
normalization:文档规范化,提高召回率
具体就是大写转成小写,is an 不要
字符过滤器(character filter):分词之前的预处理,过滤无用字符
- HTML Strip Character Filter:html_strip
- 参数:escaped_tags 需要保留的html标签
- Mapping Character Filter:type mapping
- Pattern Replace Character Filter:type pattern_replace
创建一个分词器,指定字符过滤器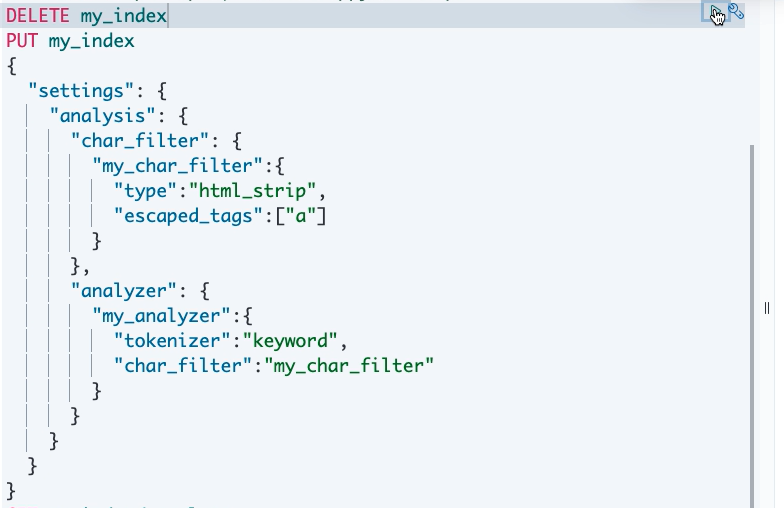
或者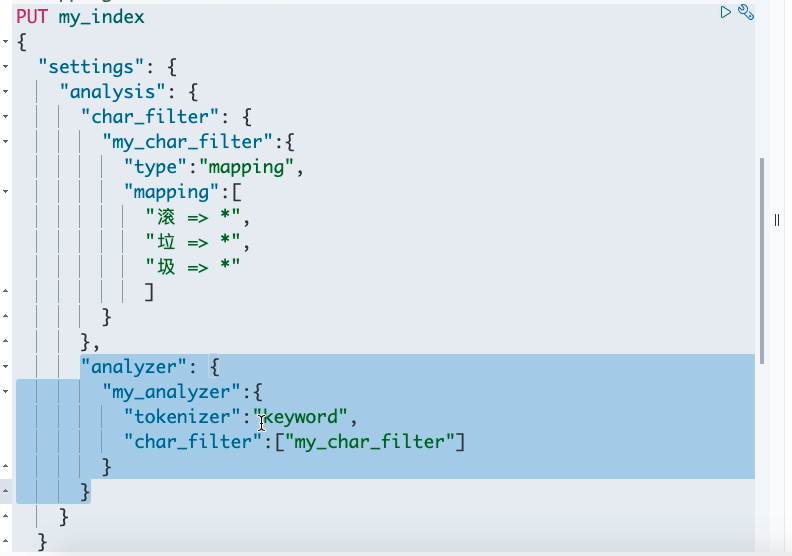
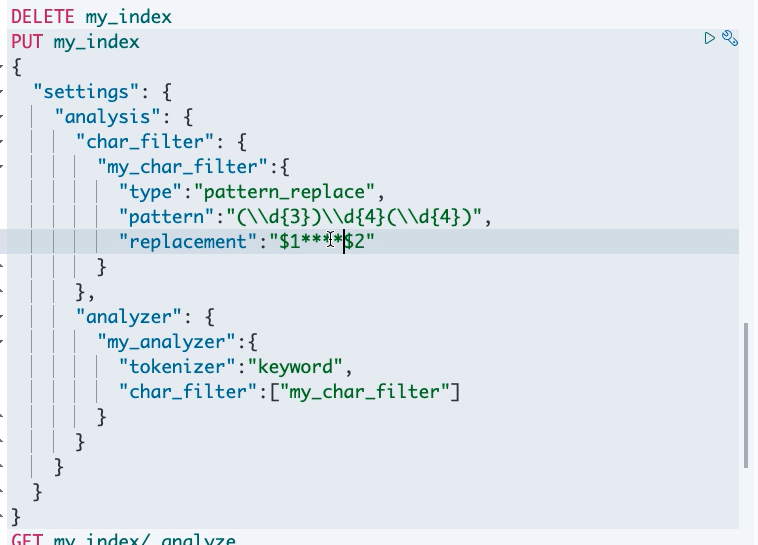
测试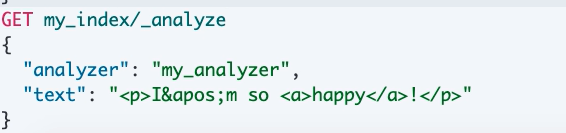
3 令牌过滤器(token filter):停用词、时态转换、大小写转换、同义词转换、语气词处理等。比如:has=>have him=>he apples=>apple the/oh/a=>干掉
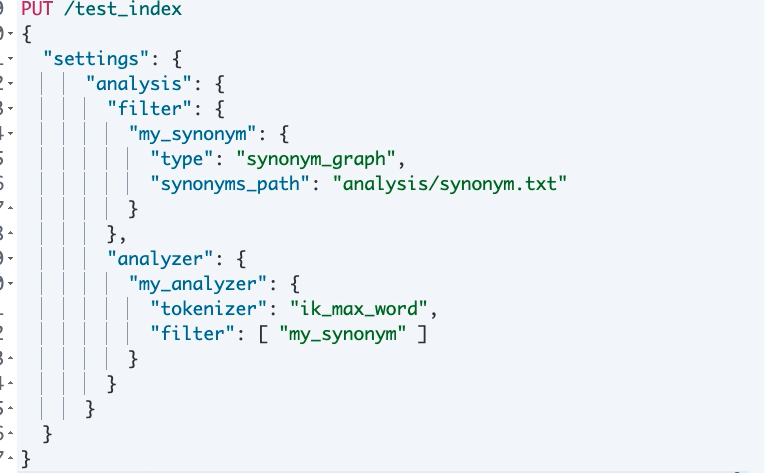


4 分词器(tokenizer):切词
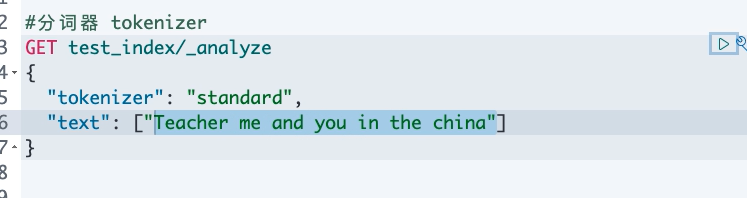

5 常见分词器:
- standard analyzer:默认分词器,中文支持的不理想,会逐字拆分。
- pattern tokenizer:以正则匹配分隔符,把文本拆分成若干词项。
- simple pattern tokenizer:以正则匹配词项,速度比pattern tokenizer快。
- whitespace analyzer:以空白符分隔 Tim_cookie
6 自定义分词器:custom analyzer
- char_filter:内置或自定义字符过滤器 。
- token filter:内置或自定义token filter 。
- tokenizer:内置或自定义分词器。
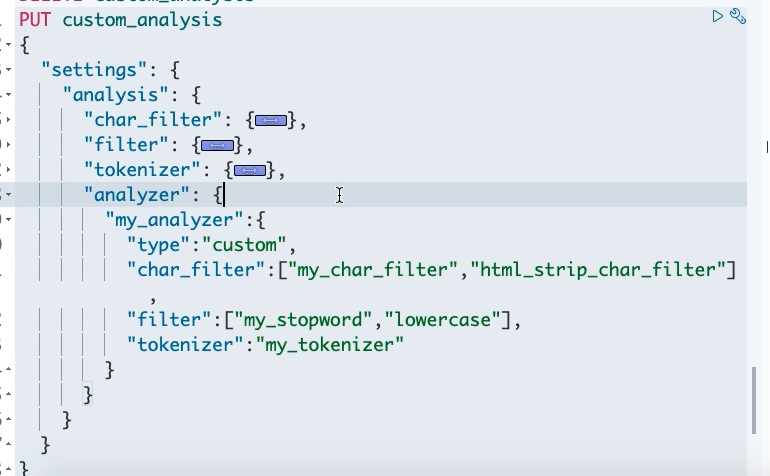
7 中文分词器:ik分词
-
安装和部署
- ik下载地址:https://github.com/medcl/elasticsearch-analysis-ik
- Github加速器:https://github.com/fhefh2015/Fast-GitHub
- 创建插件文件夹 cd your-es-root/plugins/ && mkdir ik
- 将插件解压缩到文件夹 your-es-root/plugins/ik
- 重新启动es
-
IK文件描述
- IKAnalyzer.cfg.xml:IK分词配置文件
- 主词库:main.dic
- 英文停用词:stopword.dic,不会建立在倒排索引中
- 特殊词库:
- quantifier.dic:特殊词库:计量单位等
- suffix.dic:特殊词库:行政单位
- surname.dic:特殊词库:百家姓
- preposition:特殊词库:语气词
- 自定义词库:网络词汇、流行词、自造词等

若有收获,就点个赞吧
0 人点赞
