HashMap
基础
默认大小 1<<4 也就是2^4 =16
loadfactory(负载系数/或者说水位) 默认 0.75 为啥??map大小必然是2的N次方 最佳性能应该是log(2)==0.7左右 取0.75 即(3/4) 可能就是为了取整
几个问题
1:为什么hashmap的容量是2的幂
取2的幂 是最优解,不是绝对解
hashmap采用链表地址定位,长度取2的幂 最大下标必然为 111.。。。。可以将系统因素照成的hash定位影响降到最低,换句话说,每个下标的分布概率都是一样的
2:hashmap 重写的hash方法 有什么意义?
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
这个函数作用在于扰动hash低位数值 由于链表下标定位,如果key的hash低位完全一样,则会hash碰撞
将高位与低位异或,可以将高位的属性加入寻址的考虑,减少碰撞概率
为啥是16? 可能是对半取吧~~~
源码分析
看源码可以发现 modCount 字段可以保证读写线程同步时快速报错,但是,他不支持线程安全
获取线程安全的hashmap 可以用
1: Collections.synchronizedSortedMap()
2: ConcurrentHashMap
演示hash冲突
put源码
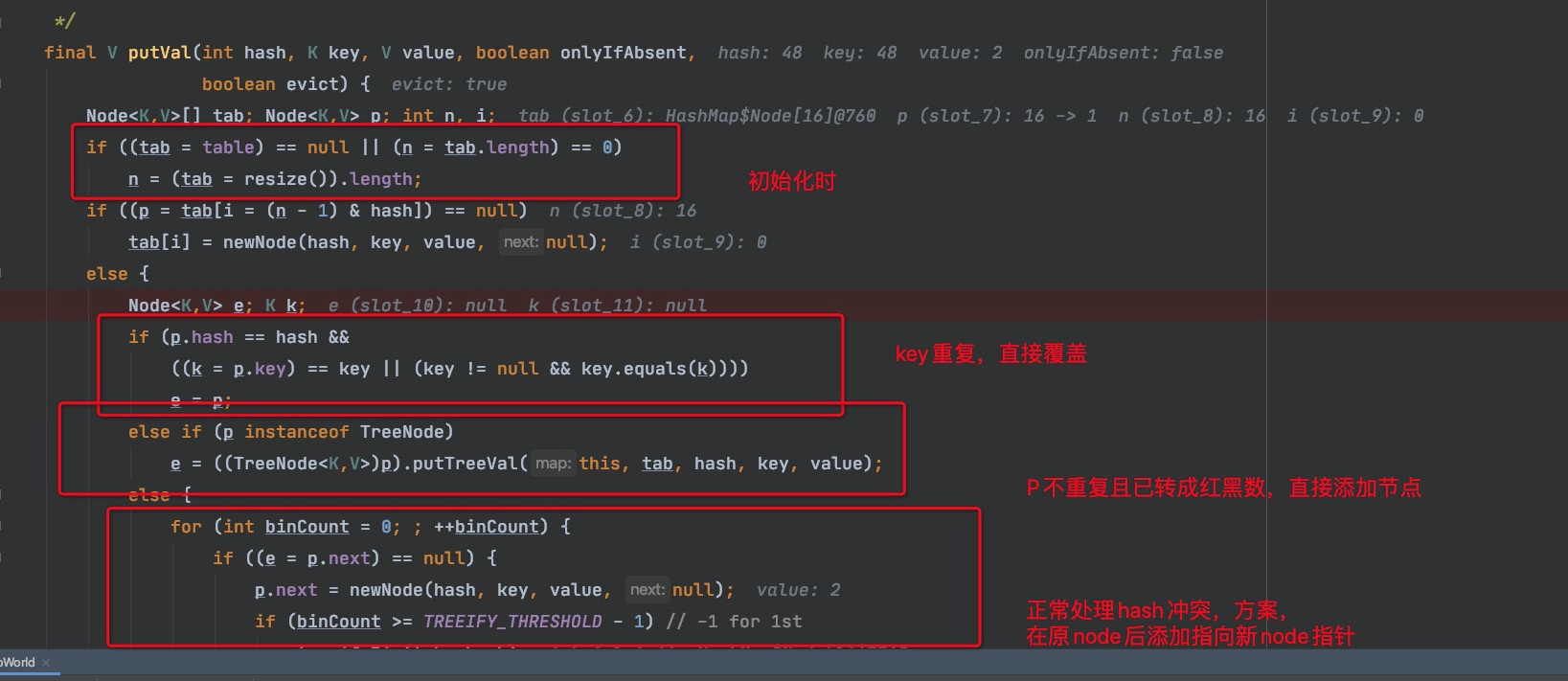
继续往后看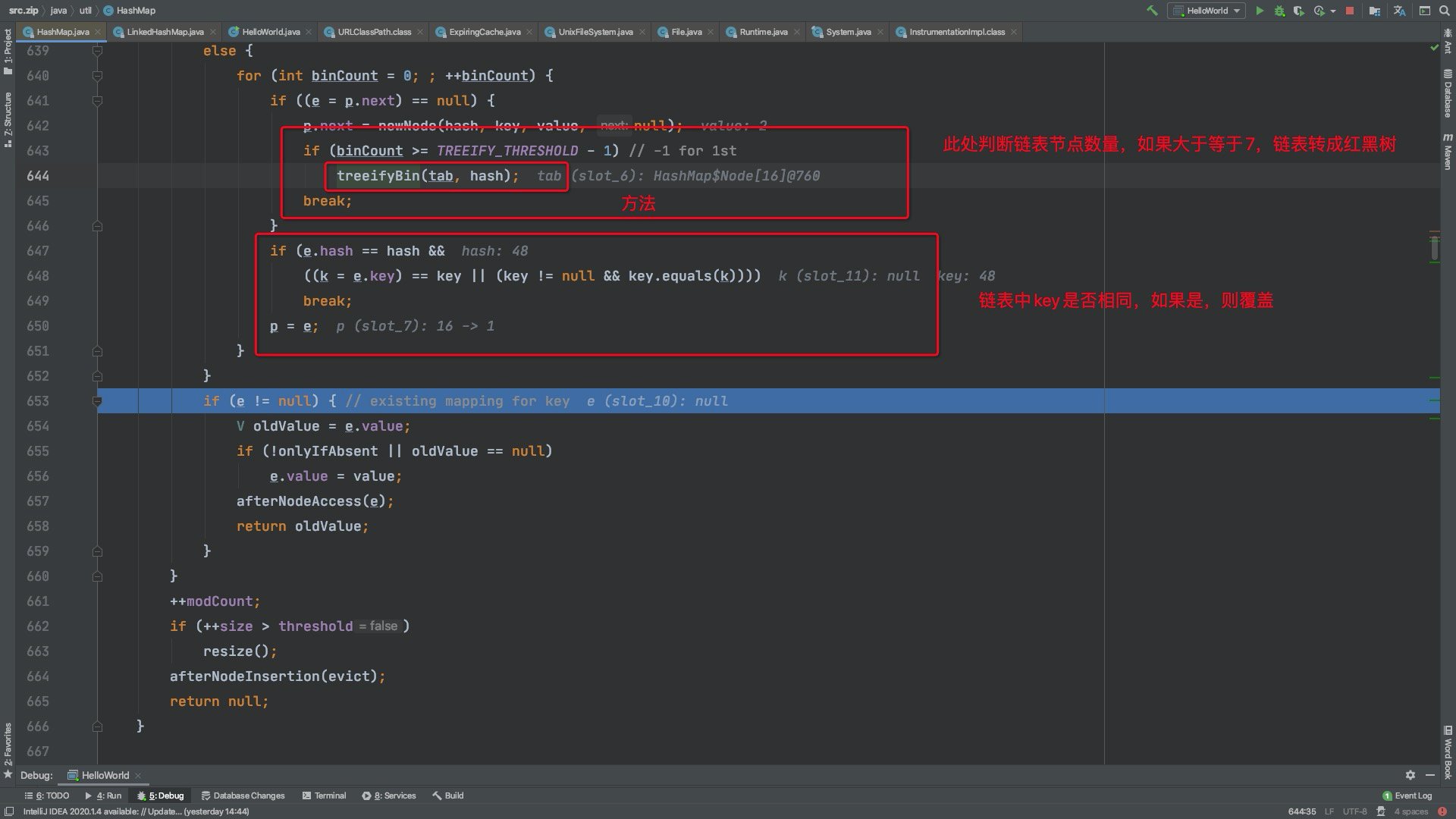
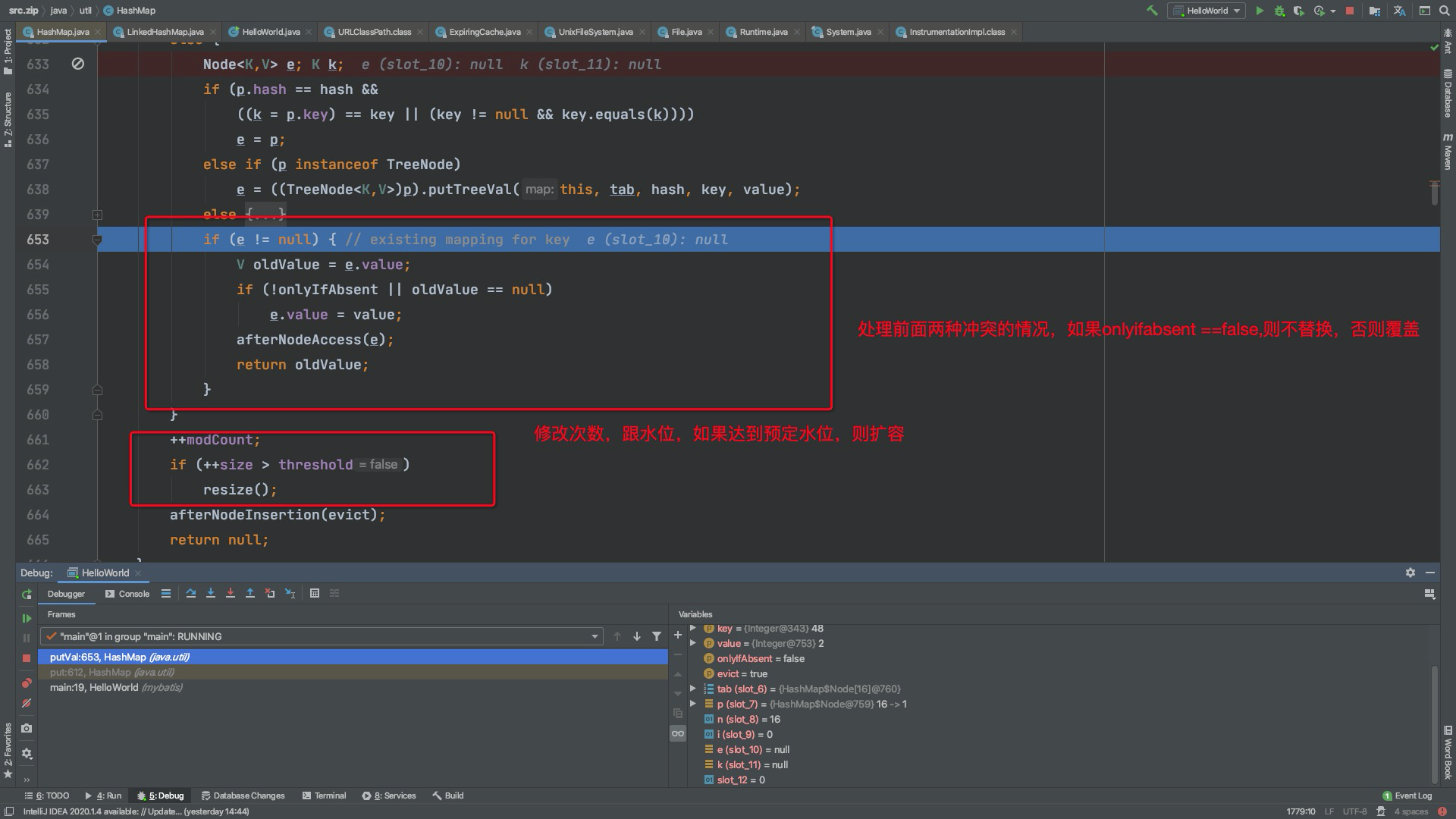
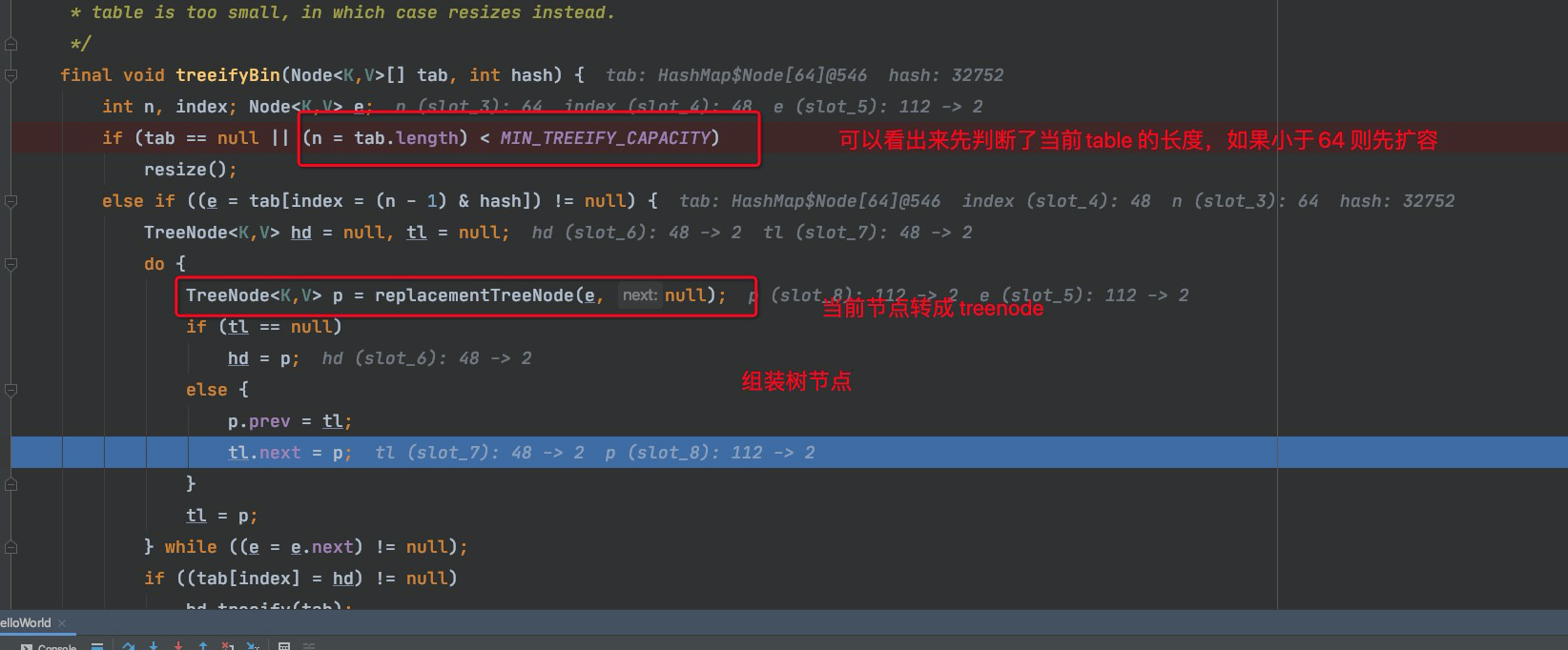
继续看一下链表转树源码
case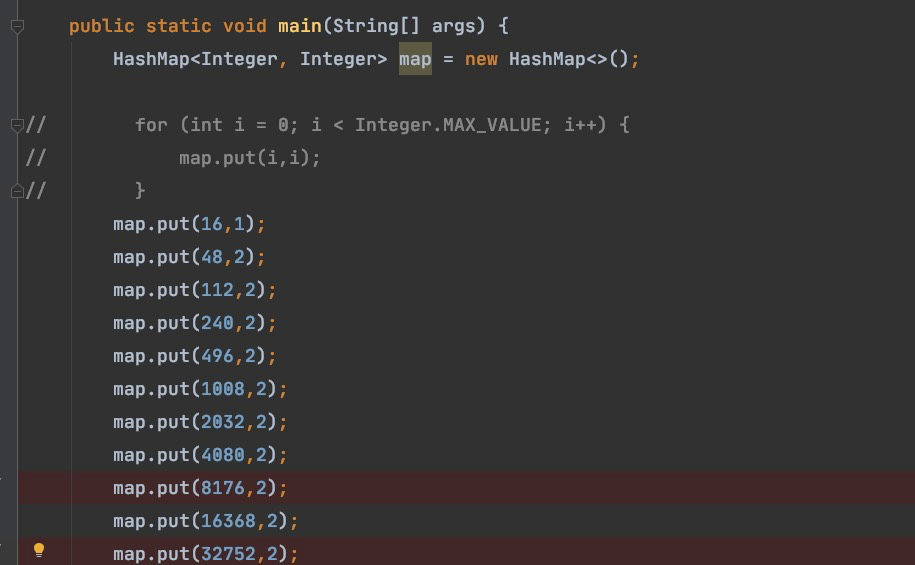
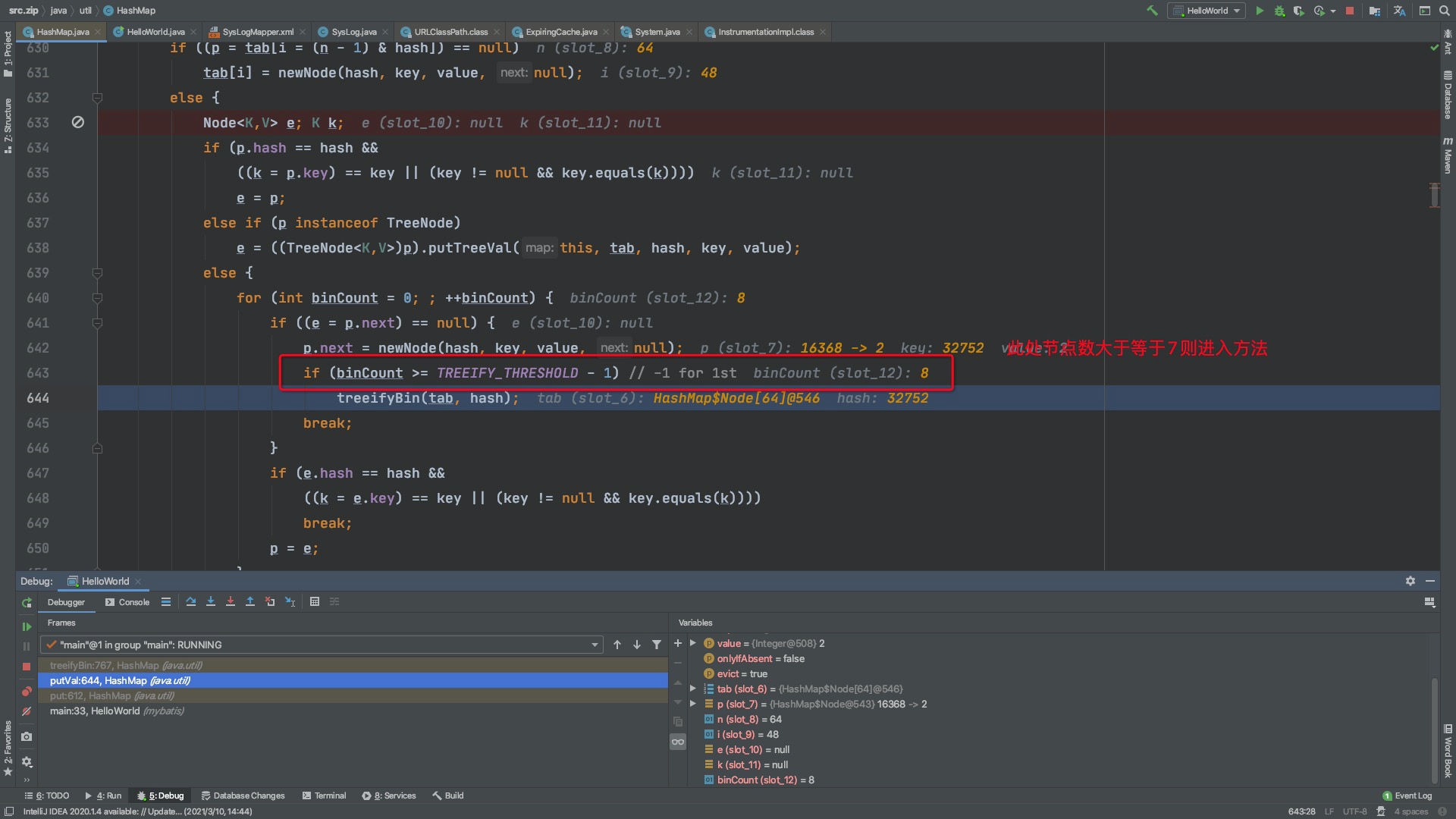
此时的数据结构转变
原 node 0 -> 1 ->2 ->3 ->4 … ->next
现在 TreeNode 0 -> 1 ->2 ->3 ->4 … ->next
0 <-1 <- 2<-3 <- 4 … <- prev
转成这样一种双向结构?
继续往下看
生成红黑树关键代码
可以看出来先比较key的hash值大小来决定插入左还是右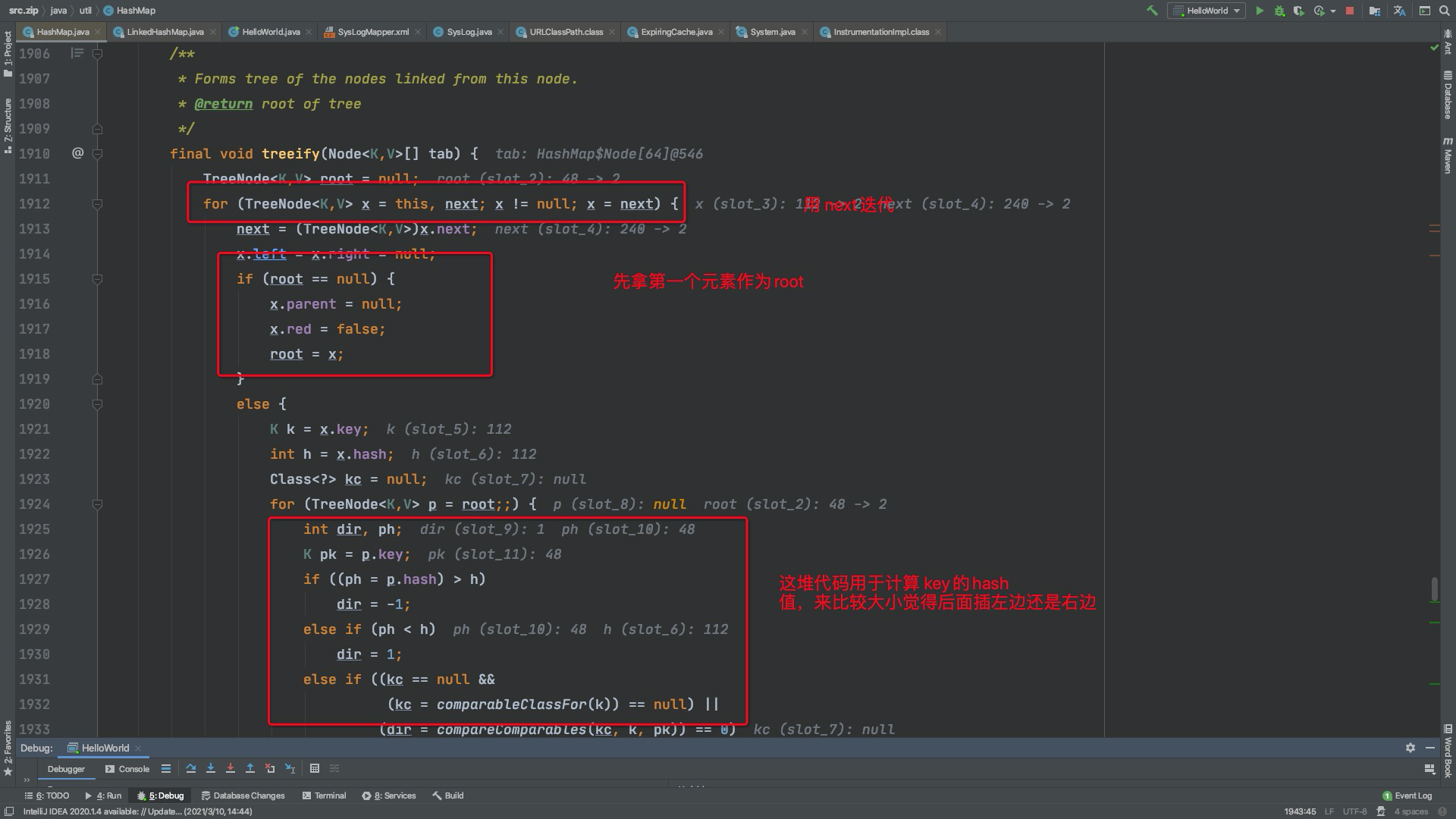
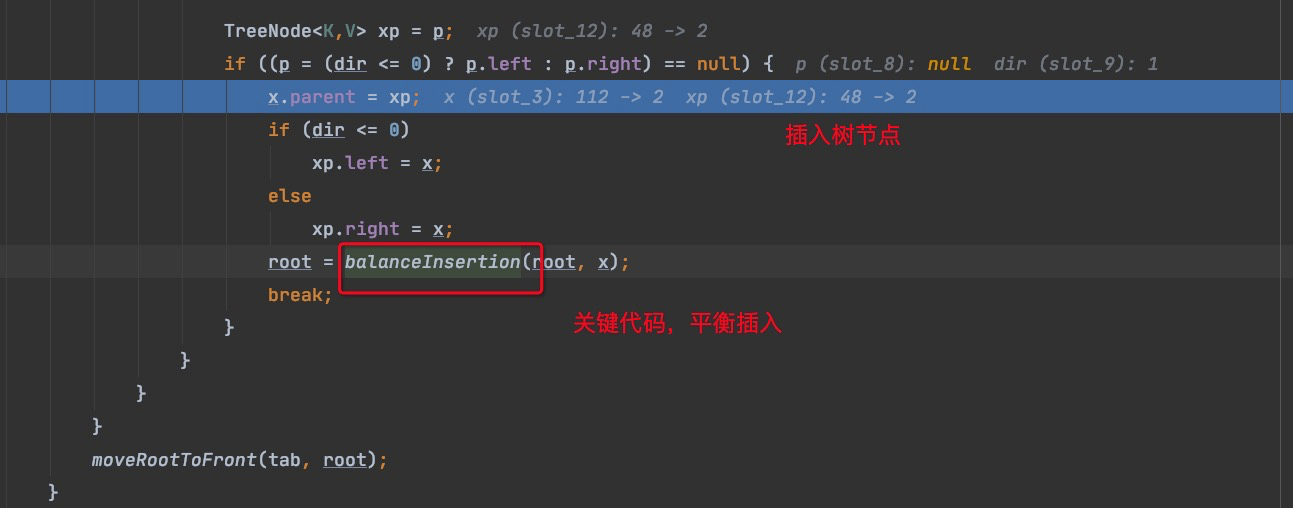
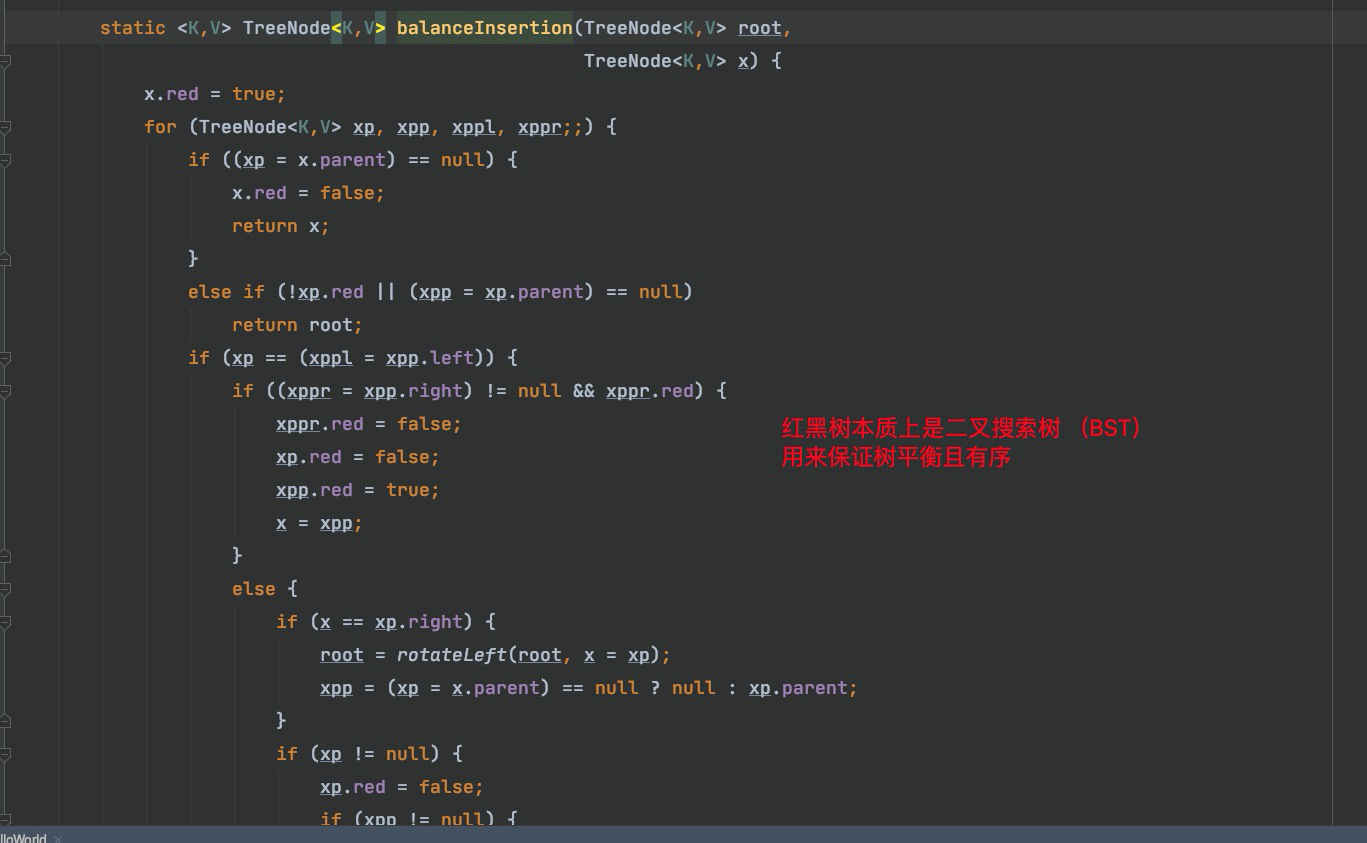
======put源码结束=====
所以hashmap的数据结构是 数组 +链表 + 红黑树
| table 数组,存储K,V HASH ,NEXT如果没有冲突就用数组, | 如果有冲突,用链表存到下标后用next查找 | 如果链表长度大于等于7且table长度大于等于64,转成红黑树 |
|---|---|---|
| 1 |
1.1 |
|
| 2 |
||
| 3 |
||
| 4 |
||
| 5 |
||
| 6 |
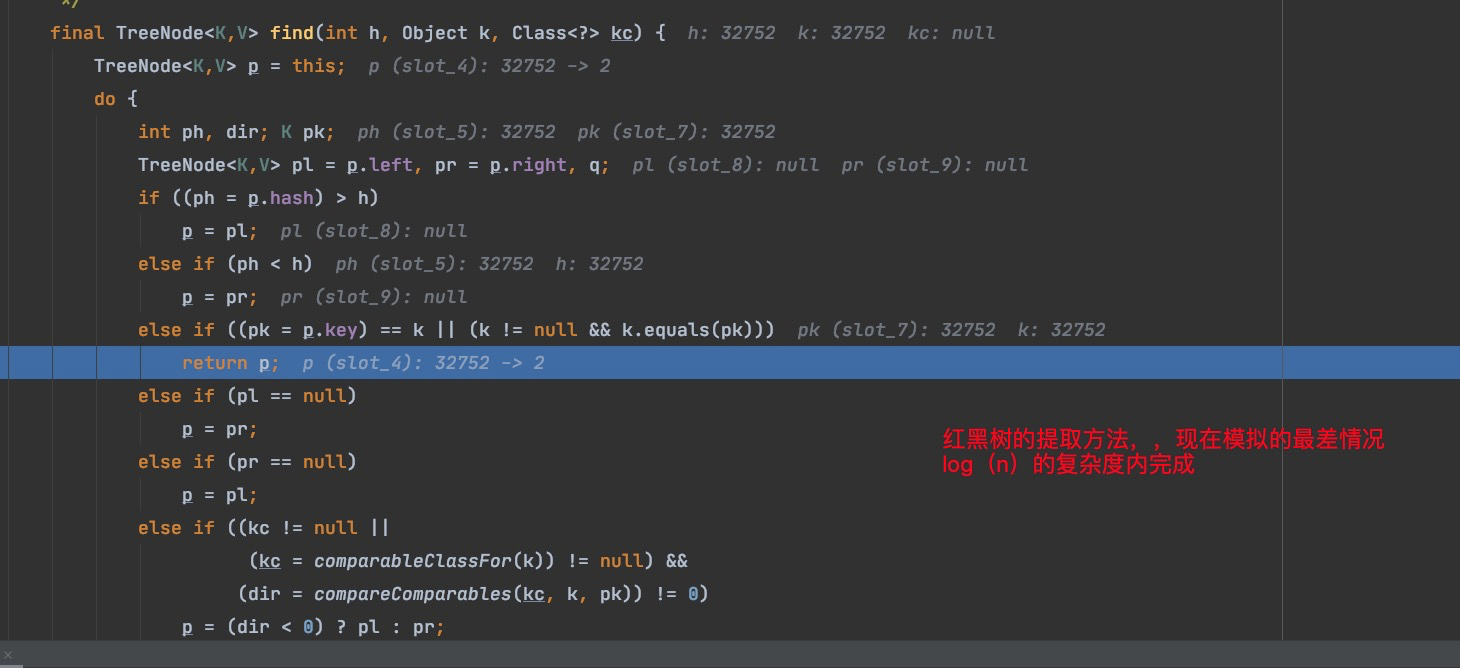
get源码
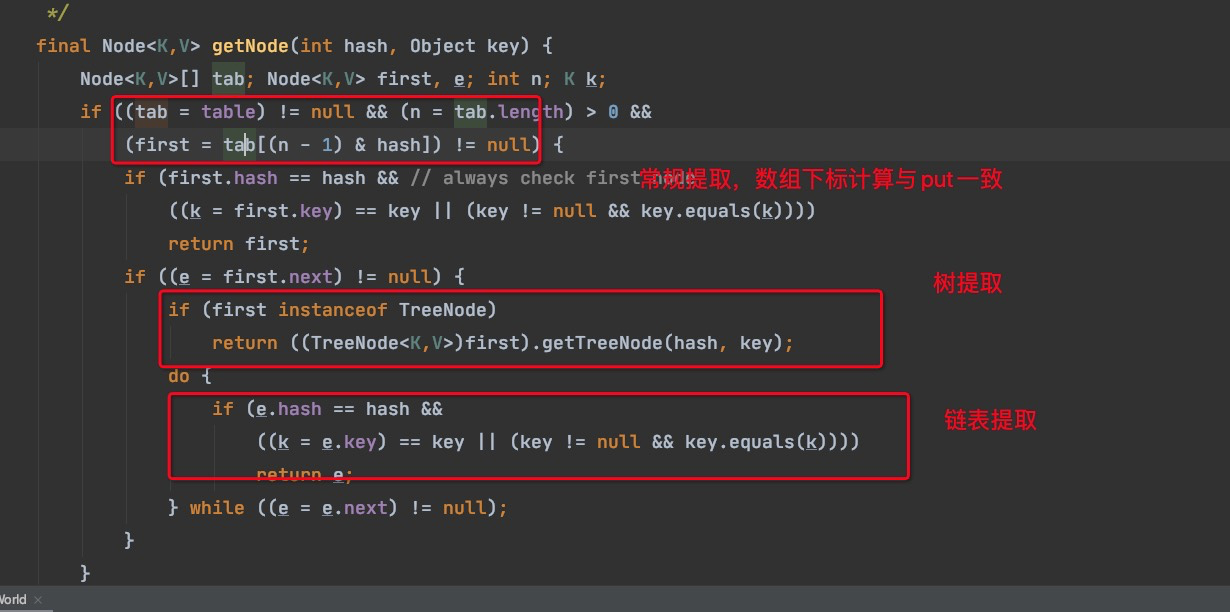
只看树提取的情况
常用方法
1:merge 1.8新增
源码
default V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) {Objects.requireNonNull(remappingFunction);Objects.requireNonNull(value);V oldValue = get(key);V newValue = (oldValue == null) ? value :remappingFunction.apply(oldValue, value);if(newValue == null) {remove(key);} else {put(key, newValue);}return newValue;}
解释
当key不存在是将value设为默认值,
当key存在时,执行remappingFunction 处理新值与旧值,超好用
例子,新老写法对比
如果 1 存在,则新旧值相加
如果1不存在value 为默认value
remappingFunction 处理新旧值运算
HashMap<String, Integer> map1 = new HashMap<>();/**新*/map1.merge("1",12, Integer::sum);map1.merge("1",14,Integer::sum);map1.merge("2",14,Integer::sum);/**老*/HashMap<String, Integer> map2 = new HashMap<>();if (map2.containsKey("1")){map2.put("1",map2.get("1")+2);}else {map2.put("1",3);}
2:putifabsent 如果不存在则插入
TreeMap
特点
红黑树的特性:
(1) 每个节点或者是黑色,或者是红色。
(2) 根节点是黑色。
(3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
(4) 如果一个节点是红色的,则它的子节点必须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
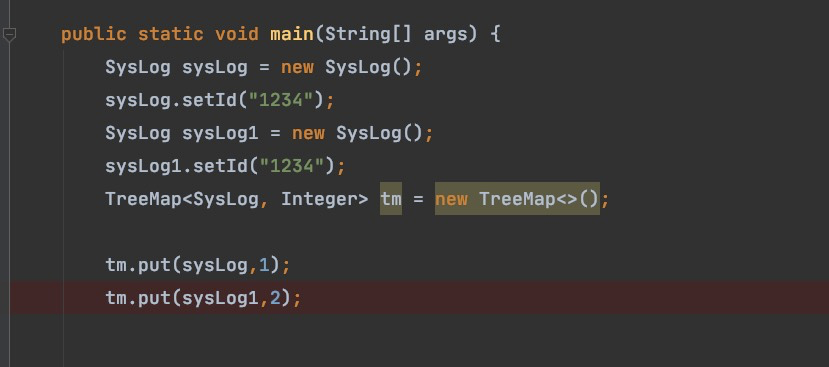
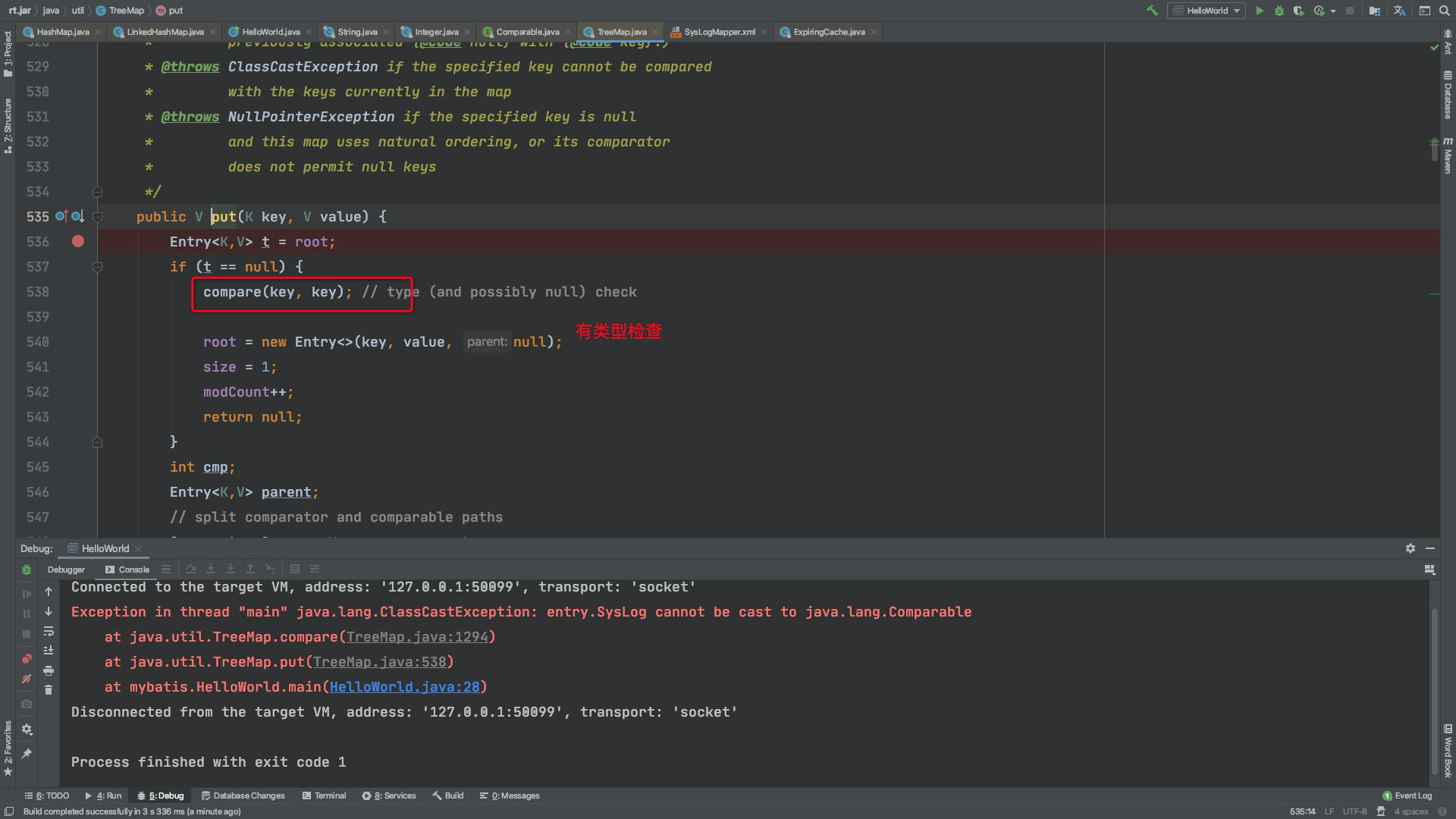
有类型检查,如果是自定义的类且没实现Comparable接口会报错哟
可以用包装类, Interger /String
非要用自定义的类就实现Comparable接口用于比较
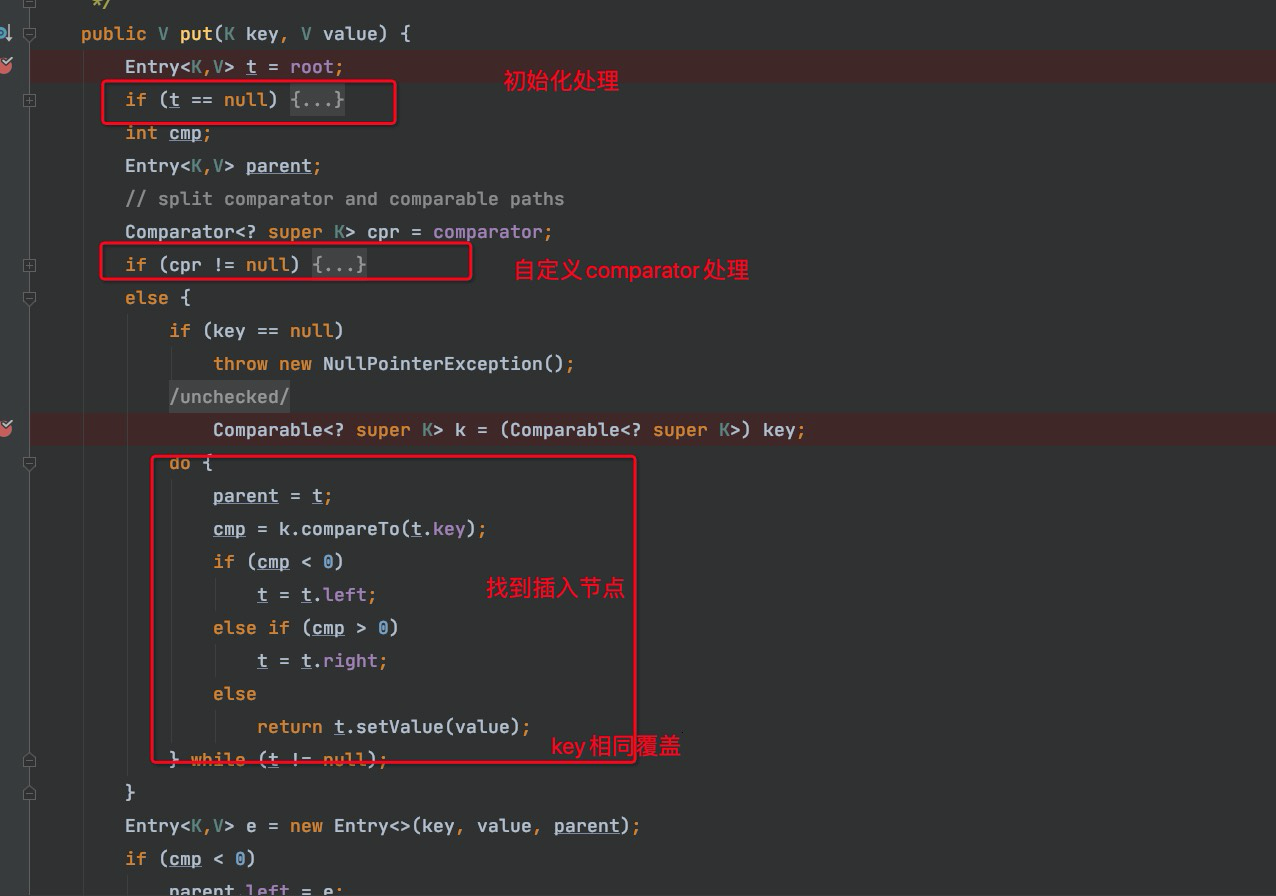
put 源码
1:case
2:case
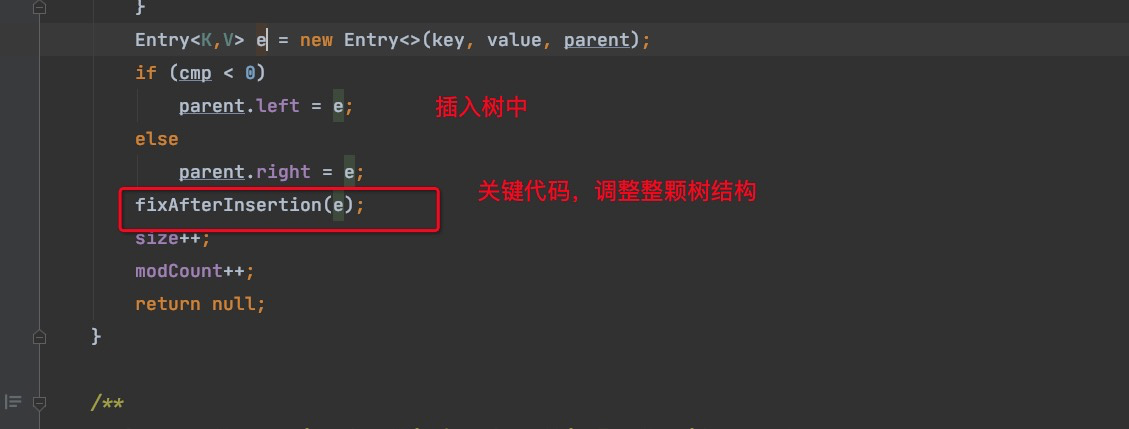
fixAfterInsertion 主要用来保持整颗树黑平衡,有点复杂,有空再看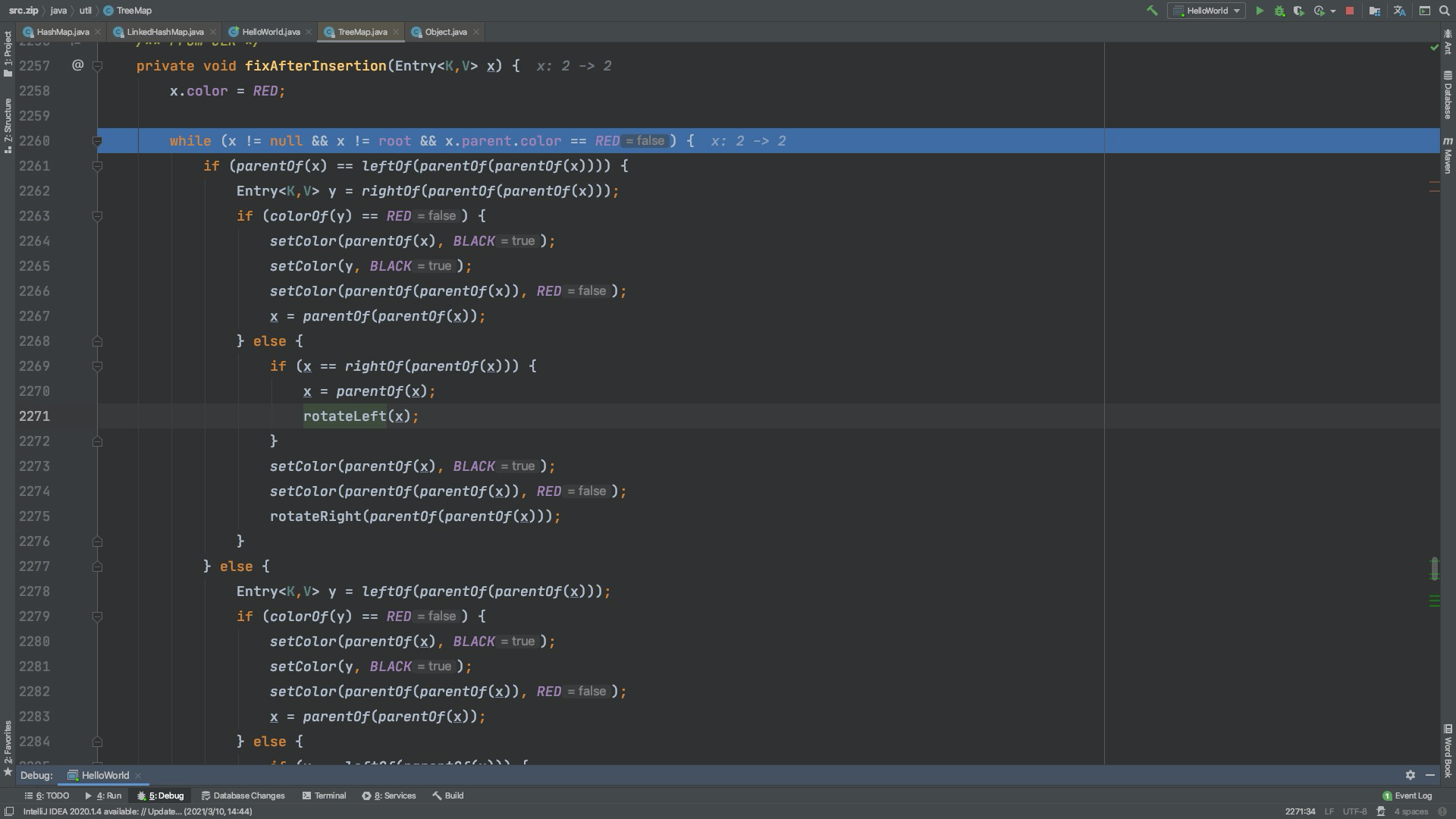
常用方法
case
TreeMap<Integer, Integer> tm = new TreeMap<>();tm.put(1,1);tm.put(2,2);tm.put(3,1);tm.put(4,2);tm.put(5,1);tm.put(6,2);tm.put(7,1);tm.put(8,2);tm.put(9,1);tm.put(10,2);
获取最大最小元素
firstEntry/ firstKey
lastEntry()/lastKey();
Map.Entry<Integer, Integer> integerIntegerEntry1 = tm.firstEntry();//System.out.println(integerIntegerEntry1); // 最小的元素Integer integer2 = tm.firstKey(); // 最小元素的keySystem.out.println(integer2);tm.lastEntry();tm.lastKey();
获取大于/小于目标元素
floorEntry/floorKey 小于
ceilingEntry/ceilingKey 大于
都是先获取自身,如果自己不存在则返回最接近的元素如果都不存在,返回null
Map.Entry<Integer, Integer> integerIntegerEntry2 = tm.floorEntry(3);System.out.println(integerIntegerEntry2); // 最后一个小于key的元素Integer integer3 = tm.floorKey(3);System.out.println(integer3); // 最后一个小于key的元素的key// 特有的方法Map.Entry<Integer, Integer> integerIntegerEntry = tm.ceilingEntry(3); //返回第一个比key大的元素System.out.println(integerIntegerEntry);Integer integer1 = tm.ceilingKey(3); //返回第一个比key大的元素 的keySystem.out.println(integer1);
获取大于/小于目标元素变形
相比于上面的,higherEntry 不会获取自身
higherEntry
Map.Entry<Integer, Integer> integerIntegerEntry3 = tm.higherEntry(3);System.out.println(integerIntegerEntry3);//大于key的所有元素(包含)Integer integer4 = tm.higherKey(3); // 大于key的所有keySystem.out.println(integer4);
完整元素视图
navigableKeySet 正序
descendingMap 、descendingKeySet 倒序
NavigableSet<Integer> integers = tm.navigableKeySet(); // 正序返回集合所有的keySystem.out.println(integers.toString());NavigableMap<Integer, Integer> dm = tm.descendingMap(); // 到序返回所有元素System.out.println(dm);
获取所有小于目标key的元素
SortedMap<Integer, Integer> integerIntegerSortedMap = tm.headMap(3);System.out.println(integerIntegerSortedMap);//小于key的所有元素(不包含改元素)SortedMap<Integer, Integer> integerIntegerSortedMap1 = tm.headMap(3,true);System.out.println(integerIntegerSortedMap1);//小于key的所有元素(包含改元素)
获取所有大于目标key的元素
SortedMap<Integer, Integer> integerIntegerSortedMap2 = tm.tailMap(3);System.out.println(integerIntegerSortedMap2);SortedMap<Integer, Integer> integerIntegerSortedMap3 = tm.tailMap(3,true);System.out.println(integerIntegerSortedMap3);
元素切片(获取区间元素)
SortedMap<Integer, Integer> integerIntegerSortedMap4 = tm.subMap(3, 5);System.out.println(integerIntegerSortedMap4);
LinkedHashMap
HashTable
线程安全、略

若有收获,就点个赞吧
0 人点赞
