一、Navigator的安装**
1.1、Navigator数据库创建
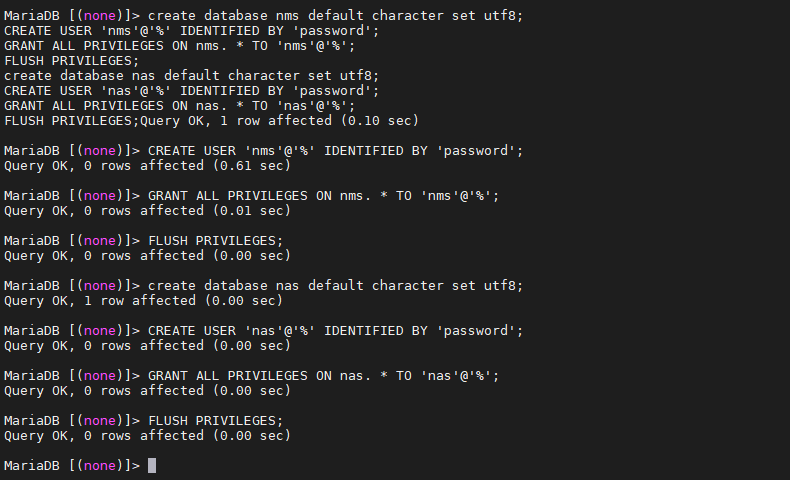
- 创建Navigator元数据库,使用MySQL创建数据库,建库如下:
create database nms default character set utf8;CREATE USER 'nms'@'%' IDENTIFIED BY 'password';GRANT ALL PRIVILEGES ON nms. * TO 'nms'@'%';FLUSH PRIVILEGES;create database nas default character set utf8;CREATE USER 'nas'@'%' IDENTIFIED BY 'password';GRANT ALL PRIVILEGES ON nas. * TO 'nas'@'%';FLUSH PRIVILEGES;
创建MySQL JDBC驱动并创建软链接
cd /usr/share/java/ln -s mysql-connector-java-5.1.34.jar mysql-connector-java.jar
1.2、添加角色
使用管理员登录Cloudera Manager的Web界面,进入Cloudera Management Service服务

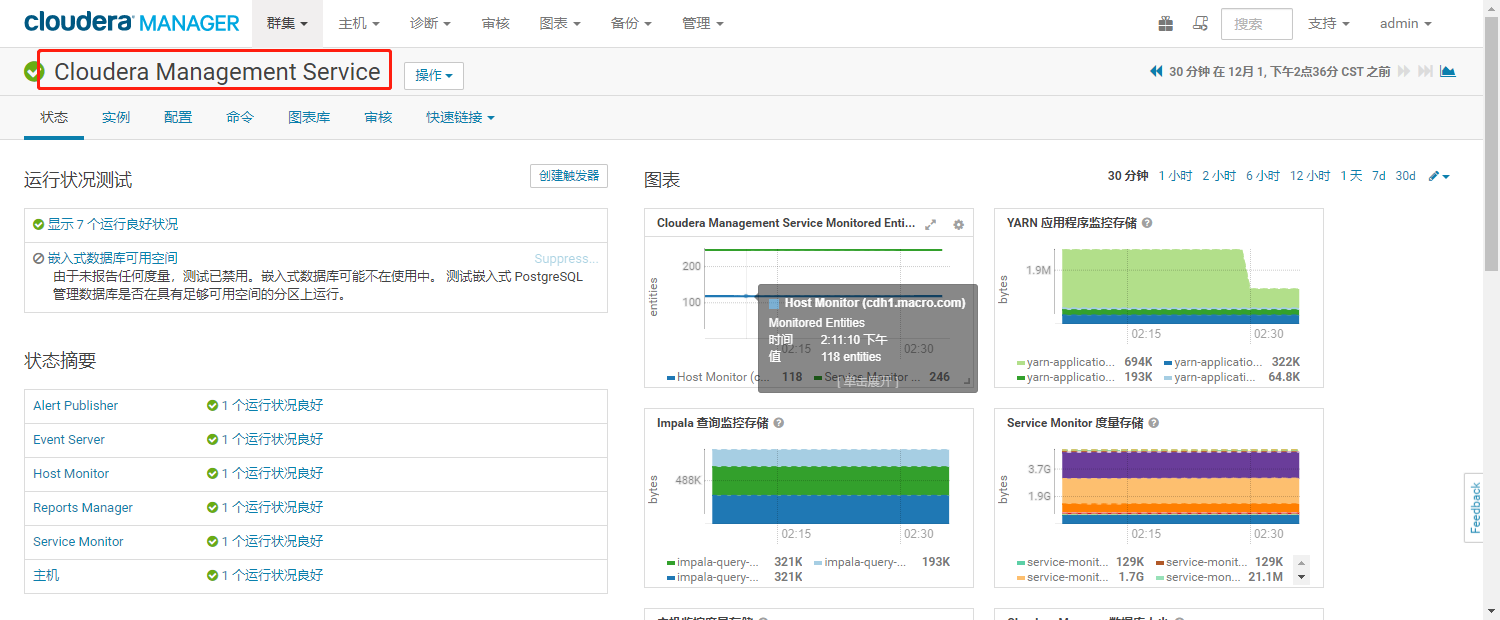
- 点击【实例】,进入实例界面,点击【添加角色实例】
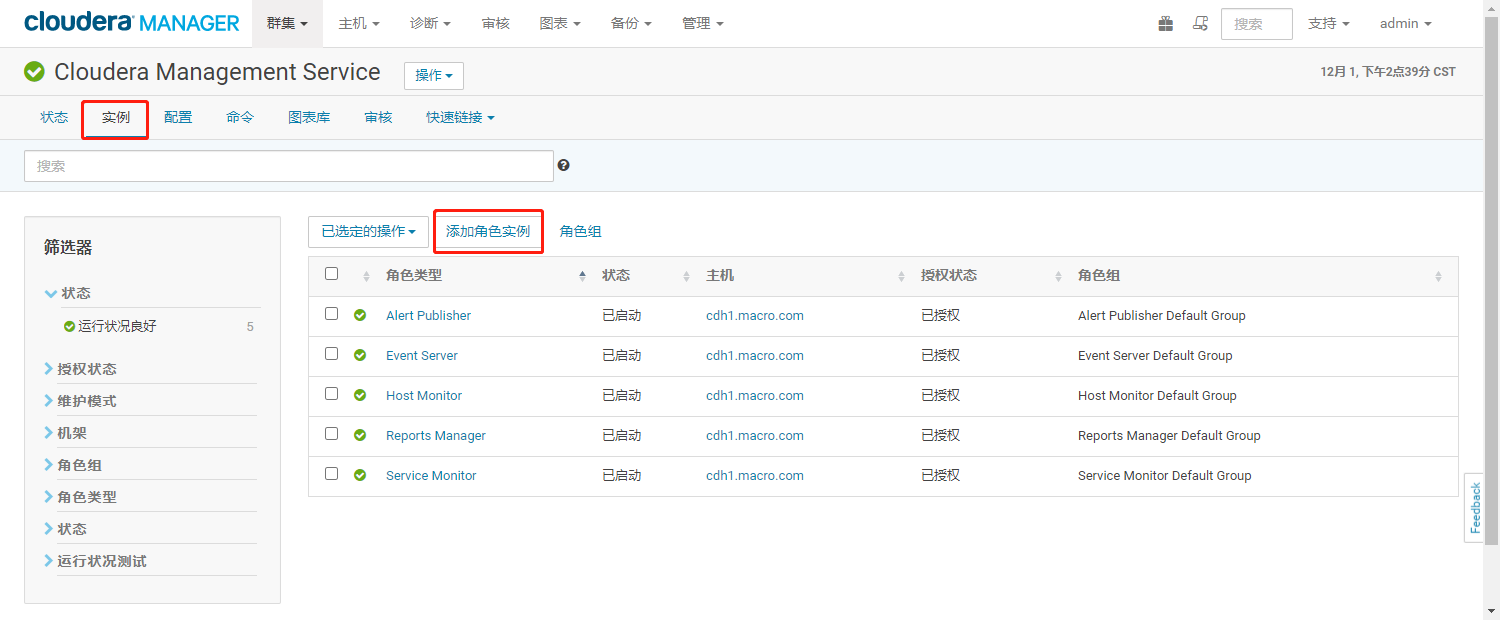
- 选择【Navigator Metadata Server】和【Navigator Audit Server】角色部署的节点

- 输入角色所使用的数据库账号及密码并点击【测试连接】,连接成功点击继续

- 进入实例列表,显示角色已安装成功
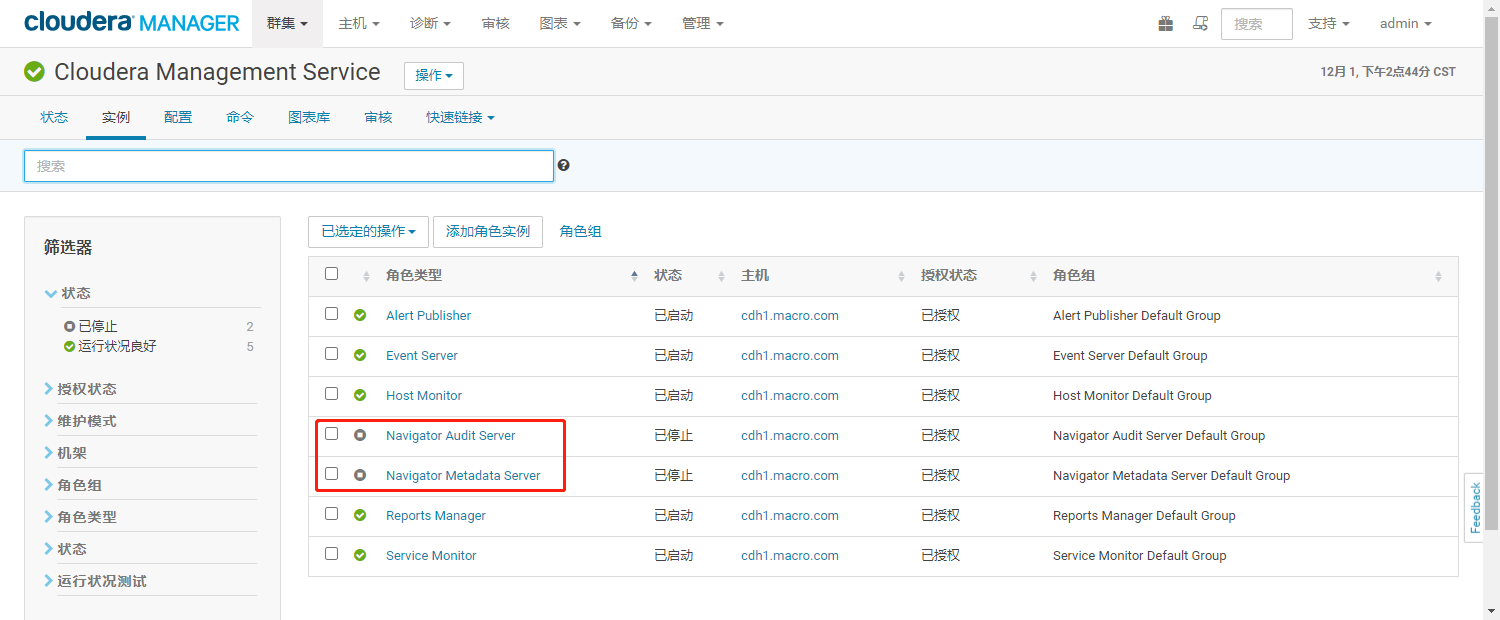
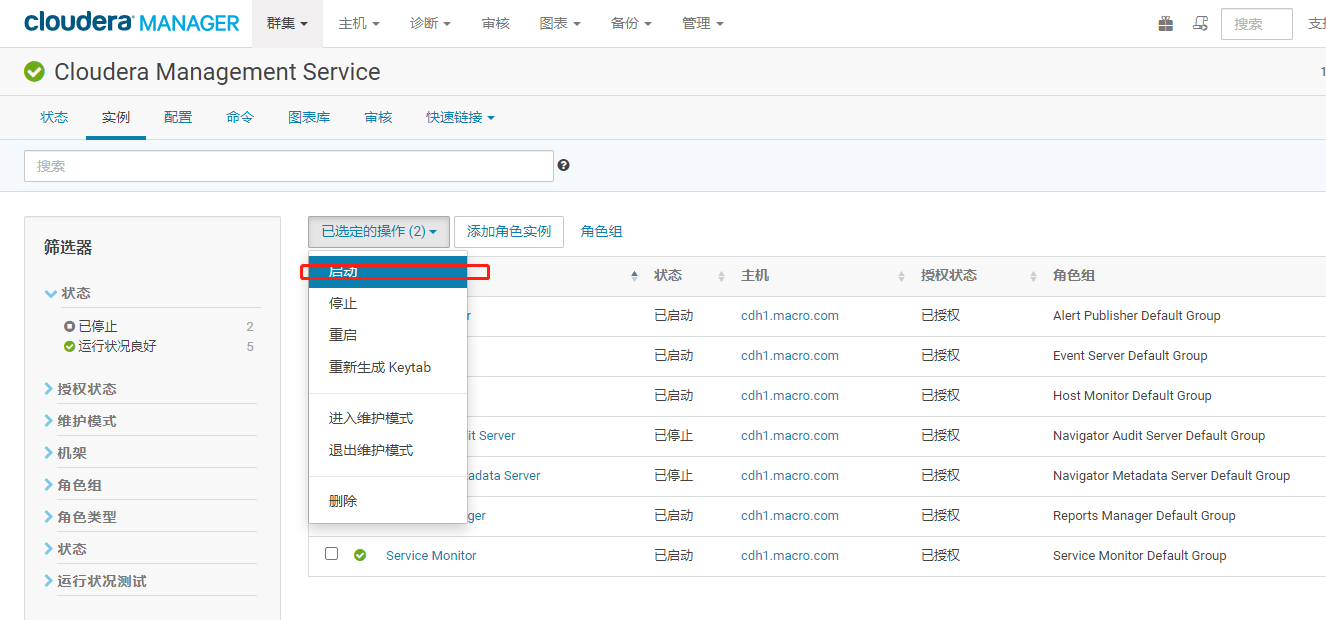
- 选择【Navigator Audit Server】和【Navigator Metadata Server】服务,点击【启动角色】
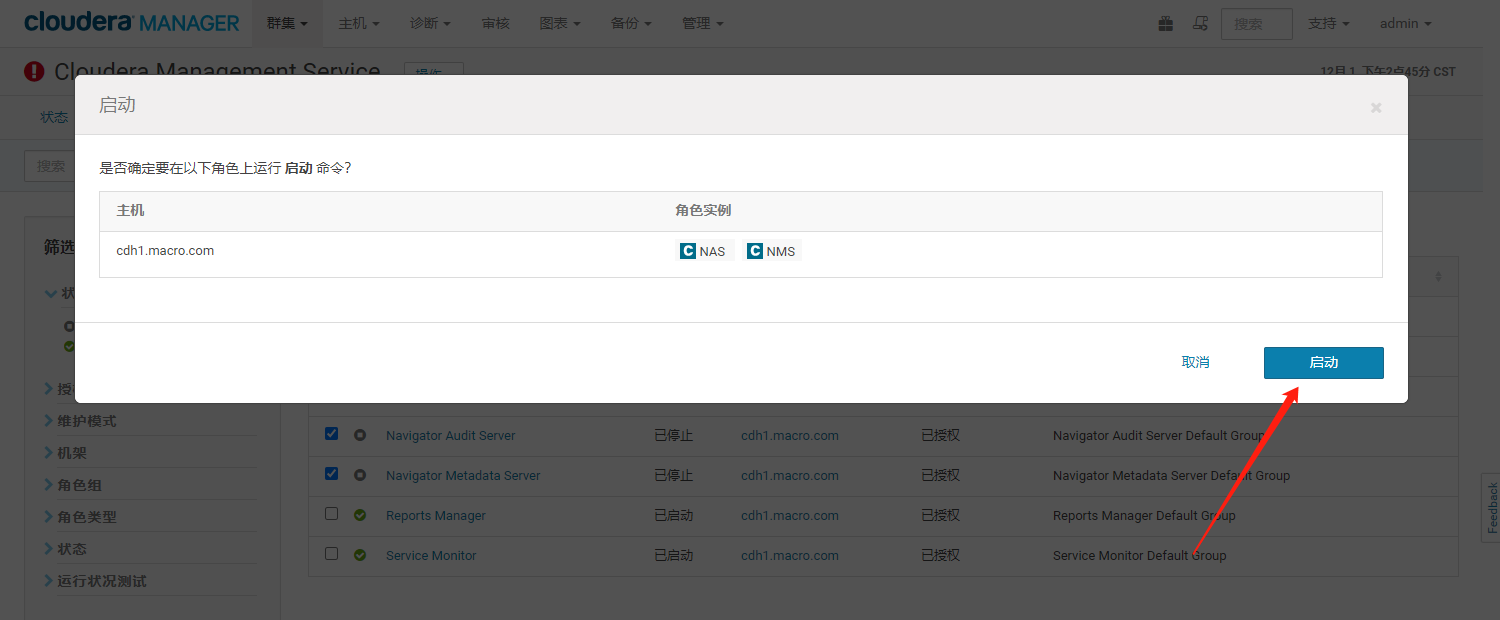
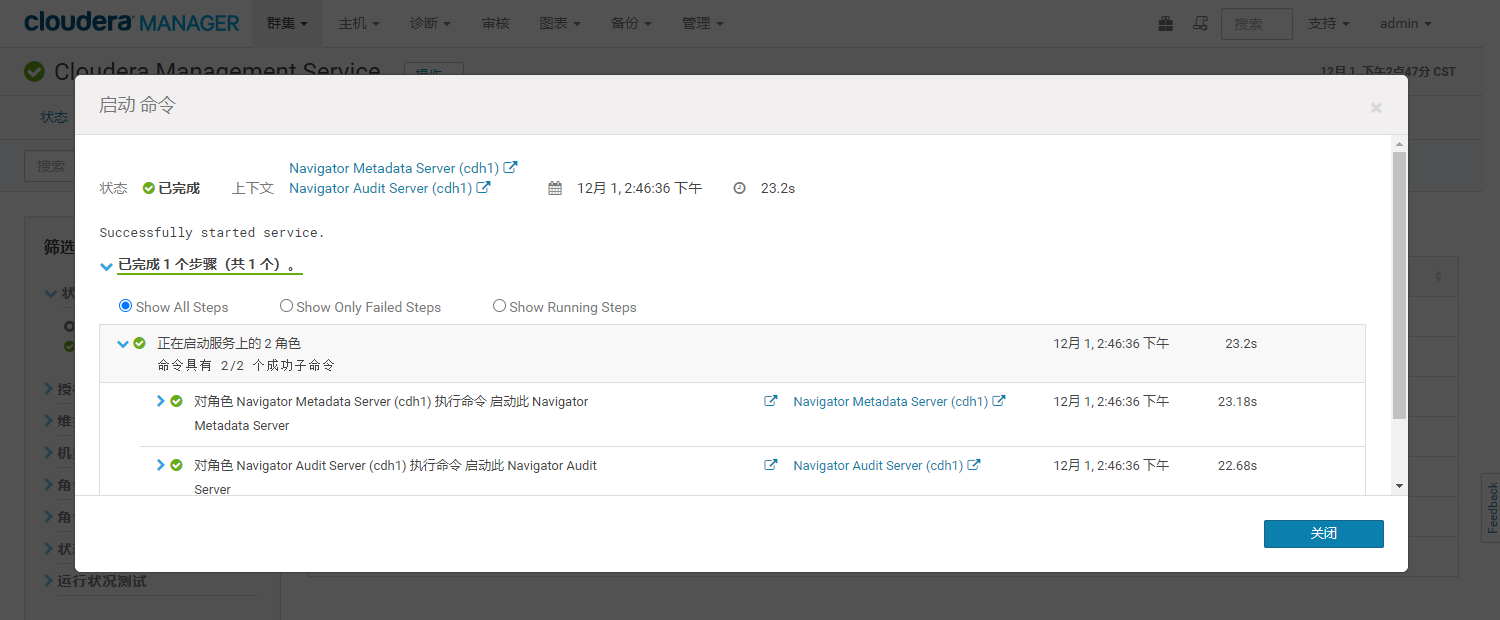
- 等待重启完毕
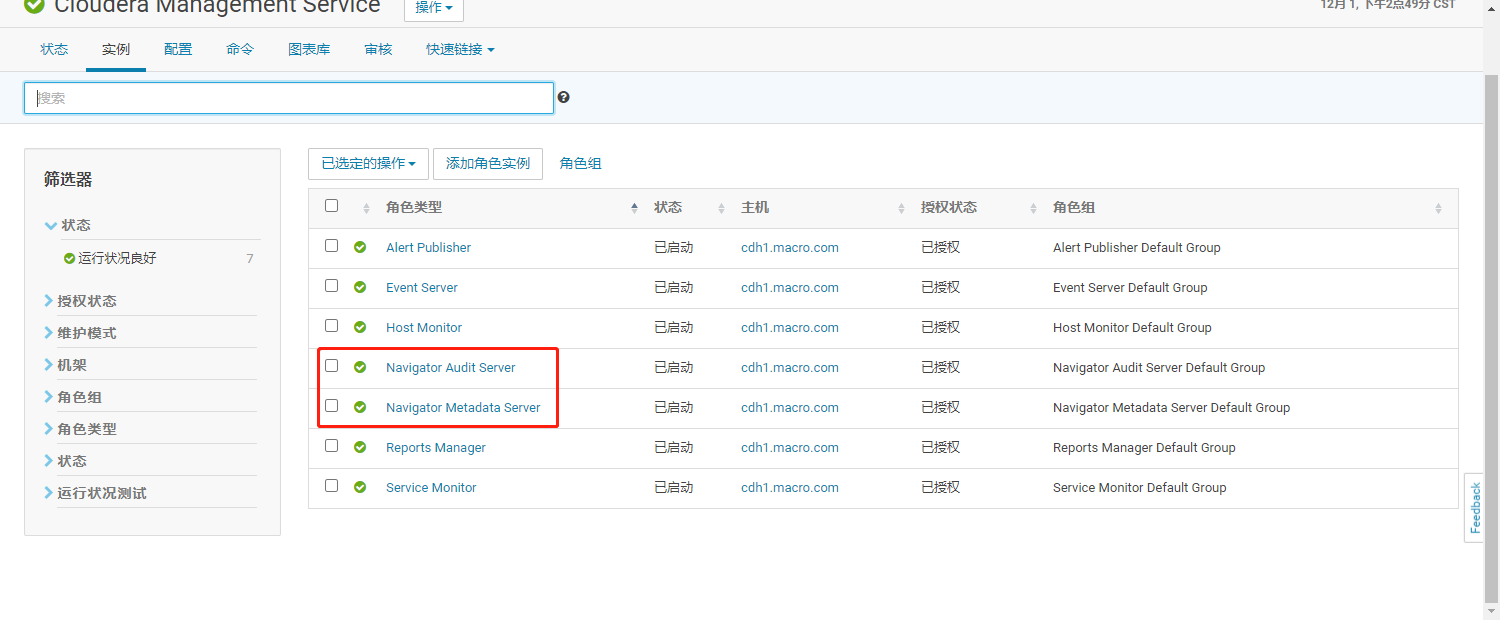
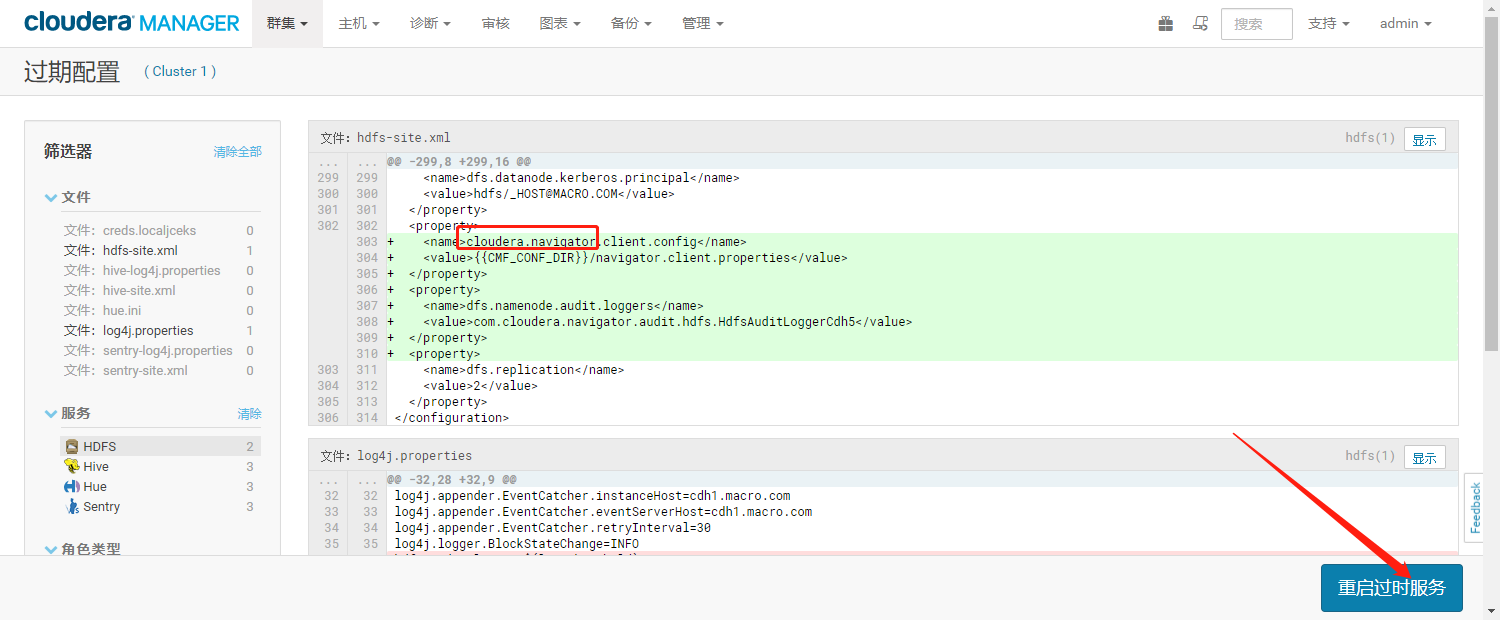
- 角色添加完毕如下图:
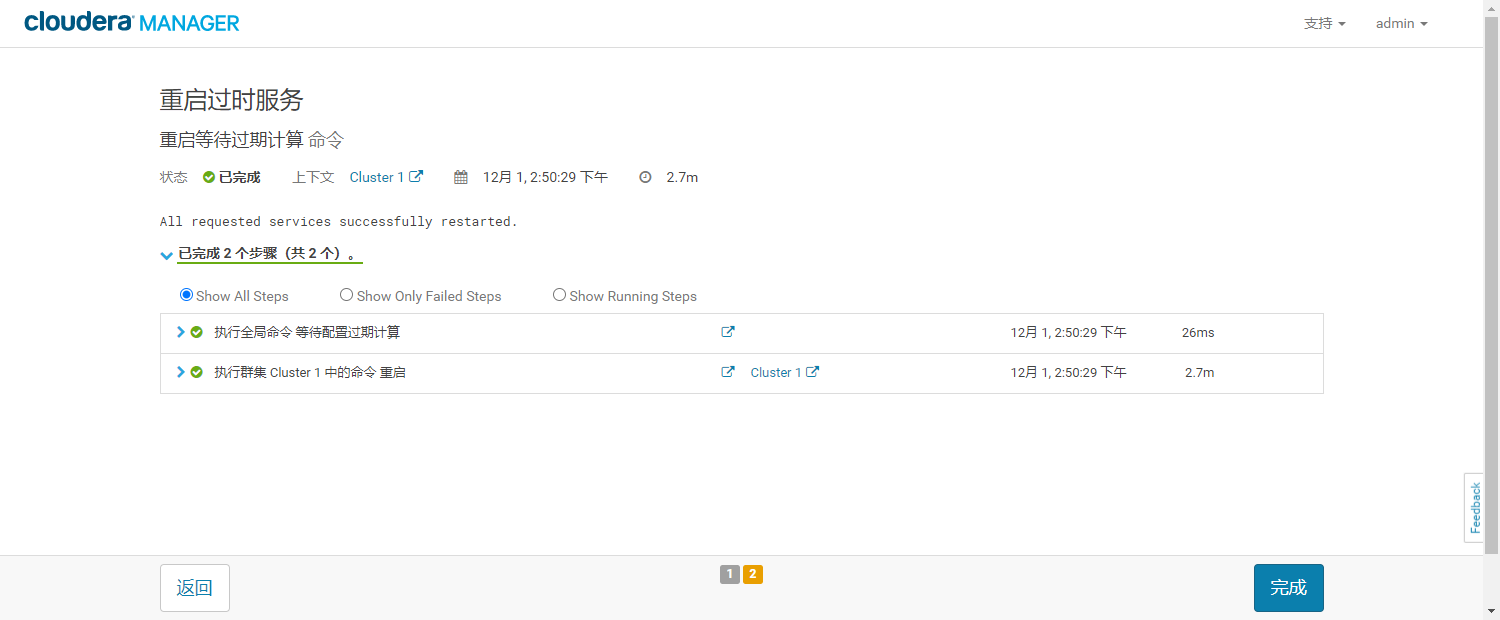
- 重启过时服务
二、Navigator的使用
1、访问入口
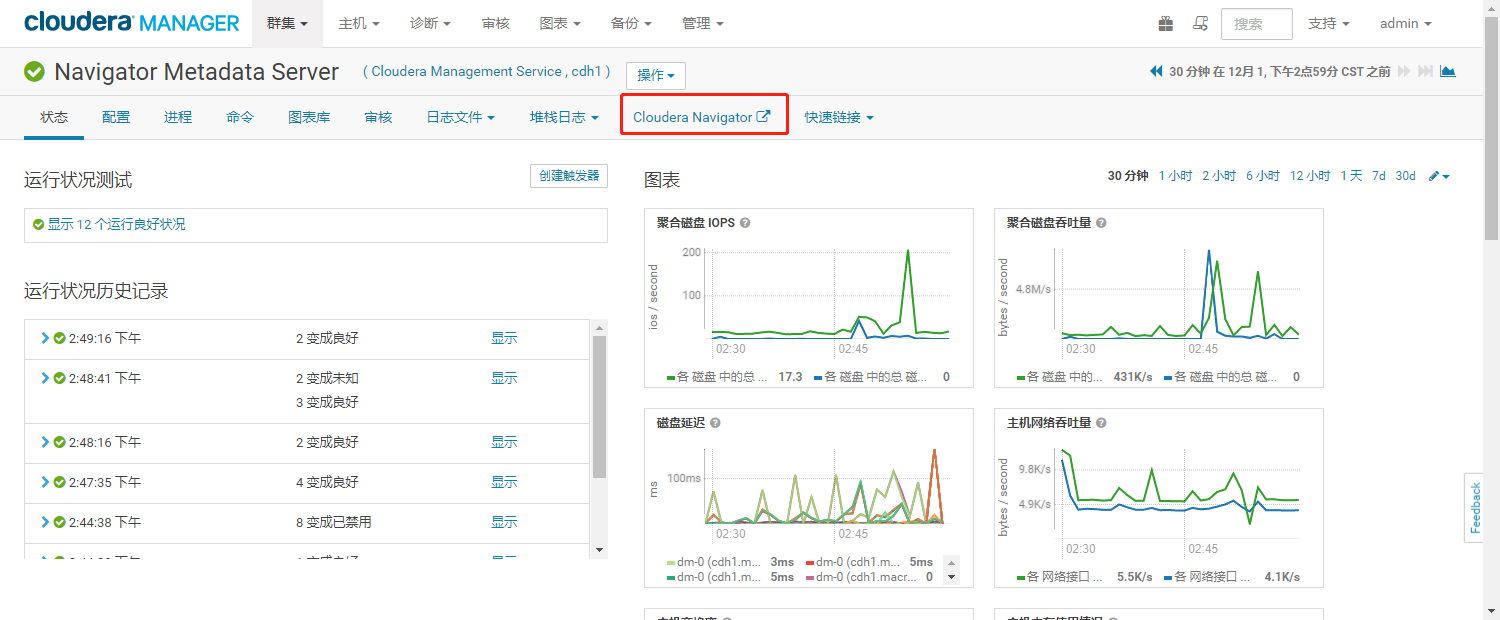
- 进入Cloudera Management Service服务,点击【Navigator Metadata Server】
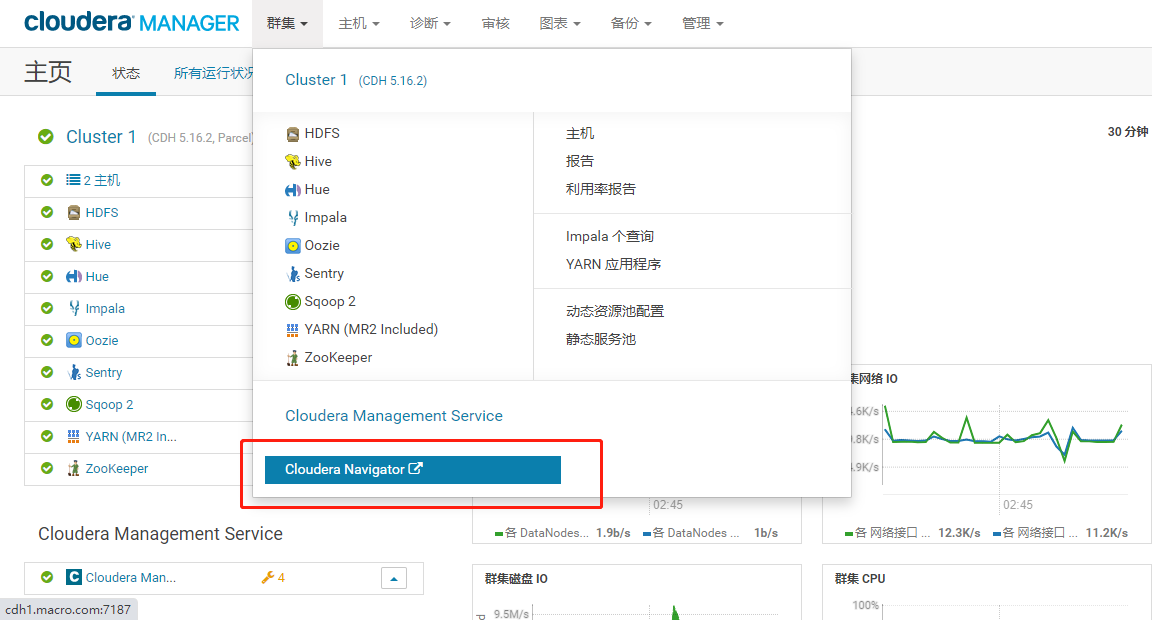
- 在Cloudera Manager首页点击【集群】菜单
- 也可以在浏览器输入如下地址访问
http://192.168.0.200:7187/login.html
(可左右滑动)
- 输入账号密码,进如Navigator主页面(账户密码都是 admin)
2、元数据搜索
- 使用管理员登录Cloudera Navigator(下图为元数据搜索功能界面)
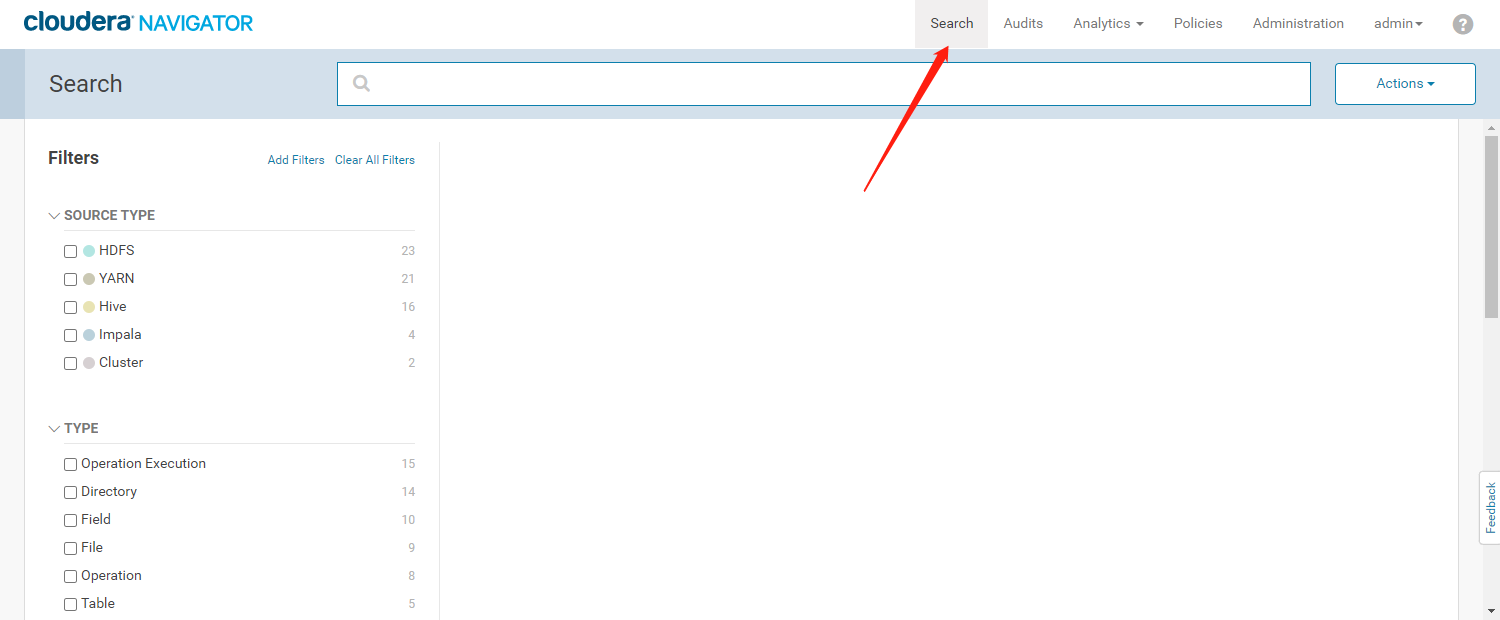
- 根据输入的检索条件可以检索出所有涉及的内容,根据Source Type进行展示
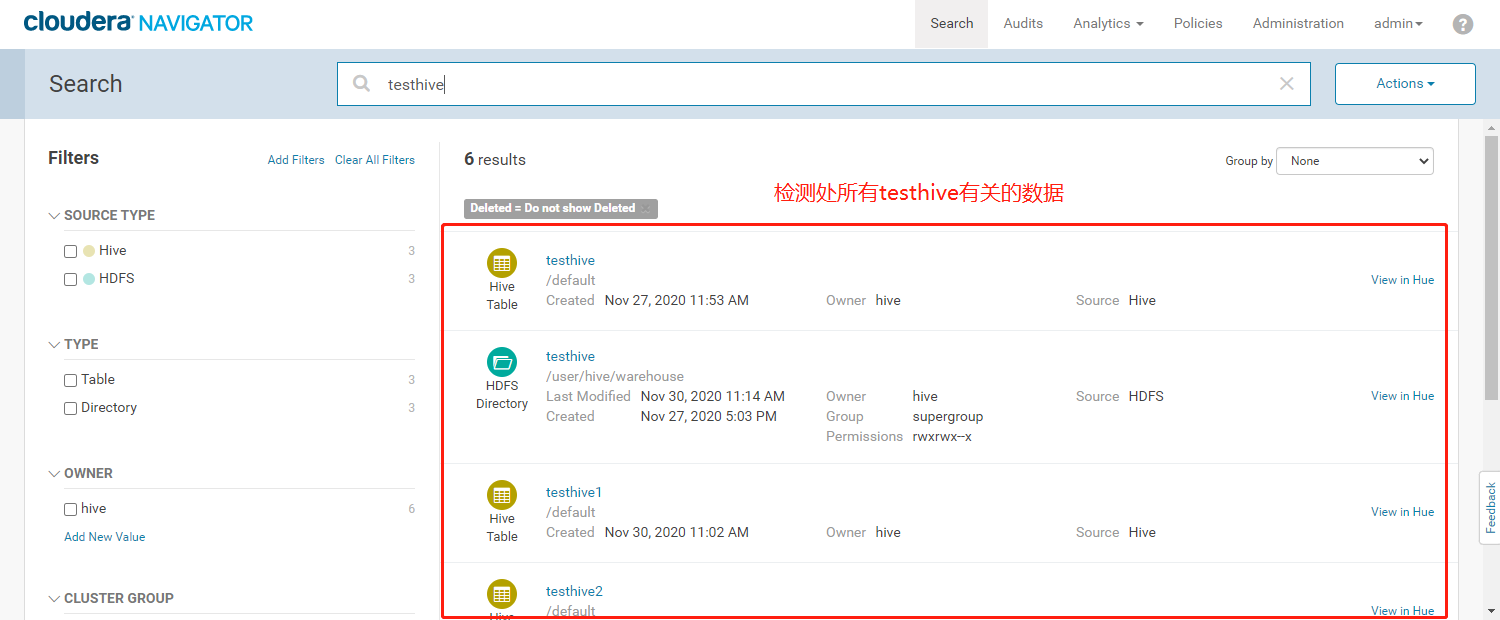
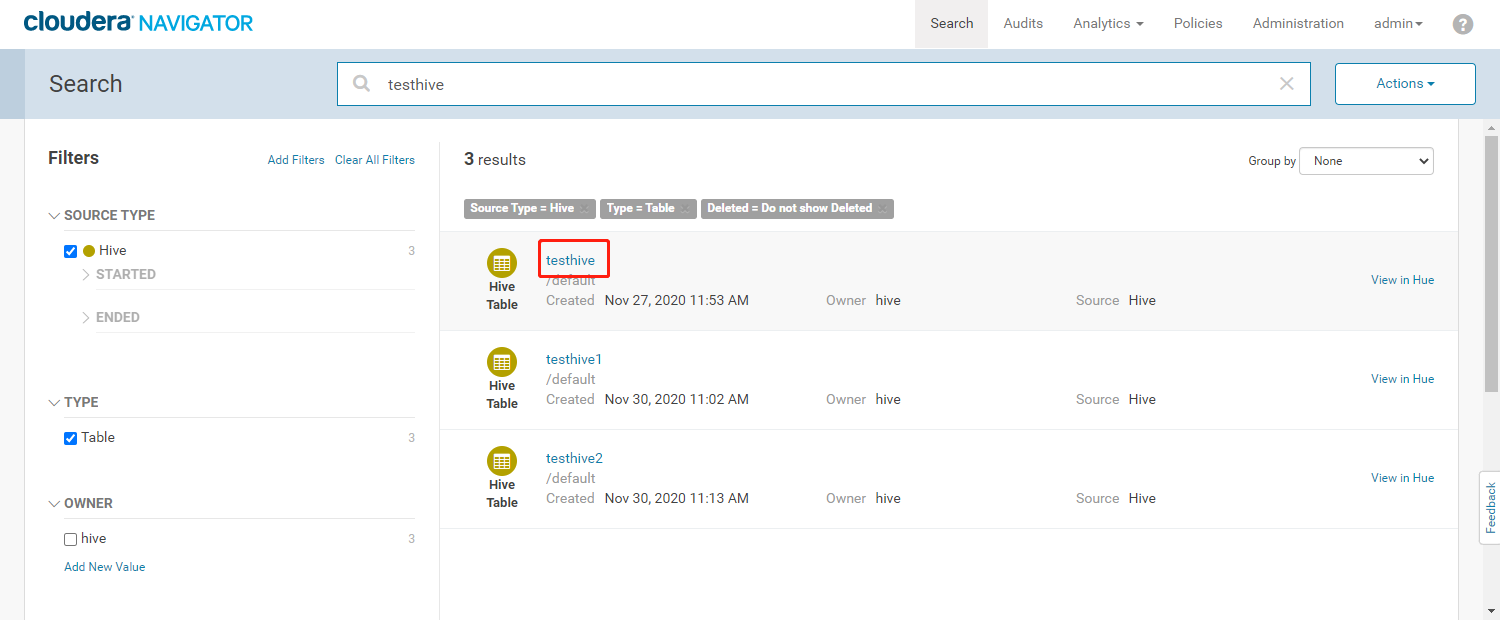
- 在搜索栏输入【testhive】,根据左边的过滤条件,过滤数据源为Hive且类型为Table类型的数据
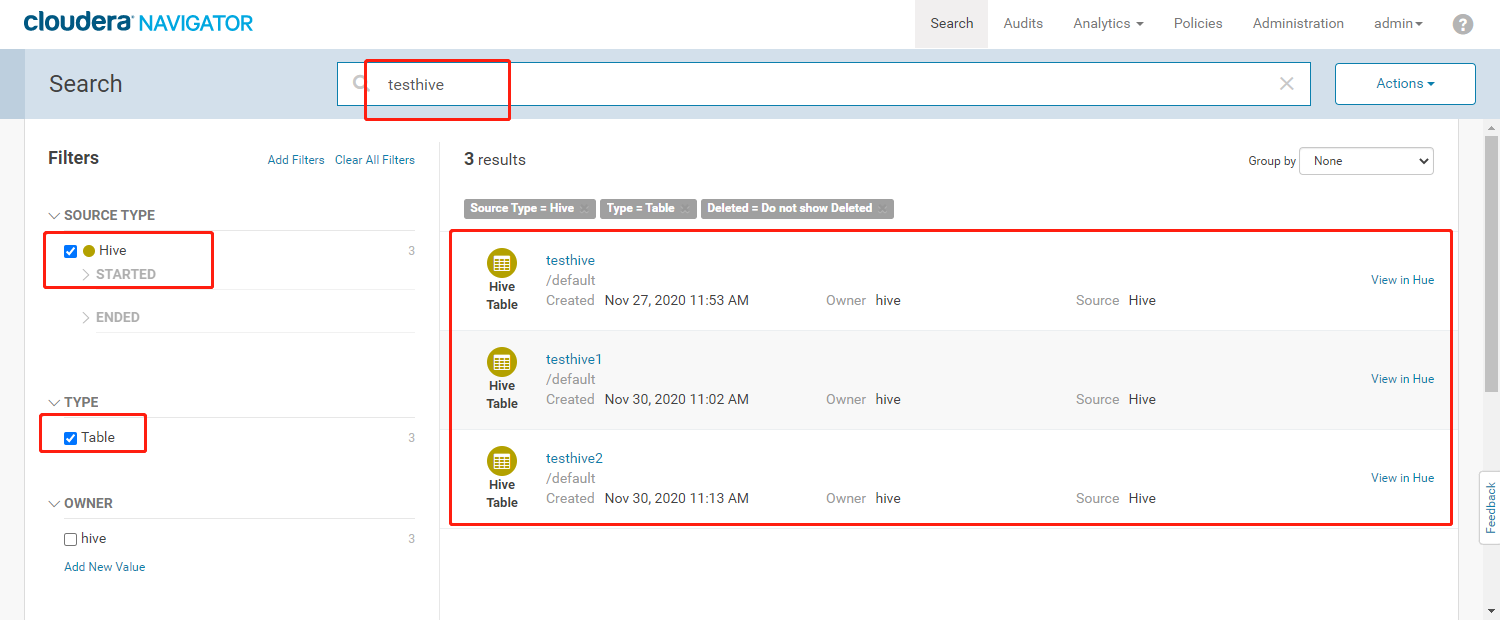
- Navigator支持元数据模糊检索,元数据类型,所属用户等条件过滤,检索出来的数据显示有数据文件的HDFS路径、所属用户、创建时间及数据源等信息。
- 查看元数据详细信息
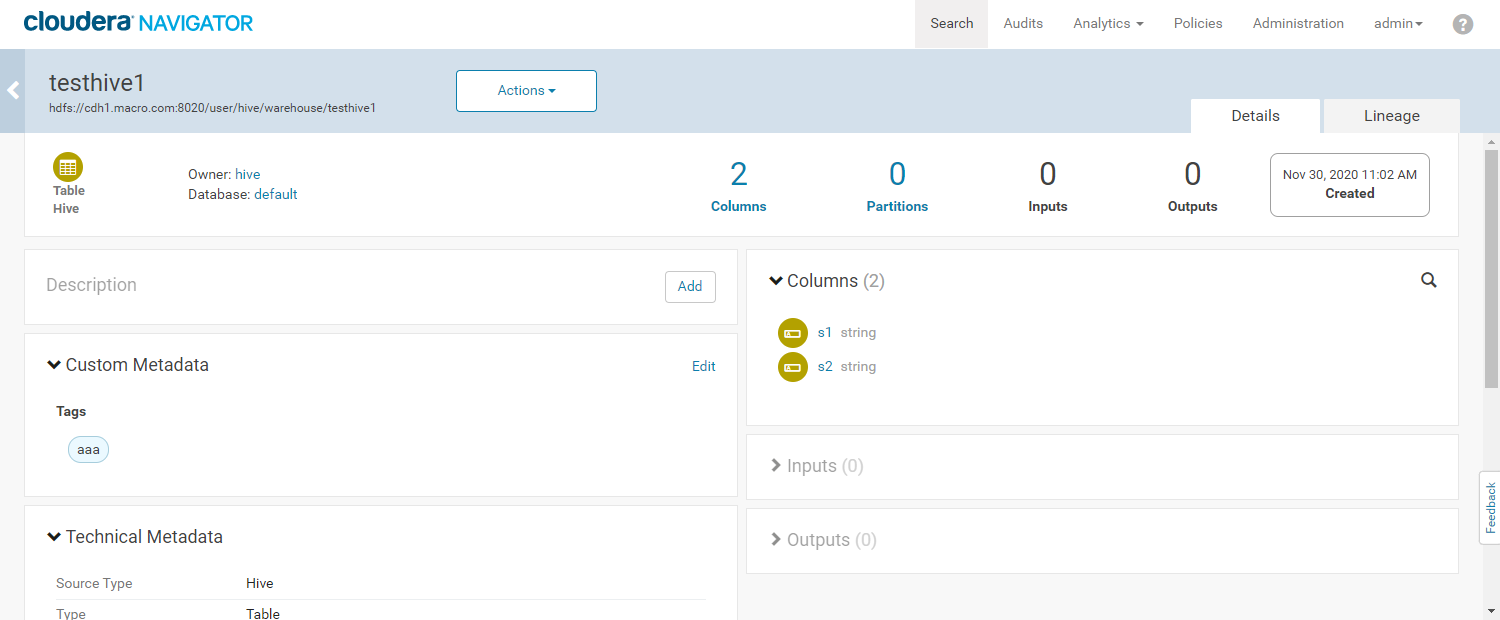
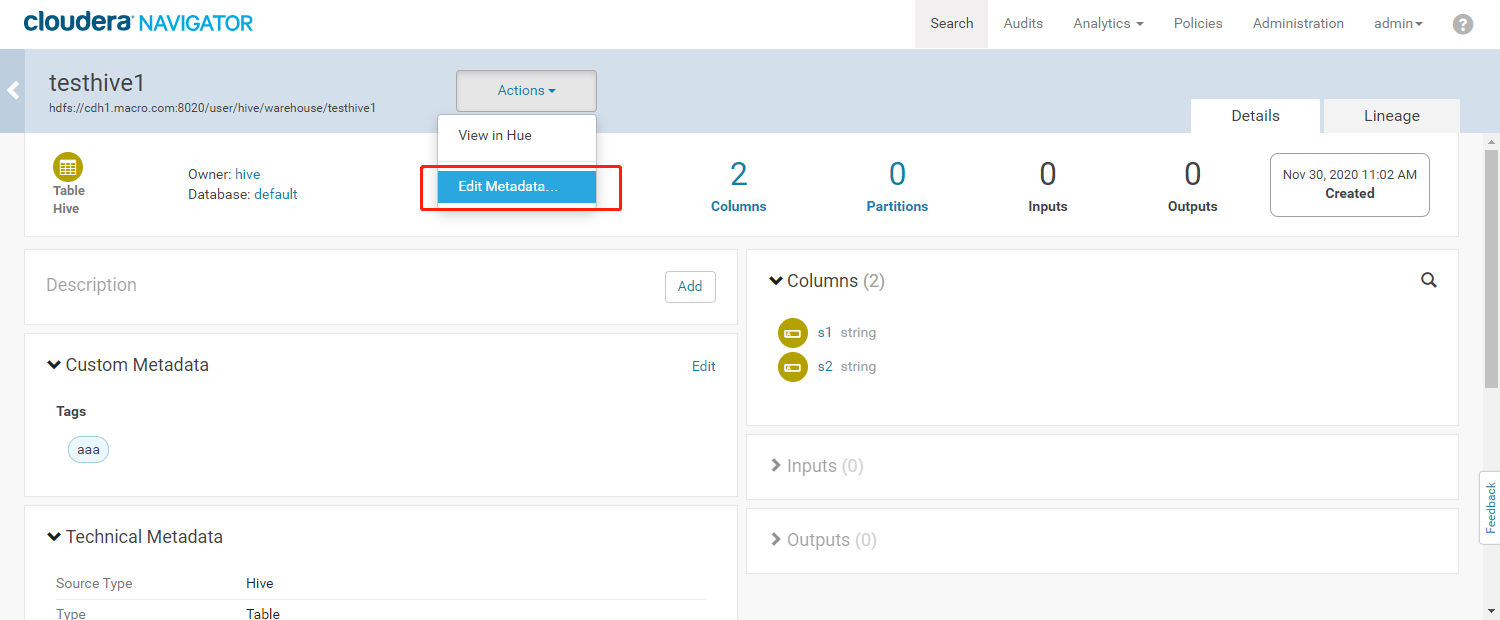
- 进入元数据详细界面,为数据添加标签(Tag)
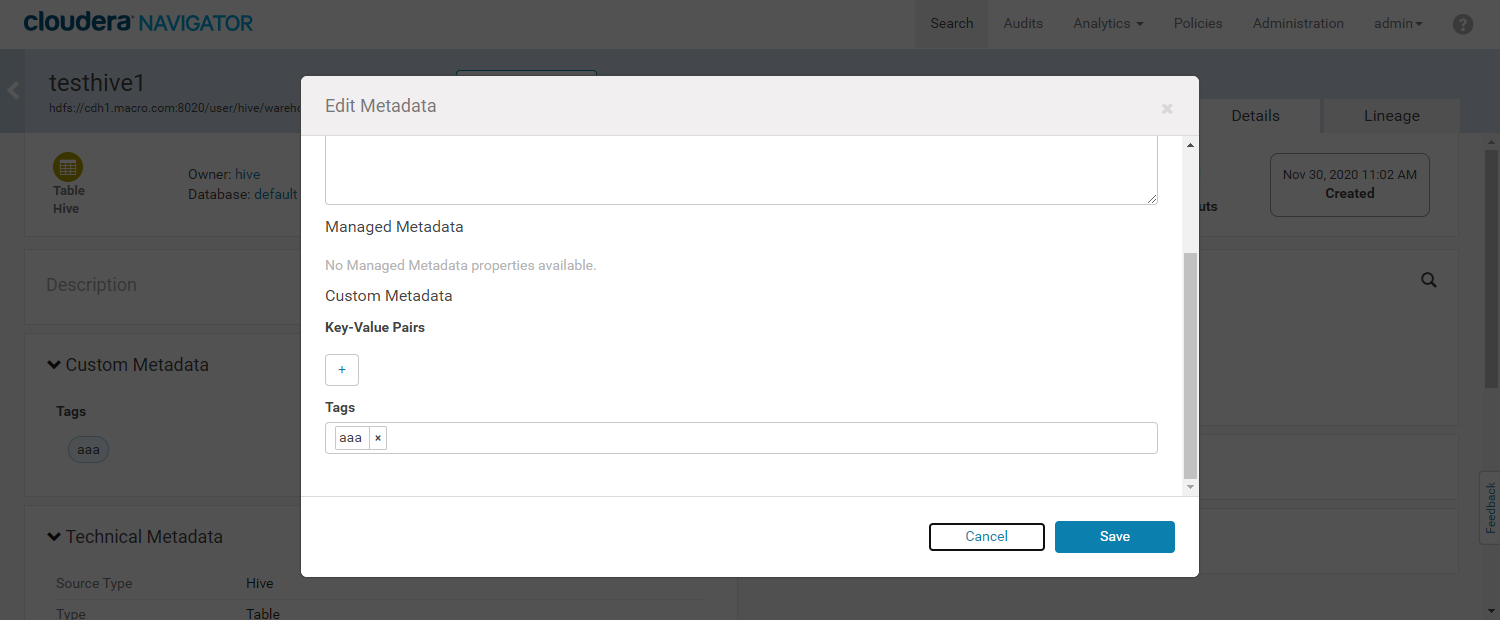
- 添加成功如下图所示
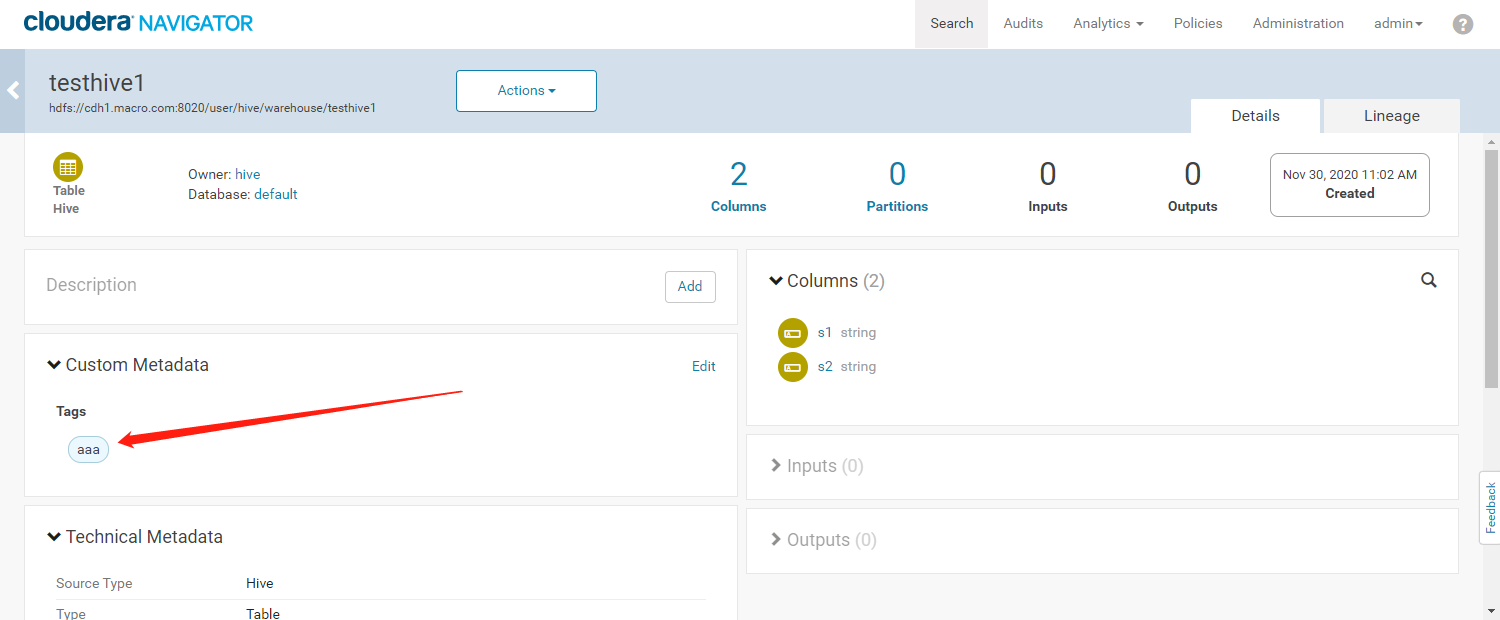
- 可以通过标签检索我们的元数据信息
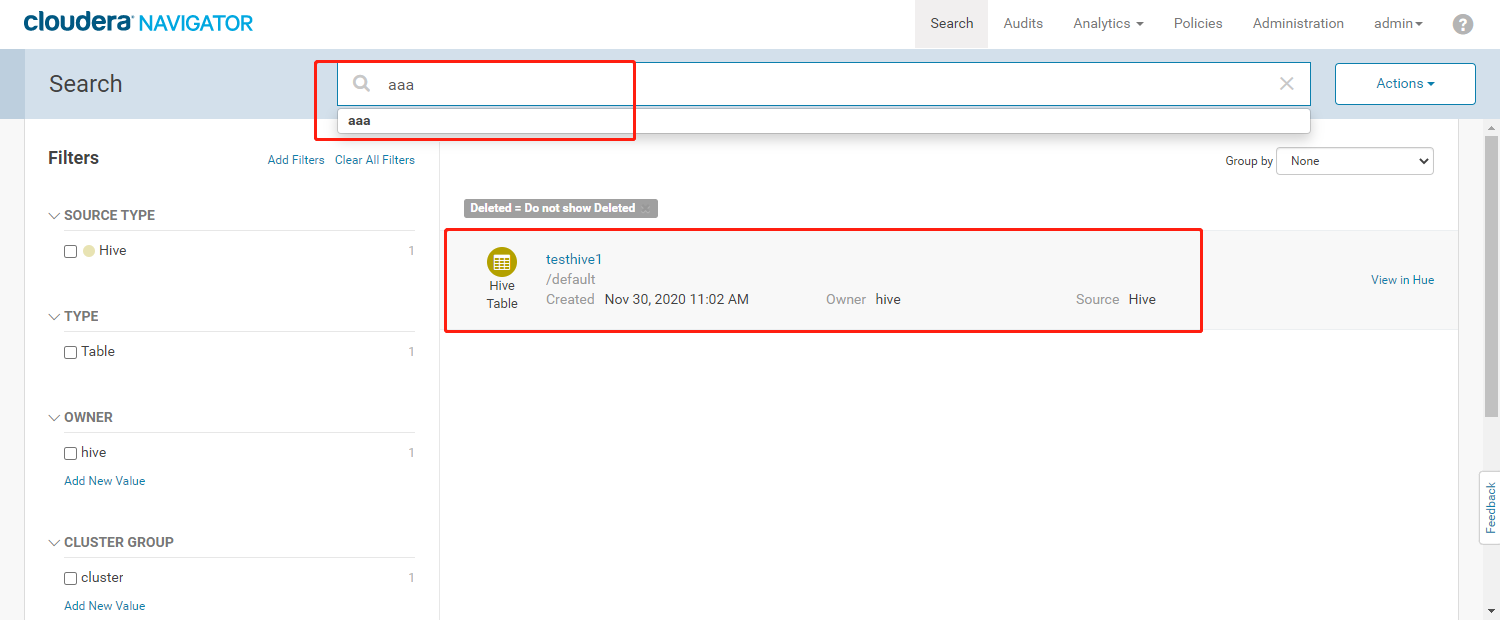
- 修改元数据名称
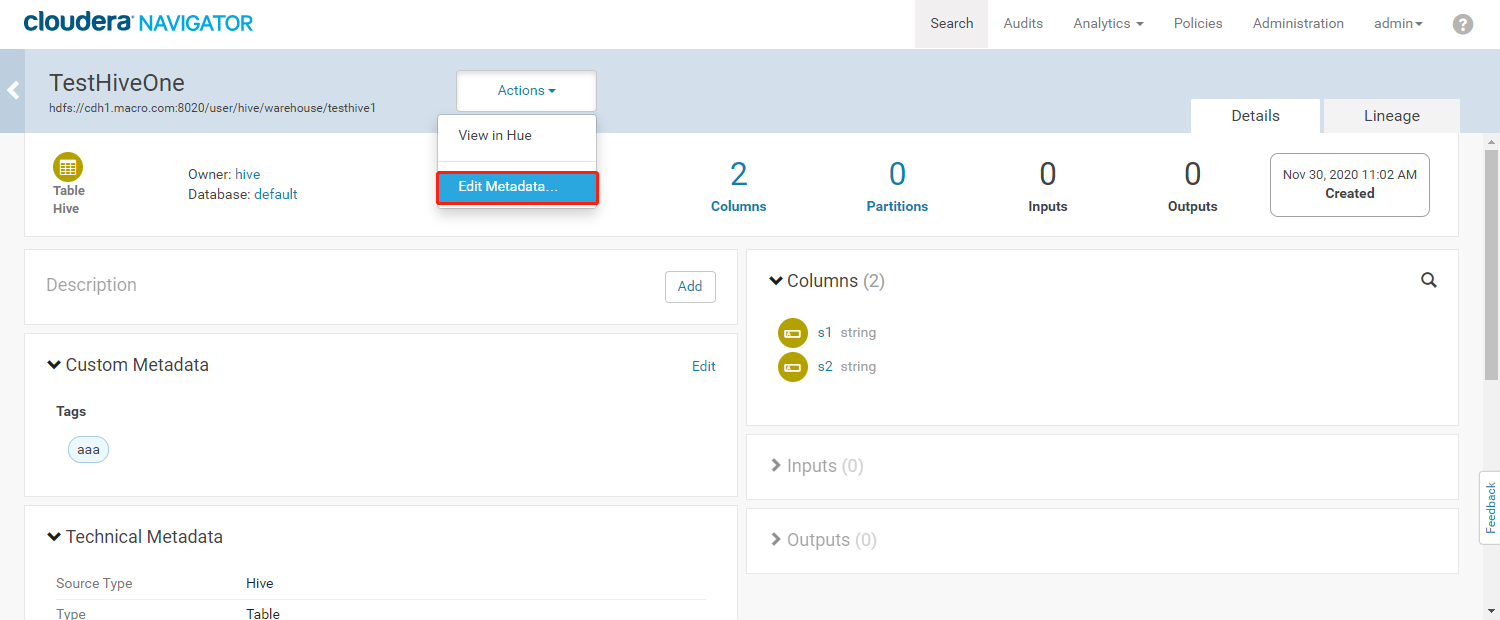
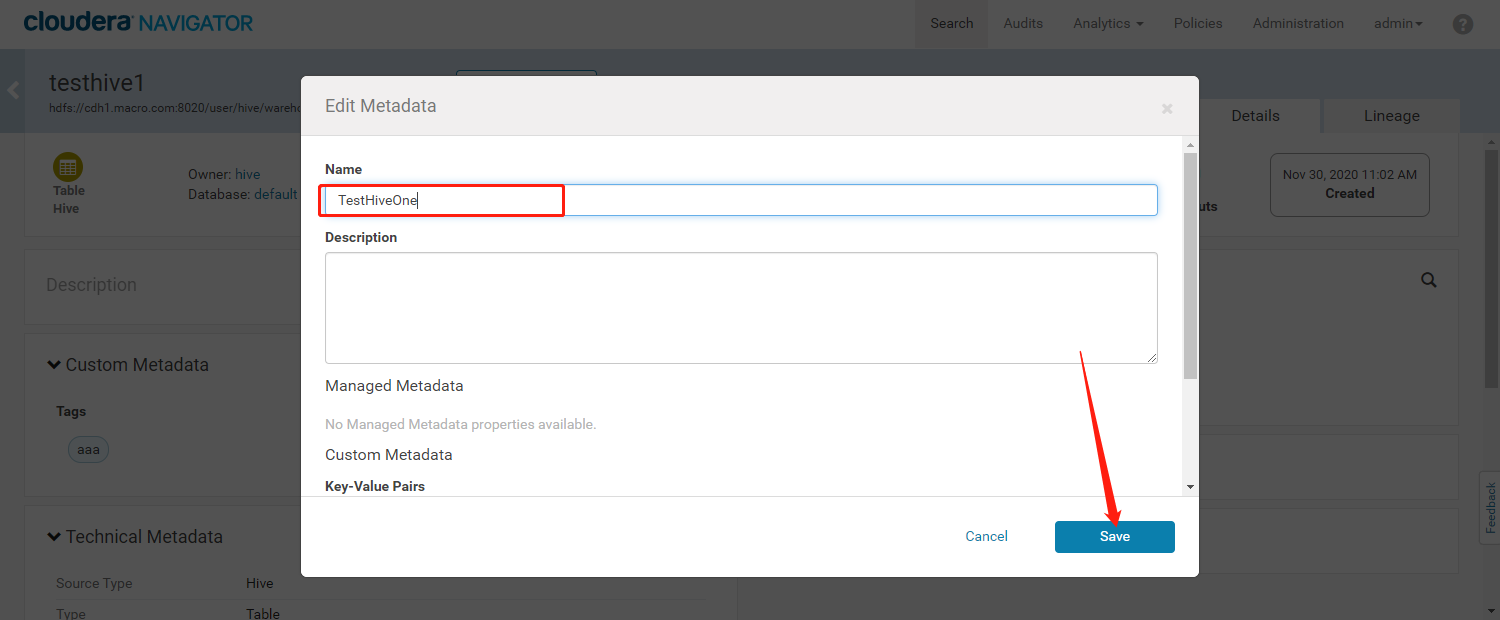
- 修改元数据名称后,可以根据修改后的名称来搜索我们的元数据信息
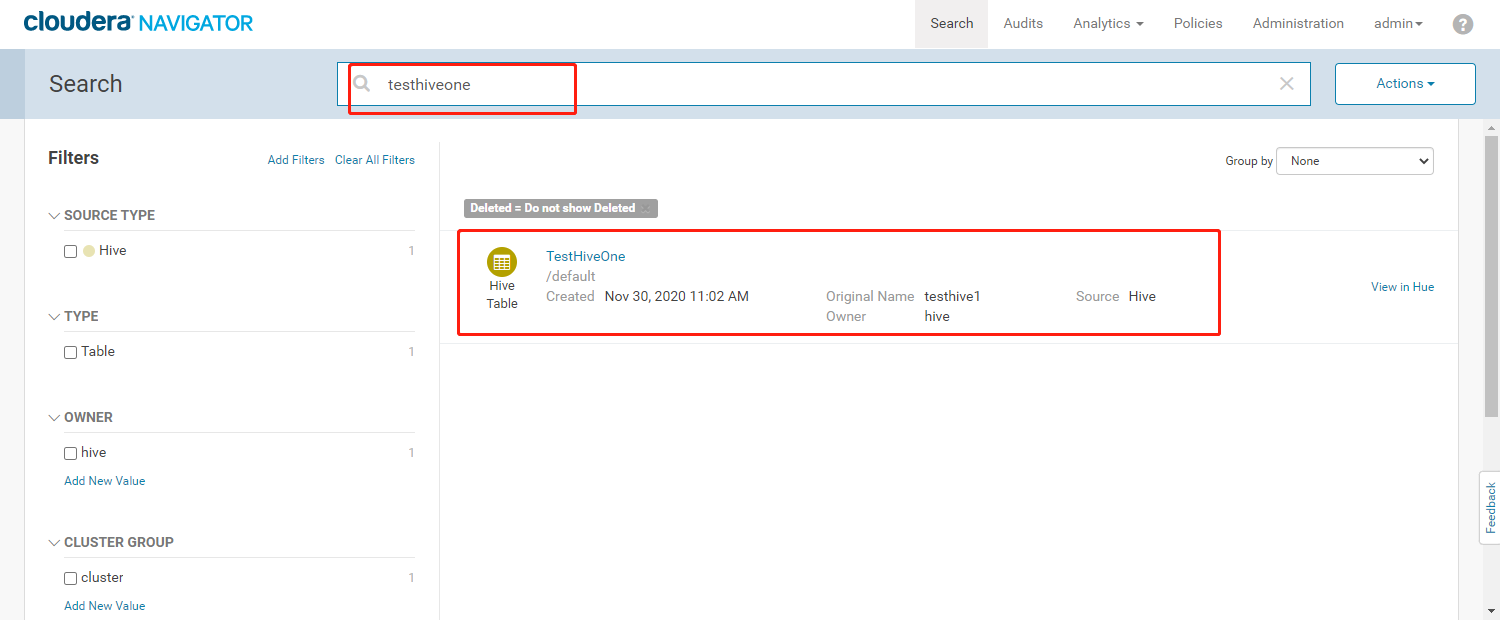
- 通过检索出来的结果,能看到修改后的元数据名称中会有一个【Original Name】字段标识原始元数据的名称。修改的元数据名称还原后则不能检索到testhive1元数据信息
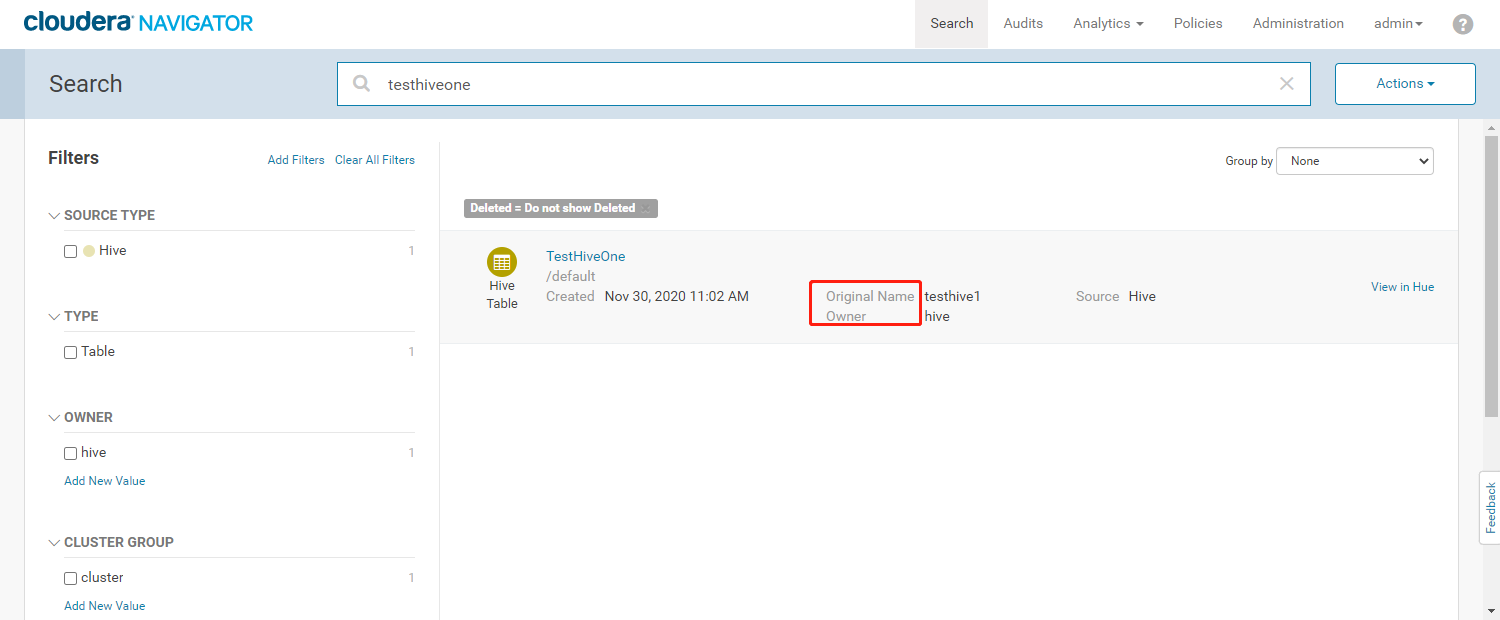
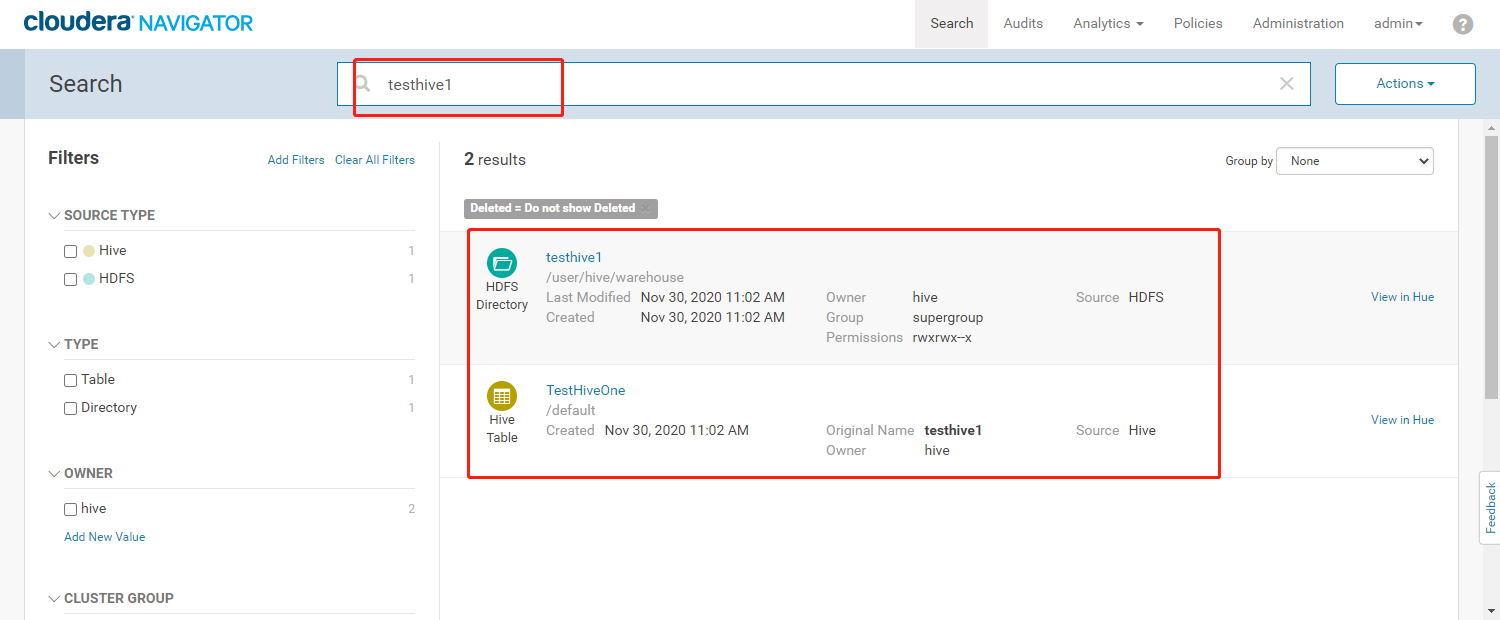
- 使用默认的【testhive1】检索出来的数据
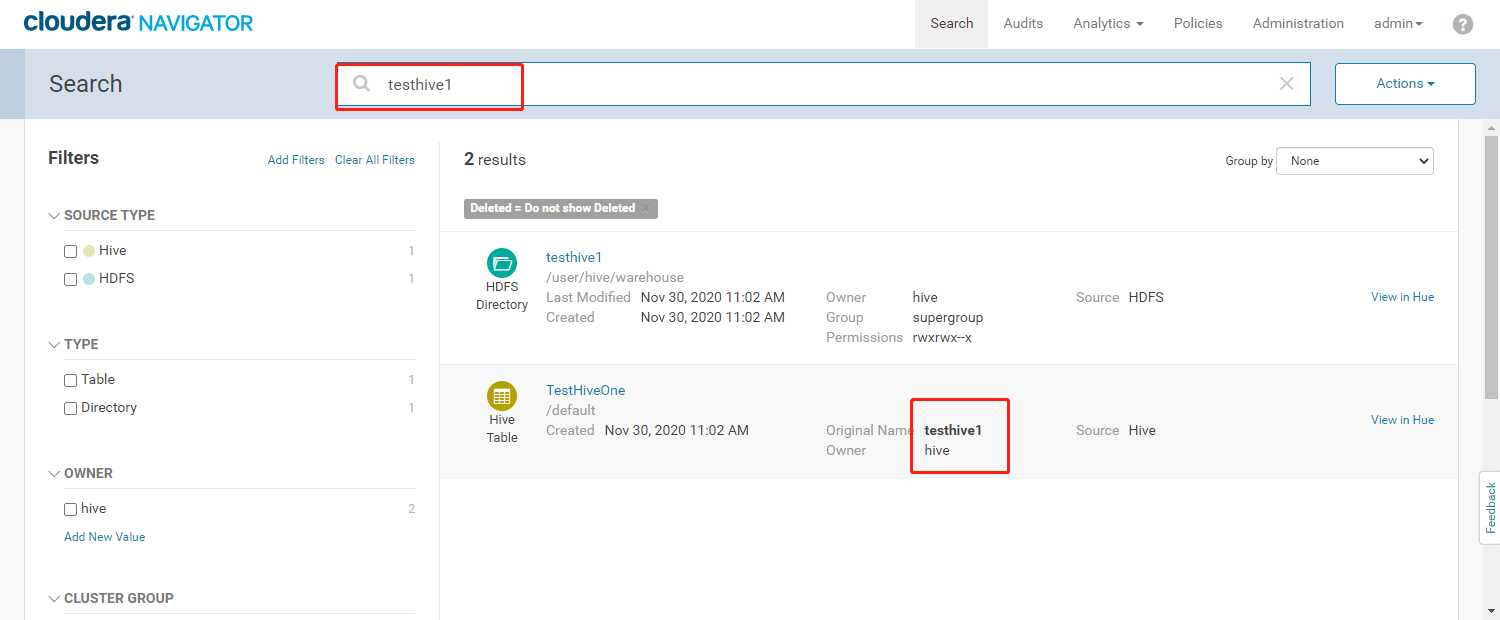
3、数据溯源管理
3.1、案例:
使用Sqoop抽取MySQL数据到HDFS,然后将创建Hive的sqoop_hosts外部表,再将sqoop_hosts表转化为hosts_paquet表,通过这系列流程查看Navigator是如何展示我们数据的流向。
3.2、依照HOSTS表在Hive种创建sqoop_hosts表
- 脚本使用Sqoop命令通过MySQL数据库中指定表(HOSTS表)创建Hive表(sqoop_hosts表)
```
vim create_hivetable.sh
————复制如下内容——————-
!/bin/sh
host=’cdh1.macro.com’ database=’cm’ user=’root’ password=’123456’ mysqlTable=’HOSTS’ hiveDB=’default’ hiveTable=’sqoop_hosts’ sqoop create-hive-table \ —connect jdbc:mysql://${host}:3306/${database} —username ${user} —password ${password} \ —table ${mysqlTable} \ —hive-table ${hiveDB}.${hiveTable} \ —hive-overwrite
2. **执行结果如下**<a name="H3KAI"></a>### 3.2、导入Mysql数据至Hive1. **在命令行执行脚本将MySQL表数据抽取到Hive的sqoop_hosts表中**
vim import_hivetable.sh ———复制如下内容——————
!/bin/sh
host=’cdh1.macro.com’ database=’cm’ user=’cm’ password=’password’ mysqlTable=’HOSTS’ hiveDB=’default’ hiveTable=’sqoop_hosts’ tmpDir=’/user/hive/warehouse/‘${hiveDB}’.db/‘${hiveTable} sqoop import —connect jdbc:mysql://${host}:3306/${database} —username ${user} —password ${password} \ —table $mysqlTable \ —hive-import —hive-table ${hiveDB}.${hiveTable} —target-dir ${tmpDir} —delete-target-dir \ —hive-overwrite \ —null-string ‘\N’ —null-non-string ‘\N’
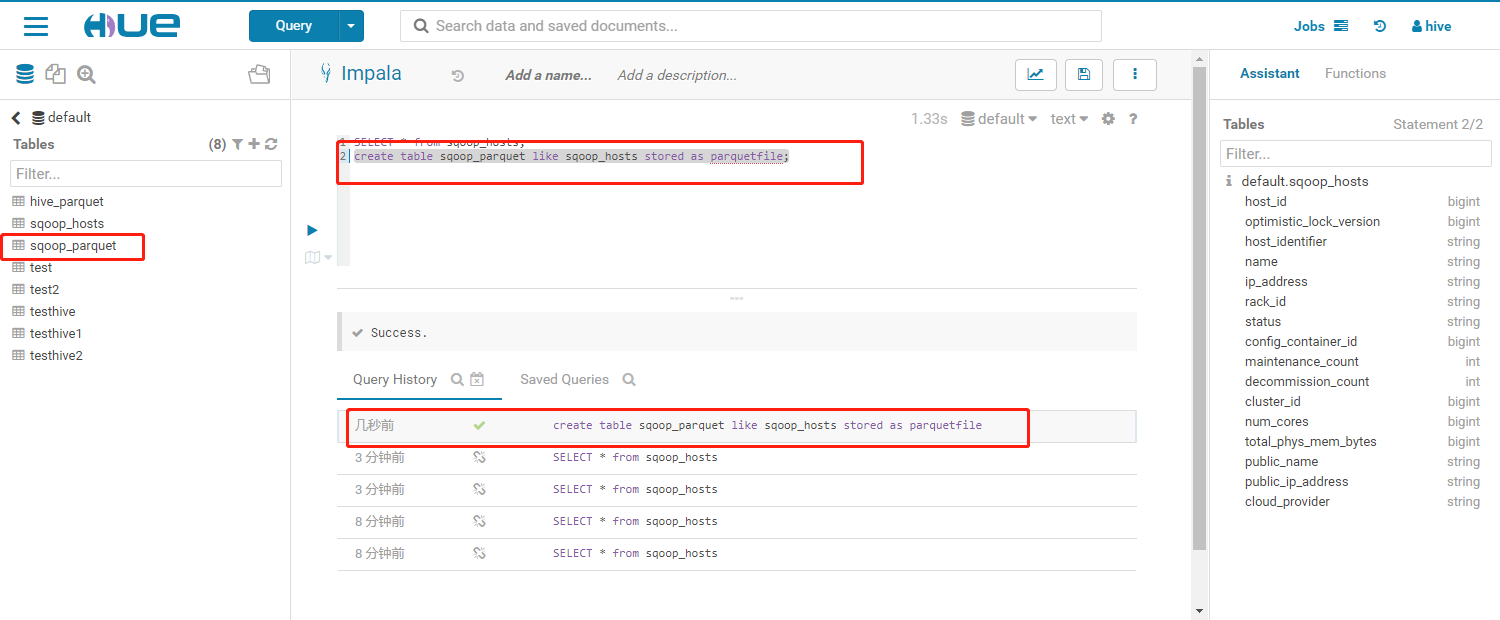
2. **执行结果如下:**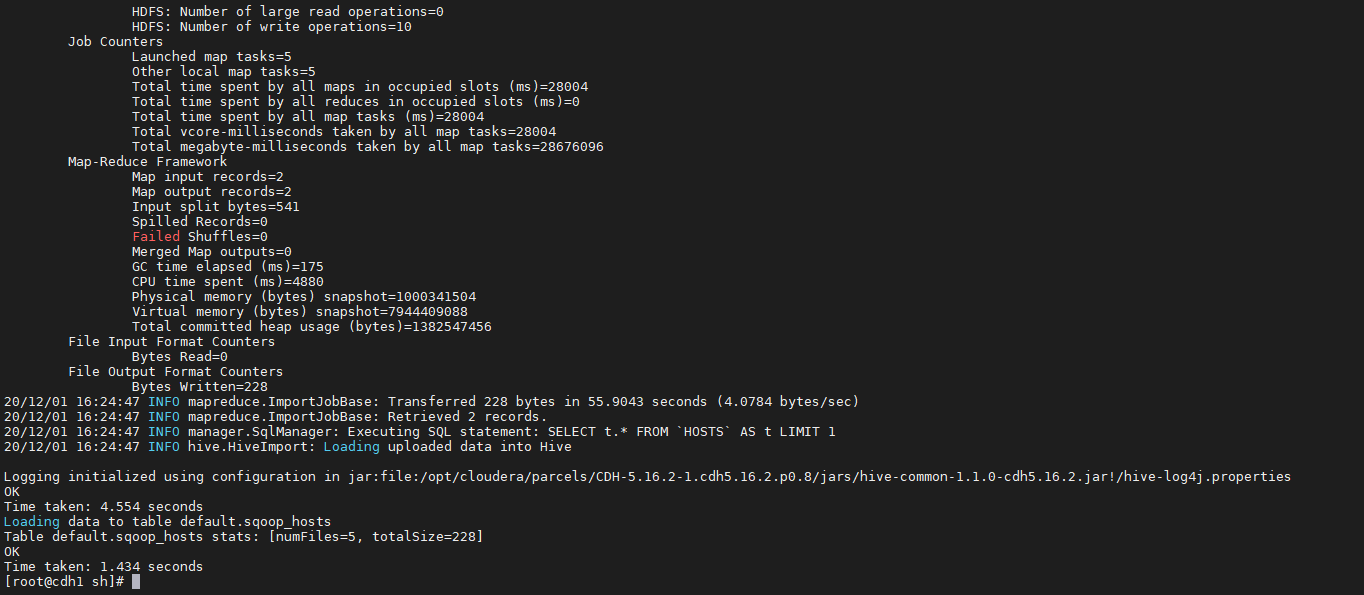3. **查询该表结果如下:**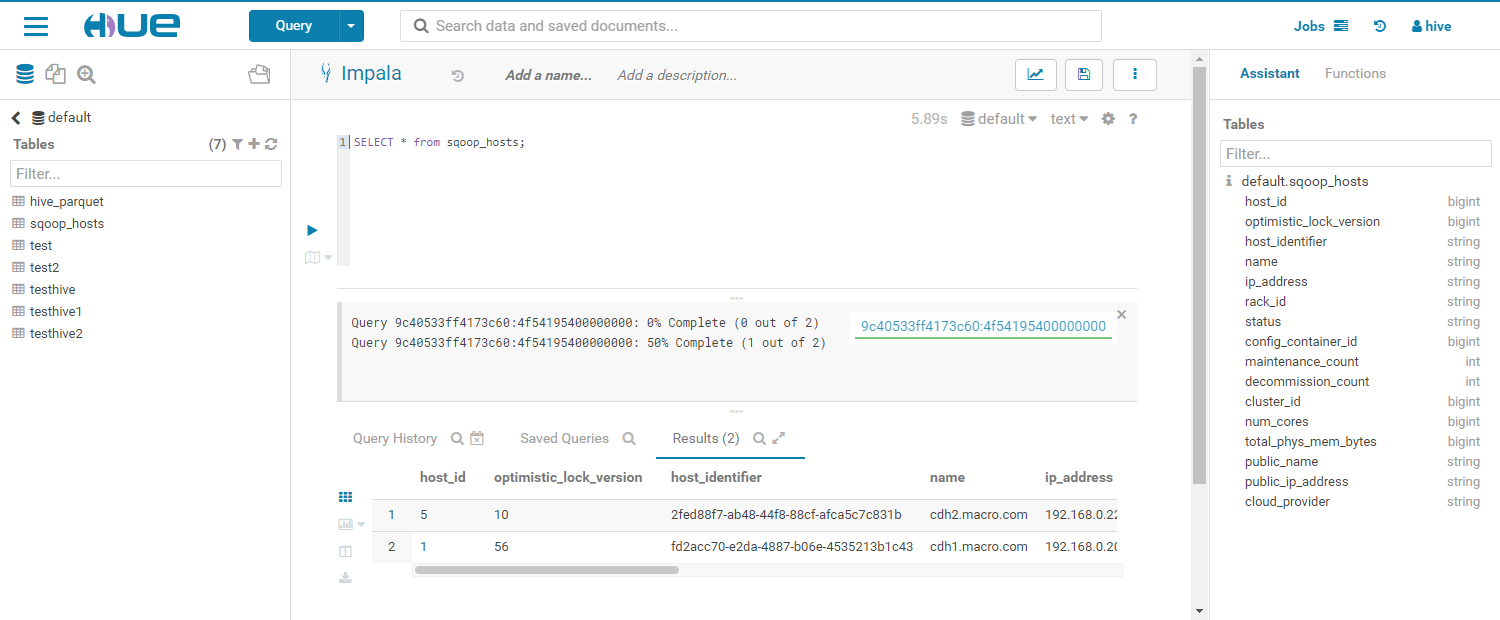4. 在Hue中执行SQL命令创建hosts_parquet表```sqlcreate table sqoop_parquet like sqoop_hosts stored as parquetfile;
- 执行结果如下:
3.4、导入Hive数据至Mysql
在mysql的cm数据库中创建test_hosts表
create table test_hosts like HOSTS;desc test_hosts;
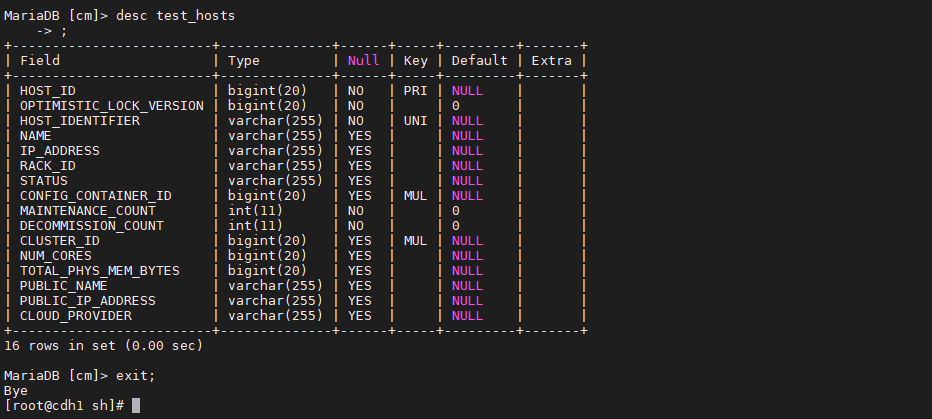
创建脚本,执行将HDFS数据抽取到MySQL数据库中的test_hosts表 ``` vim export_hivetable.sh
!/bin/sh
host=’cdh1.macro.com’ database=’cm’ user=’cm’ password=’password’ mysqlTable=’test_hosts’ hiveDB=’default’ exportDir=’/user/hive/warehouse/sqoop_hosts’ sqoop export —connect jdbc:mysql://${host}:3306/${database} \ —username ${user} \ —password ${password} \ —table ${mysqlTable} \ —export-dir ${exportDir} \ —input-fields-terminated-by ‘\01’ \ -m 1
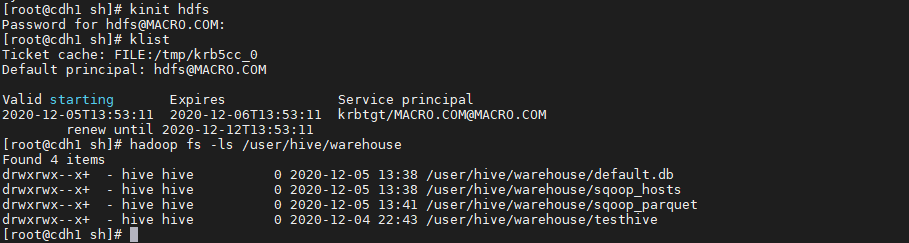
3. 执行结果如下: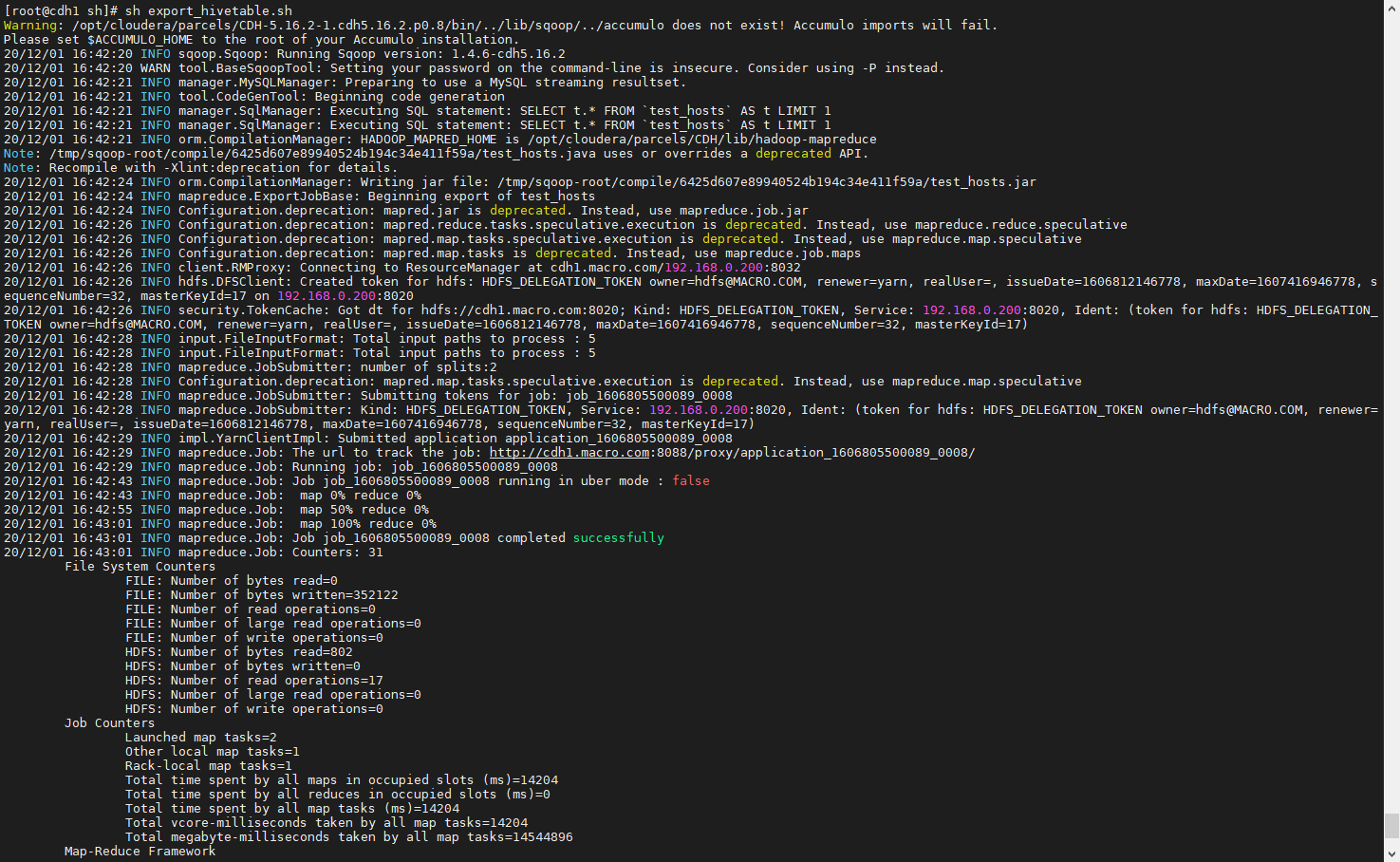<a name="YVngQ"></a>### 3.5、Navigator查看数据血缘分析1. 完成以上的数据操作流程后,登录Navigator,查看数据血缘分析。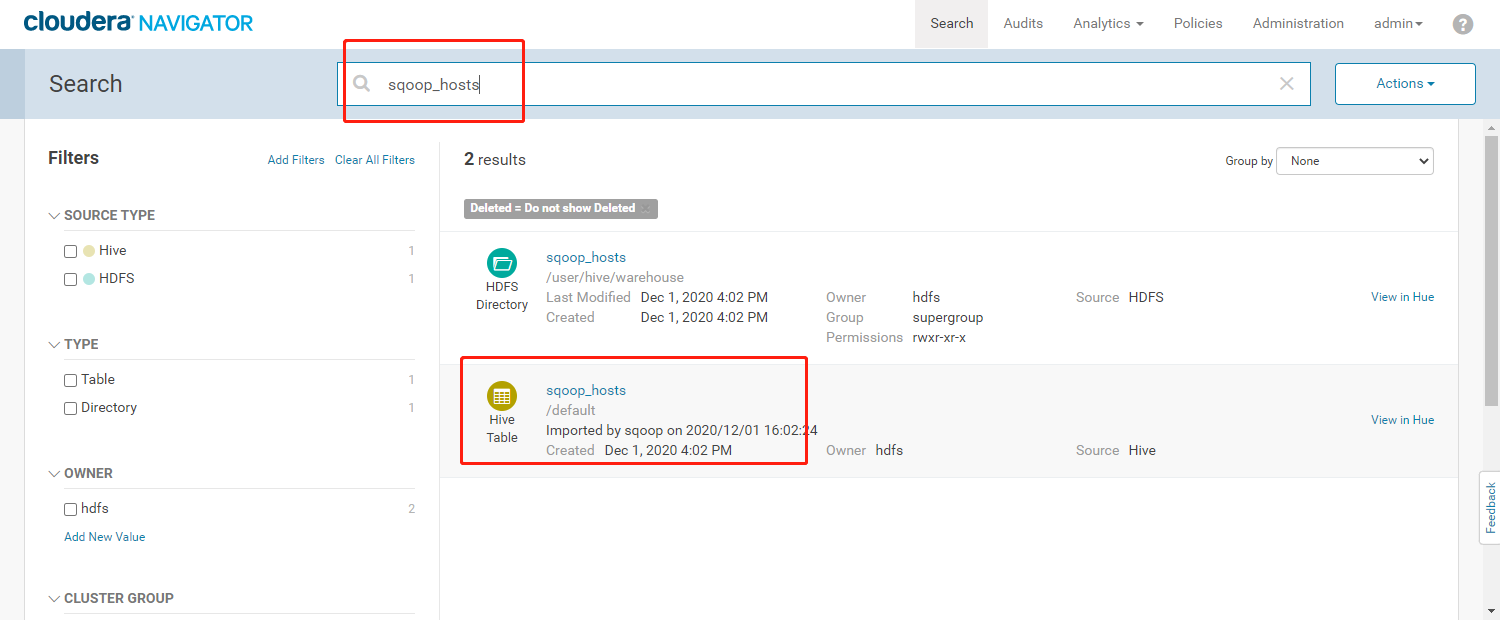2. 进入元数据详细界面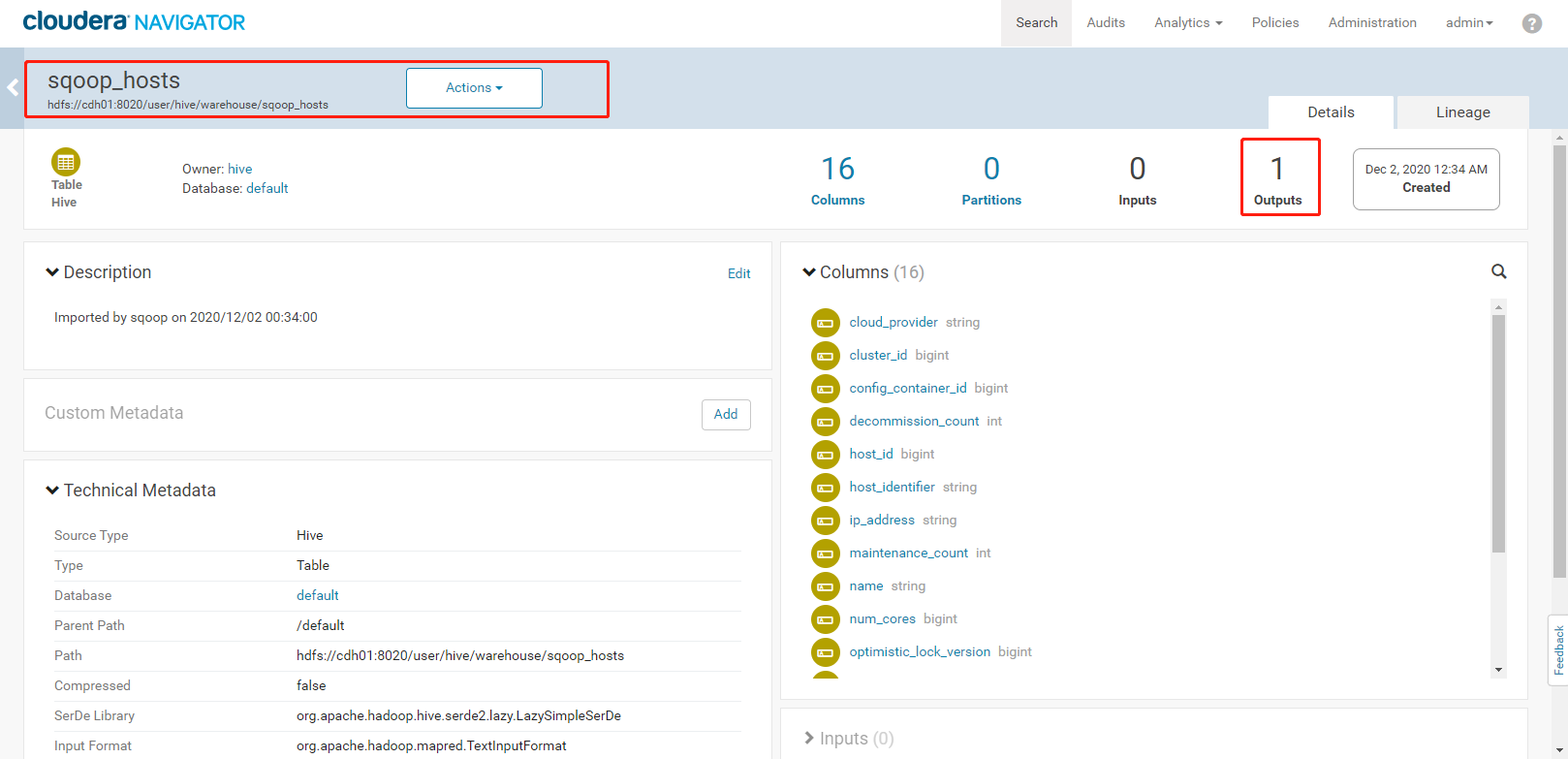3. 点击【Lineage】菜单,进入数据血缘分析界面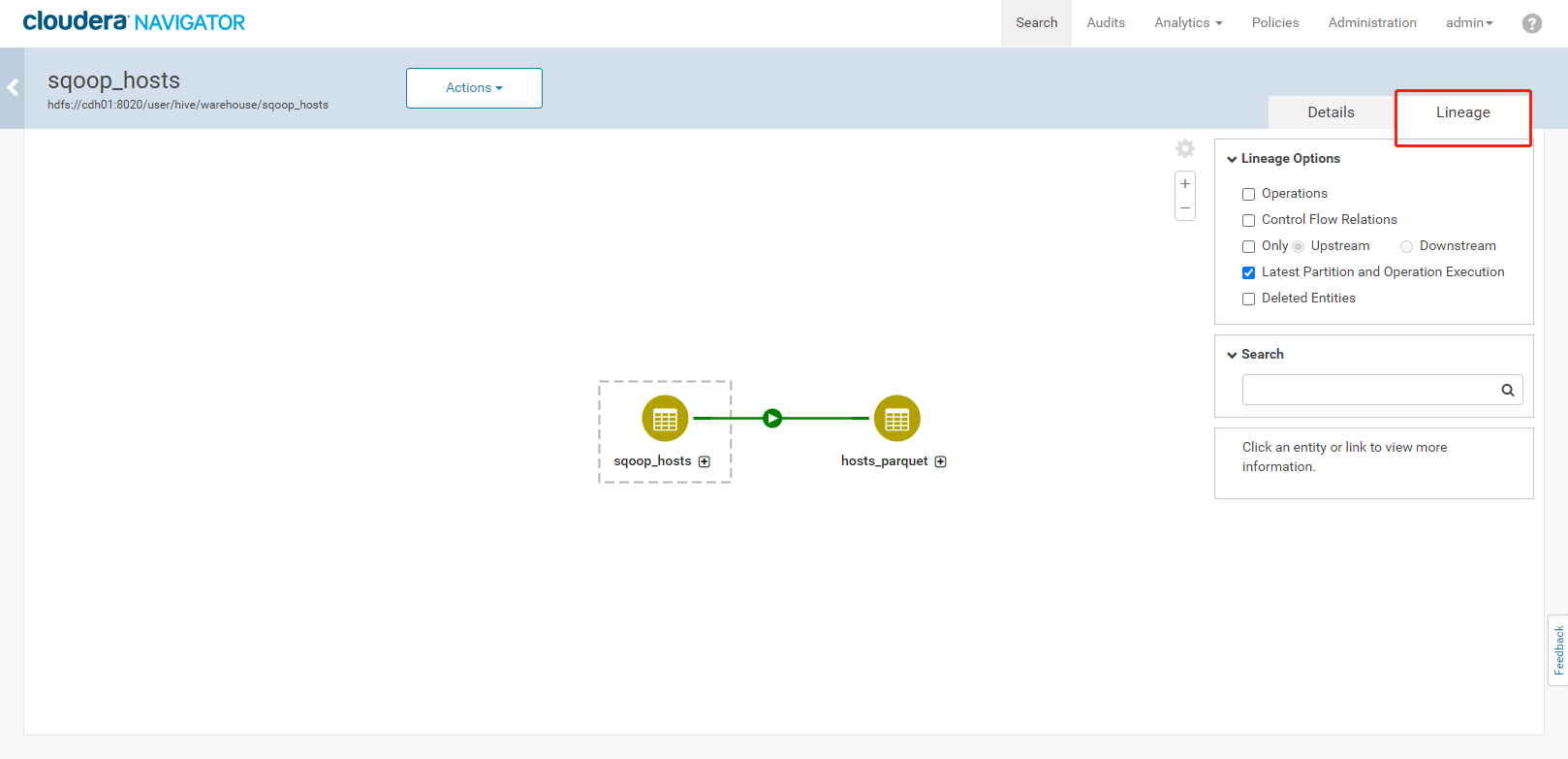4. 点击图中标注的【+】可以看到sqoop_hosts表中所有字段与hosts_parquet表中字段为11对应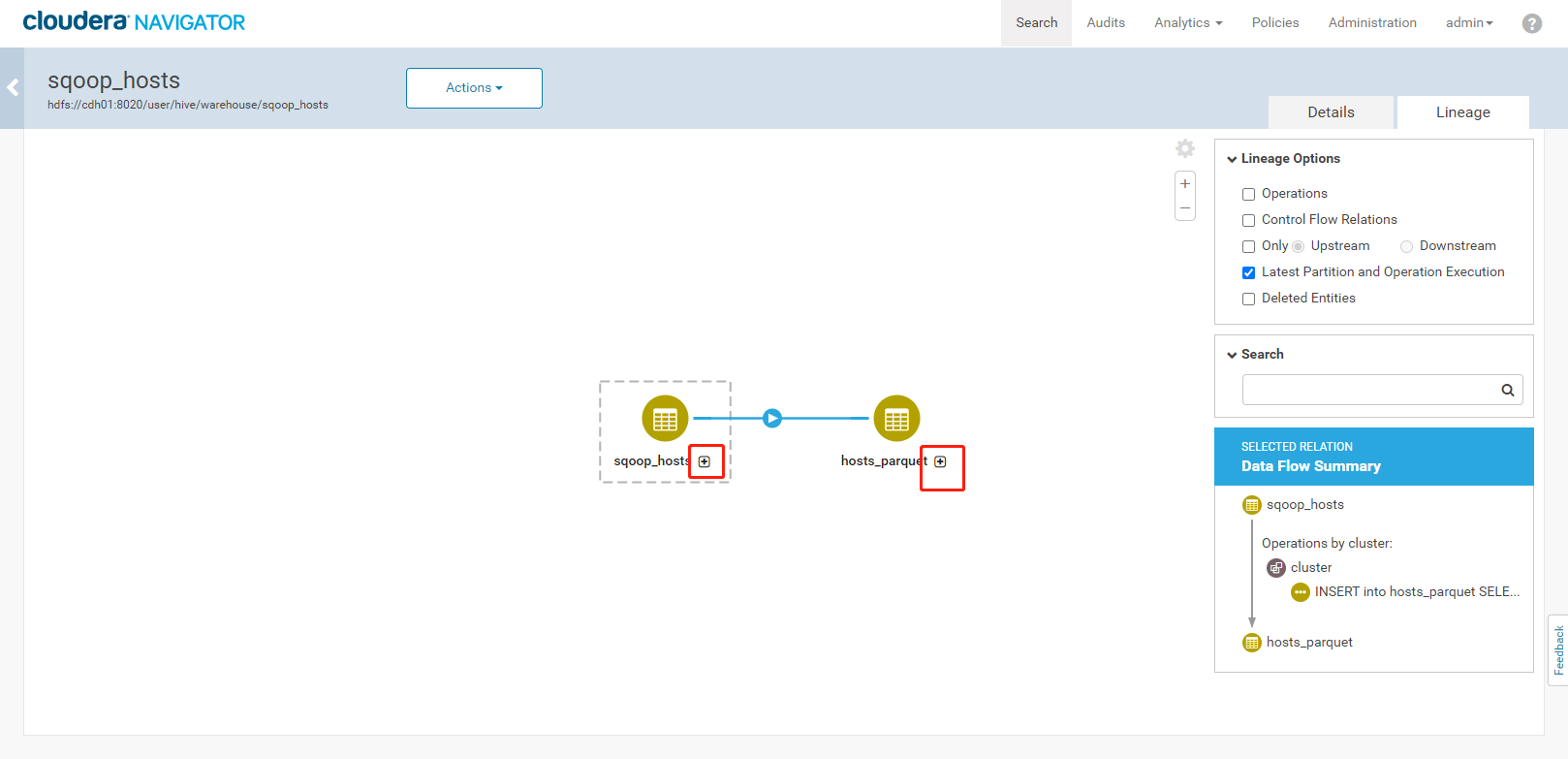<br />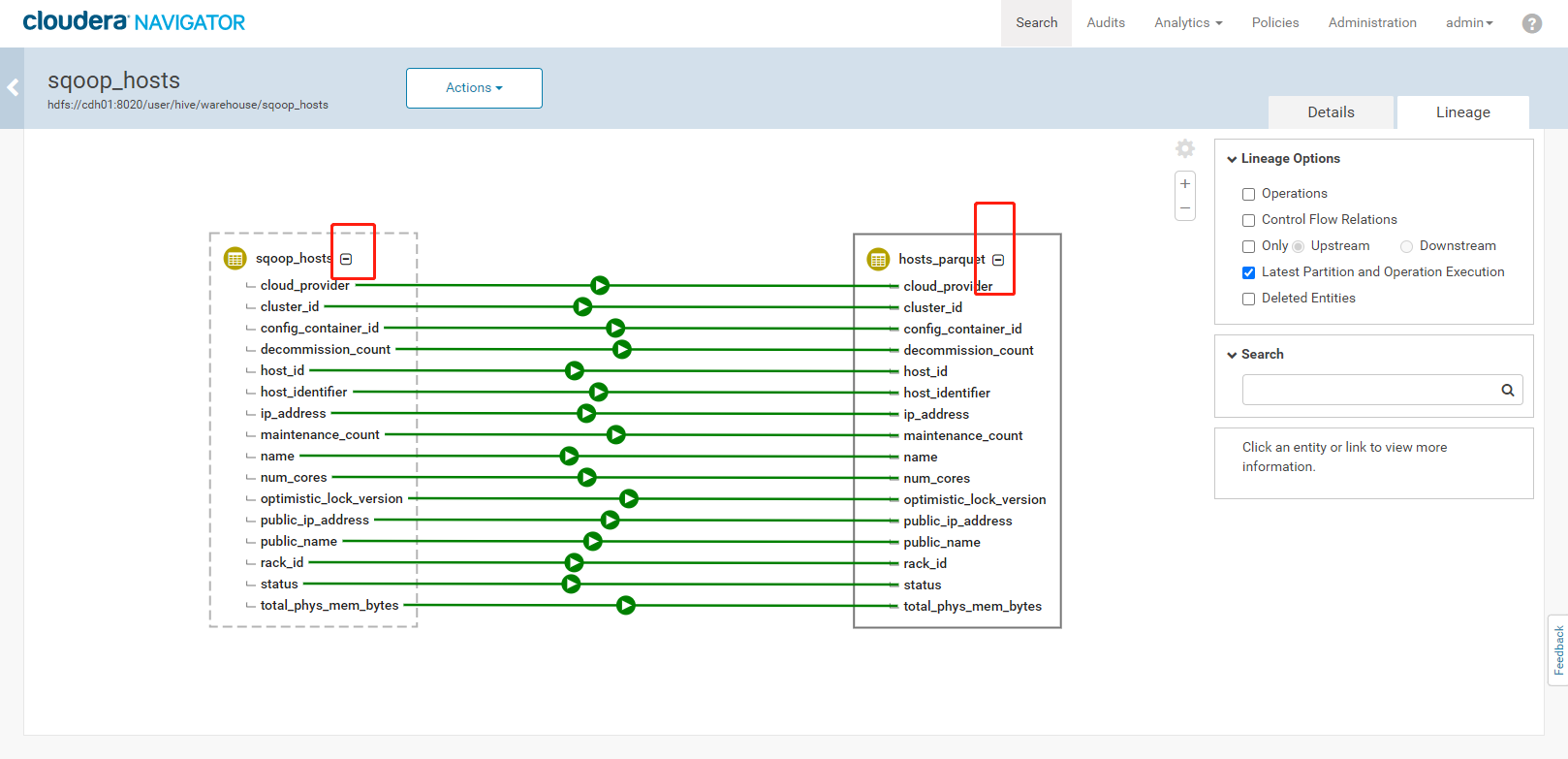<br />5. 点击右侧菜单【Operations】,可以看到详细的跟踪到元数据的源头及目的地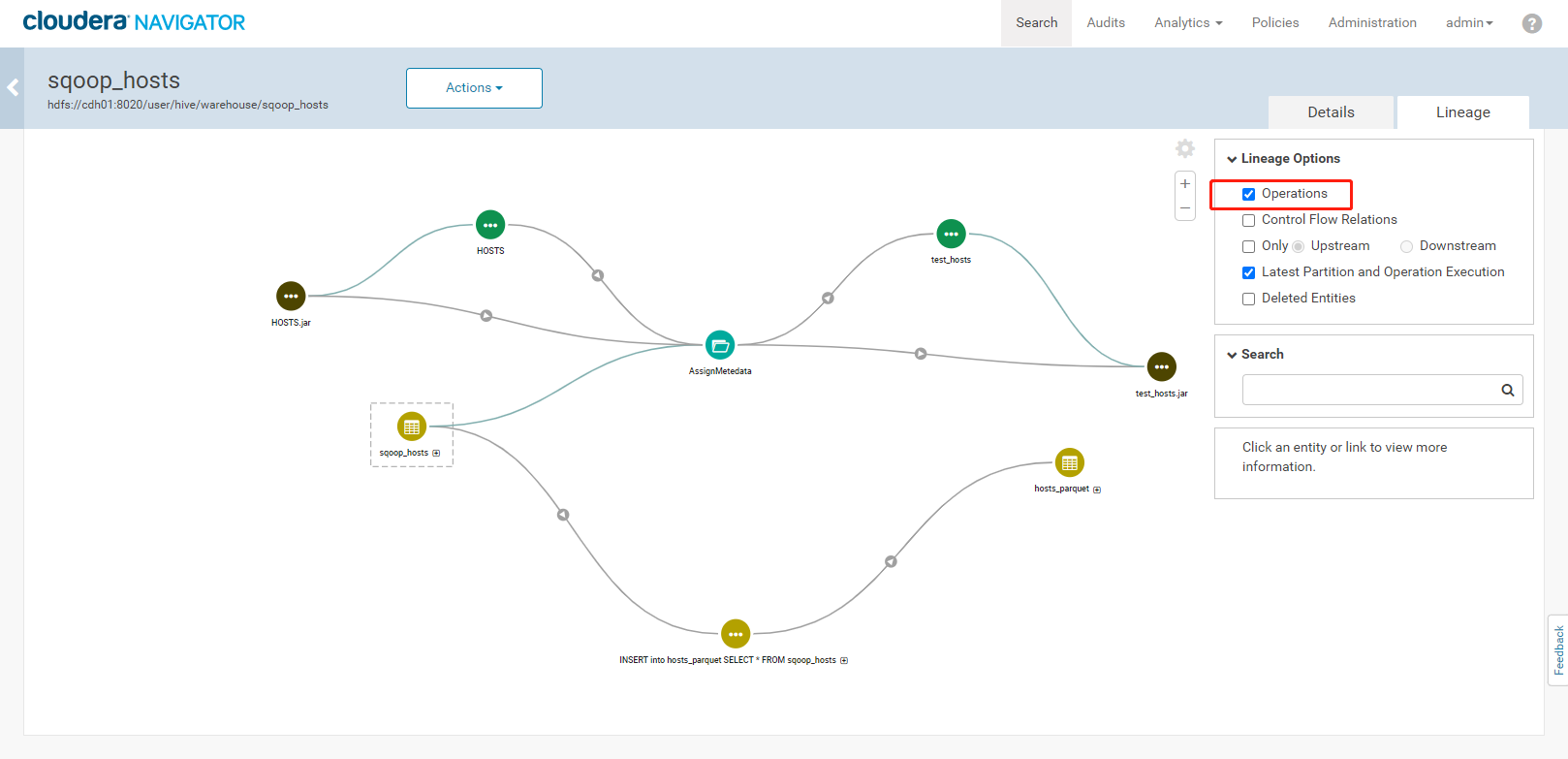6. 点击每一个节点可以查看到当前节点的详细描述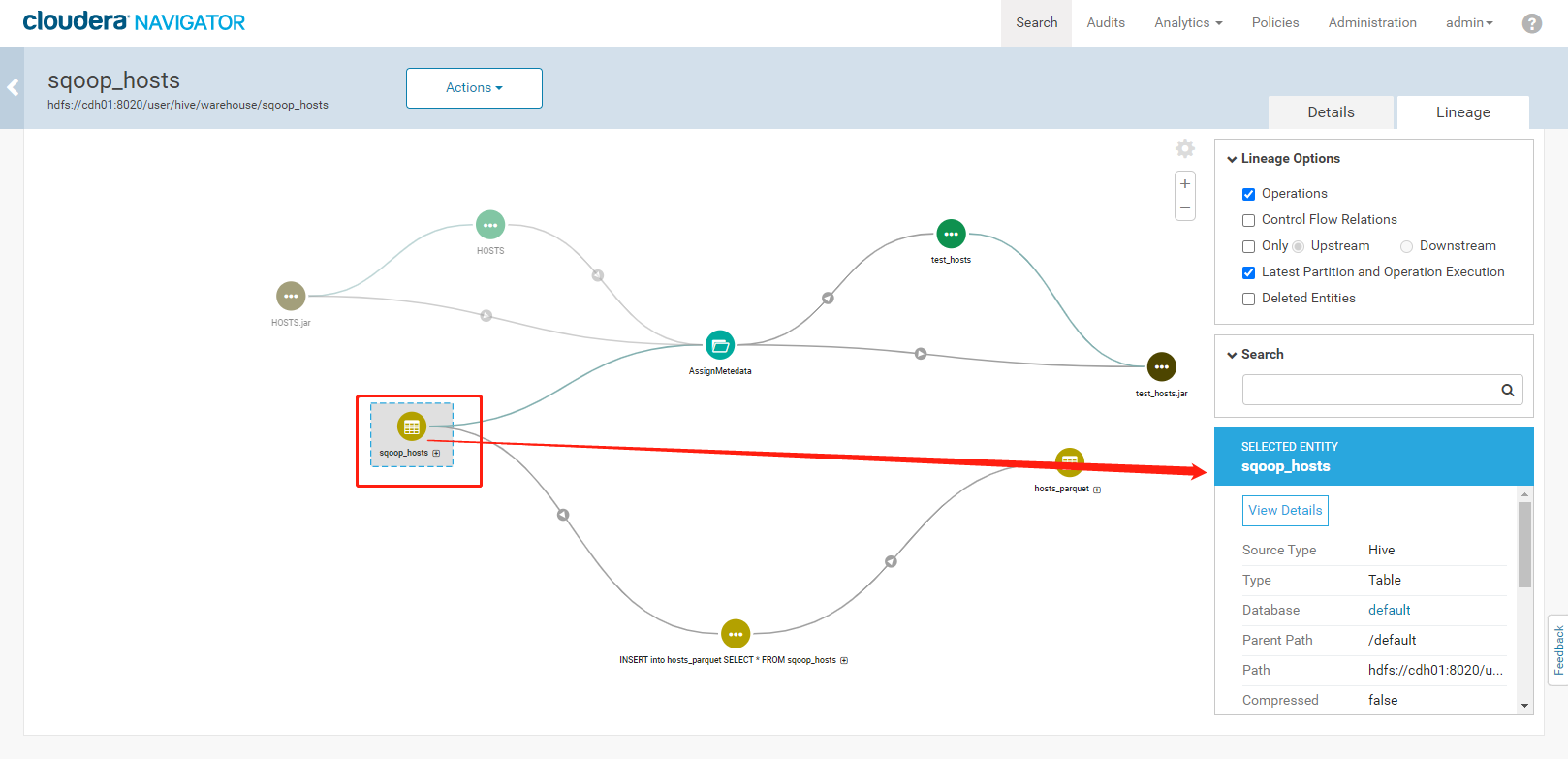7. 可以精确到每个字段的数据流向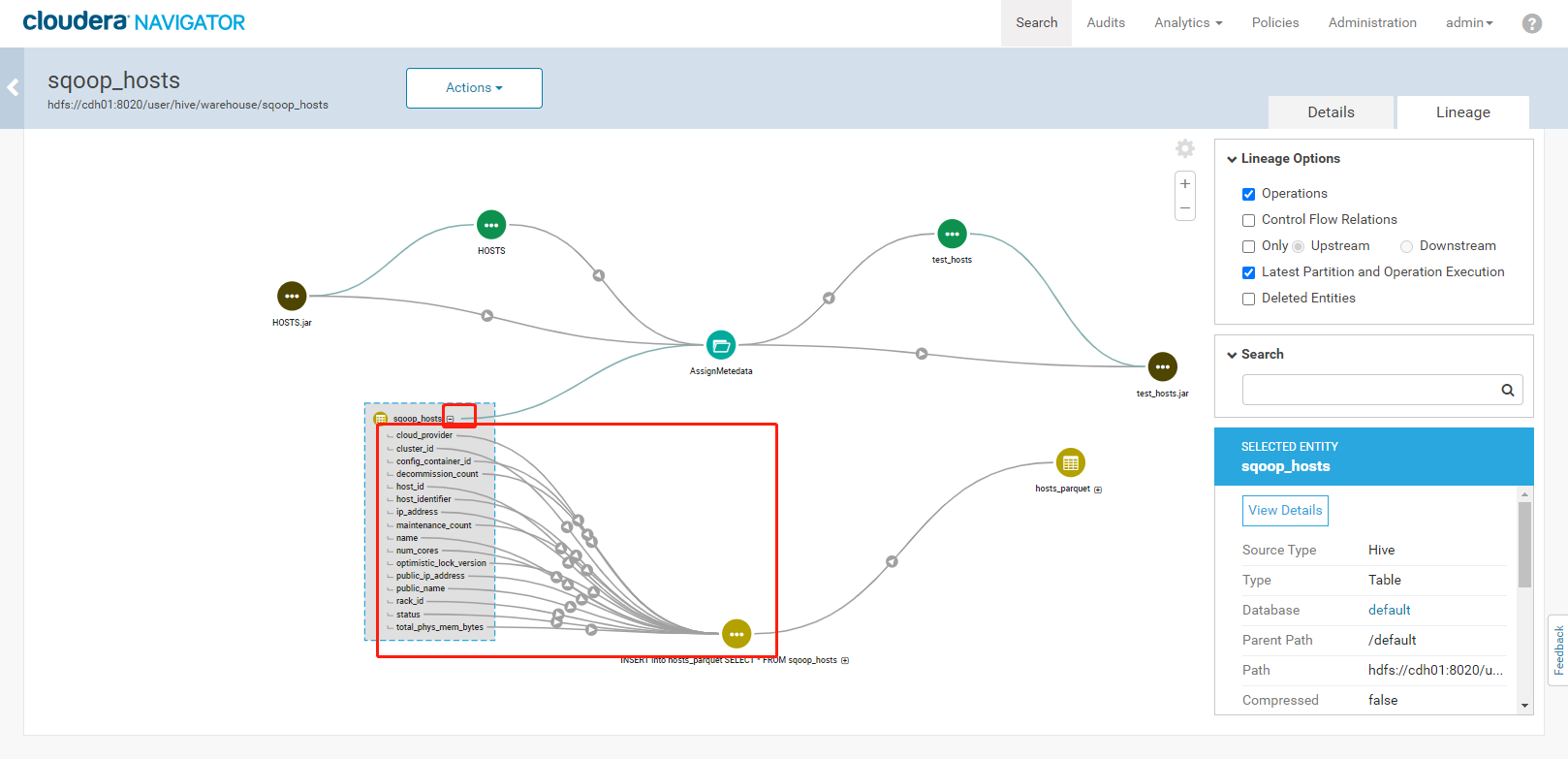<a name="FLdMu"></a>## 4、审计功能1. 我们命令行使用hdfs用户访问有权限的HDFS目录
kinit hdfs hadoop fs -ls /user/hive/warehouse
2. 登录Cloudera Manager Navigator进入【Audits】功能,添加筛选条件查看审计功能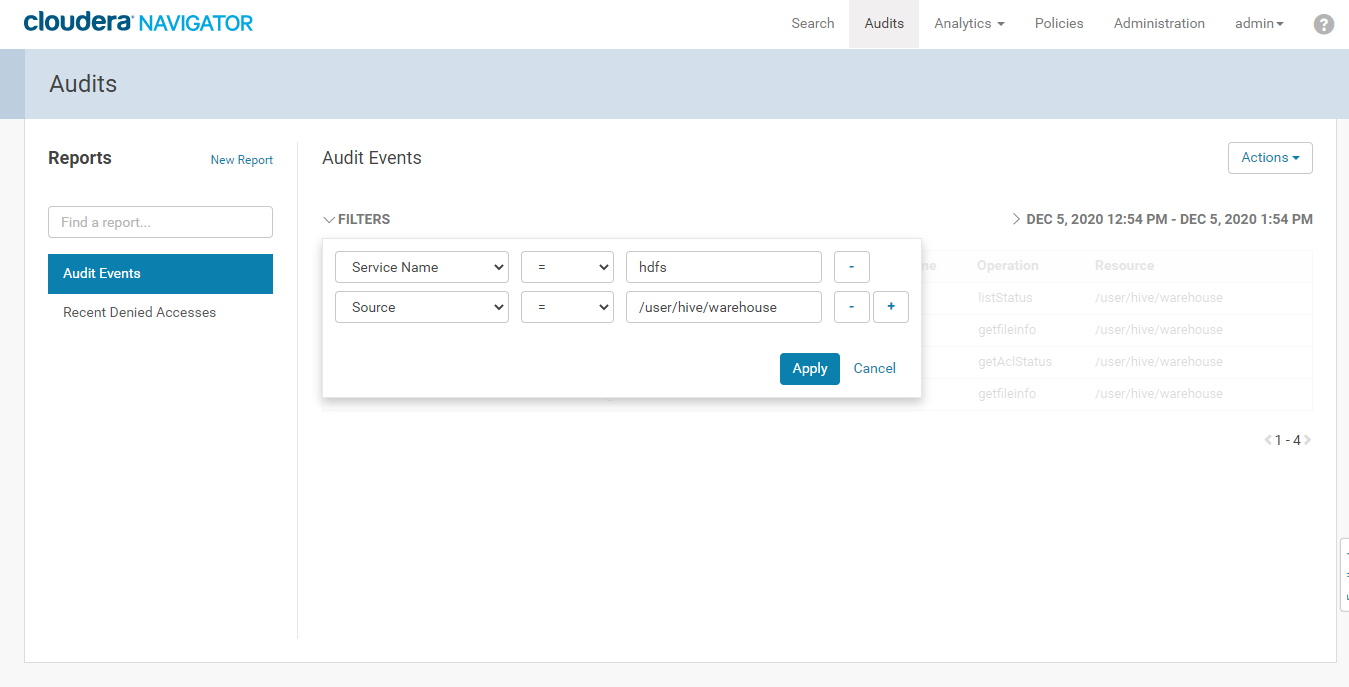3. 点击【Apply】,可以看到我们操作HDFS的/user/hive/warehouse的审计日志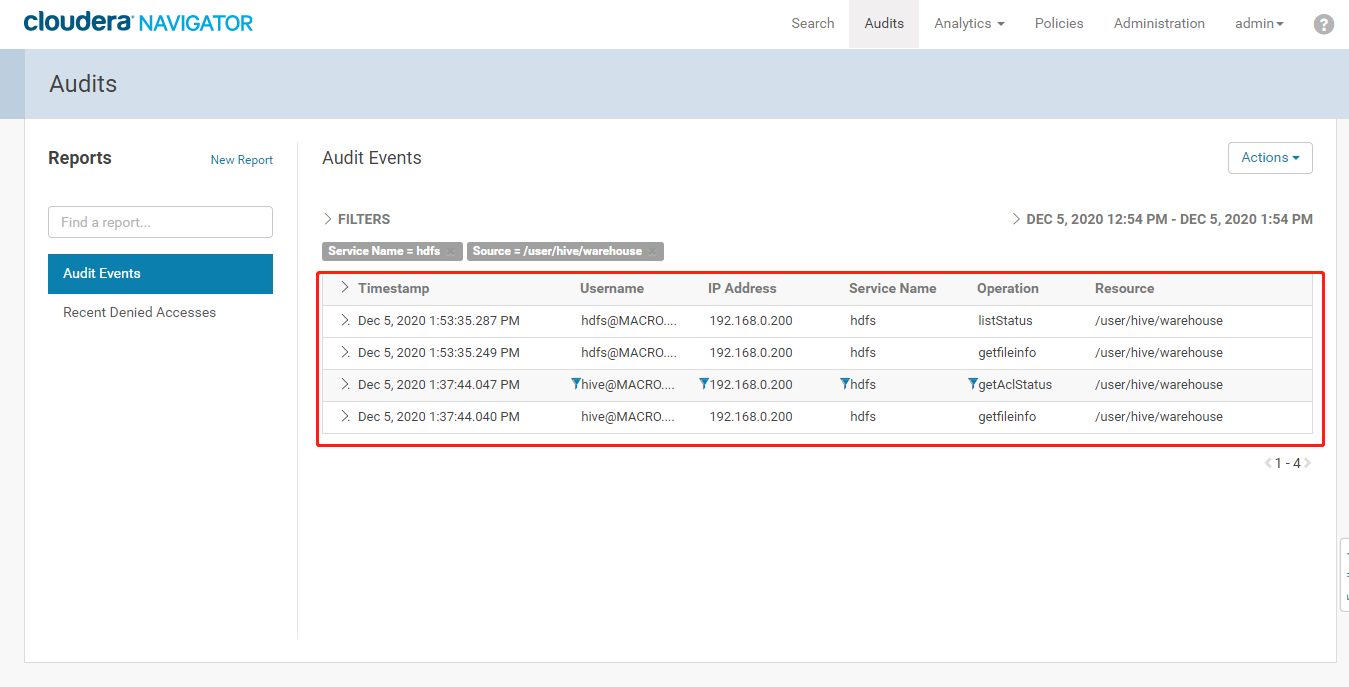4. 使用user_w用户查看无访问权限的HDFS目录
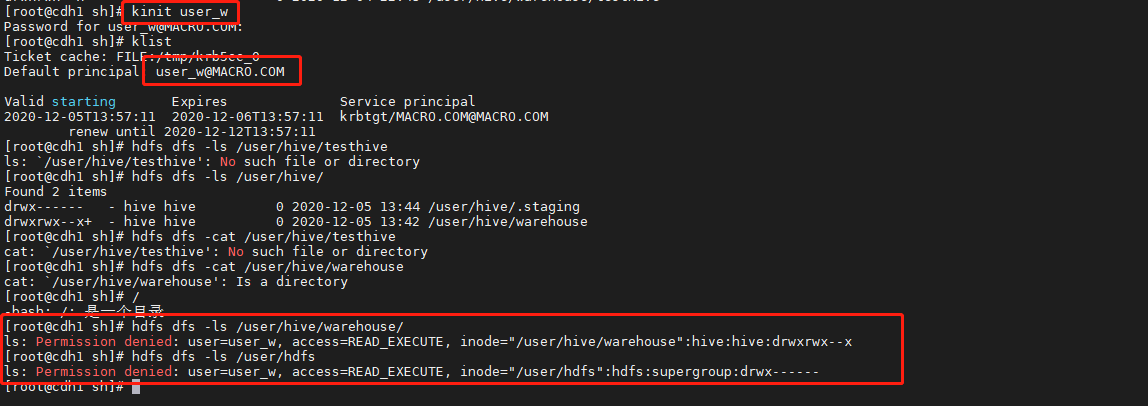
kinit user_w
klist
hdfs dfs -ls /user/hdfs
```
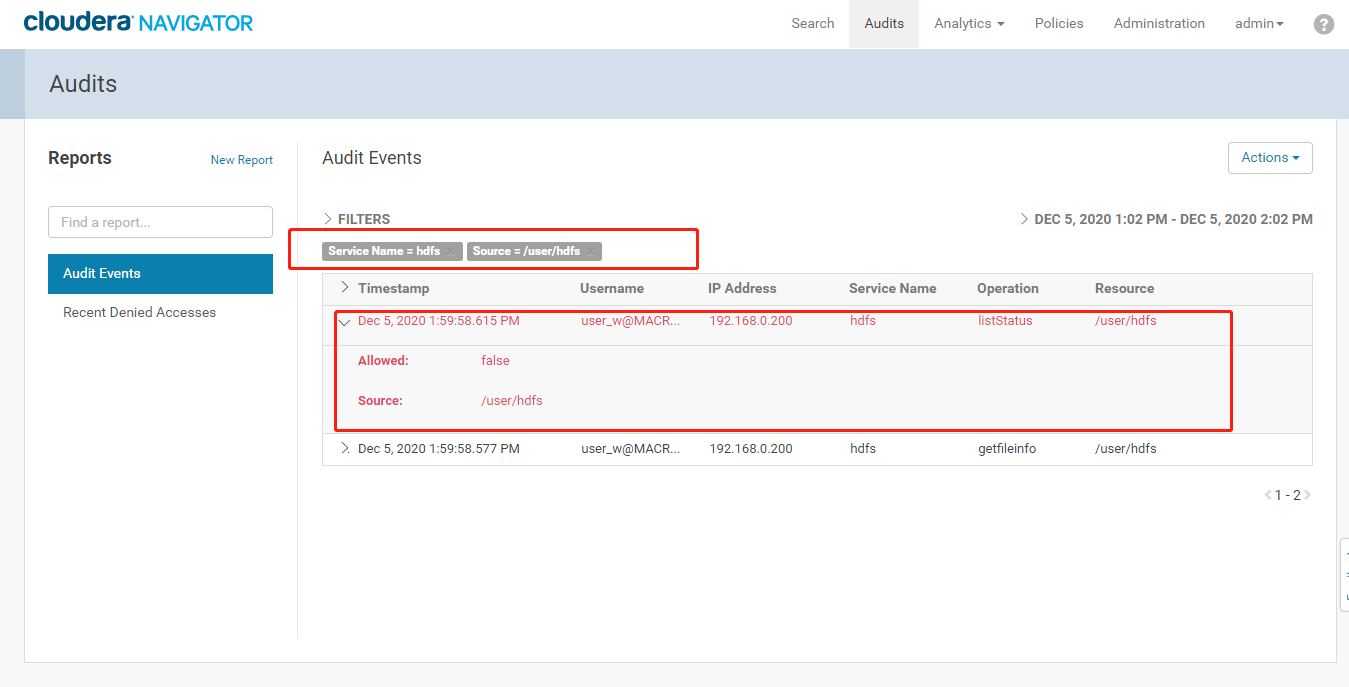
- 查看Cloudera Manager Navigator的审计日志,添加筛选条件,点击“Apply”,查看审计日志,可以看到有记录用户无权限访问该目录的日志
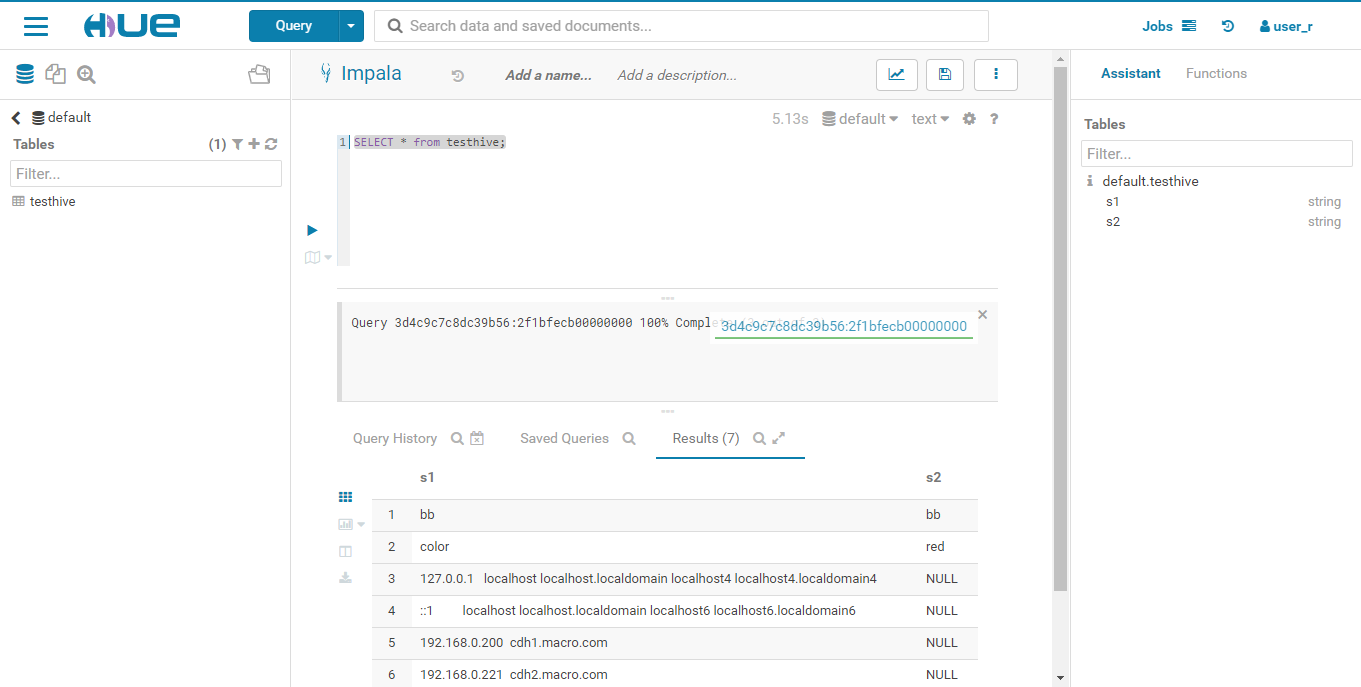
- 使用user_r用户登录Hue进行SQL操作,访问有权限的testhive表
- 登录Navigator查看审计日志
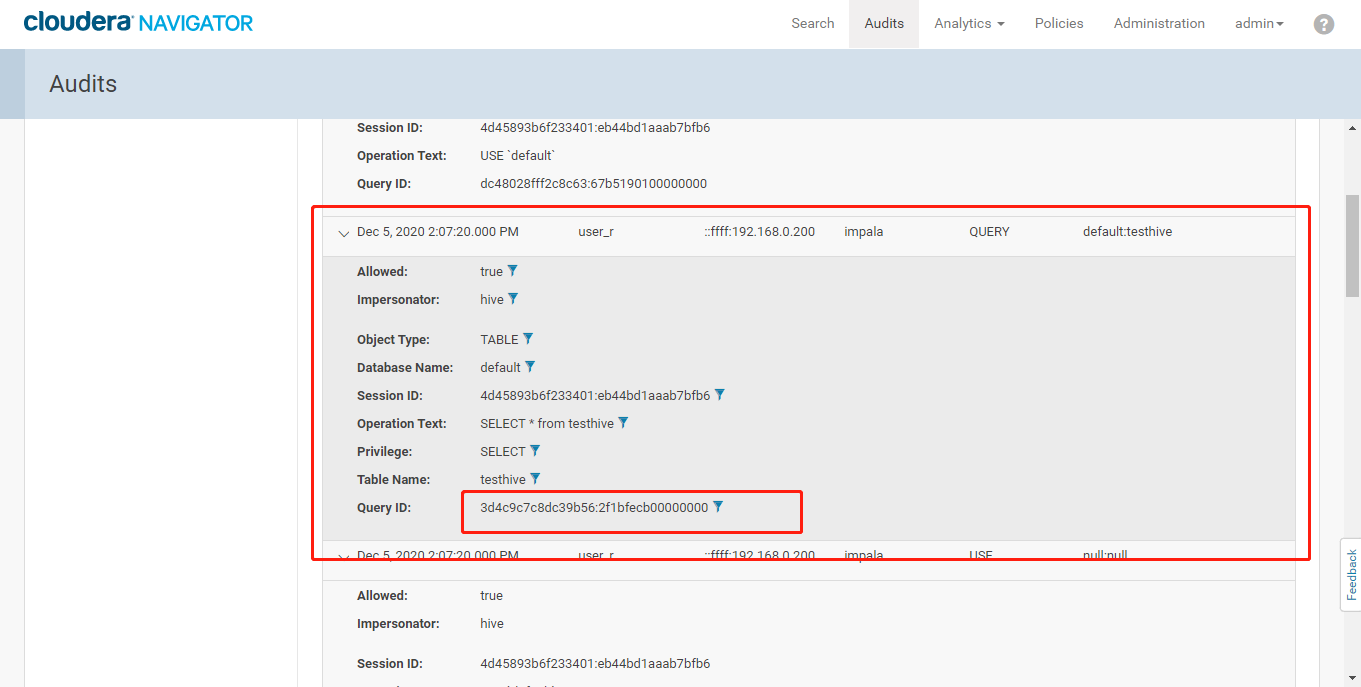
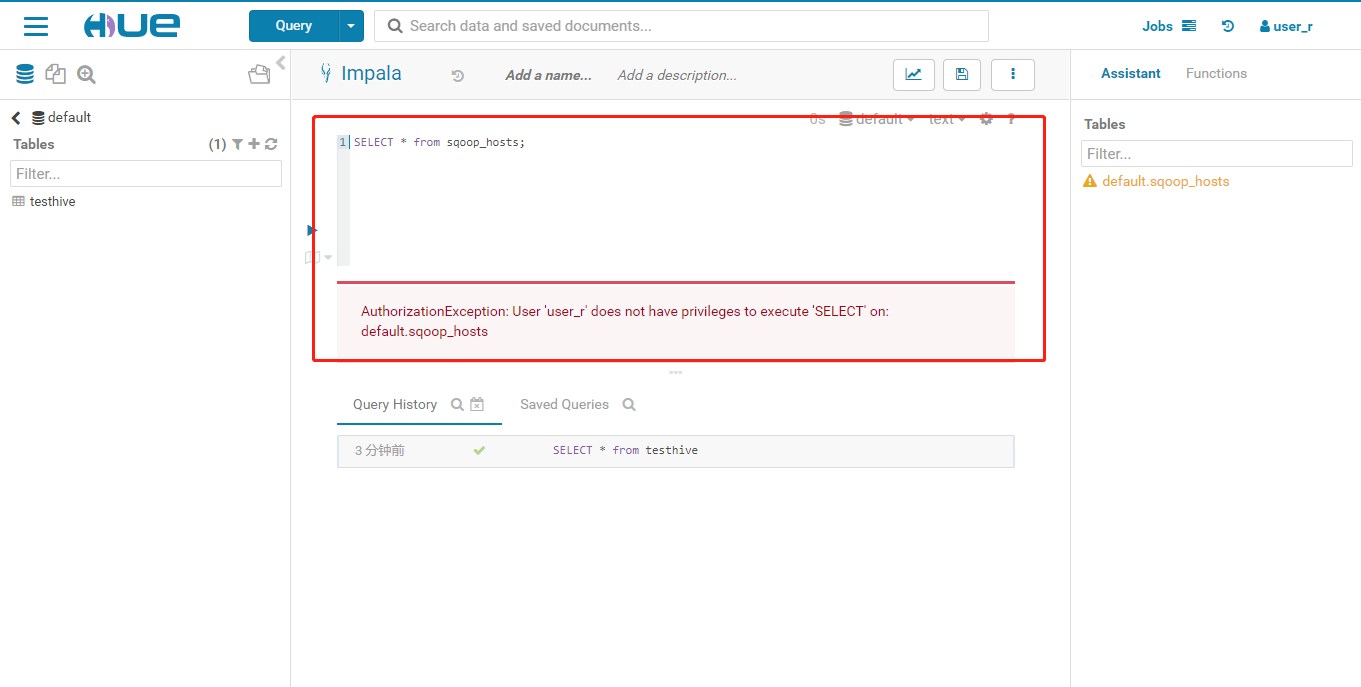
- 操作无权限访问的sqoop_hosts表
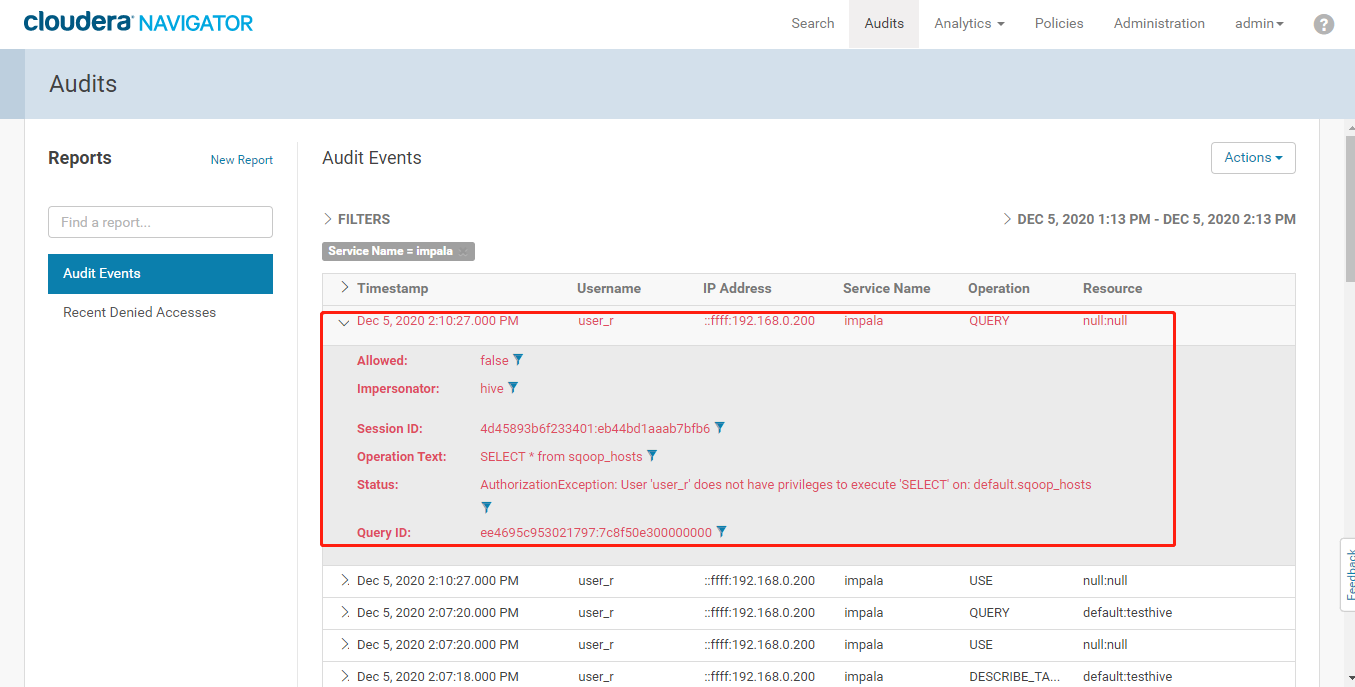
- 登录Navigator查看审计日志
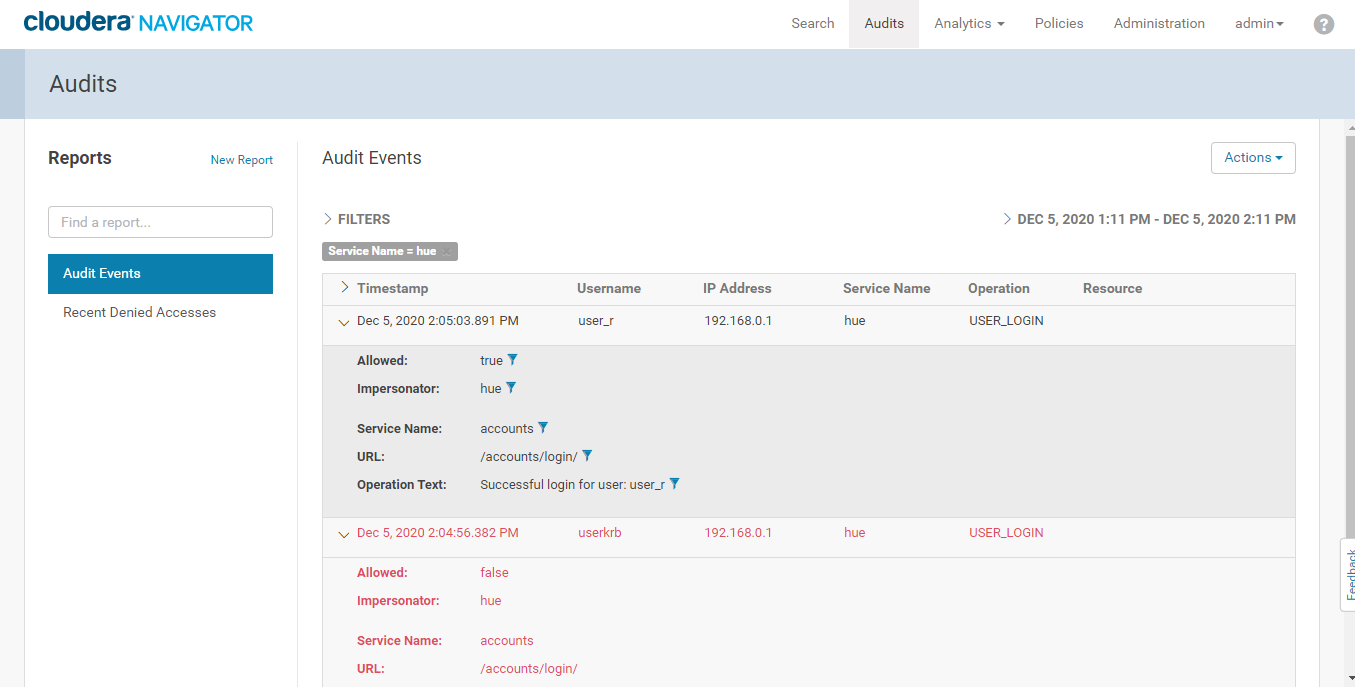
- 同样Cloudera Manager Navigator可以对系统登录等操作进行审计,这里以Hue为例
5、数据生命周期管理
- 登录Navigator平台,点击【Policies】进入数据生命周期管理界面
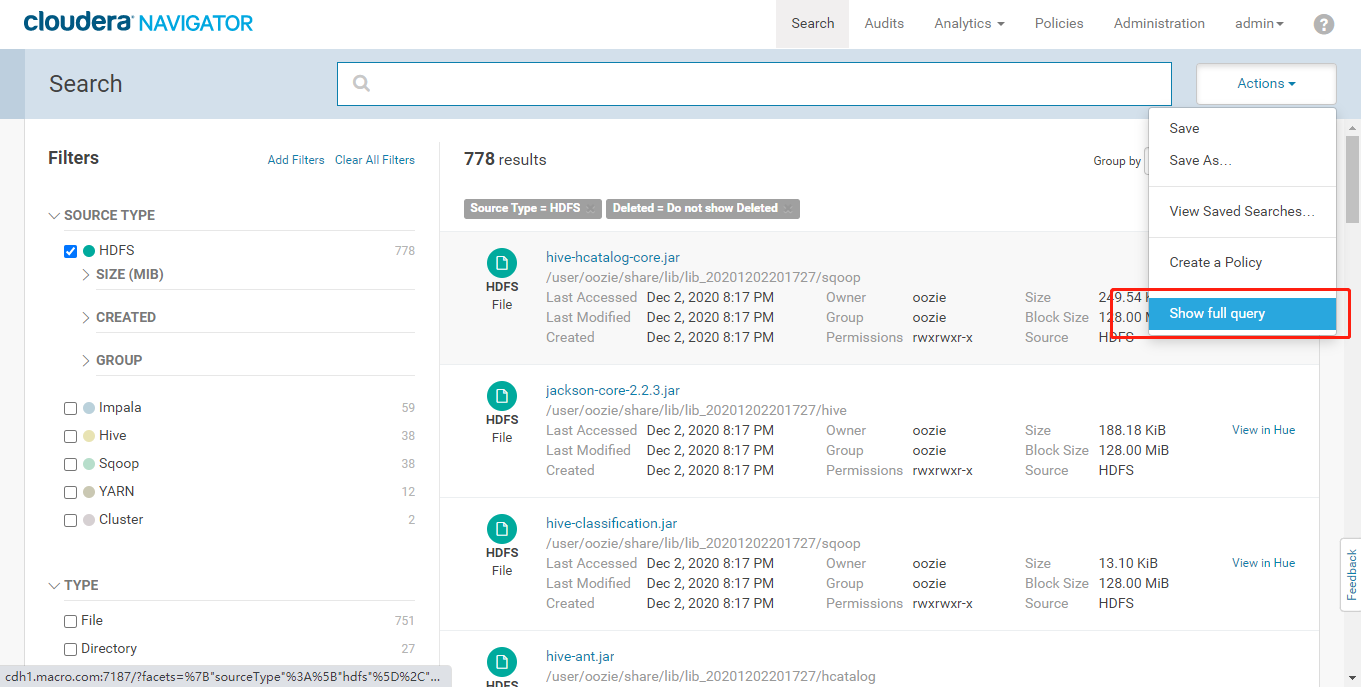
- 查看【Search Query】查询条件,点击【Show full query】
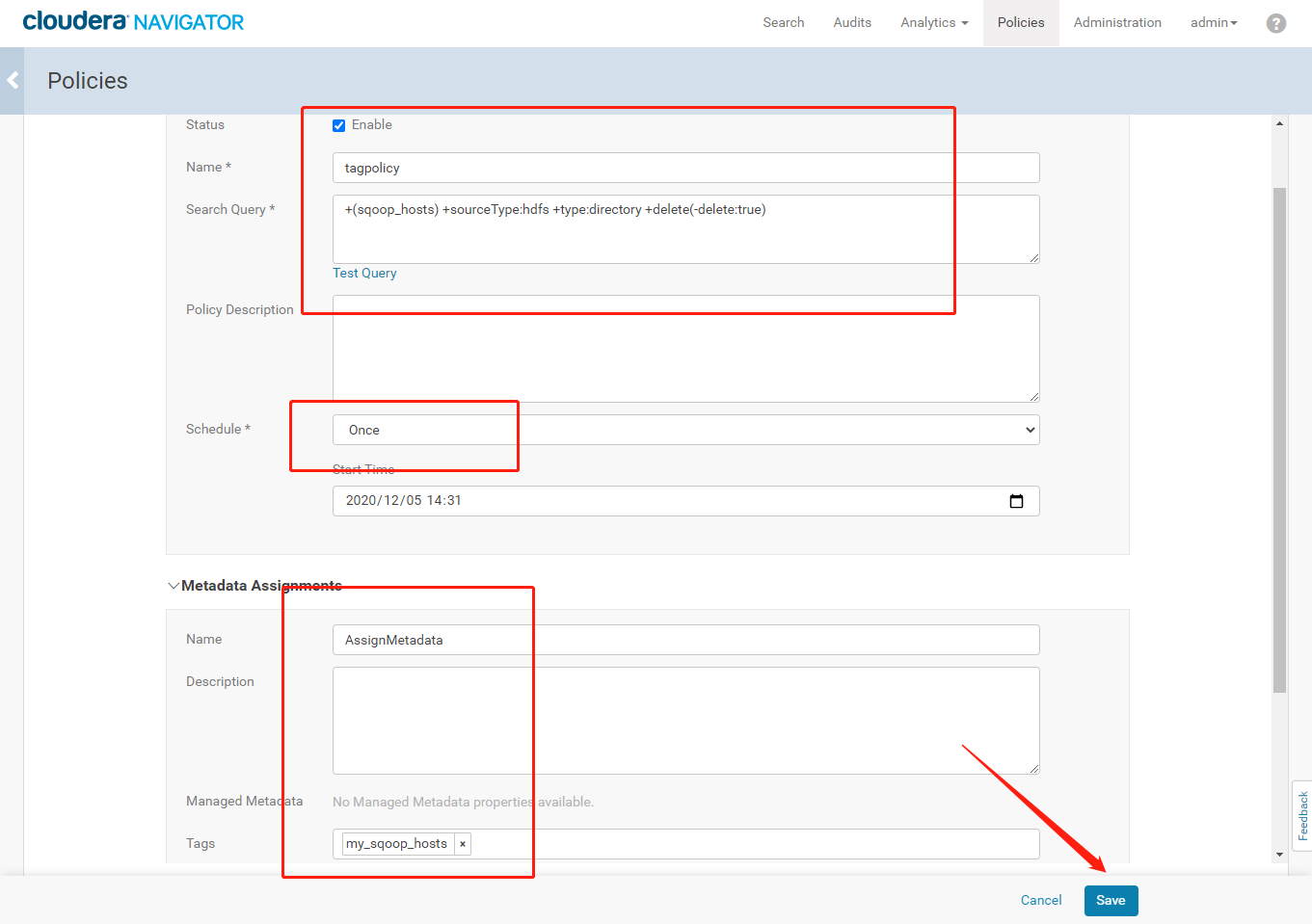
- 点击【New Policy】创建一个自动分类标签的策略,点击【Save】保存策略
- 查看自动分类标签策略运行情况
6.总结
- Navigator提供了完整的元数据检索功能。可以通过搜索表名,文件名等都可以搜索出相关所有涉及的内容,包括文件路径,创建时间,创建人等。可以根据数据来源组件,操作,表等分类进行查询。可以为数据集添加标签(tag) ,支持基于标签的搜索。
- Navigator提供了完成了集群审计功能(含数据操作,权限控制、登录等)
- Navigator提供完整的数据血缘分析,通过可视化界面方便的查看数据详细的进入HDFS到流出的一系列过程。
- Navigator提供创建策略的方式来管理数据的生命周期,如为数据添加Tag、归档数据等策略。

若有收获,就点个赞吧
0 人点赞
