pprof 可以找出性能的瓶颈,其包含两部分
- 编译到程序中的
runtime/pprof -
性能分析
cpu性能分析
启动 CPU 分析时,运行时(runtime) 将每隔 10ms 中断一次,记录此时正在运行的协程(goroutines) 的堆栈信息。程序运行结束后,可以分析记录的数据找到最热代码路径(hottest code paths)。一个函数在性能分析数据中出现的次数越多,说明执行该函数的代码路径(code path)花费的时间占总运行时间的比重越大。
内存性能分析
内存性能分析(Memory profiling) 记录堆内存分配时的堆栈信息,忽略栈内存分配信息。内存性能分析启用时,默认每1000次采样1次,这个比例是可以调整的。因为内存性能分析是基于采样的,因此基于内存分析数据来判断程序所有的内存使用情况是很困难的。
阻塞性能分析
阻塞性能分析用来记录一个协程等待一个共享资源花费的时间。在判断程序的并发瓶颈时会很有用。阻塞的场景包括:
在没有缓冲区的信道上发送或接收数据。
- 从空的信道上接收数据,或发送数据到满的信道上。
- 尝试获得一个已经被其他协程锁住的排它锁。
一般情况下,当所有的 CPU 和内存瓶颈解决后,才会考虑这一类分析。
锁性能分析
锁性能分析(mutex profiling) 与阻塞分析类似,但专注于因为锁竞争导致的等待或延时。
CPU性能分析
Go 的运行时性能分析接口都位于 runtime/pprof 包中。只需要调用 runtime/pprof 库即可得到我们想要的数据。
func main() {f, _ := os.OpenFile("cpu.pprof", os.O_CREATE|os.O_RDWR, 0644)defer f.Close()pprof.StartCPUProfile(f)defer pprof.StopCPUProfile()n := 10for i := 0; i < 5; i++ {nums := generate(n)bubbleSort(nums)n *= 10}}
这样只需运行 go run main.go 即可。
接下来,可以用 go tool pprof 分析这份数据go tool pprof -http=:9999 cpu.pprof
需要安装一个图形库apt install graphviz(Ubuntu) 即可
访问 localhost:9999,可以看到这样的页面: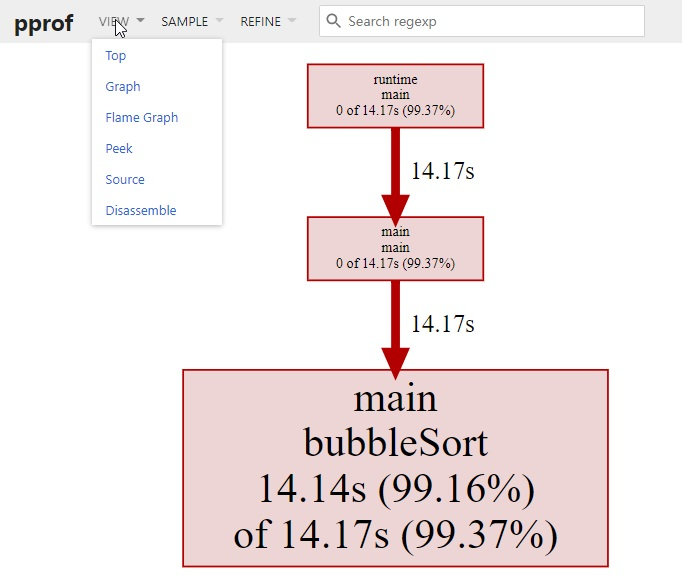
除了在网页中查看分析数据外,我们也可以在命令行中使用交互模式查看。go tool pprof cpu.pprof
$ go tool pprof cpu.pprof
File: main
Type: cpu
Time: Nov 19, 2020 at 1:43am (CST)
Duration: 16.42s, Total samples = 14.26s (86.83%)
Entering interactive mode (type “help” for commands, “o” for options)
(pprof) top
Showing nodes accounting for 14.14s, 99.16% of 14.26s total
Dropped 34 nodes (cum <= 0.07s)
flat flat% sum% cum cum%
14.14s 99.16% 99.16% 14.17s 99.37% main.bubbleSort
0 0% 99.16% 14.17s 99.37% main.main
0 0% 99.16% 14.17s 99.37% runtime.main
可以看到 main.bubbleSort 是消耗 CPU 最多的函数。
还可以按照 cum (累计消耗)排序:
(pprof) top —cum
Showing nodes accounting for 14.14s, 99.16% of 14.26s total
Dropped 34 nodes (cum <= 0.07s)
flat flat% sum% cum cum%
14.14s 99.16% 99.16% 14.17s 99.37% main.bubbleSort
0 0% 99.16% 14.17s 99.37% main.main
0 0% 99.16% 14.17s 99.37% runtime.main
内存性能分析
假设我们实现了这么一个程序,生成长度为 N 的随机字符串,拼接在一起。
package mainimport ("github.com/pkg/profile""math/rand")const letterBytes = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"func randomString(n int) string {b := make([]byte, n)for i := range b {b[i] = letterBytes[rand.Intn(len(letterBytes))]}return string(b)}func concat(n int) string {s := ""for i := 0; i < n; i++ {s += randomString(n)}return s}func main() {defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()concat(100)}
接下来,我们使用一个易用性更强的库 pkg/profile 来采集性能数据,pkg/profile 封装了 runtime/pprof 的接口,使用起来更简单。
比如我们想度量 concat() 的 CPU 性能数据,只需要一行代码即可生成 profile 文件。
import ("github.com/pkg/profile")func main() {defer profile.Start().Stop()concat(100)}
接下来将使用类似的方式,进行采集内存数据,同样地,只需简单地修改 main 函数即可。
func main() {defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()concat(100)}
接下来,我们在浏览器中分析内存性能数据:go tool pprof -http=:9999 /tmp/profile215959616/mem.pprof
benchMark生成profile
testing支持生成 CPU、memory 和 block 的 profile 文件。
- -cpuprofile=$FILE
- -memprofile=$FILE, -memprofilerate=N 调整记录速率为原来的 1/N。
- -blockprofile=$FILE
```go
func fib(n int) int {
if n == 0 || n == 1 {
} return fib(n-2) + fib(n-1) }return n
func BenchmarkFib(b *testing.B) {
for n := 0; n < b.N; n++ {
fib(30) // run fib(30) b.N times
}
}
``
只需要在 go test 添加 -cpuprofile 参数即可生成 BenchmarkFib 对应的 CPU profile 文件:<br />go test -bench=”Fib$” -cpuprofile=cpu.pprof .`

若有收获,就点个赞吧
0 人点赞
