1. 前言
我们上节课讲到的一些node embedding的方法,node embedding的方法有两个关键的部分——encoder(编码器)和similarity function(相似函数计算)。然而,上节课提到的一些encoder的方法实质上都是shallow embedding,这些方法都有一些局限性:
- 需要O(∣V∣)O(|V|)O(∣V∣)个参数,节点之间的参数无法共享,每个节点都有自己的embedding。
- 转换的过程是确定的,对于未知节点(没有出现过的节点),没有办法生成它们的embedding。
- 并不能很好地利用节点的特性。
这节课的内容基于图神经网络(Graph neural networks)来展开一些deep methods(deep graph encoders),即
ENC(v)=multiple layers of non-linear transformations of graph structureENC(v)= \text{multiple layers of non-linear transformations of graph structure}ENC(v)=multiple layers of non-linear transformations of graph structure
这节课讲到的deep graph encoders可以和上节课讲到的similarity function结合起来使用。
我们前面也提到,现在的深度学习框架主要适用于规则的网格和序列,而相比于这些,网络通常是复杂的、无序的、动态的,这就导致很难直接将现在的深度学习框架直接应用于网络上。
但是,我们同样可以从现在的深度学习框架中得到启发。
1.1 From image to graph
CNN on image
我们可以从图像的卷积神经网络(关于卷积神经网络可以看【深度学习实战】从零开始深度学习(三):卷积神经网络与计算机视觉)的思想得到启发。
在卷积神经网络的卷积层,会有一个滑动滤波器沿着像素滑动,捕获图片信息。在网络中也可以这样,可以有一个“滑动滤波器”,对于节点来说,捕获节点接收到的其他邻居节点传来的消息hihi_h__i,最后进行求和,即∑iWihi\sumi W_i h_i∑_iWihi。
对于上面的右图来说,可以直接将“滑动滤波器”应用到网络上,而对于下面这两个更加复杂的真实网络,怎样去应用CNN的思想呢?
1.2 一个简单的想法
一个最简单的想法,就是将“滑动滤波器”应用于邻接矩阵上,将滤波器得到的结果作为深度神经网络的输入,最后训练得到输出。
但是,这个想法存在很明显的不足:
(1)首先,神经网络的输入层包含O(N)O(N)O(N)个参数,且随着网络规模的增加,参数会不断增加,使得神经网络的工作效率很低;
(2)其次,当网络的规模发生变化时(比如从6个节点的网络变成7个节点的网络),模型得重新训练;
(3)第三,网络节点的编号一发生变化,邻接矩阵就会发生变化,模型将不适用。
因此,我们今天这节课主要讲解下面这几个内容:
- Basics of deep learning for graphs
- Graph Convolutional Networks
- Graph Attention Networks (GAT)
-
2. Basics of deep learning for graphs
2.1 Graph Convolutional Networks 的计算图
假设有图$G:
VVV是节点集合(vertex set)
- AAA是邻接矩阵
- X∈Rm×∣V∣X \in \Bbb{R}^{m \times |V|}X∈Rm×∣V∣是节点的特征矩阵(a matrix of node features)。这里的节点特征,根据不同的网络有不同的定义——如在社交网络里面,节点特征就包括用户资料、用户年龄等;在生物网络里面,节点的特征就包括基因表达、基因序列等;如果节点没有特征,就可以用one-hot编码或者Vector of constant 1: [1,1,…,1][1, 1, …, 1][1,1,…,1]来表示节点的特征。
需要应用GCN,我们首先要定义GCN的计算图(感觉类似于CNN中的“滑动滤波器”),这个计算图不仅能保留图GGG的结构,同时还能合并节点的相邻特性。从信息传播的角度来看,节点的邻居确定了节点的计算图(Node’s neighborhood defines a computation graph)。
那么,要得到这个计算图,我们需要学习的就是信息在图中如何传播,从而计算节点的特征(Learn how to propagate information across the graph to compute node features)。
一个想法——Aggregate Neighbours,核心思想在于基于局部网络连接来生成Node embeddings(Generate node embeddings based on local network neighborhoods)。如下面这个图:
例如图中节点A的embedding决定于其邻居节点{B,C,D}{B,C,D}{B,C,D},而这些节点又受到它们各自的邻居节点的影响。图中的“黑箱”可以看成是整合其邻居节点信息的操作,它有一个很重要的属性——其操作应该是顺序(order invariant)无关的,如求和、求平均、求最大值这样的操作,可以采用神经网络来获取。这样顺序无关的聚合函数符合网络节点无序性的特征,当我们对网络节点进行重新编号时,我们的模型照样可以使用。
那么,对于每个节点来说,它的计算图就由其邻居节点的数量来决定——
模型的深度可以自己定义(Model can be of arbitrary depth):
- Nodes have embeddings at each layer
- Layer-0节点uuu的embedding是其节点特征向量xuxu_x__u
- Layer-K embedding gets information from nodes that
are K hops away,例如Layer-1中B节点的embedding就由Layer-0中节点A的特征向量xAxA_x__A和节点C的特征向量xCxC_x__C经过神经网络计算得到。
那么,不同方法之间的区别在于“黑箱”里面到底选择怎样的计算函数。

2.2 模型——Deep Encoder
基于上述思想,我们可以给出Deep encoder的数学表达式:
首先,hkvhv^k_hvk表示节点vvv在第kkk层的embedding。Layer-0节点vvv的embedding是其节点特征向量xvxv_x__v,因此h0v=xvhv^0=x_v_hv_0=_xv。节点vvv在第kkk层的embedding通过其k−1k-1k−1层的邻居节点的embedding由神经网络计算得到。我们最后得到的节点的特征向量为最后一层,即第KKK层的输出。
2.3 模型训练
上面给出了deep encoder的模型,我们需要训练的参数是WkWk_W__k和BkBk_B__k。和传统的机器学习一样,我们需要定义损失函数来帮助训练模型。
我们可以看到,如果参数WkWk_W__k接近于零,那么hkv≈σ(Bkhk−1v)hv^k \approx \sigma(B_k h_v^{k-1})_hvk≈σ(Bkhvk−1),那整个训练过程相当于就是在学习节点自身的特征,而没有考虑邻居节点(网络结构对它的影响)。如果参数BkBk_B__k接近于零,那么hkv≈σ(Wk∑u∈N(v)hk−1u∣N(v)∣)hv^k \approx \sigma(W_k \sum{u \in N(v)} \frac {hu^{k-1}}{|N(v)|})_hvk≈σ(W__k∑u∈N(v)∣N(v)∣huk−1),那么模型就忽略了节点自身的特征。因此,我们需要模型能够平衡“个人特色”和“周围连接”这两者之间的关系。可以根据具体的应用,选择损失函数,应用随机梯度下降法进行优化。
我们可以将上面的数学表达式等价地写成矩阵形式:
H(l+1)=σ(H(l)W(l)0+A˜H(l)W(l)1H^{(l+1)}=\sigma(H^{(l)} W0^{(l)} + \tilde{A} H^{(l)} W_1^{(l)}_H(l+1)=σ(H(l)W_0(_l)+A~H(l)W_1(_l)
A˜=D−12AD−12\tilde{A}=D^{-\frac{1}{2}} A D^{-\frac{1}{2}}A~=D−21AD−21
H(l)=[h(l)T1,⋯,h(l)TN]TH^{(l)}=[h1^{(l)^T},\cdots,h_N^{(l)^T}]^T_H(l)=[h_1(_l)T,⋯,h__N(l)T]T
无监督训练
无监督训练的方法和上节课的思想一样——“Similar” nodes have similar embeddings,无监督训练只依靠节点自身的特征和图的结构。无监督训练的损失函数可以从上节课提到的任意一种方法得到——Random walks (node2vec, DeepWalk, struc2vec)、Graph factorization、Node proximity in the graph等等。
有监督训练
有监督训练的损失函数和具体的任务相关。比如节点分类任务,其损失函数如下:
2.4 模型回顾
| 步骤 | 案例 |
|---|---|
| (1) Define a neighborhood aggregation function |  |
| (2) Define a loss function on the embeddings | |
| (3) Train on a set of nodes, i.e., a batch of compute graphs |  |
| (4) Generate embeddings for nodes as needed |  |
可以看到,相较于1.2节提到的简单的想法,我们这一节提出的模型有很大的优势:
- 所有节点共享相同的聚合参数。模型参数与网络结构无关。

- 模型具有很强的推广性,对于新的图或者图中新的节点同样适用。
3. Graph Convolutional Networks and GraphSAGE
3.1 GraphSAGE Idea
前面提到的模型,在黑箱里面的操作是取平均值。GraphSAGE的想法是采用一个通用的aggregation函数来表示黑箱的运算,可以采用不同的方法聚合其邻居,然后再将其与自身特征拼接。——
hkv=σ([Ak⋅AGG({hk−1u,∀u]∈N(v)}),Bkhk−1v])hv^k=\sigma([A_k \cdot AGG({h_u^{k-1}, \forall u ]\in N(v)}),B_kh_v^{k-1}])_hvk=σ([A__k⋅AGG({huk−1,∀u]∈N(v)}),Bkhvk−1])
常用的聚合函数有以下几种:
| 聚合函数 | 表达式 |
|---|---|
| Mean | 计算邻居节点的加权平均: |
| Pool | 变换邻居向量并运用对称向量函数(式中的\gamma可以是element-wise mean或max)。AGG=γ({Qhk−1n,∀u∈N(v)})AGG=\gamma(\{Qhn^{k-1},\forall u \in N(v)\})_AGG=γ({Qhnk−1,∀u∈N(v)}) |
| LSTM | Apply LSTM to reshuffled of neighbors. AGG=LSTM([hk−1u,∀u∈π(N(v))])AGG=LSTM([hu^{k-1},\forall u \in \pi(N(v))])_AGG=LSTM([huk−1,∀u∈π(N(v))]) |
3.2 小结


3.3 关于GNN的一些论文
| 主题 | 论文 |
|---|---|
| Tutorials and overviews | 1. Relational inductive biases and graph networks (Battaglia et al., 2018), 2. Representation learning on graphs: Methods and applications (Hamilton et al., 2017) |
| Attention-based neighborhood aggregation | Graph attention networks (Hoshen, 2017; Velickovic et al., 2018; Liu et al., 2018) |
| Embedding entire graphs | 1. Graph neural nets with edge embeddings (Battaglia et al., 2016; Gilmer et. al., 2017) 2. Embedding entire graphs (Duvenaud et al., 2015; Dai et al., 2016; Li et al., 2018) and graph pooling (Ying et al., 2018, Zhang et al., 2018) 3. Graph generation and relational inference (You et al., 2018; Kipf et al., 2018) 4. How powerful are graph neural networks (Xu et al., 2017) |
| Embedding nodes | 1. Varying neighborhood: Jumping knowledge networks (Xu et al., 2018), GeniePath (Liu et al., 2018) 2. Position-aware GNN (You et al. 2019) |
| Spectral approaches to graph neural networks | 1. Spectral graph CNN & ChebNet (Bruna et al., 2015; Defferrard et al., 2016) 2. Geometric deep learning (Bronstein et al., 2017; Monti et al., 2017) |
| Other GNN techniques | 1. Pre-Training Graph Neural Networks for Generic Structural Feature Extraction (Hu et al., 2019) 2. GNNExplainer: Generating Explanations for Graph Neural Networks(Ying et al., 2019) |
4. Graph Attention Networks (GAT)
定义avua{vu}_a__vu代表节点uuu传给节点vvv的重要程度。在我们前面提到的模型中: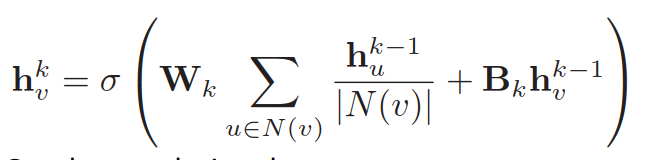
avu=1/∣N(v)∣a{vu}=1/|N(v)|_a__vu=1/∣N(v)∣,avua{vu}_a__vu根据图的结构定义,即节点vvv的所有邻居节点uuu传递的信息对vvv来说是同样重要的。然而,对于一个节点来说,有些邻居节点更加重要,那么,可以采用注意力机制给不同的节点分配权重。
加入注意力机制的首要目标和任务就是指定图中每个节点的不同邻居的任意重要性。
Attention Mechanism 注意力机制
假设参数avua{vu}_a__vu可以通过注意力函数(注意力机制)aaa计算得到,则注意力系数(attention coefficients)evue{vu}_e__vu可以通过两个节点之间的信息流得到(comptue across pairs of nodes based on their messages),evue{vu}_e__vu表示节点uuu的信息对节点vvv的重要性:
evu=a(Wkhk−1u,Wkhk−1v)e{vu}=a(W_k h_u^{k-1},W_k h_v^{k-1})_e__vu=a(Wkhuk−1,Wkhvk−1)
使用softmax函数对系数进行归一化,以便在不同的邻居节点间具有可比性。
avu=exp(euv)∑k∈N(v)exp(evk)a{vu}=\frac {exp(e{uv})}{\sum{k \in N(v)}exp(e{vk})}a__vu=∑k∈N(v)exp(e__vk)exp(e__uv)
hkv=σ(∑u∈N(v)auvWkhk−1u)hv^k=\sigma(\sum{u \in N(v)}a{uv}W_kh_u^{k-1})_hvk=σ(u∈N(v)∑auvWkhuk−1)
那么,注意力机制aaa应该怎么选择呢?可以蚕蛹一层简单的神经网络来作为注意力机制函数,在训练过程中,这层神经网络的相关参数(即注意力机制的相关参数)也会跟着模型一起训练。
下面是关于注意力机制的一些属性:
5. Hand-on Session
这一部分主要是一些在python上的实操。

若有收获,就点个赞吧
0 人点赞
