剖析 golang 的25个关键字
基本在所有语言当中,关键字都是不允许用于自定义的,在Golang中有25个关键字,图示如下: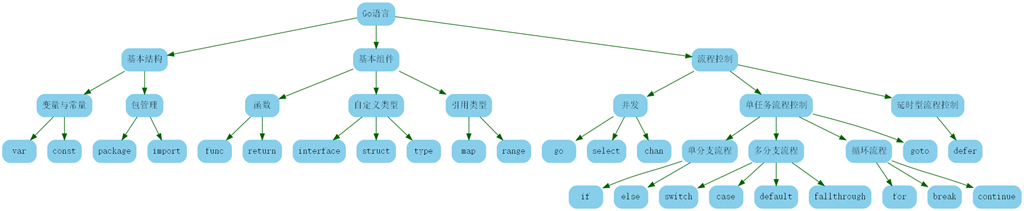
下面我们逐个解析这25个关键字。
var && const
使用var关键字是Go最基本的定义变量方式,有时也会使用到 := 来定义变量。
定义变量
var name string
定义变量并初始化值
var name string = "keywords"
同时初始化多个同类型变量
var name1, name2, name3 string = "name1", "name2", "name3"
同时初始化多个不同类型变量
var (name string = "keywords",count int = 2)
也可省略变量类型
var name1, name2, name3 = "name1", "name2", "name3"
使用 := 这个符号取代var和type,这种形式叫做简短声明。不过它有一个限制,那就是它只能用在函数内部;在函数外部使用则会无法编译通过,所以一般用var方式来定义全局变量。
name1, name2, name3 := "name1", "name2", "name3"
const 用来声明一个常量,const 语句可以出现在任何 var 语句可以出现的地方,声明常量方式与 var 相同,这里就不在赘述了。但是需要注意的是,const 声明的是常量,一旦创建,不可赋值修改。
package && import
包是函数和数据的集合。用 package 关键字定义一个包,用 import 关键字引入一个包,文件名不需要和包名一致。包名的约定是使用小写字符。Go 包可以由多个文件组成,但是使用相同的 package 这一行。
当函数或者变量等首字母为大写时,会被导出,可在外部直接调用。
包名是导入的默认名称。可以通过在导入语句指定其他名称来覆盖默认名称
import bar "bytes"
map
map 是 Go 内置关联数据类型(在一些其他的语言中称为哈希 或者字典 )。
创建一个空 map
m := make(map[string]int)
设置键值对对map赋值
m["k"] = 7
使用 name[key] 来获取一个键的值
v := m["k"]fmt.Println("v: ", v)
当对一个 map 调用内建的 len 时,返回的是键值对数目
fmt.Println("len:", len(m))
内建的 delete 可以从一个 map 中移除键值对
delete(m, "k")
复制代码
当从一个 map 中取值时,可选的第二返回值指示这个键是在这个 map 中。这可以用来消除键不存在和键有零值,像 0 或者 “” 而产生的歧义。
val, ok := m["k"]fmt.Println("val:", val)
如果想更深入了解map实现原理的同学,可查看我得这篇小结 Array、Slice、Map原理浅析
func
使用关键字 func 定义函数
func test(a, b int) int {return a + b}
其中,有返回值的函数,必须有明确的终止语句,否则会引发编译错误。
函数是可变参的,变参的本质上是slice,只能有一个,且必须是最后一个,如
func test(s string, n ...int) string {var x intfor _, i := range n {x += i}return fmt.Sprintf(s, x)}
Golang 函数支持多返回值。这个特性在 Go 语言中经常被用到,例如用来同时返回一个函数的结果和错误信息。
func vals() (int, int) {return 3, 7}
return && defer
defer用于资源的释放,会在函数返回之前进行调用。一般采用如下模式:
func test() {f, err := os.Open(filename)if err != nil {panic(err)}defer f.Close()}
复制代码
如果有多个defer表达式,调用顺序类似于栈,越后面的defer表达式越先被调用,即后入先出的规则。
func test() {defer fmt.Println(1)defer fmt.Println(2)}
输出结果为
2
1
为了更深刻理解 defer 和 return 下面我们先来看几个例子。
例1:
func f() (result int) {defer func() {result++}()return 0}
复制代码
例2:
func f() (r int) {t := 5defer func() {t = t + 5}()return t}
例3:
func f() (r int) {defer func(r int) {r = r + 5}(r)return 1}
函数返回的过程是这样的:先给返回值赋值,然后调用defer表达式,最后才是返回到调用函数中。
defer表达式可能会在设置函数返回值之后,在返回到调用函数之前,修改返回值,使最终的函数返回值与你想象的不一致。
其实使用defer时,用一个简单的转换规则改写一下,就不会迷糊了。改写规则是将return语句拆成两句写,return xxx会被改写成:
返回值 = xxx
调用defer函数
空的return
复制代码
下面我们针对上面的三个例子分析,先看例1,它可以改写成这样:
func f() (result int) {result = 0 //return语句不是一条原子调用,return xxx其实是赋值+ret指令func() { //defer被插入到return之前执行,也就是赋返回值和ret指令之间result++}()return}
复制代码
所以这个返回值是1。
例2,它可以改写成这样:
func f() (r int) {t := 5r = t //赋值指令func() { //defer被插入到赋值与返回之间执行,这个例子中返回值r没被修改过t = t + 5}return //空的return指令}
复制代码
所以这个返回值是5。
例3,它可以改写成这样:
func f() (r int) {r = 1 //给返回值赋值func(r int) { //这里改的r是传值传进去的r,不会改变要返回的那个r值r = r + 5}(r)return //空的return}
复制代码
所以这个返回值是1。
defer确实是在return之前调用的。但表现形式上却可能不像。本质原因是return xxx语句并不是一条原子指令,defer被插入到了赋值 与 ret之间,因此可能有机会改变最终的返回值。
goroutine的控制结构中,有一张表记录defer,调用runtime.deferproc时会将需要defer的表达式记录在表中,而在调用runtime.deferreturn的时候,则会依次从defer表中出栈并执行。
type
type是go语法里的重要而且常用的关键字,其主要作用就是用来定义类型。
定义结构体
type Person struct {name string}
复制代码
类型等价定义,相当于类型重命名
type name stringfunc main() {var myname name = "golang" //其实就是字符串类型fmt.Println(myname)}
复制代码
定义接口
type Person interface {Run()}
struct
Go 的结构体 是各个字段字段的类型的集合。是值类型,赋值和传参会赋值全部内容。
struct的基本用法
type Person struct {Name stringAge int}func main() {p := Person{Name: "ck",Age: 20,}p.Age = 25fmt.Println(p)}
复制代码
顺序初始化必须包含全部字段。否则会报错
type Person struct {Name stringAge int}func main() {p1 := Person{"ck", 20}p2 := Person{"ck"} // Error: too few values in struct initializer}
复制代码
支持匿名结构,可用作结构成员或定义变量
type Person struct {Name stringAttr struct{age int}}
复制代码
支持 “==”、”!=” 相等操作符,可用作 map 键类型。
type Person struct {Name string}m := map[Person]int{Person{"ck"}: 10,}
复制代码
struct 支持嵌入式结构,可以像普通字段那样访问匿名字段成员,如下
type Person struct {Name string}type User struct {PersonAge int}func main() {u := User{Person: Person{Name: "ck",},Age: 22,}fmt.Println(u.Name) // ck}
当被嵌入结构中的某个字段与当前struct中已存在的字段同名时,编译器从外向内逐级查找所有层次的匿名字段,直到发现目标或者报错。
type Person struct {Age int}type User struct {PersonAge int}func main() {u := User{Person: Person{Age: 20,},Age: 22,}fmt.Println(u.Age) // 22}
如果想访问被嵌入结构Person中的Age
fmt.Println(u.Person.Age) // 20
interface
首先 interface 是一种类型,从它的定义可以看出来用了 type 关键字,更准确的说 interface 是一种具有一组方法的类型,这些方法定义了 interface 的行为。
如果一个类型实现了一个 interface 中所有方法,我们说类型实现了该 interface,所以所有类型都实现了 empty interface,因为任何一种类型至少实现了 0 个方法。go 没有显式的关键字用来实现 interface,只需要实现 interface 包含的方法即可。
接口定义与基本操作
type Dog interface {Category()}type Ha struct {Name string}func (h Ha) Category() {fmt.Println("狗子")}func main() {h := Ha{"二哈"}h.Category()test(h)}func test(a Dog) {fmt.Println("成功调用啦")}// 输出结果为:狗子 成功调用啦
上述代码中可以看到,对于 test 函数接收的参数类型为 Dog 这个类型,我们传入的是 Ha 类型的h,该函数正常运行并输出了结果,说明 Ha 类型已经成功实现了 Dog 。
嵌入结构
当我们需要使用复杂结构关系的时候,我们就会需要用到嵌入接口。接下来,我们将上述例子修改一下,如下所示
type Dog interface {Animal}type Animal interface {Category()}type Ha struct {Name string}func (h Ha) Category() {fmt.Println("狗子")}func main() {h := Ha{"二哈"}h.Category()test(h)}func test(a Dog) {fmt.Println("成功调用啦")}// 输出结果为:狗子 成功调用啦
可以看到,程序同样正常运行,这也就证明了我们成功是实现了嵌入接口。
类型断言
一个 interface 被多种类型实现时,有时候我们需要区分 interface 的变量究竟存储哪种类型的值。
go 可以使用 comma, ok 的形式做区分 value, ok := em.(T):em 是 interface 类型的变量,T代表要断言的类型,value 是 interface 变量存储的值,ok 是 bool 类型表示是否为该断言的类型 T。。
type Dog interface {Animal}type Animal interface {Category()}type Ha struct {Name string}func (h Ha) Category() {fmt.Println("狗子")}func main() {h := Ha{"二哈"}h.Category()test(h)}func test(a Dog) {if v, ok := a.(Ha); ok {fmt.Println(v.Name)}}// 输出结果为:狗子 二哈
如果需要区分多种类型,可以使用 switch 断言,更简单直接,这种断言方式只能在 switch 语句中使用。
type Dog interface {Animal}type Animal interface {Category()}type Ha struct {Name string}func (h Ha) Category() {fmt.Println("狗子")}func main() {h := Ha{"二哈"}h.Category()test(h)}func test(a Dog) {switch v := a.(type) {case Ha:fmt.Println(v.Name)default:fmt.Println("暂未匹配到该类型")}}// 输出结果为:狗子 二哈
空接口
空接口 interface{} 没有任何方法签名,也就意味着任何类型都实现了空接口。其作用类似于面向对象语言中的根对象 Object 。
func Print(v interface{}) {fmt.Println(v)}func main() {Print(1)Print("Hello, World")}// 输出结果为:1 Hello, World
复制代码
既然空的 interface 可以接受任何类型的参数,那么一个 interface{}类型的 slice 是不是就可以接受任何类型的 slice ?
func printAll(vals []interface{}) { //1for _, val := range vals {fmt.Println(val)}}func main(){names := []string{"stanley", "david", "oscar"}printAll(names)}
执行之后竟然会报 cannot use names (type []string) as type []interface {} in argument to printAll 错误,why?
这个错误说明 go 没有帮助我们自动把 slice 转换成 interface{} 类型的 slice,所以出错了。go 不会对 类型是interface{} 的 slice 进行转换 。
但是我们可以手动进行转换来达到我们的目的。
var dataSlice []int = foo()var interfaceSlice []interface{} = make([]interface{}, len(dataSlice))for i, d := range dataSlice {interfaceSlice[i] = d}
有个坑需要注意
如果是按 pointer 调用,go 会自动进行转换,因为有了指针总是能得到指针指向的值是什么,如果是 value 调用,go 将无从得知 value 的原始值是什么,因为 value 是份拷贝。go 会把指针进行隐式转换得到 value,但反过来则不行。
for
for 是 Go 中唯一的循环结构。这里有 for 循环的三个基本使用方式。
最常用的方式,带单个循环条件
i := 1for i <= 3 {fmt.Println(i)i = i + 1}
复制代码
经典的初始化/条件/后续形式 for 循环
for j := 7; j <= 9; j++ {fmt.Println(j)}
复制代码
不带条件的 for 循环将一直执行,直到在循环体内使用了 break 或者 return 来跳出循环。
for {fmt.Println("loop")break}
if else
golang 中 if 要注意的点是
- 可省略条件表达式的括号。
- 支持初始化语句,可定义代码块局部变量。
- 代码块左大括号必须在条件表达式尾部。
- 不支持三元操作符 “a > b ? a : b”
if num := 9; num < 0 {fmt.Println(num, "is negative")} else if num < 10 {fmt.Println(num, "has 1 digit")} else {fmt.Println(num, "has multiple digits")}
switch case default
switch sExpr {case expr1:some instructionscase expr2:some other instructionscase expr3:some other instructionsdefault:other code}
sExpr和expr1、expr2、expr3的类型必须一致。Go的switch非常灵活,表达式不必是常量或整数,执行的过程从上至下,直到找到匹配项;而如果switch没有表达式,它会匹配true。 Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch
fallthrough
在switch中,使用fallthrough可以强制执行后面的case代码。
switch sExpr {case false:fmt.Println("The integer was <= 4")fallthroughcase true:fmt.Println("The integer was <= 5")fallthroughcase false:fmt.Println("The integer was <= 6")fallthroughcase true:fmt.Println("The integer was <= 7")case false:fmt.Println("The integer was <= 8")fallthroughdefault:fmt.Println("default case")}}
复制代码
输出
The integer was <= 5The integer was <= 6The integer was <= 7
for break continue goto range
for 是 Go 中唯一的循环结构。这里有 for 循环的三个基本使用方式。
最常用的方式,带单个循环条件。
i := 1for i <= 3 {fmt.Println(i)i = i + 1}
复制代码
经典的初始化/条件/后续形式 for 循环。
for j := 7; j <= 9; j++ {fmt.Println(j)}
不带条件的 for 循环将一直执行,直到在循环体内使用了 break 或者 return 来跳出循环。
for {fmt.Println("loop")break}
break是跳出本次循环,continue是跳过该次循环,继续下次循环。
go
轻松开启高并发,一直都是golang语言引以为豪的功能点。golang通过goroutine实现高并发,而开启goroutine的钥匙正是go关键字。开启并发执行的语法格式是:
go funcName()
select
Go的select关键字可以让你同时等待多个通道操作,将协程(goroutine),通道(channel)和select结合起来构成了Go的一个强大特性。
package mainimport "time"import "fmt"func main() { // 本例中,我们从两个通道中选择c1 := make(chan string)c2 := make(chan string) // 为了模拟并行协程的阻塞操作,我们让每个通道在一段时间后再写入一个值go func() {time.Sleep(time.Second * 1)c1 <- "one"}()go func() {time.Sleep(time.Second * 2)c2 <- "two"}() // 我们使用select来等待这两个通道的值,然后输出for i := 0; i < 2; i++ {select {case msg1 := <-c1:fmt.Println("received", msg1)case msg2 := <-c2:fmt.Println("received", msg2)}}}
输出结果
received onereceived two
如我们所期望的,程序输出了正确的值。对于select语句而言,它不断地检测通道是否有值过来,一旦发现有值过来,立刻获取输出。
chan
channel[通道]是golang的一种重要特性,正是因为channel的存在才使得golang不同于其它语言。channel使得并发编程变得简单容易有趣。
一个channel可以理解为一个先进先出的消息队列。如下图所示:
创建channel有以下几种 方式,
var ch chan string; // nil channelch := make(chan string); // zero channelch := make(chan string, 10); // buffered channel
channel里面的value buffer的容量也就是channel的容量。channel的容量为零表示这是一个阻塞型通道,非零表示缓冲型通道[非阻塞型通道]。
但是,这里有个坑,当channel的容量为0时,for循环一次开10个goroutine打印输出,此时理论上应该是顺序输出的,但是确实无序输出的,这是因为现在的 Go 默认就是启用的多核,不像以前版本还需要手动设置使用多核

若有收获,就点个赞吧
0 人点赞
