核心概念
什么是搜索引擎
- 全文搜索引擎:自然语言处理(NLP)、爬虫、网页处理、大数据处理
- 垂直搜索引擎:有明确搜索目的的搜索引擎,各类站内搜索。
es不能简单的和搜索引擎划等号。es还存在聚合分析和大数据存储,搜索引擎还包括NLP 和爬虫等。es可以说是搜索引擎的核心之一。
搜索引擎的要求
- 查询速度快
- 高效的压缩算法
- 快速的编码和解码速度
- 搜索结果准
- 7.0版本之后默认是用BM25评分算法
- 之前使用的是TF-IDF算法
- 检索结果丰富
- 召回率
海量数据如何达到搜索引擎级别的速度呢
索引
- 帮助快速检索
- 以数据结构为载体
- 以文件形式落地
本质是一个文件,但是不同的文件中数据是不一致的,帮助理解的是mysql的数据文件存储,在mylsam中myi是存储索引,myd是存储数据
M
以mysql的组成结构举例
点击查看【processon】
分为客户端、server、存储引擎
存储引擎是使用的b+树,3阶一般就可以存储千万级别的数据量
mysql 的b+ 树可以解决大数据检索的问题吗
- 如果会用b+树,因为索引列是大文本,树的深度可能会很深,IO量大
- 索引可能会失效(例如模糊匹配的%开头)
- 精准度差
这个时候就可以引入lucene(一个全文检索库)
Lucene
- 成熟的全文检索库,java开发、高性能、可伸缩、开源免费
- apache下的一个子项目
- Lucene是一个IR库(infrometion Retrieval library)Elasticsearch是在其基础上开发的。
全文检索
索引系统通过检索文章中的每一个词,为其建立索引,指明其出现的位置和次数。当我们的用户检索的时候,就会通过事先创建好的索引进行检索,再给用户返回。 这里的索引就是倒排索引
lucene的结构,segment数据段相当于存储引擎。 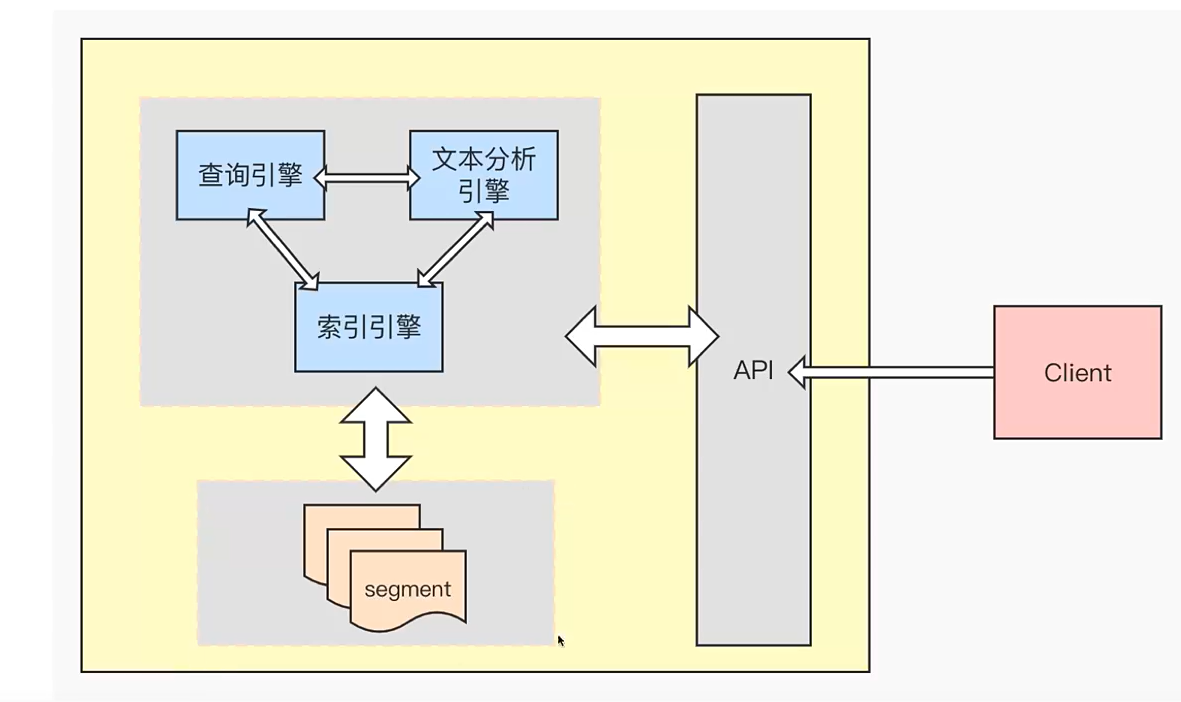
倒排索引
term dictionary 词项 :文本切分词项
posting list 倒排表:重复的词数据行 。还存储TF词频


若有收获,就点个赞吧
0 人点赞
