大数据基础平台POC测试
一、目标
针对大数据基础平台升级迁移项目,对交流厂商提供的产品功能进行验证,以对厂商提供的产品做进一步了解;
本POC重点在于考察厂商提供的产品与我行大数据平台的兼容效果,功能是否满足我行对大数据平台的可靠性、安全性、易用性等功能需求。数据来源可基于我行现有测试环境数据或TPC-DS脚本生成模拟数据。
二、考核指标
1、技术平台实现(15分)
确认厂商提供的产品与我行大数据平台的兼容效果,数据迁移兼容性测试,ETL任务迁移兼容性测试。
2、功能性测试(25分)
3、产品管理和维护能力(25分)
自动升级功能测试,集群管理简易性测试,集群统一管理和统一监控测试。
4、产品处理能力和性能(25分)
5、高可用性测试 (10分)
三、测试环境
1、硬件资源
| 服务器 | 配置 |
|---|---|
| 管理节点 | |
| 节点数量 | 1 |
| cp | 3Core |
| 内存 | 16GB |
| 硬盘 | 数据盘1T*1 |
| 数据节点 | |
| 节点数量 | 2 |
| cpu | 3Core |
| 内存 | 16GB |
| 硬盘 | 数据盘1T*1 |
2、软件环境
| 软件名称 | 描述 |
|---|---|
| 操作系统 | Red Hat7.7 |
| CDP | CDP7.1.4 |
| Hadoop | Hadoop 3.1.1-cdp7.1.4 |
| JDK | jdk1.8.0_144 |
3、集群环境
3.1 CM版本为7.1.4,CDH版本为7.1.4,通过rpm包进行安装。
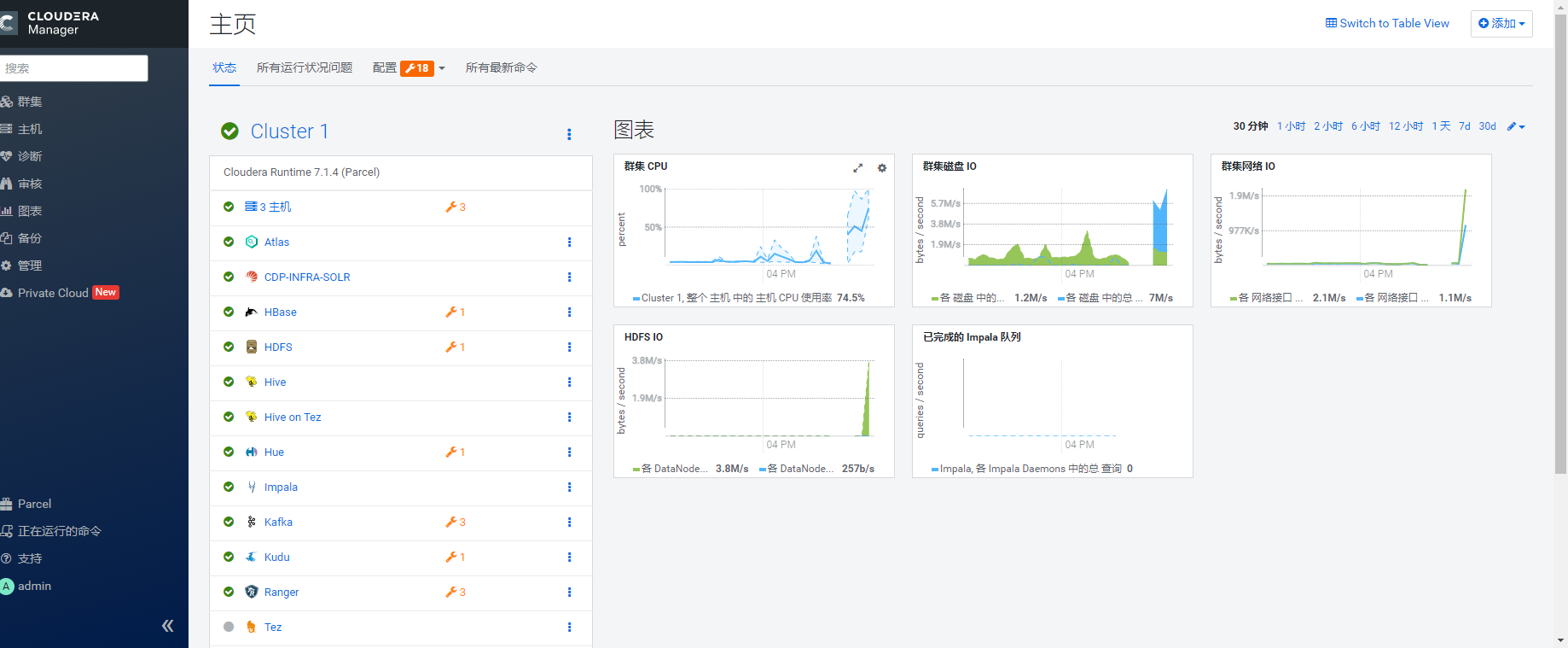
3.2 节点信息如下:
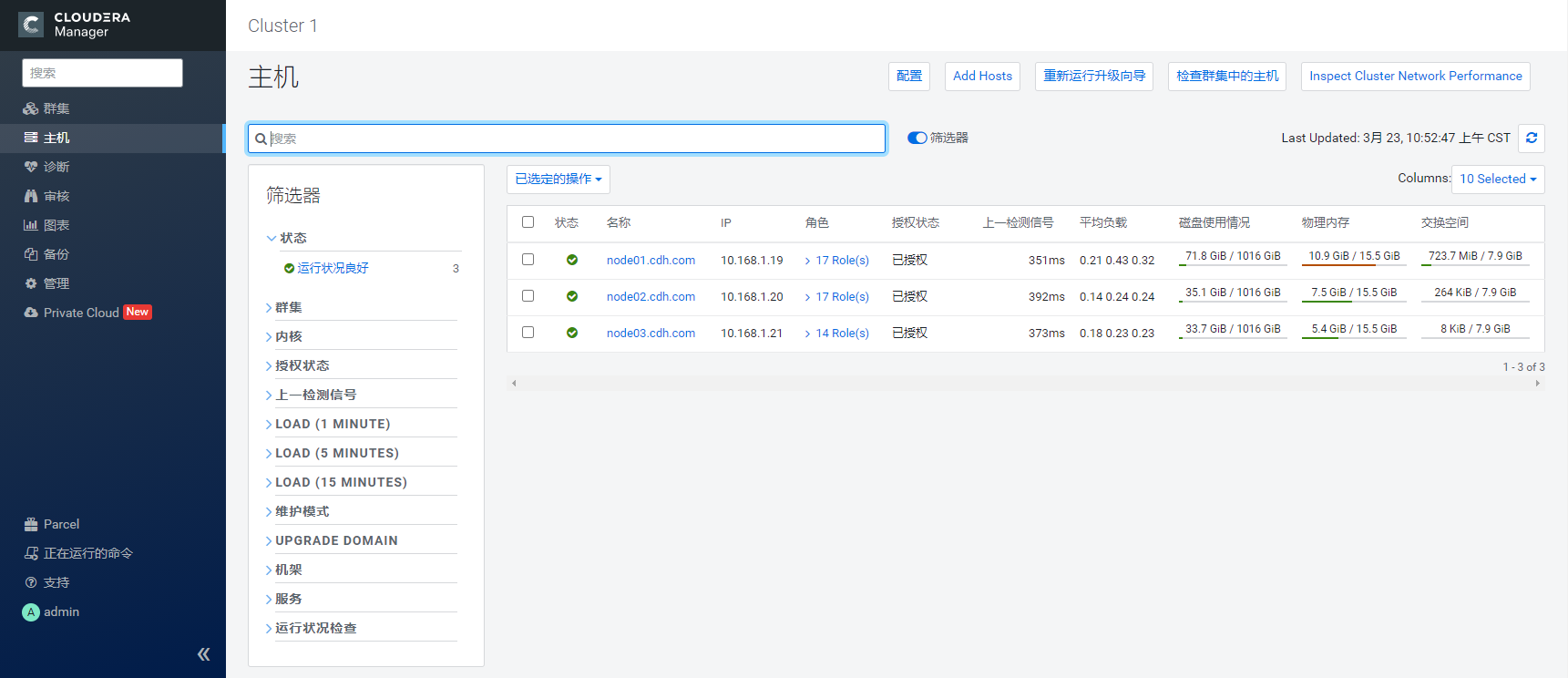
3.3 集群各服务分配如下:
| 主机名 | ip地址 | 安装服务 |
|---|---|---|
| node01.cdh.com | 10.168.1.19 | Atlas Server HBase RegionServer HDFS DataNode Hive Gateway Hue Load Balancer Hue Server Impala Daemon YARN Queue Manager Store YARN Queue Manager Webapp Ranger Admin Ranger Tagsync Ranger Usersync Tez Gateway YARN (MR2 Included) JobHistory Server YARN (MR2 Included) NodeManager YARN (MR2 Included) ResourceManager ZooKeeper Server |
| node02.cdh.com | 10.168.1.20 | HBase RegionServer HDFS Balancer HDFS DataNode HDFS NameNode HDFS SecondaryNameNode Hive Gateway Hive Metastore Server Hive on Tez HiveServer2 Impala Daemon Cloudera Management Service Alert Publisher Cloudera Management Service Event Server Cloudera Management Service Host Monitor Cloudera Management Service Reports Manager Cloudera Management Service Service Monitor Tez Gateway YARN (MR2 Included) NodeManager ZooKeeper Server |
| node03.cdh.com | 10.168.1.21 | HBase Master HBase RegionServer HDFS DataNode Hive Gateway Impala Catalog Server Impala Daemon Impala StateStore Kafka Broker Kudu Master Kudu Tablet Server Solr Server Tez Gateway YARN (MR2 Included) NodeManager ZooKeeper Server |
四、测试用例
1、技术平台实现功能测试
1.1 数据迁移、ETL任务的兼容性测试
| 测试编号 | UseCase001 |
|---|---|
| 测试项目 | 数据迁移 |
| 测试目的 | 数据迁移的兼容性、ETL任务的兼容性 |
| 测试环境 | 大数据平台测试环境 |
| 前置条件 | 大数据平台安装 |
| 测试步骤 | 1. 将现有大数据平台的数据迁移到POC集群中,观察数据兼容性 1. 运行单表抽数ETL 作业、多表关联ETL 作业 |
| 预期结果 | 1. 操作都能顺利完成,可以获得结果 1. 业务无中断、无损失 1. 所有表操作正常 |
| 测试结果 | 1. 操作都能顺利完成,可以获得结果 1. 业务无中断、无损失 1. 所有表操作正常 |
| 备注 |
1.1.2 测试步骤
现有大数据平台的数据迁移到POC集群中,执行distcp 命令 将数据从19节点数据到13节点数据。
Hadoop distcp -Dmapreduce.job.queuename=userName -Dmapreduce.job.name=jobName hdfs:///user/data/ hdfs://10.168.1.13:8020/user
执行结果
1.1.3 测试结果
1、操作都能顺利完成,可以获得结果
2、业务无中断、无损失
3、所有表操作正常
2、可靠性和安全性
2.1 HDFS安全访问测试
| 测试编号 | UseCase002 |
|---|---|
| 测试项目 | HDFS用户管理认证测试 |
| 测试目的 | 测试在Kerberos认证组件支持下,HDFS具有用户认证的功能,合法的用户可以进行操作,非法用户不能进行操作 |
| 测试环境 | 大数据平台测试环境 |
| 前置条件 | HDFS启用安全功能,并已经正常工作。 集群已经启用 Kerberos 认证 |
| 测试步骤 | 1. 测试没有认证的用户,无法进行HDFS操作 1. 测试经过认证的用户,HDFS操作成功 |
| 预期结果 | 支持 kerberos 身份认证体系, 只用经过认证的用户才能够访问HDFS平台。 |
| 测试结果 | 支持 kerberos 身份认证体系, 只用经过认证的用户才能够访问HDFS平台。 |
| 备注 |
2.1.1 测试详细步骤
- 测试没有认证的用户,无法进行 HDFS 操作
a. 先清空kerberos的tickets cache。
kdestroy
b. 执行:hadoop fs -mkdir /user/test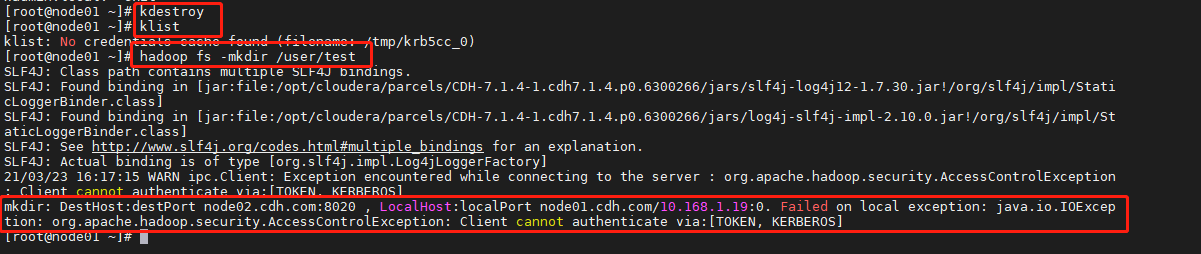
- 测试经过认证的用户,可以进行hdfs操作
a. 创建并执行hdfs用户的凭据:
kadmin.localaddprinc hdfs@CDH.COM# 输入密码exit

b. 登录hdfs的principal
kinit hdfshadoop fs -mkdir /user/testhadoop fs -ls /user/

2.2 Hive授权测试(行级)
| 测试编号 | UseCase003 |
|---|---|
| 测试项目 | Hive收取按测试(行级) |
| 测试目的 | 验证数据处理技术的数据安全控制 |
| 测试环境 | 大数据平台测试环境 |
| 前置条件 | 1. 集群正常运行 1. 已经开启kerberos认证。 1. 为用户创建principal。 1. 创建用户ranger1;创建测试表ranger_test;假设ranger_test只有两列(id String,name String);插入测试数据(1,hive)。 1. 集群已经配置并启动Ranger组件。 1. 授权ranger1用户对表ranger_test有访问权限。 |
| 测试步骤 | 1. 在Ranger中配置行过滤策略,指定用户为ranger1,对ranger_test表的权限为select,过滤条件为name为hive的行 1. 用ranger1用户去查询数据 |
| 预期结果 | name为hive的行数据不能被显示 |
| 测试结果 | name为hive的行数据不能被显示 |
| 备注 |
2.2.1 测试详细步骤
- 在集群所有节点添加用户ranger1,创建该用户凭据。

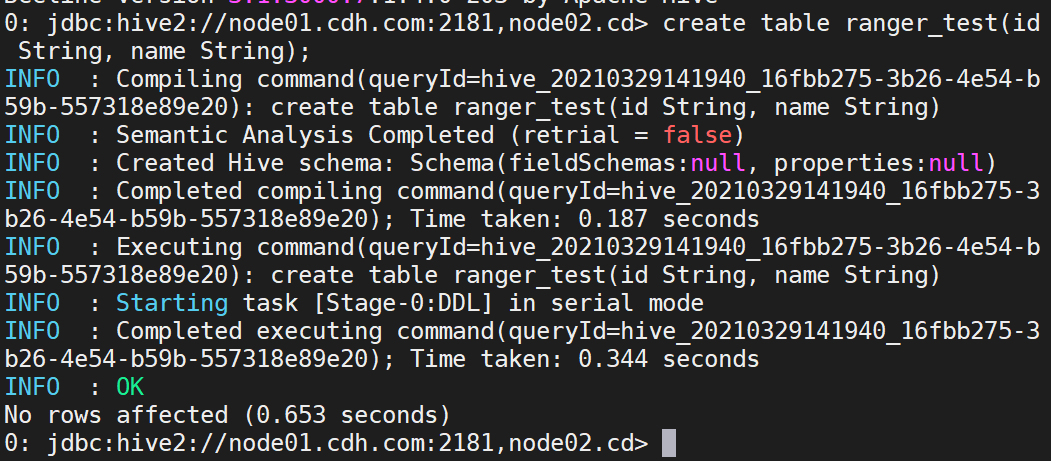
使用hive用户登录principal,创建对应表,添加测试数据。
create table ranger_test(id String, name String);
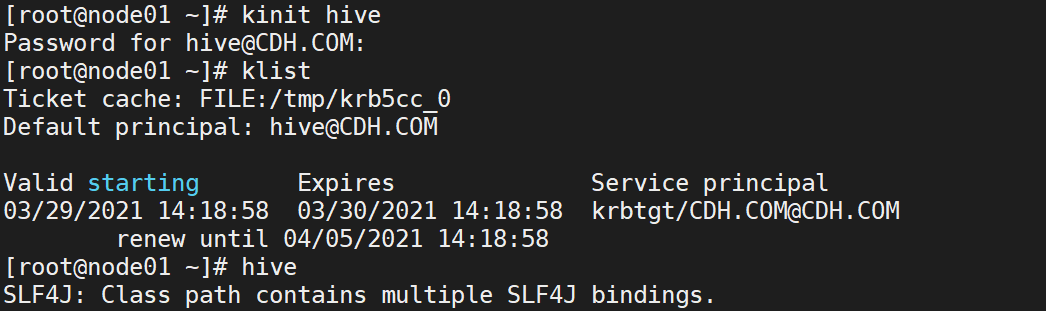
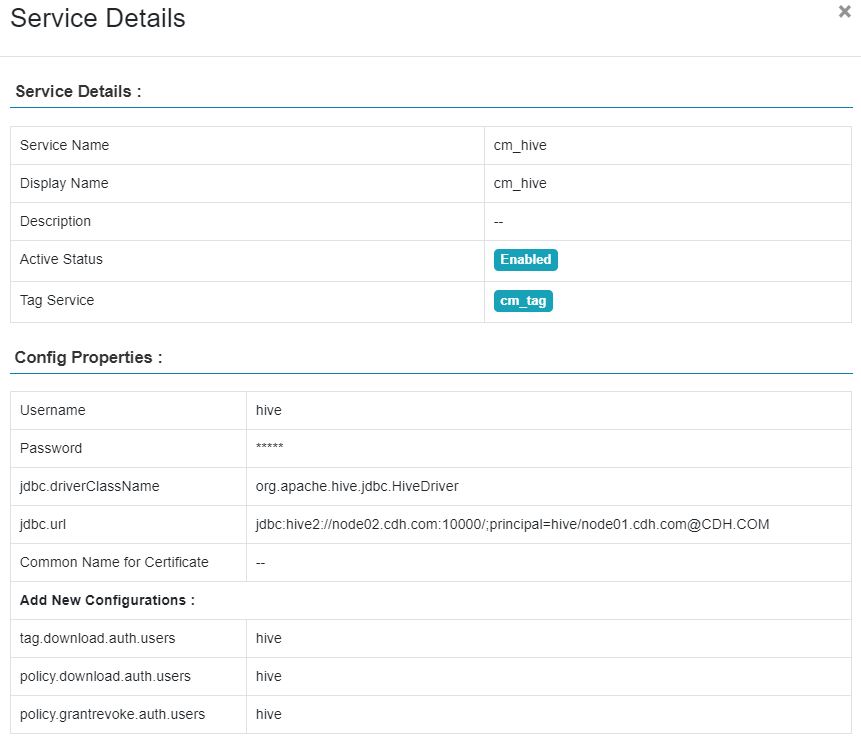
先创建一个service。
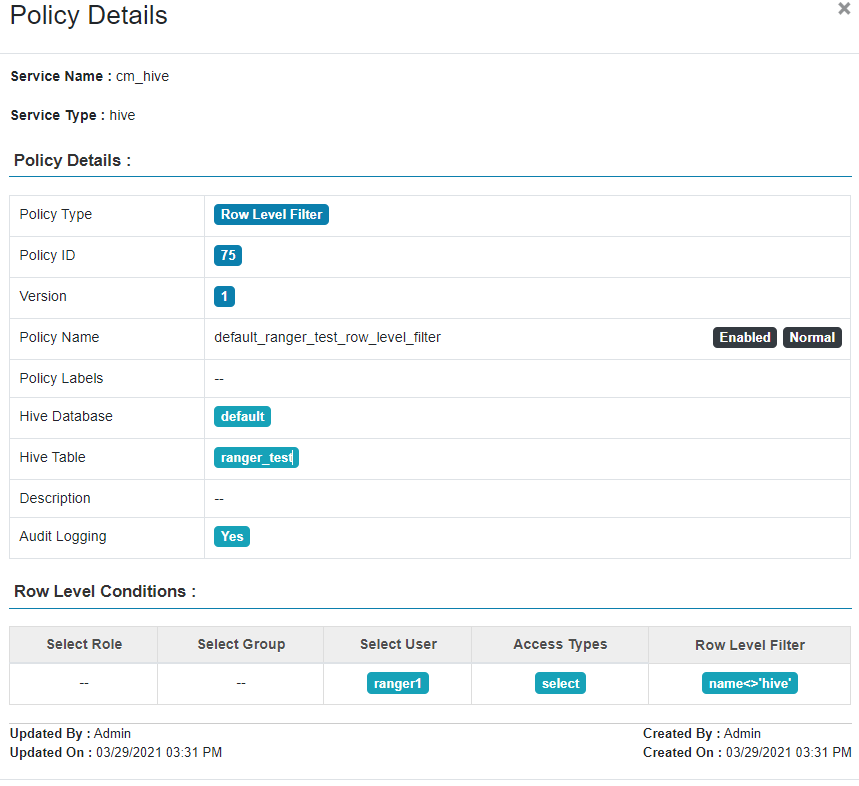
- 再创建policy使得用户ranger1有权限访问default数据库下的ranger_test表中name字段为”hive”的行,最后设置行过滤条件。
用hive用户插入数据
insert into ranger_test values('1','ranger'),('2','hive'),('3','hdfs');

切换ranger1用户,查询ranger_test查看执行结果。
a. name为‘hive’的数据被过滤掉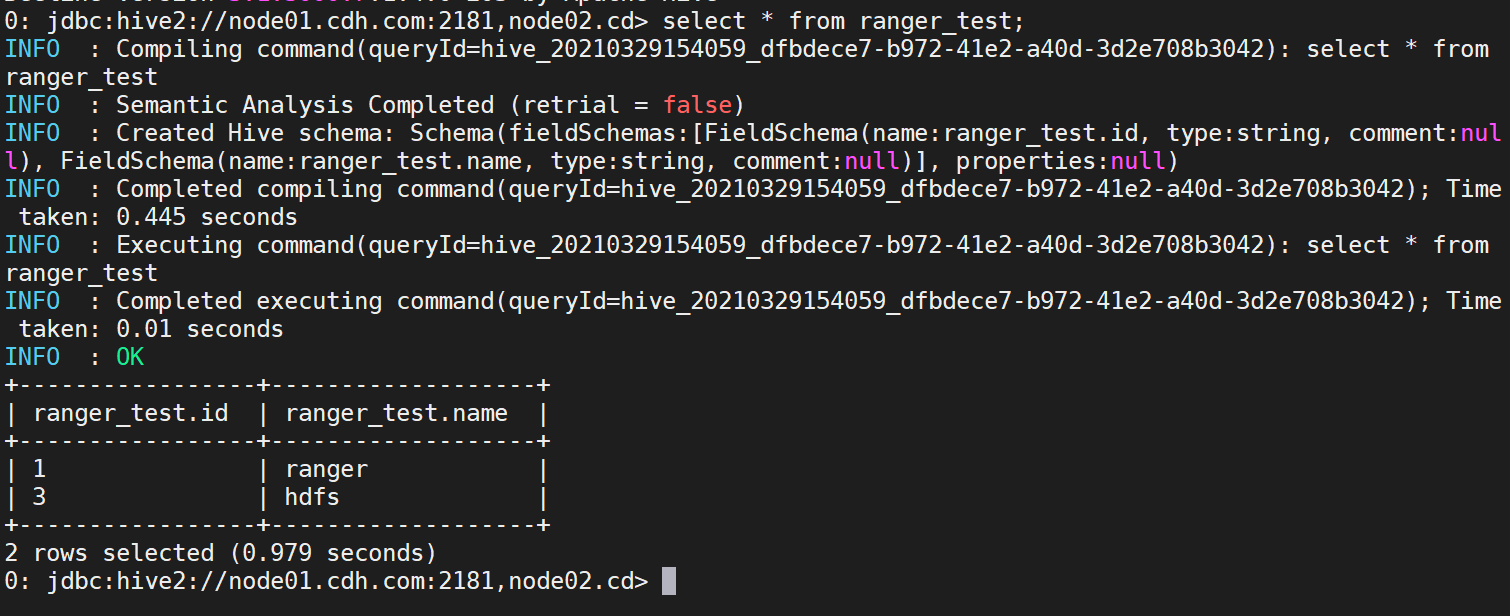
b. ranger1用户插入数据提示没有权限,ranger1用户只有select权限。
2.3 审计功能测试
| 测试编号 | UseCase004 |
|---|---|
| 测试项目 | 安全及数据治理测试 |
| 测试目的 | 验证厂商平台中是否会追踪用户数据访问的记录 |
| 测试环境 | 大数据平台测试环境 |
| 前置条件 | 大数据平台正常工作 |
| 测试步骤 | 1. 用户通过SQL引擎访问一个有权限的表 1. 用户通过SQL引擎访问一个没有权限的表 1. 用户通过HBase执行Get/Put操作 |
| 预期结果 | 1. 系统记录表正确访问的记录 1. 系统记录表无法访问的记录 1. 系统记录 HBase 的 put/get 操作的记录 |
| 测试结果 | 1. 系统记录表正确访问的记录 1. 系统记录表无法访问的记录 1. 系统记录 HBase 的 put/get 操作的记录 |
| 备注 |
2.3.1 测试详细步骤
- 环境准备
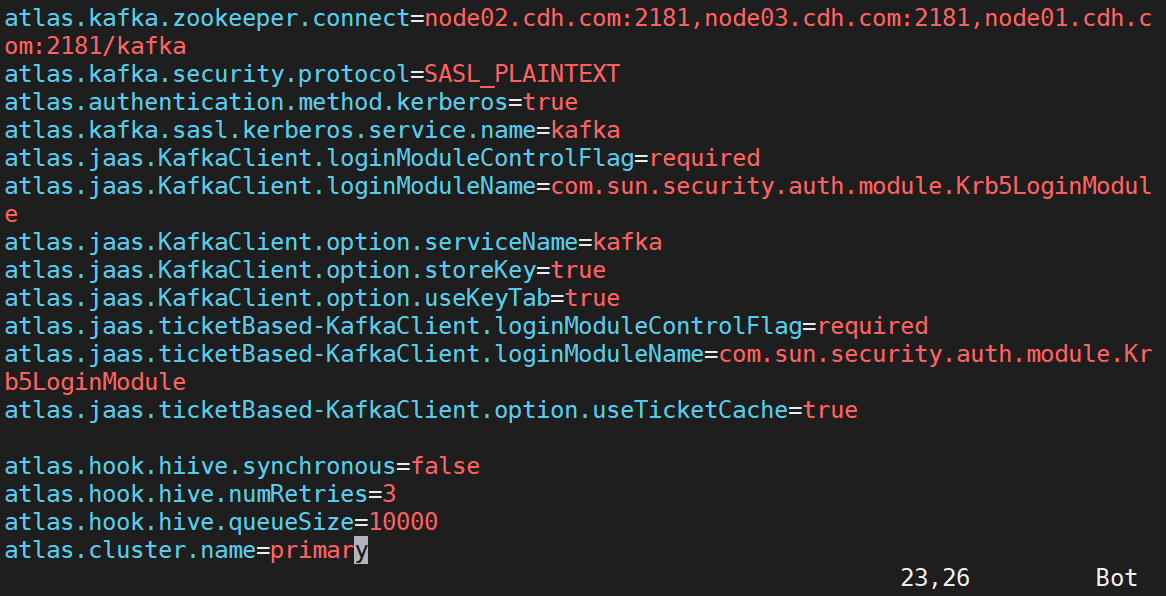
a. 找到atlas配置文件,添加hive配置参数 (/etc/atlas/conf.cloudera.atlas/atlas-application.properties)
atlas.hook.hiive.synchronous=falseatlas.hook.hive.numRetries=3atlas.hook.hive.queueSize=10000atlas.cluster.name=primary
b. 将atlas-application.properties配置文件加入到atlas-plugin-classloader-1.0.0.jar中
zip -u /opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/atlas-plugin-classloader-0.8.4.jar /etc/atlas/conf.cloudera.atlas/atlas-application.properties

c. 分发到其他节点
scp /opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/atlas-plugin-classloader-0.8.4.jar 10.168.1.20:/opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/scp /opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/atlas-plugin-classloader-0.8.4.jar 10.168.1.21:/opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/

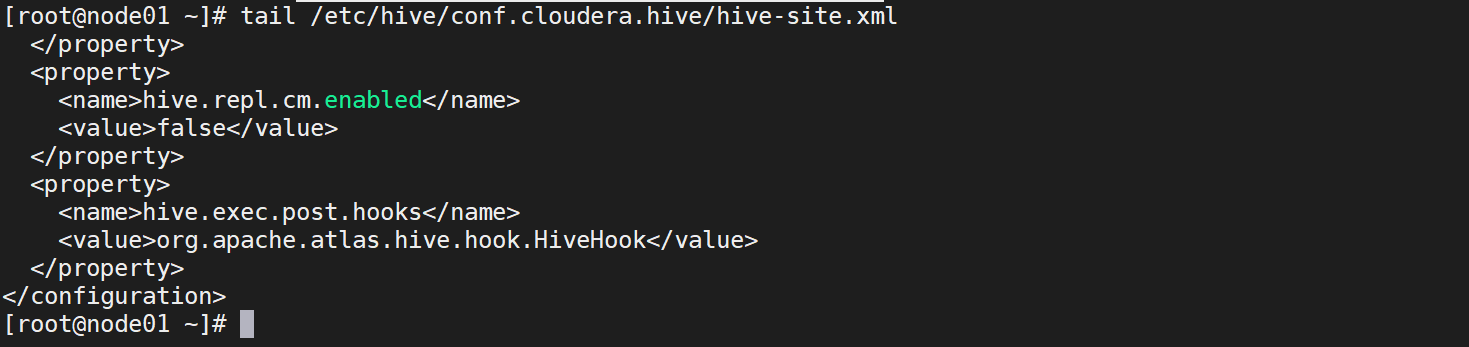
d. 所有hive节点:在/etc/hive/conf.cloudera.hive/hive-site.xml文件中设置Atlas hook修改配置文件,添加如下参数。
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook</value></property>
e. 修改/etc/hive/conf.cloudera.hive/hive-env.sh文件,追加hive插件相关jar包
export HIVE_AUX_JARS_PATH=/opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/atlas-plugin-classloader-0.8.4.jar,/opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook/hive/hive-bridge-shim-2.0.0.7.1.4.0-203.jar

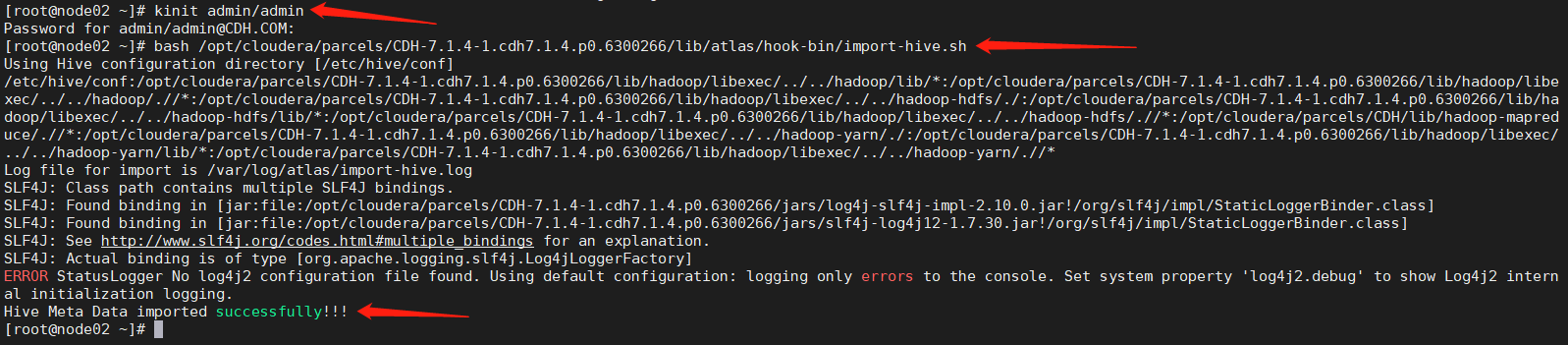
f. 通过脚本将hive元数据导入atlas (注意:启用kerberos之后需要kinit admin/admin用户)
bash /opt/cloudera/parcels/CDH-7.1.4-1.cdh7.1.4.p0.6300266/lib/atlas/hook-bin/import-hive.sh
- 元数据测试
a. 登录数据治理软件Atlas
b. 使用用户登录hive,通过sql查询一个有权限的表,以及无权限的表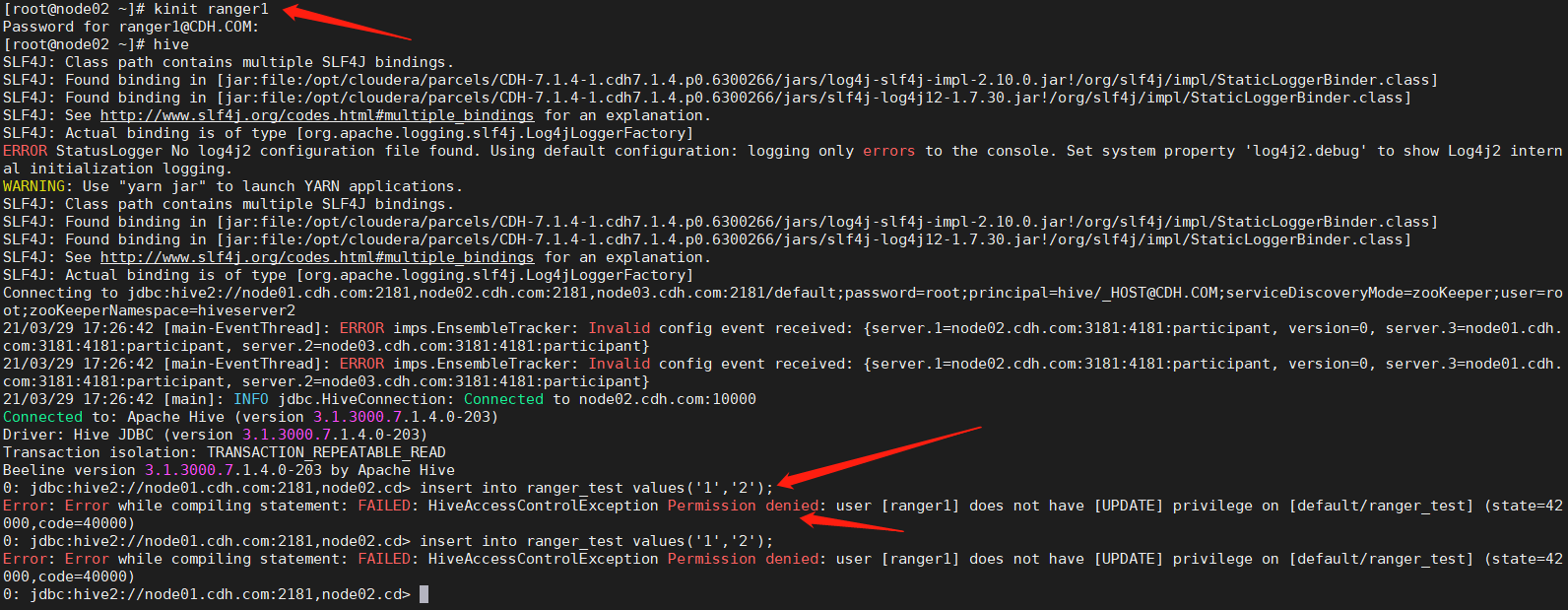
- 审计测试
a. 查看审计信息,其中用户访问有权限的表的审计信息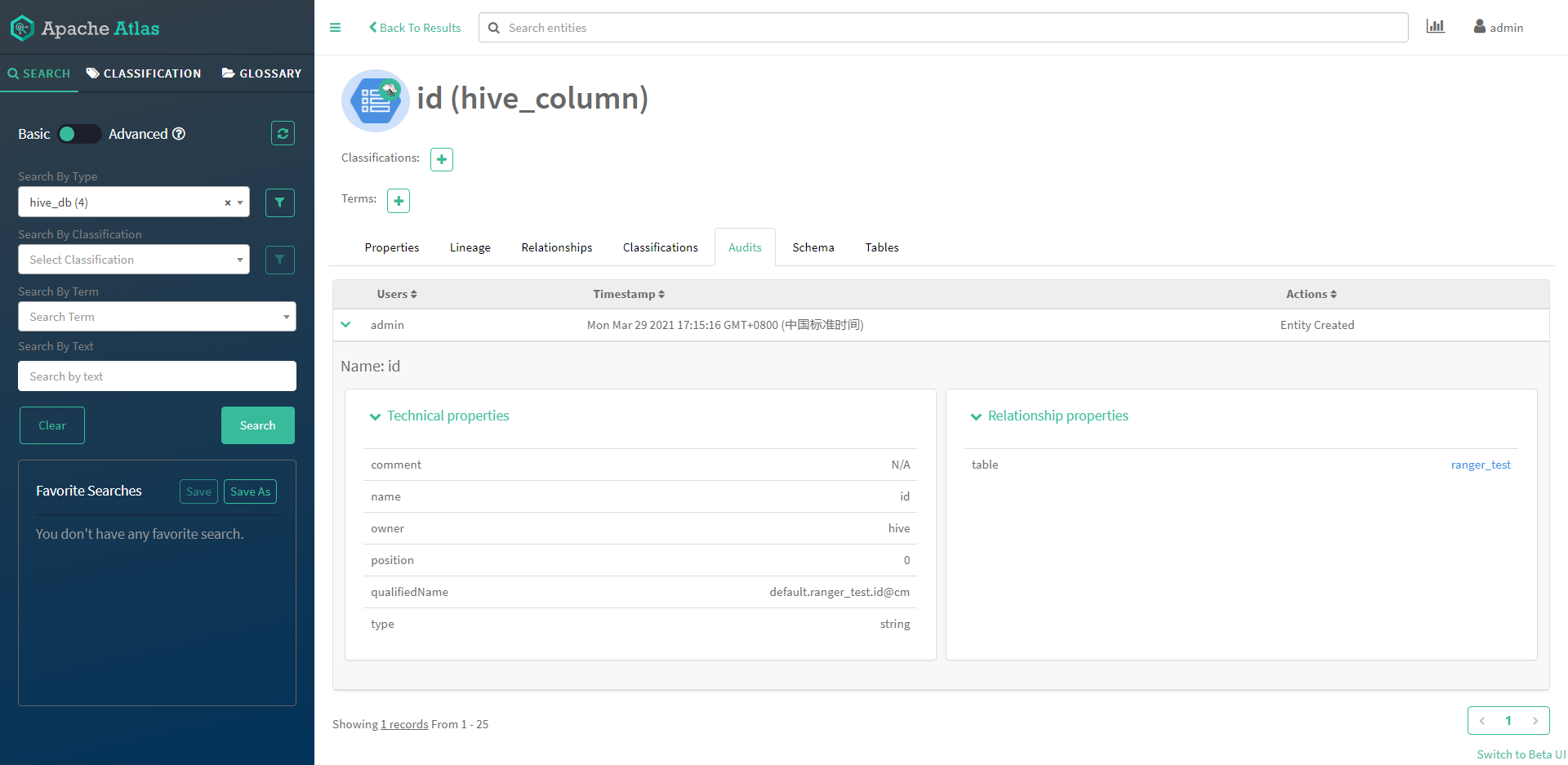
b. 访问无权限的表记录可以在ranger看到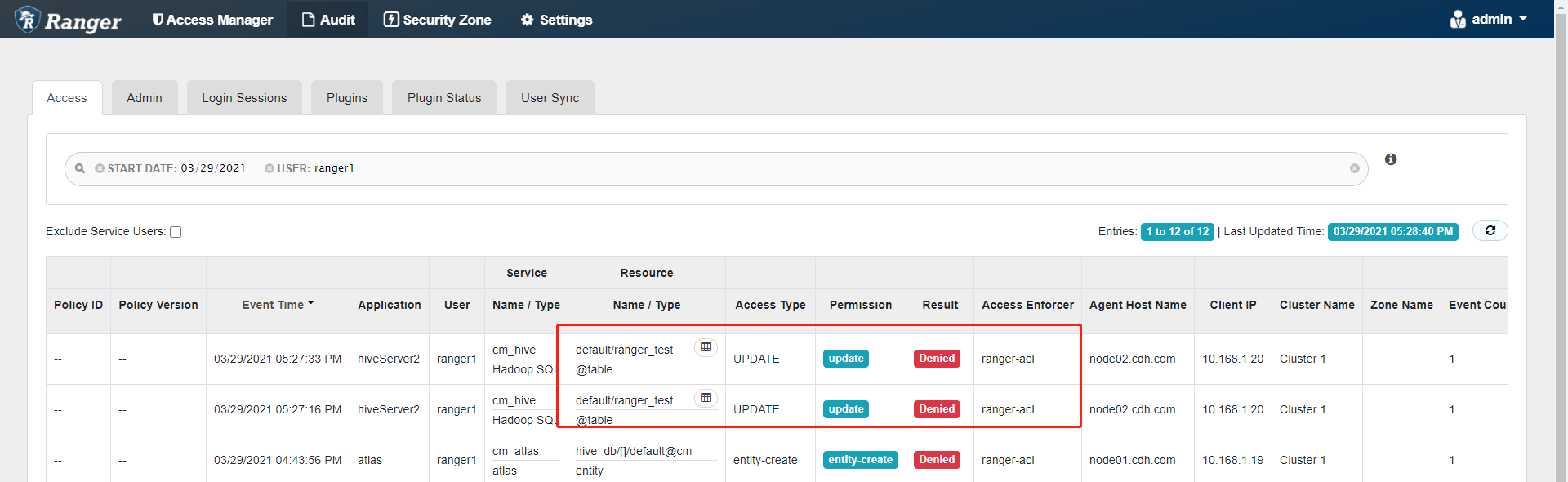
c. 使用hbase shell 进行GET/PUT操作
d. 查看审计信息,可以看到用户进行操作的详细信息
2.4 Ranger安全管理测试
| 测试编号 | UseCase005 |
|---|---|
| 测试项目 | Ranger安全管理测试 |
| 测试目的 | 测试支持集成的Ranger安全管理系统 |
| 测试环境 | 1. 大数据平台测试环境 1. 集群已经安装hadoop及ranger,并且可以正常使用 |
| 前置条件 | 大数据平台正常工作 |
| 测试步骤 | 1. 与hiveServer2集成测试 1. 与HDFS插件集成测试 1. 与yarn插件集成测试 1. 与kafka插件集成测试 |
| 预期结果 | 1. 系统记录HDFS正确访问的记录 1. 系统记录hiveServer2访问的记录 1. 系统记录有数据正确访问kafka的记录 1. 系统记录有访问Yarn的记录 |
| 测试结果 | 1. 系统记录HDFS正确访问的记录 1. 系统记录hiveServer2访问的记录 1. 系统记录有数据正确访问kafka的记录 1. 系统记录有访问Yarn的记录 |
| 备注 |
2.4.1 测试详细步骤
- 通过cdh 的webui进行快捷安装hiveserver2/hdfs/yarn/kafka的插件
进入web端点击“ranger”—>”点击操作”—>”setup ranger plugins services”
- 进入ranger webui,看到如下界面表示插件集成完毕
- 与HDFS插件集成测试
a. 创建用测试户ranger1,以及测试文件。修改参数,开启hdfs的ranger, 然后在HDFS中勾选【Enable Ranger Authorization】,保存重启生效。
b. 操作hdfs 目录,执行相关创建、查看命令,查看audits。
- 系统记录hiveServer2访问的记录
a. 创建用户,通过hiveserver2登录hive,执行查询,添加操作。
b. 通过ranger的webui可以看到用户访问hiverserver2的记录。
- 与yarn插件集成测试
a. 进入cdh的webui,点击“yarn”f服务—》搜索框搜索“ranger”,勾选ranger服务。
b. 重启服务,以wordcount为例,向yarn提交任务。
c. 创建输入输出目录。
d. 执行jar命令。
e. 查看ranger 的webui,可以看到用户提交yarn任务的记录。
- 与kafka插件集成测试
a. 使用命令行的形式来提交任务。
b. 先创建topic。
kafka-topics --create --topic topicname --replication-factor 1 --partitions 1 --zookeeper 10.168.1.19:2181,10.168.1.20:2181,10.168.1.21:2181/kafka
c. 指定生产用户/消费用户。
# 开启producer:kafka-console-producer --broker-list 10.168.1.29:9092 --topic topica# 开启consumer:kafka-console-consumer --bootstrap-server 10.168.1.29:9092 --topic topica --from-beginning
d. 添加数据进行测试。
e. Producer
f. Consumer
2.5 多租户管理功能
| 测试编号 | UseCase006 |
|---|---|
| 测试项目 | 多租户管理功能 |
| 测试目的 | 验证支持多级多部门租户管理,为不同部门创建不同级别的租户,为不同部门租户分配不同的数据权限,不同级别的租户支持不同的文件访问权限 |
| 测试环境 | 大数据平台测试环境 |
| 前置条件 | 大数据平台正常工作 |
| 测试步骤 | 1. 创建两个一级租户:Yarn应用;Hbase应用。 1. 以某个一级租户为基础,新增二级租户; 1. 以yarn应用租户为基础,新增yarn应用部门1; 1. 以yarn应用租户为基础,新增yarn应用部门2; 1. 以hbase查询租户为基础,新增hbase查询应用1; 1. 新增三级租户:Yarn应用部门1-应用1;Yarn应用部门1-应用2。 1. 删除hbase查询应用1和yarn应用部门1应用1,再新增hbase查询应用2,再删除yarn应用(对应的下级租户都被删除)。 1. 测试完后,重新建立租户hbase查询应用1和yarn应用部门1-应用1等。 |
| 预期结果 | Yarn Queue Manger能完成多级租户的增加和删除 |
| 测试结果 | Yarn Queue Manger能完成多级租户的增加和删除 |
| 备注 | 以上测试步骤内容在测试过程中更加情况可调整 |
2.5.1 测试详细步骤
- 创建 yarn hbase 租户。
- 创建 yarn hbase 队列。
- 以yarn应用租户为基础,新增yarn应用部门1、2。
- 以hbase查询租户为基础,新增hbase查询应用1。
- 删除hbase查询应用1和yarn应用部门1应用1,再新增hbase查询应用2,再删除yarn应用(对应的下级租户都被删除)。
- 重新建立租户hbase查询应用1和yarn应用部门1-应用1等。
2.6 租户资源动态分配
| 测试编号 | UseCase007 | | —- | —- | | 测试项目 | 租户资源动态分配 | | 测试目的 | 验证支持多级多部门租户管理,为不同部门创建不同级别的租户,为不同部门租户分配不同的数据权限,不同级别的租户支持不同的文件访问权限 | | 测试环境 | 大数据平台测试环境 | | 前置条件 | 大数据平台正常工作 | | 测试步骤 |
1. 对 A 用户进行存储配额限制设置
1. 尝试使用 A 用户向集群中存储超出其配额限制的数据
1. 记录存储尝试是否成功
1. 对B租户进行CPU、内存配额限制设置
1. 以B租户下的用户运行高消耗资源任务,记录其执行时长
| | 预期结果 |
1. 集群管理软件提供用户存储配额限制功能,超出用户配额限制的存储请求将不能成功完成
1. B租户下用户执行的任务两次时间接近资源配额限制比
| | 测试结果 |
1. 集群管理软件提供用户存储配额限制功能,超出用户配额限制的存储请求将不能成功完成
1. B租户下用户执行的任务两次时间接近资源配额限制比
| | 备注 | |
2.6.1 测试详细步骤
- 通过Cloudera Manager进入YARN的配置,启用YARN的ACL。
- 设置yarn.admin.acl。
如上所述,这里我们设置为“yarn yarn”,即用户yarn和组yarn,当然只设置一个用户yarn也一样。YARN的管理员设置,如可执行yarn rmadmin/yarn kill等命令,该值必须配置,否则后续的队列相关的acl管理员设置无法生效。
- 保存配置更改并重启集群服务。
- 创建队列并进行ACL设置。
a. 创建用户usera,userb,userc,所属的组都跟自己同名。创建用户userd所属组与用户userc同组。
b. 在CM上点击集群,再点击YARN Queue Manager UI进入队列管理界面。
c. 行子队列的创建,这里分别创建队列usera和userb。
d. 设置队列名和CONFIGURED CAPACITY的百分比,这里所有队列的CONFIGURED CAPACITY百分比加起来必须是100%,否则不能保存。
e. 全部添加完之后,如下图。
- 设置队列的ACL权限。
a. 以root.usera为例,点击旁边的三个点,然后选择查看/编辑队列。
b. 编辑后如下图,这个设置的意思是用户usera有提交应用到队列root.usera的权限。用户userb,userc和用户组usere里面的用户拥有对队列root.usera的管理权限。
c. 对队列userb的设置如下,表示用户usera,userb拥有对队列root.userb的提交应用的权限,下面的Queue Administer ACL里面是天的一个空格,表示所有用户都没有管理权限。
- 队列ACL测试
a. 分别用用户usera,userb和userd提交任务到root.usera
根据上面的测试可以看到,拥有Submit Application ACL或者Queue Administer ACL权限的用户或者组都可以向该队列提交任务。没有权限的用户,则会提交任务失败。以上测试说明,提交任务的用户和拥有该资源池管理权限的用户或用户组,拥有对该队列的管理权限。
- 注意事项
a. 要通过YARN Queue Manager UI进行资源池队列的ACL控制,需要先在YARN的配置里面勾选启ResourceManager ACL。
b. 一旦配置了队列的ACL,用户可以往自己有权限的队列里提交作业,如果该队列没权限,则作业提交失败。如果用户没有队列的管理访问权限,没办法kill该队列里的作业。
c. 子队列会继承父队列的权限,在子队列设置权限前,父队列ACL要设置成空格。
d. 某个用户可以kill自己提交的作业,即使该用户不在“Queue Administer ACL”的用户/组里。
e. 一旦用户具有某个队列的“Queue Administer ACL”,即使他不在“Submit Administer ACL”里,他依旧可以往该队列提交任务。
f. 在配置框里面,user和group之间用空格隔开。多个user或者多个group用逗号分隔。如果只配置group,需要在前面加上空格。
g. 执行任务失败 超出租户内存配额限制设置报错,可对租户进行CPU、内存配额限制设置
sudo -u usera hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi -D mapred.job.queue.name=usera -D mapreduce.map.memory.mb=500000 -D mapreduce.map.cpu.vcores=20 1 10
3、产品管理和维护能力
3.1 自动部署测试
3.1.1 测试详细步骤
3.2 监控告警
3.2.1 测试详细步骤
3.3 文件快照
3.3.1 测试详细步骤
3.4 配置参数管理
3.4.1 测试详细步骤
3.5 资源报告
3.5.1 测试详细步骤
3.6 集群滚动升级
3.6.1 测试详细步骤
3.7 查询性能
3.8 高可用测试
3.8.1 测试详细步骤

若有收获,就点个赞吧
0 人点赞
