原生snowflake
原生snowflake使用一个64位整数,根据当前时间来生成ID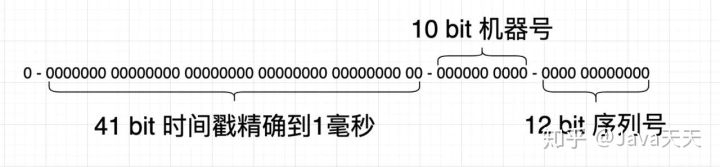
- 因为最高位是标识位,为1表示为负数,所以最高位不使用。
- 41bit 保存时间戳,精确到毫秒。也就是说最大可使用的年限是69年。
- 10bit 的机器位,能部属在1024台机器节点来生成ID。
- 12bit 的序列号,一毫秒最大生成唯一ID的数量为4096个。
原生的Snowflake算法是完全依赖于时间的,如果有时钟回拨的情况发生,会生成重复的ID,市场上的解决方案也是非常多的:
- 最简单的方案,就是关闭生成唯一ID机器的时间同步。
- 使用阿里云的的时间服务器进行同步,2017年1月1日的闰秒调整,阿里云服务器NTP系统24小时“消化”闰秒,完美解决了问题。
- 如果发现有时钟回拨,时间很短比如5毫秒,就等待,然后再生成。或者就直接报错,交给业务层去处理。
- 可以找2bit位作为时钟回拨位,发现有时钟回拨就将回拨位加1,达到最大位后再从0开始进行循环。
sonyflake
索尼公司的Sonyflake对原生的Snowflake进行改进,重新分配了各部分的bit位: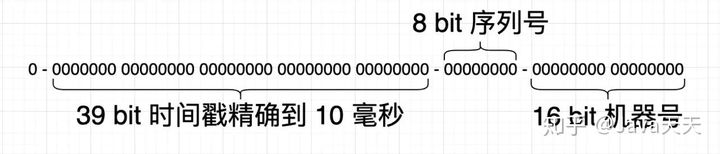
- 39bit 来保存时间戳,与原生的Snowflake不同的地方是,Sonyflake是以10毫秒为单位来保存时间的。这样的话,可以使用的年限为 174年 比Snowflake长太多了。
- 8bit 做为序列号,每10毫最大生成256个,1秒最多生成25600个,比原生的Snowflake少好多,如果感觉不够用,目前的解决方案是跑多个实例生成同一业务的ID来弥补。
- 16bit 做为机器号,默认的是当前机器的私有IP的最后两位
对于时间回拨的问题Sonyflake简单暴力,就是直接等待 :
func (sf *Sonyflake) NextID() (uint64, error) {const maskSequence = uint16(1<<BitLenSequence - 1)sf.mutex.Lock()defer sf.mutex.Unlock()current := currentElapsedTime(sf.startTime)if sf.elapsedTime < current {sf.elapsedTime = currentsf.sequence = 0} else { // sf.elapsedTime >= currentsf.sequence = (sf.sequence + 1) & maskSequenceif sf.sequence == 0 {sf.elapsedTime++overtime := sf.elapsedTime - currenttime.Sleep(sleepTime((overtime)))}}return sf.toID()}

若有收获,就点个赞吧
0 人点赞
