低秩矩阵分解Low-rank Matrix Factorization
这个模块应用因子模型”factor model”来使用一个低秩近似矩阵low-rank approximation来表示一个不完全矩阵incomplete matrix.数学上,该模型致力于对任意给定的不完全矩阵,找到最小的矩阵U和V(也被称为因子factor),: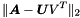 并服从
并服从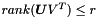 .其中
.其中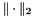 表示Frobenius范数,令A是一个m x n矩阵,U是 m x r,V是 n x r,in dimension,并且
表示Frobenius范数,令A是一个m x n矩阵,U是 m x r,V是 n x r,in dimension,并且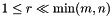 。该模型没有打算实现完全分解full decomposition,或被用于reverse步骤的一部分。该模型被广泛用于推荐系统recommendation system(例如Netflix)及特征选择feature selection(例如图像处理image process)。
。该模型没有打算实现完全分解full decomposition,或被用于reverse步骤的一部分。该模型被广泛用于推荐系统recommendation system(例如Netflix)及特征选择feature selection(例如图像处理image process)。
函数语法:
不完全矩阵incomplete matrix使用低秩矩阵分解成两个因子factor
lmf_igd_run( rel_output,rel_source,col_row,col_column,col_value,row_dim,column_dim,max_rank,stepsize,scale_factor,num_iterations,tolerance)
参数
rel_output
TEXT,输出的表名 输出factor matrix U和V是flattened format
RESULT AS (matrix_u DOUBLE PRECISION[],matrix_v DOUBLE PRECISION[],rmse DOUBLE PRECISION);
row i相当于matrix_u[i:i][1:r],column j相当于matrix_v[j:j][1:r].
rel_source
TEXT. 包含输入数据的表名.
输入 matrix> 需要是以下格式:
{TABLE|VIEW} input_table (row INTEGER,col INTEGER,value DOUBLE PRECISION)输入数据(不完全矩阵incomplete matrix)包含在一张表中,矩阵中的有效entity被定义为(row, column, value).输入矩阵必须为1-based,意思是row >= 1, 和 col >= 1. NULL值不被允许
col_row
TEXT. 包含 row number的列名.
col_column
TEXT. 包含 column number的列名.
col_value
DOUBLE PRECISION. The value at (row, col).
row_dim (optional)
INTEGER, default: “SELECT max(col_row) FROM rel_source”. 矩阵的列数.
column_dim (optional)
INTEGER, default: “SELECT max(col_col) FROM rel_source”. 矩阵的行数.
max_rank
INTEGER, default: 20. 近似矩阵的秩(The rank of desired approximation).
stepsize (optional)
DOUBLE PRECISION, default: 0.01. Hyper-parameter that decides how aggressive the gradient steps are.
scale_factor (optional)
DOUBLE PRECISION, default: 0.1.决定初始因子factor范围scale的Hyper-parameter (Hyper-parameter that decides scale of initial factors).
num_iterations (optional)
INTEGER, default: 10. 最大迭代次数无论是否收敛(Maximum number if iterations to perform regardless of convergence).
tolerance (optional)
DOUBLE PRECISION, default: 0.0001.收敛时可接受的误差等级(Acceptable level of error in convergence).
例子:
准备输入表:
DROP TABLE IF EXISTS lmf_data;CREATE TABLE lmf_data (row INT,col INT,val FLOAT8);
插入数据:
INSERT INTO lmf_data VALUES (1, 1, 5.0);INSERT INTO lmf_data VALUES (3, 100, 1.0);INSERT INTO lmf_data VALUES (999, 10000, 2.0);
调用lmf_igd_run()存储过程
DROP TABLE IF EXISTS lmf_model;SELECT madlib.lmf_igd_run('lmf_model','lmf_data','row','col','val',999,10000,3,0.1,2,10,1e-9);
结果为:
NOTICE: Matrix lmf_data to be factorized: 999 x 10000
NOTICE:
Finished low-rank matrix factorization using incremental gradient
table : lmf_data (row, col, val)
Results:
RMSE = 2.55605187132731e-06
Output:
view : SELECT * FROM lmf_model WHERE id = 1
lmf_igd_run
1
(1 row)
要查看结果,你需要返回的model id(上面lmf_igd_run()函数已经指出id为1)
SELECT array_dims(matrix_u) AS u_dims,array_dims(matrix_v) AS v_dims
FROM lmf_model
WHERE id = 1;
u_dims | v_dims
———————+————————
[1:999][1:3] | [1:10000][1:3]
(1 row)
查询结果值
SELECT matrix_u[2:2][1:3] AS row_2_features
FROM lmf_model
WHERE id = 1;
row_2_features
{{0.296678517945111,1.14573554042727,0.317661632783711}}
(1 row)
预估缺失entity
SELECT matrix_u[2:2][1:3] AS row_2_features
FROM lmf_model
WHERE id = 1;
row_2_features
{{0.296678517945111,1.14573554042727,0.317661632783711}}
(1 row)
参考资料
[1] N. Srebro and T. Jaakkola. “Weighted Low-Rank Approximations.” In: ICML. Ed. by T. Fawcett and N. Mishra. AAAI Press, 2003, pp. 720–727. isbn: 1-57735-189-4.
[2] Simon Funk, Netflix Update: Try This at Home, December 11 2006, http://sifter.org/~simon/journal/20061211.html
[3] J. Wright, A. Ganesh, S. Rao, Y. Peng, and Y. Ma. “Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Matrices via Convex Optimization.” In: NIPS. Ed. by Y. Bengio, D. Schuurmans, J. D. Lafferty, C. K. I. Williams, and A. Culotta. Curran Associates, Inc., 2009, pp. 2080–2088. isbn: 9781615679119.

若有收获,就点个赞吧
0 人点赞
