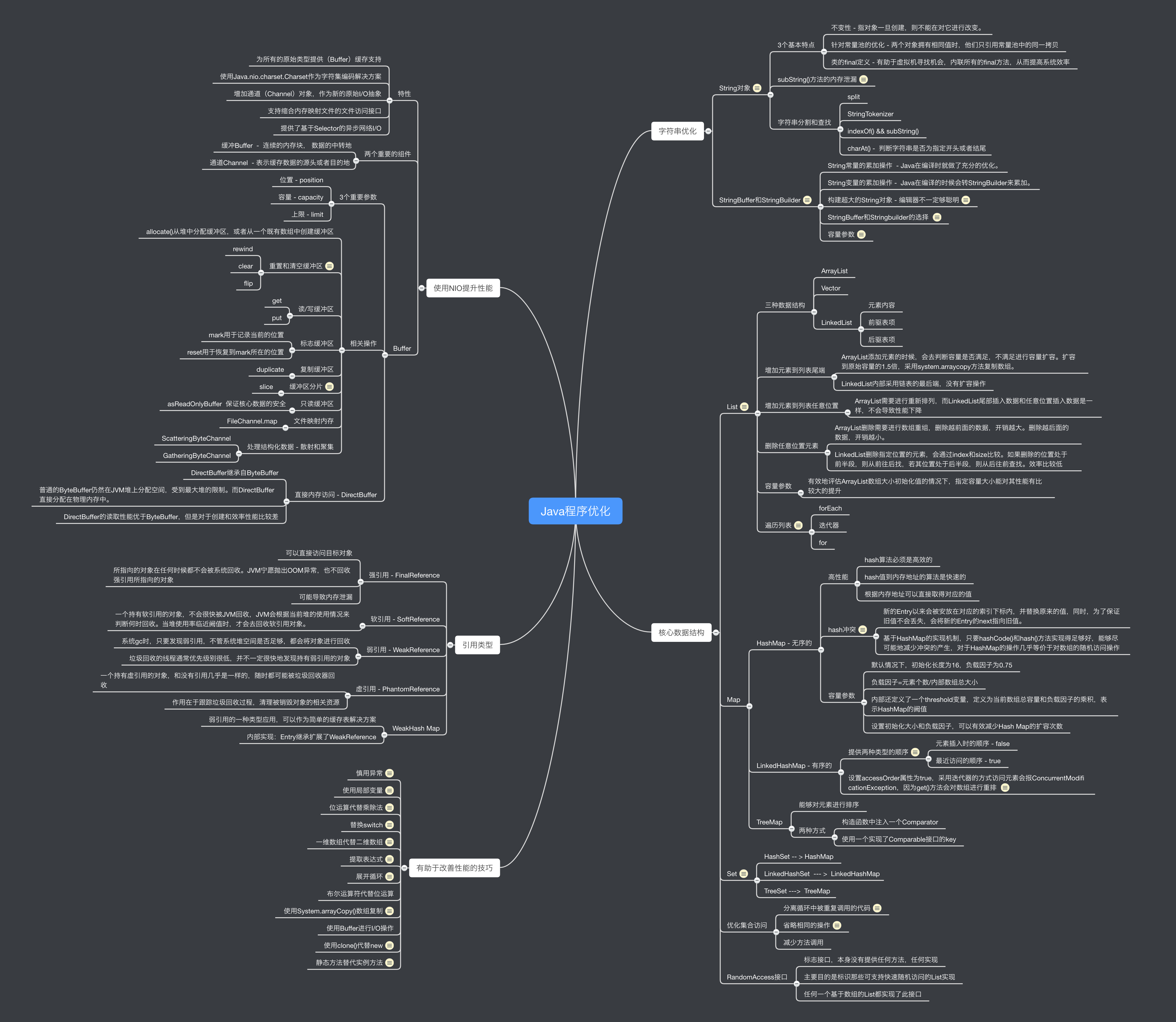
字符串优化
String对象
实现主要由3部分组成:char数组、偏移量、String的长度3个基本特点
不变性 - 指对象一旦创建,则不能在对它进行改变。
针对常量池的优化 - 两个对象拥有相同值时,他们只引用常量池中的同一拷贝
类的final定义 - 有助于虚拟机寻找机会,内联所有的final方法,从而提高系统效率
subString()方法的内存泄漏
底层采用new String()构造了一个新的对象,只是偏移量和长度修改,实际的内容没有变,采用的是一种空间换时间的策略字符串分割和查找
split
StringTokenizer
indexOf() && subString()
charAt() - 判断字符串是否为指定开头或者结尾
StringBuffer和StringBuilder
由于String对象是不可变对象,因此对字符串操作时,都会创建新的对象。
JDK提供了创建和修改字符串的工具String常量的累加操作 - Java在编译时就做了充分的优化。
String变量的累加操作 - Java在编译的时候会转StringBuilder来累加。
构建超大的String对象 - 编辑器不一定够聪明
string = string +i
string = string.concat(String.valueOf(i))
sb.append(i) —- StringBuilderStringBuffer和Stringbuilder的选择
StringBuffer所有的方法都做了同步 Synchronized 保证线程安全性
而StringBuilder没有做同步, 存在线程安全性问题容量参数
默认容量大小为16,当容量不满足的时候,会进行扩容。
扩容规则是 现有的长度翻倍(value.length + 1) *2
建议明确长度的时候直接指定,避免频繁的内存复制
核心数据结构
List
ArrayList和Vector都采用动态数组的方式实现,主要差别在于Vector的方法都是线程安全的,LinkedList采用循环双向链表的结构三种数据结构
ArrayList
Vector
LinkedList
元素内容
前驱表项
后驱表项
增加元素到列表尾端
ArrayList添加元素的时候,会去判断容量是否满足,不满足进行容量扩容。扩容到原始容量的1.5倍,采用system.arraycopy方法复制数组。
LinkedList内部采用链表的最后端,没有扩容操作
增加元素到列表任意位置
- ArrayList需要进行重新排列,而LinkedList尾部插入数据和任意位置插入数据是一样,不会导致性能下降
删除任意位置元素
ArrayList删除需要进行数组重组,删除越前面的数据,开销越大。删除越后面的数据,开销越小。
LinkedList删除指定位置的元素,会通过index和size比较。如果删除的位置处于前半段,则从前往后找,若其位置处于后半段,则从后往前查找。效率比较低
容量参数
- 有效地评估ArrayList数组大小初始化值的情况下,指定容量大小能对其性能有比较大的提升
遍历列表
推荐使用迭代器的方式forEach
迭代器
for
Map
HashMap - 无序的
高性能
hash算法必须是高效的
hash值到内存地址的算法是快速的
根据内存地址可以直接取得对应的值
hash冲突
需要存放至HashMap的两个元素通过Hash计算查找出内存中的同一地址新的Entry以来会被安放在对应的索引下标内,并替换原来的值,同时,为了保证旧值不会丢失,会将新的Entry的next指向旧值。
基于HashMap的实现机制,只要hashCode()和hash()方法实现得足够好,能够尽可能地减少冲突的产生,对于HashMap的操作几乎等价于对数组的随机访问操作
容量参数
默认情况下,初始化长度为16,负载因子为0.75
负载因子=元素个数/内部数组总大小
内部还定义了一个threshold变量,定义为当前数组总容量和负载因子的乘积,表示HashMap的阙值
设置初始化大小和负载因子,可以有效减少Hash Map的扩容次数
LinkedHashMap - 有序的
提供两种类型的顺序
accessOrder 属性控制元素插入时的顺序 - false
最近访问的顺序 - true
设置accessOrder属性为true,采用迭代器的方式访问元素会报ConcurrentModificationException,因为get()方法会对数组进行重排
迭代器的场景,对数据结构进行修改操作会报如上错误
TreeMap
能够对元素进行排序
两种方式
构造函数中注入一个Comparator
使用一个实现了Comparable接口的key
Set
Set集合中的元素是不能重复的HashSet — > HashMap
LinkedHashSet —- > LinkedHashMap
TreeSet —-> TreeMap
优化集合访问
分离循环中被重复调用的代码
for(int i=0,length=array.length;i<length;i++)省略相同的操作
s = collection.get(i) 抽一个局部变量减少方法调用
RandomAccess接口
标志接口,本身没有提供任何方法,任何实现
主要目的是标识那些可支持快速随机访问的List实现
任何一个基于数组的List都实现了此接口
使用NIO提升性能
特性
为所有的原始类型提供(Buffer)缓存支持
使用Java.nio.charset.Charset作为字符集编码解决方案
增加通道(Channel)对象,作为新的原始I/O抽象
支持缩合内存映射文件的文件访问接口
提供了基于Selector的异步网络I/O
两个重要的组件
缓冲Buffer - 连续的内存块, 数据的中转地
通道Channel - 表示缓存数据的源头或者目的地
Buffer
3个重要参数
位置 - position
容量 - capacity
上限 - limit
相关操作
allocate()从堆中分配缓冲区,或者从一个既有数组中创建缓冲区
重置和清空缓冲区
三个方法并不是清空buffer的内容,而是重置了buffer的各项标识位rewind
clear
flip
读/写缓冲区
get
put
标志缓冲区
mark用于记录当前的位置
reset用于恢复到mark所在的位置
复制缓冲区
- duplicate
缓冲区分片
将在现有的缓冲区中,创建新的子缓冲区,子缓冲区和父缓冲区共享数据。有助于将系统模块化- slice
只读缓冲区
- asReadOnlyBuffer 保证核心数据的安全
文件映射内存
- FileChannel.map
处理结构化数据 - 散射和聚集
ScatteringByteChannel
GatheringByteChannel
直接内存访问 - DirectBuffer
DirectBuffer继承自ByteBuffer
普通的ByteBuffer仍然在JVM堆上分配空间,受到最大堆的限制。而DirectBuffer直接分配在物理内存中。
DirectBuffer的读取性能优于ByteBuffer,但是对于创建和效率性能比较差
引用类型
强引用 - FinalReference
可以直接访问目标对象
所指向的对象在任何时候都不会被系统回收。JVM宁愿抛出OOM异常,也不回收强引用所指向的对象
可能导致内存泄漏
软引用 - SoftReference
- 一个持有软引用的对象,不会很快被JVM回收,JVM会根据当前堆的使用情况来判断何时回收。当堆使用率临近阙值时,才会去回收软引用对象。
弱引用 - WeakReference
系统gc时,只要发现弱引用,不管系统堆空间是否足够,都会将对象进行回收
垃圾回收的线程通常优先级别很低,并不一定很快地发现持有弱引用的对象
虚引用 - PhantomReference
一个持有虚引用的对象,和没有引用几乎是一样的,随时都可能被垃圾回收器回收
作用在于跟踪垃圾回收过程,清理被销毁对象的相关资源
WeakHash Map
弱引用的一种类型应用,可以作为简单的缓存表解决方案
内部实现:Entry继承扩展了WeakReference
有助于改善性能的技巧
慎用异常
比如for循环中使用try-catch。可以将try-catch挪到for循环外部使用局部变量
局部变量的访问速度远远高于类的成员变量位运算代替乘除法
比如乘除2 可以使用 <<= 1 >>=1替换switch
利于数组来替换switch的值一维数组代替二维数组
提取数组长度到变量,以减少重复循环时的开销提取表达式
将公共的操作提取表达式,方便复用展开循环
减少循环次数,循环次数+3,内部实现+3布尔运算符代替位运算
使用System.arrayCopy()数组复制
底层是native使用Buffer进行I/O操作
使用clone()代替new
clone只会进行浅拷贝,只会复制对象引用,对于值的 深拷贝需要重新实现clone静态方法替代实例方法
工具类的方法尽量都使用static

若有收获,就点个赞吧
0 人点赞

{kind=link}