搜索和查询
查询上下文
GET product/_search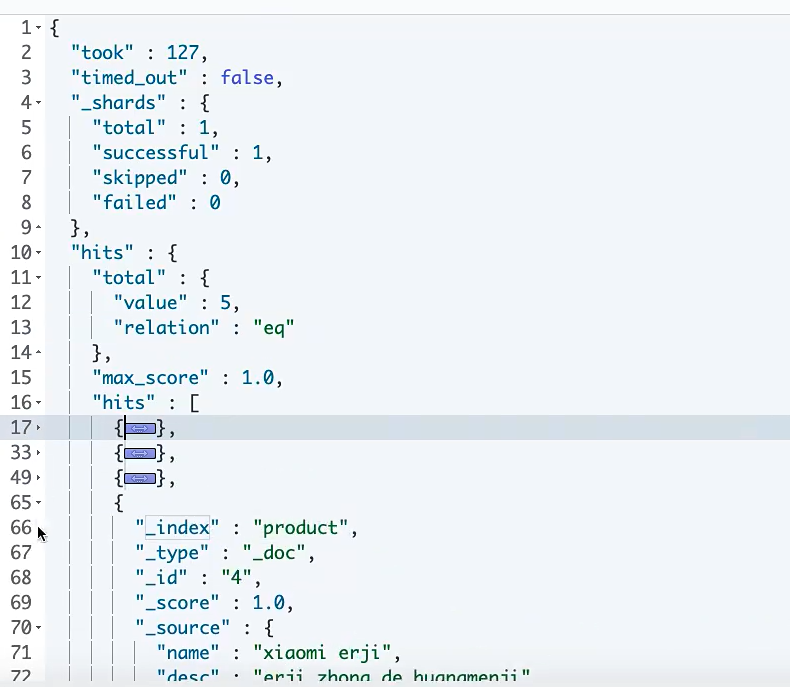
took:代表查询耗时 ms
time_out:代表是否超时
shards:代表查询使用分片情况
hits:真正返回给我们的结果
total:value:一共有5条
max_score:1.0 评分
hits:具体的数据
index:所属的索引
type:类型
id
socre:评分值
source:元数据
字段
字段
字段
相关度评分
相关度评分,对搜索结果排序,认为搜索结果与搜索预期相关度越高评分就越高,在7.x之前相关度评分默认使用TF/IDF算法计算而来,7.x之后默认为BM25
元数据
- 禁用_source:
- 好处:节省存储开销
- 坏处:
- 不支持update、update_by_query和reindex API。
- 不支持高亮。
- 不支持reindex、更改mapping分析器和版本升级。
- 通过查看索引时使用的原始文档来调试查询或聚合的功能。
- 将来有可能自动修复索引损坏。
总结:如果只是为了节省磁盘,可以压缩索引比禁用_source更好。
数据源过滤器:
Including:结果中返回哪些field
Excluding:结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表索引不存在在mapping中定义过滤:支持通配符,但是这种方式不推荐,因为mapping不可变
PUT product{"mappings": {"_source": {"includes": ["name","price"],"excludes": ["desc","tags"]}}}
常用过滤规则
- “_source”: “false”,
- “_source”: “obj.*”,
- “_source”: [ “obj1.“, “obj2.“ ],
- “_source”: {
“includes”: [ “obj1.“, “obj2.“ ],
“excludes”: [ “*.description” ]
}

若有收获,就点个赞吧
0 人点赞
