1,倾斜 2,资源不够 3,GC
注意:反压可能是暂时的,可能是由于负载高峰、CheckPoint 或作业重启引起的数据积压而导致反压。如果反压是暂时的,应该忽略它。另外,请记住,断断续续的反压会影响我们分析和解决问题。
定位到反压节点后,分析造成原因的办法主要是观察 Task Thread。按照下面的顺序,一步一步去排查。
1,查看是否数据倾斜
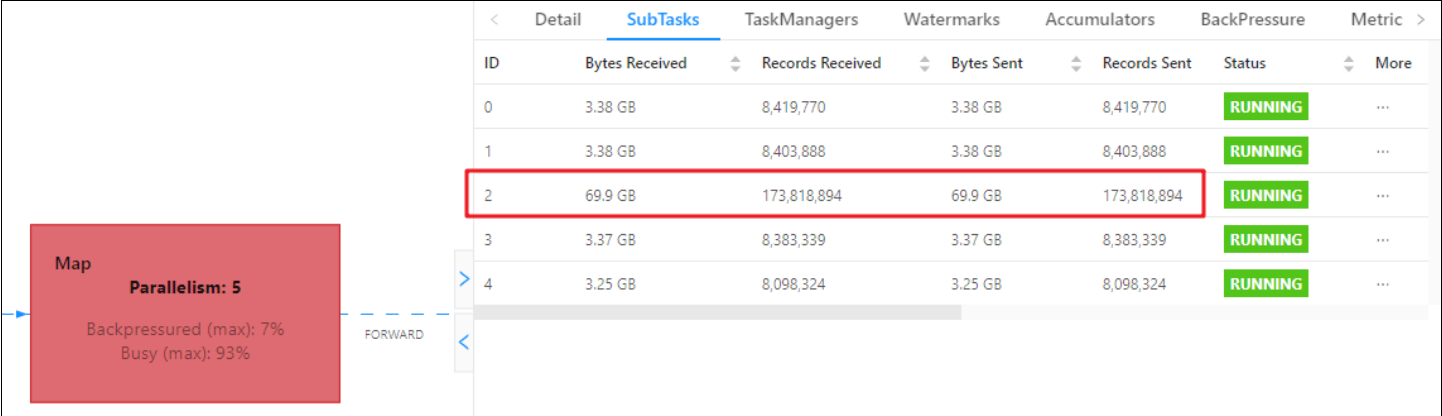
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
2,使用火焰图分析
如果不是数据倾斜,最常见的问题可能是用户代码的执行效率问题(频繁被阻塞或者性能问题),需要找到瓶颈算子中的哪部分计算逻辑消耗巨大。
最有用的办法就是对 TaskManager 进行 CPU profile,从中我们可以分析到 Task Thread 是否跑满一个 CPU 核:如果是的话要分析 CPU 主要花费在哪些函数里面;
如果不是的话要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是 checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
1)开启火焰图功能
Flink 1.13 直接在 WebUI 提供 JVM 的 CPU 火焰图,这将大大简化性能瓶颈的分析,默认是不开启的,需要修改参数:
rest.flamegraph.enabled: true #默认 false
也可以在提交时指定:
bin/flink run \ -t yarn-per-job \ -d \ -p 5 \ -Drest.flamegraph.enabled=true \ -Dyarn.application.queue=test \ -Drest.flamegraph.enabled=true \ -Djobmanager.memory.process.size=1024mb \ -Dtaskmanager.memory.process.size=2048mb \ -Dtaskmanager.numberOfTaskSlots=2 \ -c com.hao.flink.tuning.UvDemo \ /opt/module/flink-1.13.6/jar/flink-turn-1.0-SNAPSHOT.jar
2)WebUI 查看火焰图
找最上面之间最长的 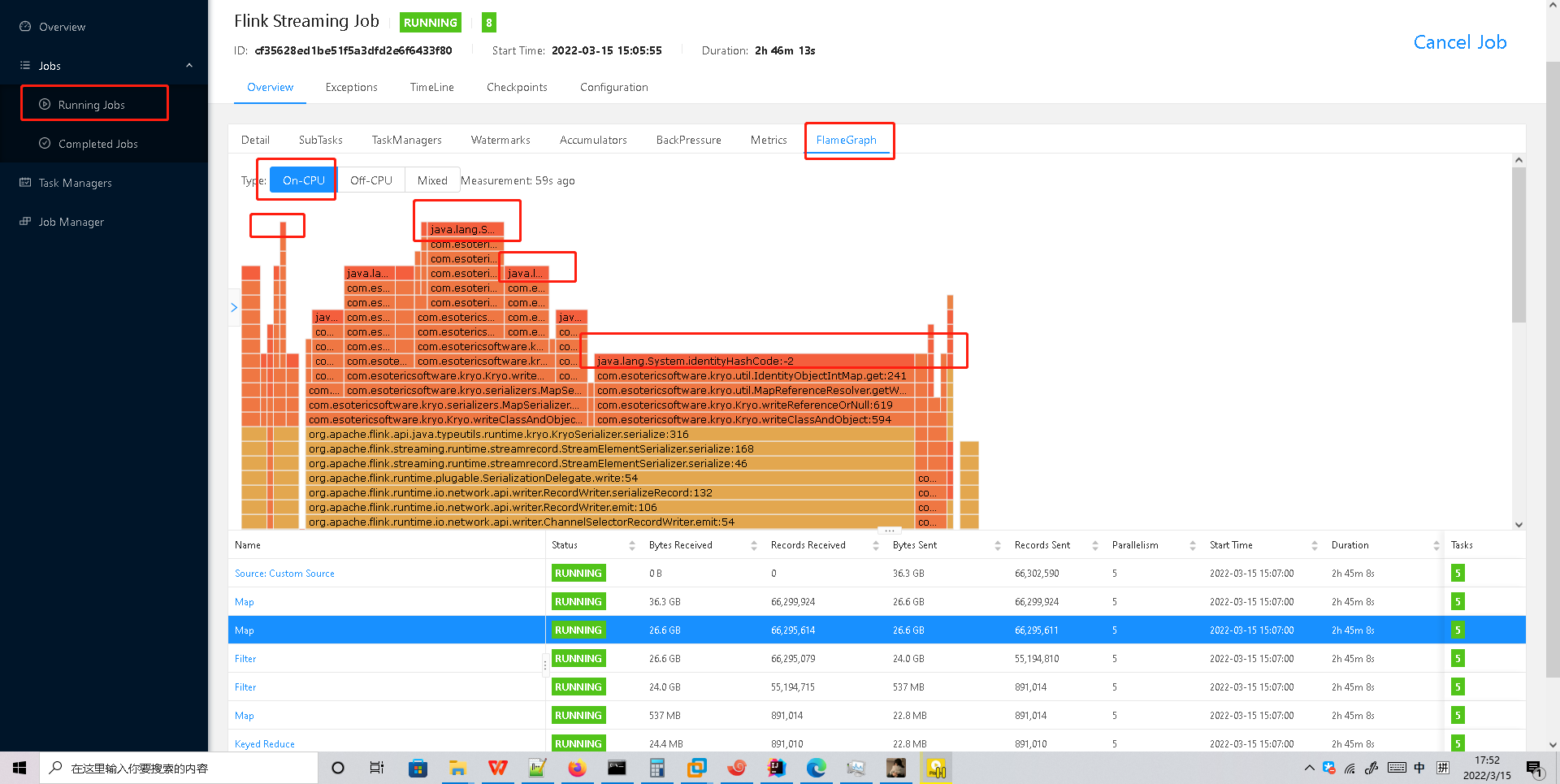
等待中的堵塞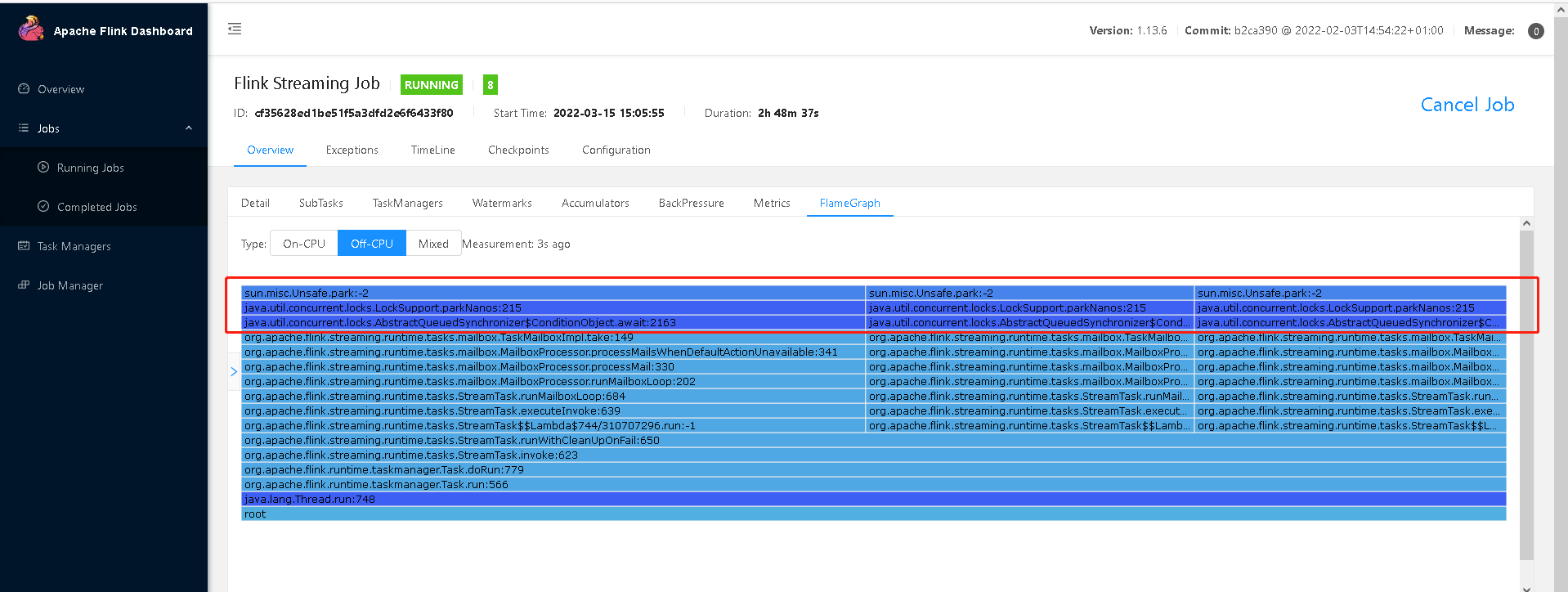
火焰图是通过对堆栈跟踪进行多次采样来构建的。每个方法调用都由一个条形表示,其中条形的长度与其在样本中出现的次数成正比。
➢ On-CPU: 处于 [RUNNABLE, NEW]状态的线程
➢ Off-CPU: 处于 [TIMED_WAITING, WAITING, BLOCKED]的线程,用于查看在样本中发现的阻塞调用。
3)分析火焰图
颜色没有特殊含义,具体查看:
➢ 纵向是调用链,从下往上,顶部就是正在执行的函数
➢ 横向是样本出现次数,可以理解为执行时长。
看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。
如果是 Flink 1.13 以前的版本,可以手动做火焰图:
如何生成火焰图:http://www.54tianzhisheng.cn/2020/10/05/flink-jvm-profiler/
分析 GC 情况
首先第一步,要打印日志信息,
TaskManager 的内存以及 GC 问题也可能会导致反压,包括 TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。通常建议使用默认的 G1 垃圾回收器。
可以通过打印 GC 日志(-XX:+PrintGCDetails),使用 GC 分析器(GCViewer 工具)来验证是否处于这种情况。
➢ 在 Flink 提交脚本中,设置 JVM 参数,打印 GC 日志:
bin/flink run \ -t yarn-per-job \ -d \ -p 5 \ -Drest.flamegraph.enabled=true \ -Denv.java.opts=”-XX:+PrintGCDetails -XX:+PrintGCDateStamps” \ -Dyarn.application.queue=default \ -Djobmanager.memory.process.size=1024mb \ -Dtaskmanager.memory.process.size=2048mb \ -Dtaskmanager.numberOfTaskSlots=2 \ -c com.hao.flink.tuning.UvDemo \ /opt/module/flink-1.13.6/jar/flink-turn-1.0-SNAPSHOT.jar
查看日志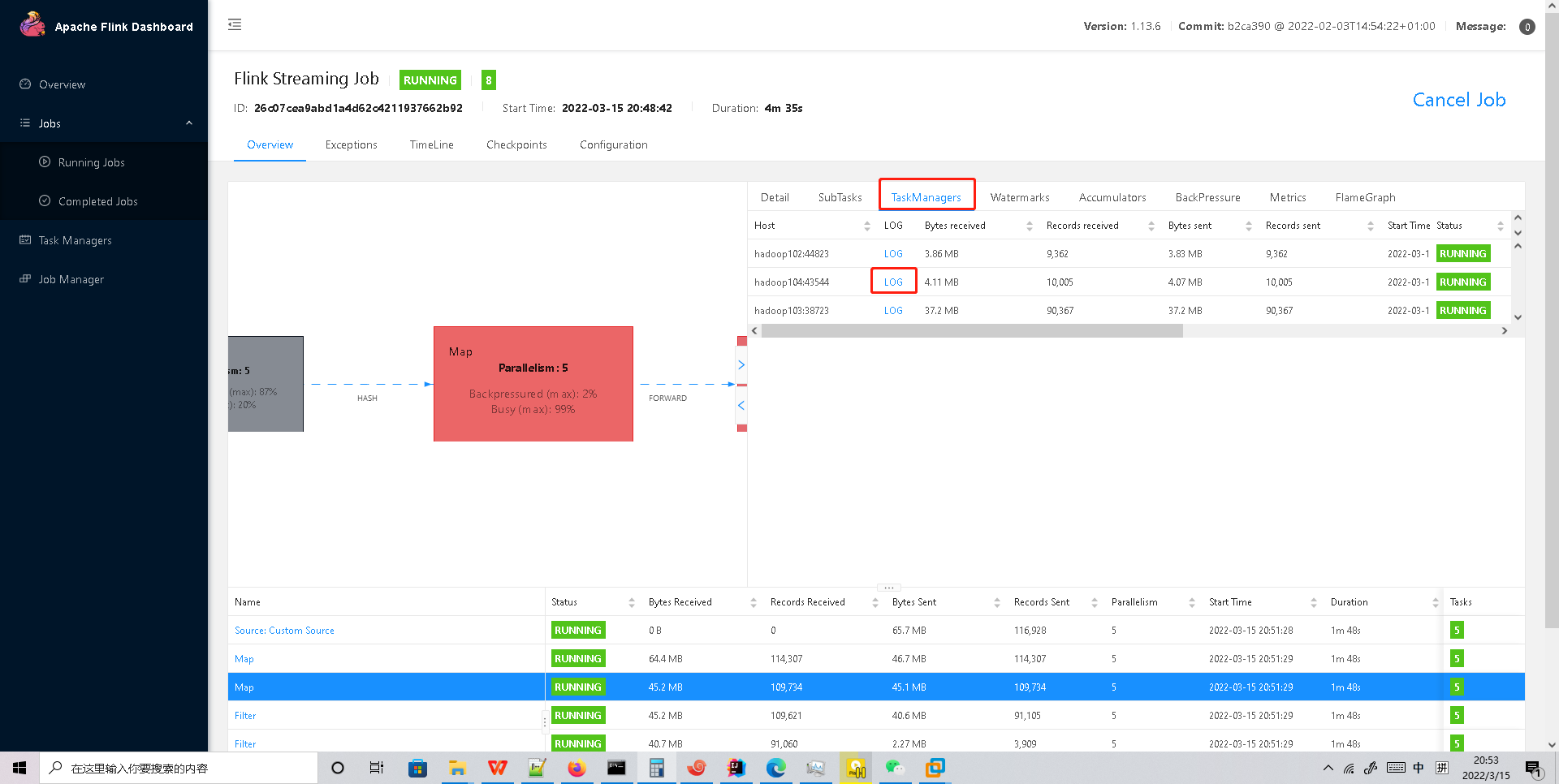
默认日志看这里 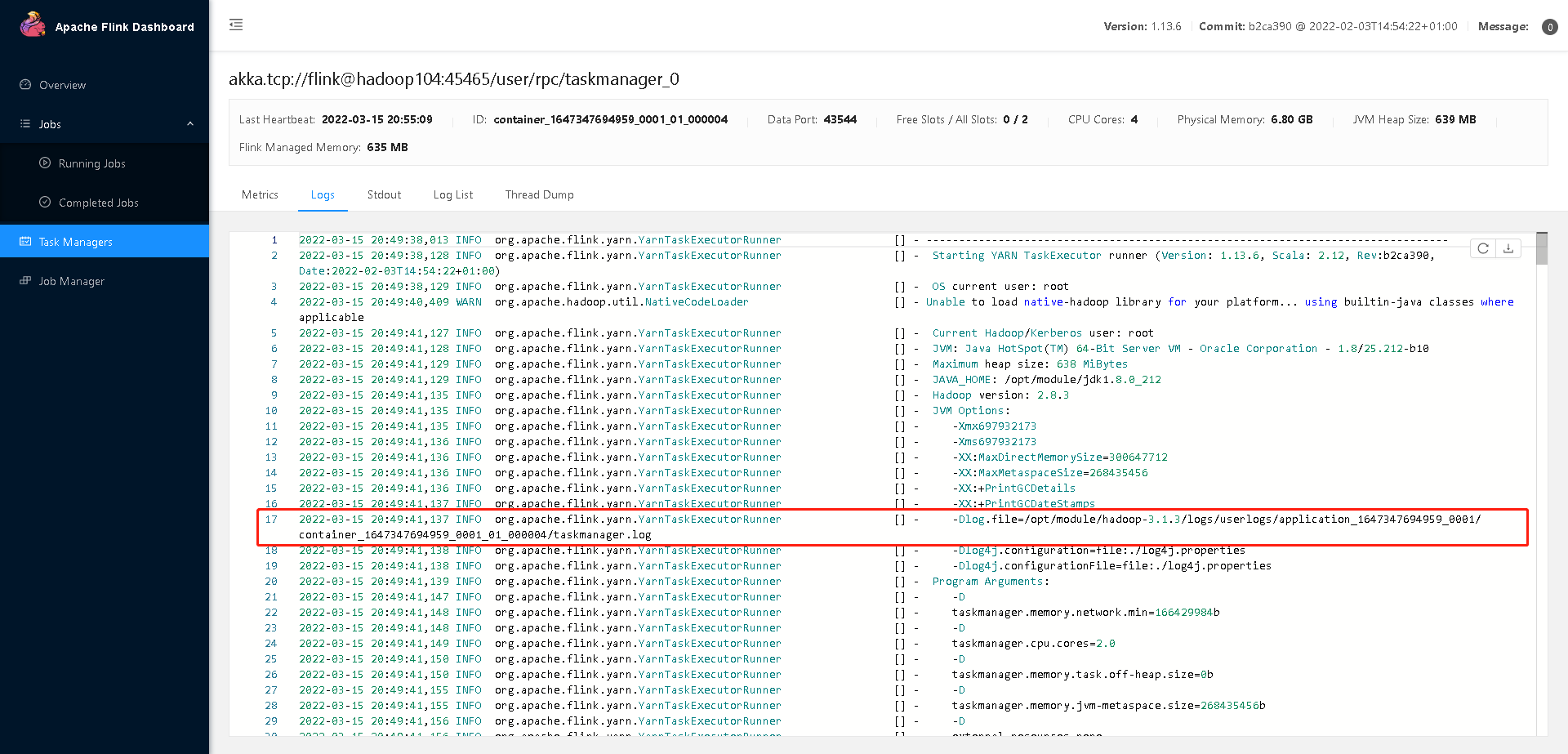
如果没有默认日志的话,也不用着急,
➢ 下载 GC 日志的方式:
因为是 on yarn 模式,运行的节点一个一个找比较麻烦。可以打开 WebUI,选择 JobManager 或者 TaskManager,点击 Stdout,即可看到 GC 日志,点击下载按钮即可 将 GC 日志通过 HTTP 的方式下载下来。
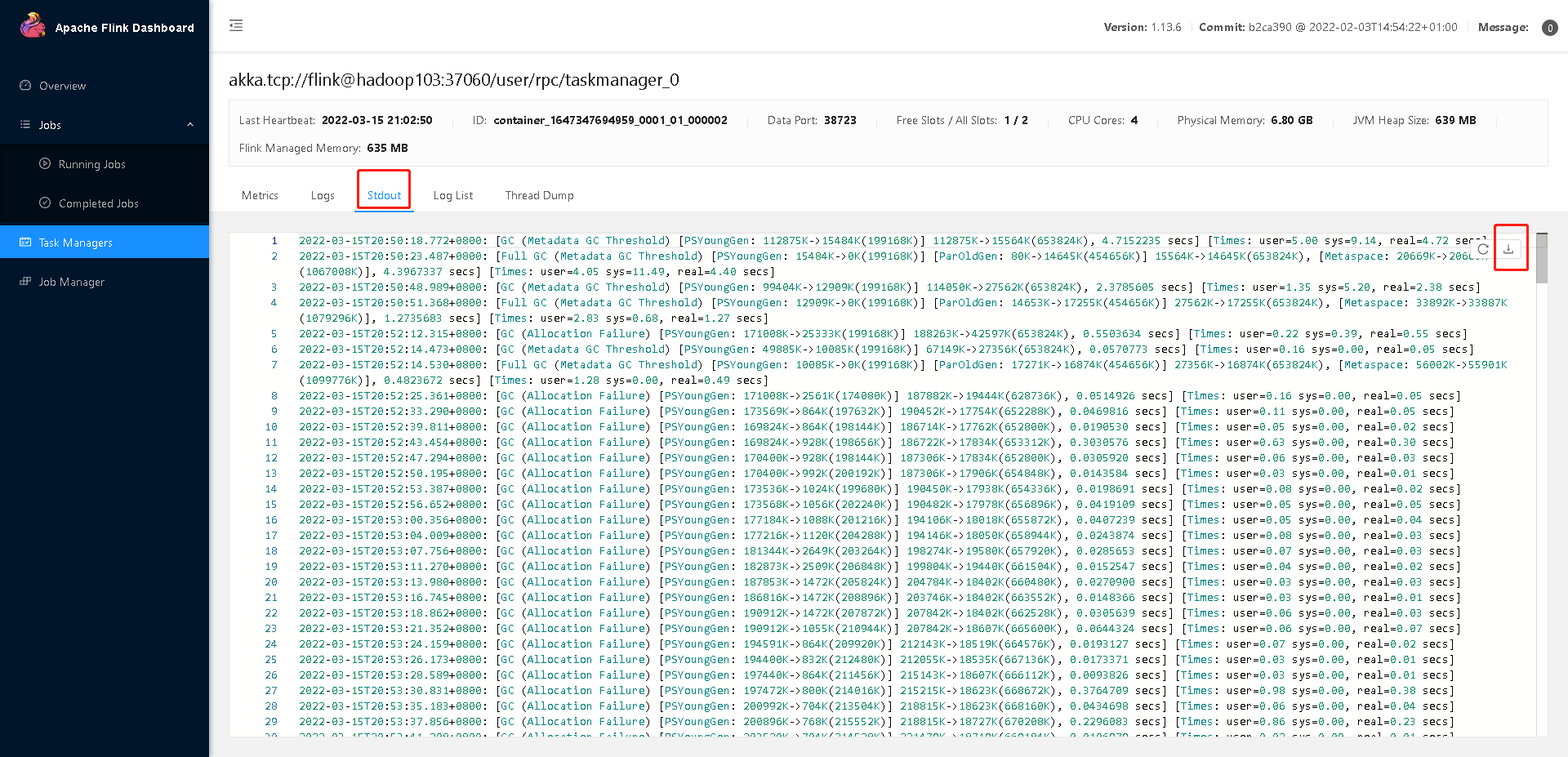
分析 GC 日志:
通过 GC 日志分析出单个 Flink Taskmanager 堆总大小、年轻代、老年代分配的内存空间、Full GC 后老年代剩余大小等,相关指标定义可以去 Github 具体查看。
GCViewer 地址:https://github.com/chewiebug/GCViewer
Linux 下分析:
java -jar gcviewer_1.3.4.jar gc.log
Windows 下分析:
直接双击 gcviewer_1.3.4.jar,打开 GUI 界面,选择 gc 的 log 打开
扩展:最重要的指标是 Full GC 后,老年代剩余大小这个指标,按照《Java 性能优化权威指南》这本书 Java 堆大小计算法则,设 Full GC 后老年代剩余大小空间为 M,那么堆的大小建议 3 ~ 4 倍 M,新生代为 1 ~ 1.5 倍 M,老年代应为 2 ~ 3 倍 M。
gcviewer 工具教学 : https://www.e-learn.cn/tag/gcviewer
外部组件交互
如果发现我们的 Source 端数据读取性能比较低或者 Sink 端写入性能较差,需要检查第三方组件是否遇到瓶颈,还有就是做维表 join 时的性能问题。
例如:
Kafka 集群是否需要扩容,Kafka 连接器是否并行度较低
HBase 的 rowkey 是否遇到热点问题,是否请求处理不过来
ClickHouse 并发能力较弱,是否达到瓶颈
……
关于第三方组件的性能问题,需要结合具体的组件来分析,最常用的思路:
1)异步 io+热缓存来优化读写性能
2)先攒批再读写
维表 join 参考:
https://flink-learning.org.cn/article/detail/b8df32fbc6542257a5b449114e137cc3
https://www.jianshu.com/p/a62fa483ff54

若有收获,就点个赞吧
0 人点赞
