主成分分析Principal Component Analysis
主成分分析(PCA)是一个使用一个正交变换来将一个可能有相互影响的变量的观测值的集合转换到一个线性不相关变量的值的集合(也称之为主成分)的数学过程。这种转换使用以下方式定义:first主成分有最多的可能的变量(也就是说,尽可能的说明数据的变化),之后的每个成分依次有在某种限制(它正交(等于不相关)于前一个成分)之下的尽可能最高的变量。
原文:Principal component analysis (PCA) is a mathematical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. This transformation is defined in such a way that the first principal component has the largest possible variance (i.e., accounts for as much of the variability in the data as possible), and each succeeding component in turn has the highest variance possible under the constraint that it be orthogonal to (i.e., uncorrelated with) the preceding components.
阅读里的主成分分析(principal component analysis)介绍及使用注意
训练函数
训练函数有一下形式:
pca_train( source_table,out_table,row_id,components_param,grouping_cols,lanczos_iter,use_correlation,result_summary_table)或者
pca_sparse_train( source_table,out_table,row_id,col_id,val_id,row_dim,col_dim,components_param,grouping_cols,lanczos_iter,use_correlation,result_summary_table)
参数
source_table
text,包含PCA训练数据的输入表名。输入矩阵必须有 n 行和 m 列,n 是数据点的个数,m 是每个数据点的特征。
密集输入表(dense input table)必须为madlib的两种标准密集矩阵格式的中的一种,稀疏输入表(sparse input table)必须为madlib的标准稀疏矩阵格式。
两种标准密集矩阵为:
{TABLE|VIEW} source_table (row_id INTEGER,row_vec FLOAT8[],)以及
{TABLE|VIEW} source_table (row_id INTEGER,col1 FLOAT8,col2 FLOAT8,...)
注意列名row_id作为一个输入参数,必须包含输入矩阵的连续的row index,从1开始。
稀疏PCA的输入表必须为以下格式:
{TABLE|VIEW} source_table (...row_id INTEGER,col_id INTEGER,val_id FLOAT8,...)注意row_id和col_id指向矩阵非0entity,val_id定义对应的值。
out_table
text,包含输出表的表名,输出表被划分为3张表。
主要的输出表(primary output table)(即out_table)对主成分使用最高k个特征值进行编码(The primary output table (out_table) encodes the principal components with the k highest eigenvalues),k既可以直接由用户指定,也可以通过误差的比例来计算(computed according to the proportion of variance)。表有一下几列:
row_id Eigenvalue rank in descending order of the eigenvalue size.
principal_components 包含主成分的element的向量
std_dev 每个主成分的标准差
proportion 覆盖主成分的误差比例
表out_table_mean包含列的平均数,该表只有一列。
column_mean 输入矩阵的包含列平均数的向量
optional表result_summary_table包含PCA的性能信息。表的内容在参数result_summary_table中描述。
row_id
text,以稀疏矩阵格式(只有这一种格式)存储的包含列IDS的列。列的类型必须能够强制转换刀int,列的值在1到 m 之间。
val_id
text,以稀疏矩阵格式(只有这一种格式)存储的列名为’val_id’的列。
row_dim
integer,稀疏矩阵中的行数(只有稀疏矩阵)
col_dim
integer,稀疏矩阵中的列数(只有稀疏矩阵)
components_param
INTEGER或者FLOAT.输入数据中控制主成分(principal components)数量的参数。如果’components_param’是integer,它用来表示用来计算的主成分的数量(k)。如果’components_param’是FLOAT,算法会返回足够的主向量(pricipal vector)来使当前收集的特征值的和与所有特征值的和的比例大于这个参数(误差比例)(If ‘components_param’ is FLOAT, the algorithm will return enough principal vectors so that the ratio of the sum of the eigenvalues collected thus far to the sum of all eigenvalues is greater than this parameter (proportion of variance)),’components_param’的值必须为一个在(0.0-1.0)范围的正的INTEGER或FLOAT。
INTEGER和 FLOAT的区别表述是在引进误差比例功能后能维护后台兼容性。一个相关的components_param’ = 1 (INTEGER)的特例会返回一个主成分,但是’components_param’ = 1.0 (FLOAT)会返回所有主成分,它等价于误差比例为100%.
grouping_cols (optional)
text,默认为null。
注意,当前版本没有实现(1.9.1),所有非空的值会被忽略。在将来的版本中会加入Grouping support。这个参数计划用于实现一个逗号分隔的列名(a comma-separated list of column names)。源数据将使用这些列的组合分组group。一个单独的PCA模型将会在每个分组的列的组合上计算(An independent PCA model will be computed for each combination of the grouping columns.)。
lanczos_iter (optional)
integer,默认值为 {k+40, smallest matrix dimension}的最小值。SVD计算的Lanczos迭代次数。Lanczos迭代次数大致上等价与SVD计算的精度,一个更高的迭代次数等同于更高精度但是更长的计算时间。迭代次数最小值为k,但是不大于矩阵的最小维数(the smallest dimension of the matrix).如果迭代书被设置为0,那么默认值将会被启用。
注意,如果lanczos_iter和误差比例(通过’components_param’参数设置)都有赋值,’components_param’会先决定主成分的个数(也就是说主成分的个数不会大于’lanczos_iter’,即使目标比例没有达到)
use_correlation (optional)
boolean,默认false。是否使用关联矩阵(correlation matrix)来计算主成分(principal components)来替代协方差矩阵(covariance matrix).当前use_correlation是一个向前兼容的变量(use_correlation is a placeholder for forward compatibility),必须设置为false。
result_summary_table (optional)
text,默认值为null,可选的结果汇总表名。设置为null时,没有汇总表生成。
汇总表有以下列:
rows_used integer,输入的数据点个数
exec_time (ms) FLOAT8,PCA计算运行的毫秒数
iter integer,SVD计算中的迭代次数
recon_error float8,SVD近似的绝对误差
relative_recon_error float8,SVD近似的相对误差
use_correlation boolean 表名是否关联矩阵(correlation matrix)被使用
例子
- 查看PCA训练函数的说明文档
SELECT madlib.pca_train();
- 创建样例数据表
DROP TABLE IF EXISTS mat;CREATE TABLE mat (row_id integer,row_vec double precision[]);COPY mat (row_id, row_vec) FROM stdin DELIMITER '|';1|{1,2,3}2|{2,1,2}3|{3,2,1}\.
- 使用固定额component个数运行PCA函数
DROP TABLE IF EXISTS result_table;DROP TABLE IF EXISTS result_table_mean;SELECT madlib.pca_train( 'mat','result_table','row_id',3);
- 查看PCA结果
SELECT * FROM result_table;row_id | principal_components | std_dev | proportion--------+---------------------------------------------------------------+----------------------+----------------------1 | {0.707106781186547,0,-0.707106781186547} | 1.41421356237309 | 0.8571428571422452 | {-5.55111512312578e-17,1,-5.55111512312578e-17} | 0.577350269189626 | 0.1428571428570413 | {-0.707106781186547,-1.11022302462516e-16,-0.707106781186547} | 1.06311148852927e-16 | 4.84374015875188e-33
- 使用误差比例来运行PCA函数
DROP TABLE IF EXISTS result_table;DROP TABLE IF EXISTS result_table_mean;SELECT madlib.pca_train( 'mat','result_table','row_id',0.9);
- 查看结果
SELECT * FROM result_table;row_id | principal_components | std_dev | proportion--------+-------------------------------------------------------------+-------------------+-------------------1 | {0.707106781186548,-3.8597597340484e-17,-0.707106781186547} | 1.41421356237309 | 0.8571428571422452 | {6.93889390390723e-18,-1,0} | 0.577350269189626 | 0.142857142857041
注意
- 表名可以带上schema(如果schema没有被指定会查找current_schemas()),所有的表名和列名不许遵循大小写敏感以及数据库的引用规则(如’mytable’和’MyTable’都会被转换为相同的entity。也就是说‘mytable’,如果表名混合大小写或者多字节字符串那么该字符串必须用双引号。所以在这个例子中,输入表名必须为”mytable”).
- 因为PCA的centering步骤,稀疏矩阵几乎总会在训练过程中变成密集矩阵。因此,这种实现自动将稀疏矩阵密集化,,所以在使用稀疏矩阵代替密集矩阵作为输入时不会有性能改善。
- 对于参数’components_param’,INTEGER和FLOAT8意义是不同的。一个components_param’ = 1 (INTEGER)的特例就是会返回1个主成分principal component,但是 but ‘components_param’ = 1.0 (FLOAT) 会返回所有的主成分。误差比例100%.
- 如果lanczos_iter和误差比例(通过’components_param’参数)都有赋值,’components_param’会先决定主成分的个数(也就是说主成分的个数不会大于’lanczos_iter’,即使目标比例没有达到)
技术背景
PCA的实现使用SVD分解来恢复principal component(和直接计算协方差的特征向量相反)。令 X 为数据矩阵,令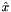 是一个 X 的列平均向量(let be a vector of the column averages of X)
,PCA按照以下方式求得矩阵
是一个 X 的列平均向量(let be a vector of the column averages of X)
,PCA按照以下方式求得矩阵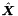 。
。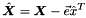 ,其中
,其中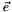 是值全为1的向量。
是值全为1的向量。
PCA然后计算SVD矩阵因子: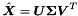 .其中
.其中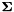 是对角矩阵。特征值通过
是对角矩阵。特征值通过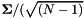 的entiry来恢复,并且principal component是V的行。使用 N-1 而不是 N 来计算协方差的原因是
的entiry来恢复,并且principal component是V的行。使用 N-1 而不是 N 来计算协方差的原因是
需要注意PCA实现假定用户会仅仅使用含有非0特征值的principal component。SVD计算使用Lanczos方法完成,不保证带有包含0值的特征值的奇异向量的正确性(The SVD calculation is done with the Lanczos method, with does not guarantee correctness for singular vectors with zero-valued eigenvalues).因此,含有0值特征值的principal component不能保证正确。一般情况下,这不会是个问题除非用户想要使用整个特征范围的principal component(Generally, this will not be problem unless the user wants to use the principal components for the entire eigenspectrum)。
相关文档
文件包含相关SQL函数

若有收获,就点个赞吧
0 人点赞
