0-10%是绿色的,是ok的
10%-50%是黄色的,LOW
而超过50%是红色的 则为 HIGH
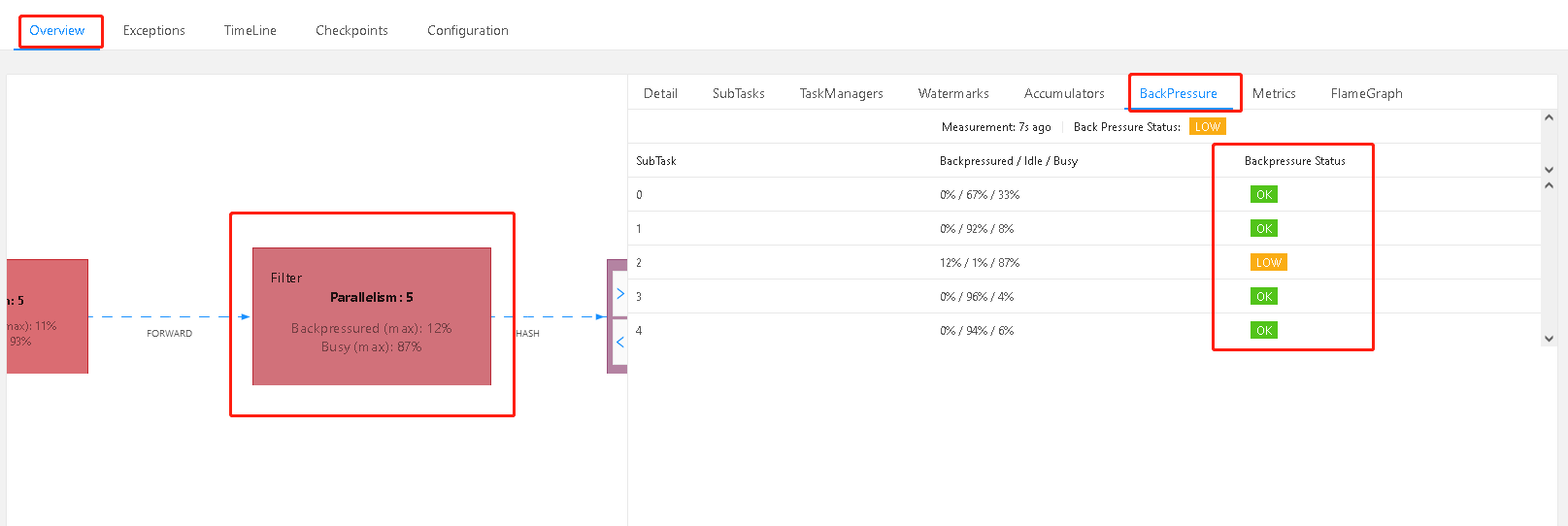
通过 WebUI 看到 Map 算子处于反压:
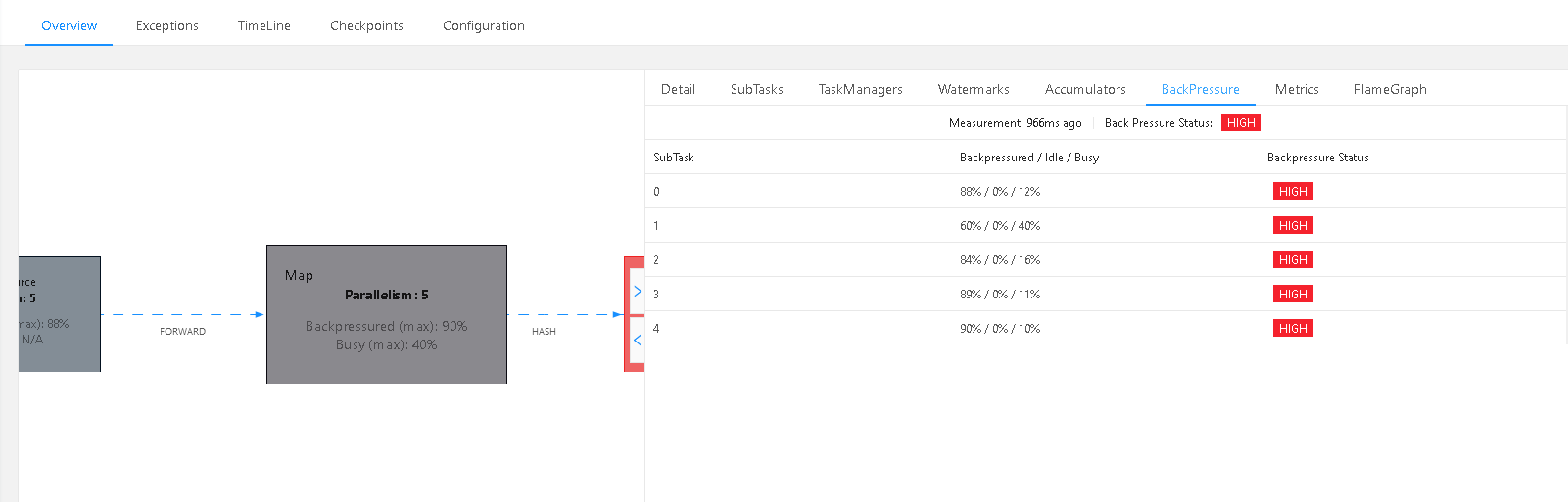
下游能力不行,导致上面被堵死了
第三个算子 能力不行,导致它前面的两个算子导致了反压。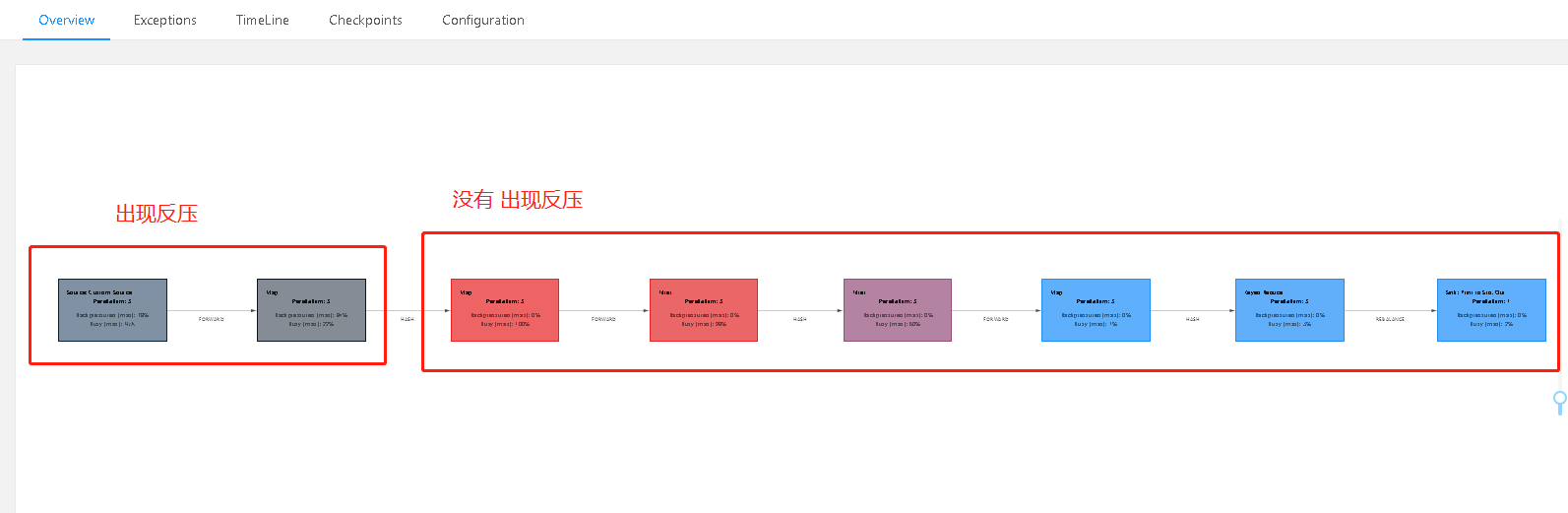
分析瓶颈算子
如果处于反压状态,那么有两种可能性:
(1)该节点的发送速率跟不上它的产生数据速率。这一般会发生在一条输入多条输出的 Operator(比如 flatmap)。这种情况,该节点是反压的根源节点,它是从 Source Task 到 Sink Task 的第一个出现反压的节点。
(这一种可以理解为高速堵车,最前面的车可能是龟速行驶,导致后面的车一直在堵,但前面的车缺一点反应都没有)
(2)下游的节点接受速率较慢,通过反压机制限制了该节点的发送速率。这种情况, 需要继续排查下游节点,一直找到第一个为 OK 的一般就是根源节点。 总体来看,如果我们找到第一个出现反压的节点,反压根源要么是就这个节点,要么是它紧接着的下游节点。 (刚刚图中出现的情况就是第二种)
通常来讲,第二种情况更常见。如果无法确定,还需要结合 Metrics 进一步判断。
利用Metrics定位
监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个 Metrics:
| Metris | 描述 |
|---|---|
| outPoolUsage | 发送端 Buffer 的使用率 |
| inPoolUsage | 接受端 Buffer 的使用率 |
| floatingBuffersUsage(1.9 以上) | 接收端 Floating Buffer 的使用率 |
| exclusiveBuffersUsage(1.9 以上) | 接收端 Exclusive Buffer 的使用率 |
其中 inPoolUsage = floatingBuffersUsage + exclusiveBuffersUsage。
1)根据指标分析反压
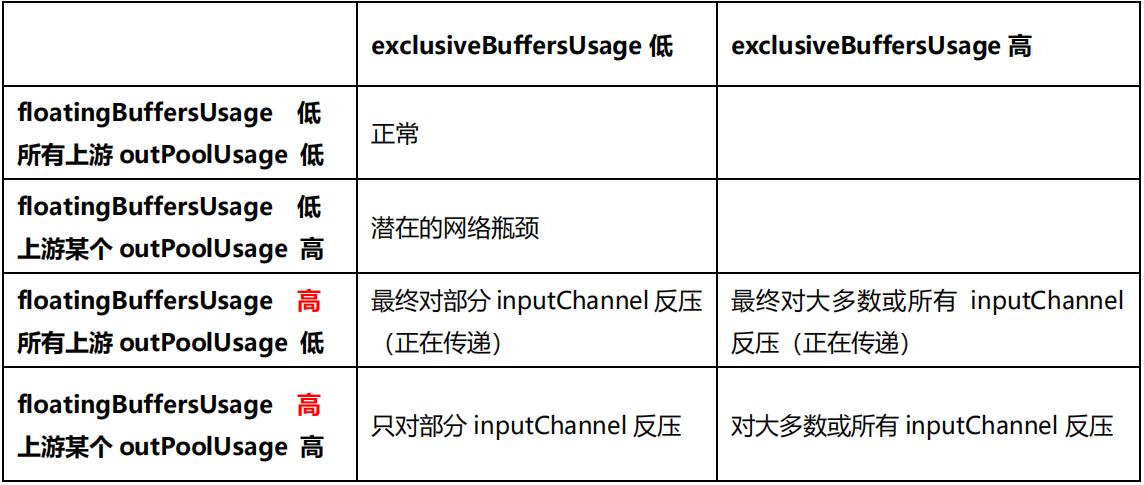
分析反压的大致思路是:如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。反压情况可以根据以下表格进行对号入座(1.9 以上):
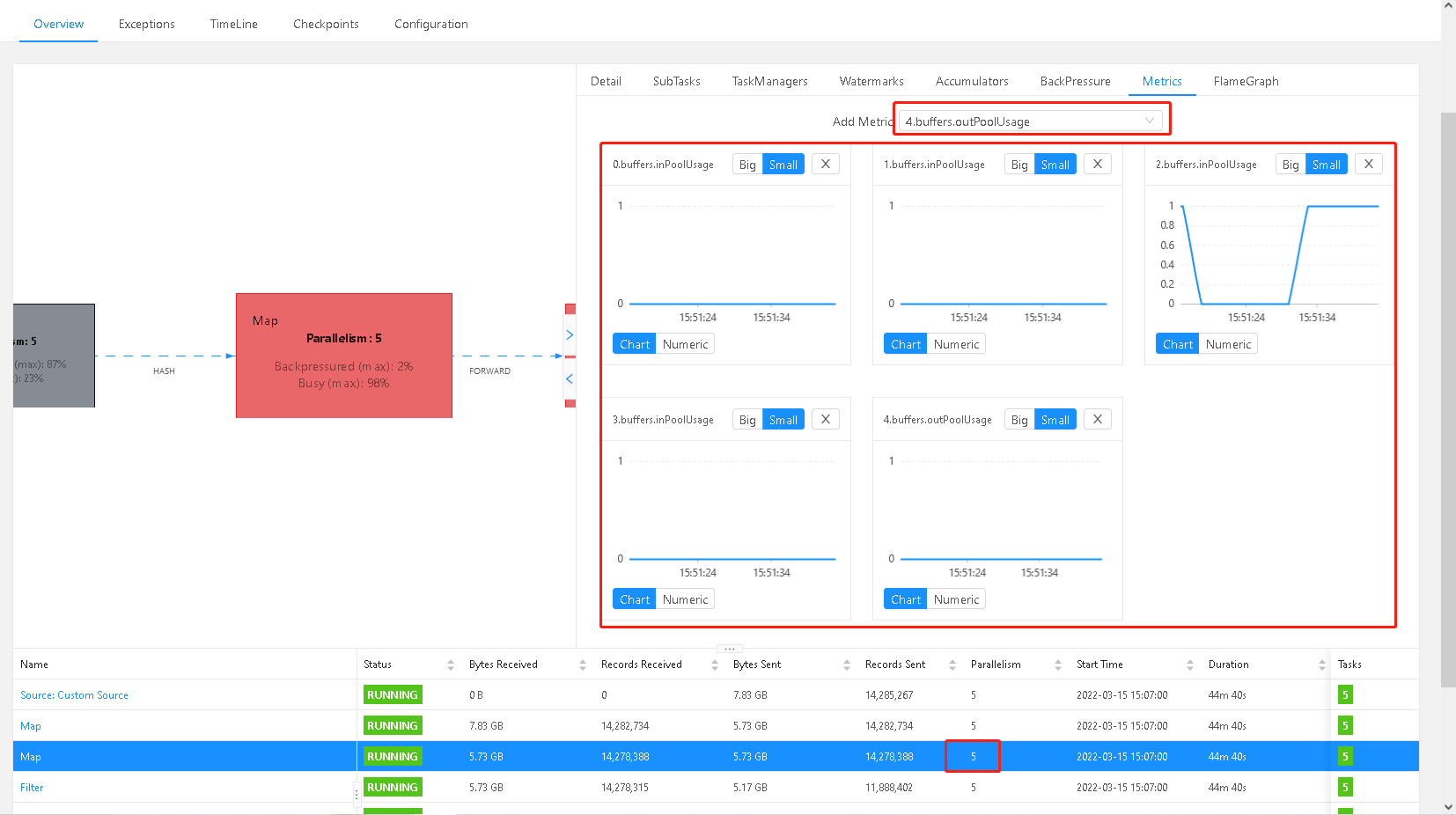
编号2接收端的使用率比较高,已经到达了瓶颈了,之后编号2的发送端的是使用率也已经到达了瓶颈了,至少是说,就是第三个算子的问题,而导致的反压问题。
1)根据指标分析反压
分析反压的大致思路是:如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。反压情况可以根据以下表格进行对号入座(1.9 以上):

2)可以进一步分析数据传输
Flink 1.9及以上版本,还可以根据 floatingBuffersUsage/exclusiveBuffersUsage 以及其上游 Task 的 outPoolUsage 来进行进一步的分析一个 Subtask 和其上游
Subtask 的数据传输。
在流量较大时,Channel 的 Exclusive Buffer 可能会被写满,此时 Flink 会向 Buffer Pool 申请剩余的 Floating Buffer。这些 Floating Buffer 属于备用 Buffer。
总结:
1)floatingBuffersUsage 为高,则表明反压正在传导至上游
2)同时 exclusiveBuffersUsage 为低,则表明可能有倾斜
比如,floatingBuffersUsage 高、exclusiveBuffersUsage 低为有倾斜,因为少数 channel 占用了大部分的 Floating Buffer。

若有收获,就点个赞吧
0 人点赞
