基础
事务
相关命令
查事务级别
select @@transaction_isolation;
设置事务级别
set transaction_isolation=’READ-UNCOMMITTED’;
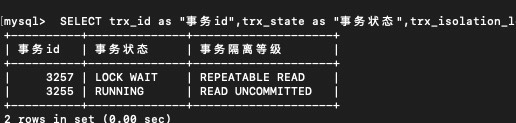
查事务详情
SELECT trx_id as “事务id”,trx_state as “事务状态”,trx_isolation_level as “事务隔离等级” FROM INFORMATION_SCHEMA.INNODB_TRX;
1:增删改时才会新增事务id

2:特性
原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)
3:隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读(虚读) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
4:演示
4.1 脏读演示
开启两个事务 RR RU
RU能读取到RR未提交数据,反之不行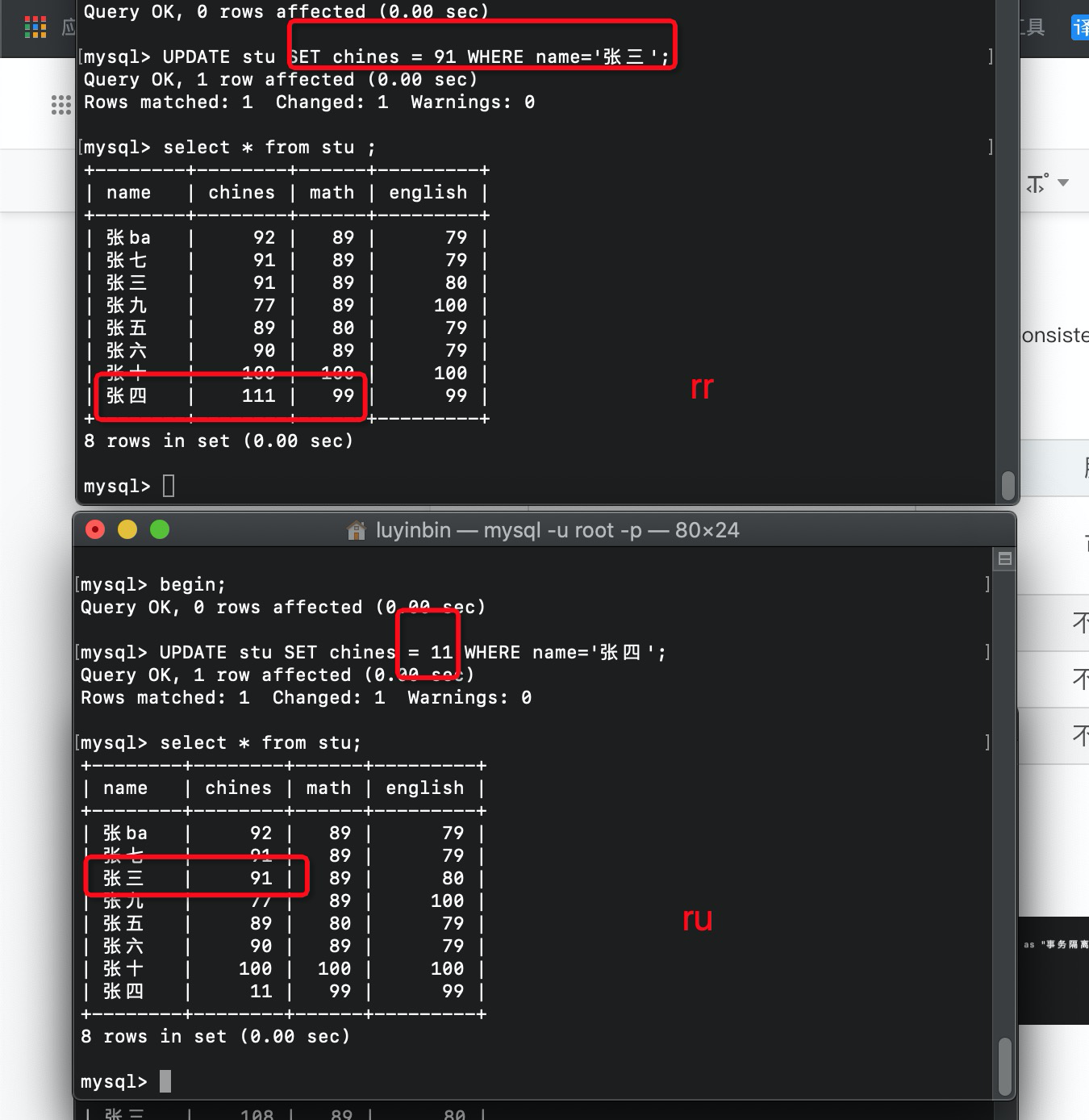
4.2 rc’ 不可重复读演示

同一事务两次读取数据不一致
t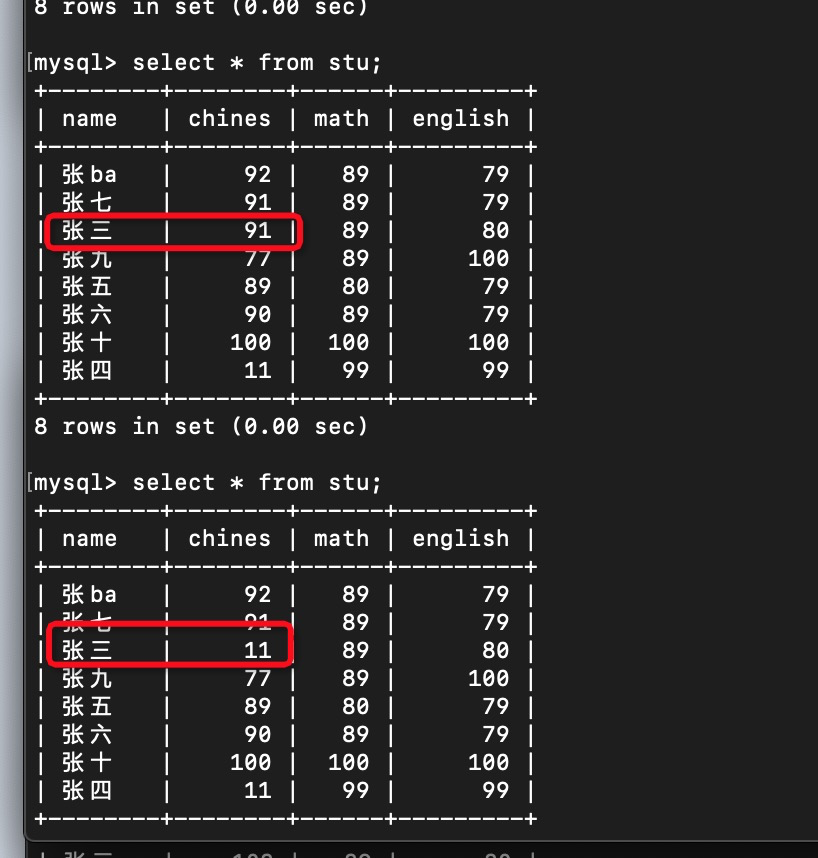
4.3 RR 幻读演示;
rr当前数据 T1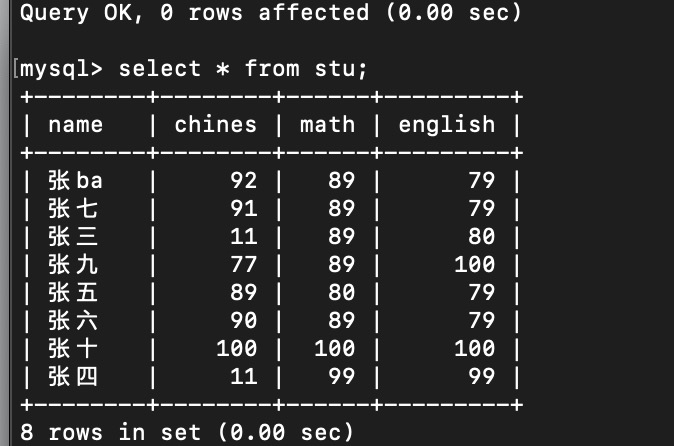
T2 事务插入并提交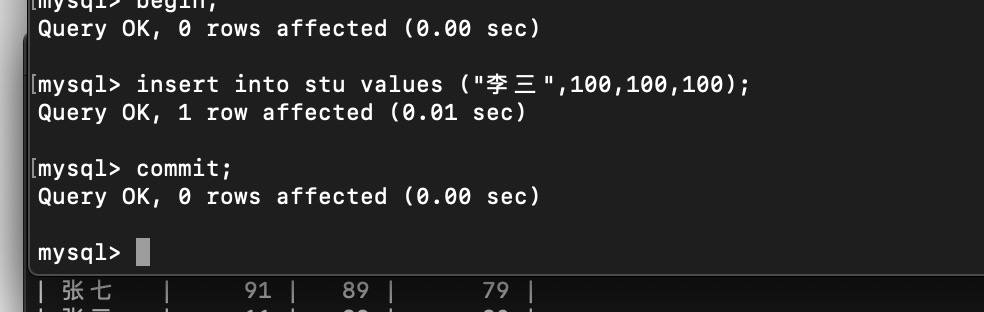
T1插入报错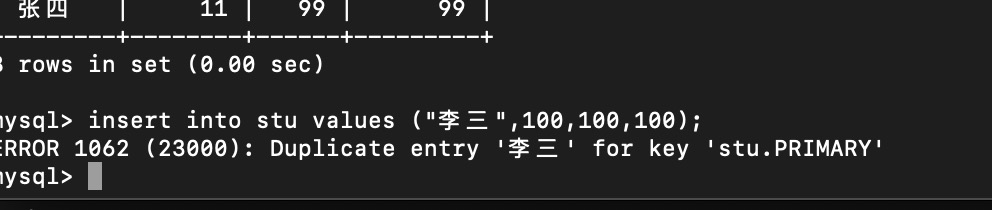
T1 再查
由于mvcc控制,查到的只是当前视图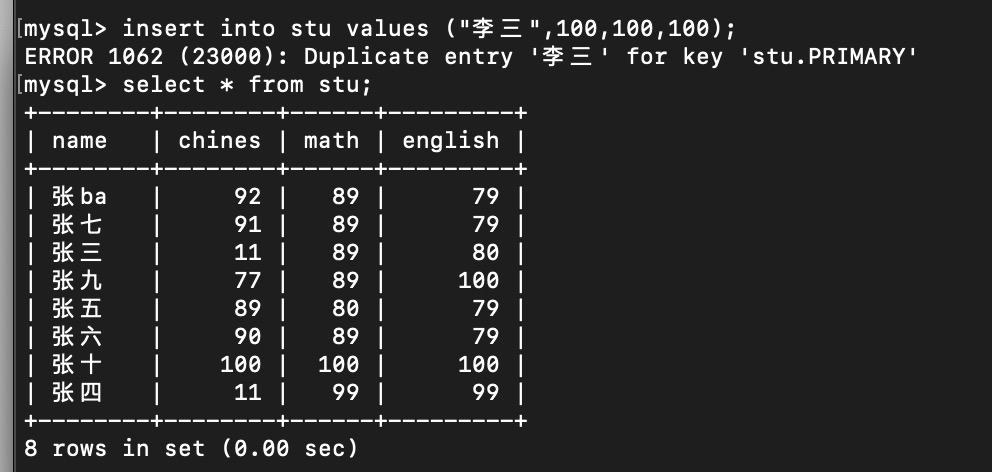
此时发生幻读
4.4 尝试加锁
T2 查询,加锁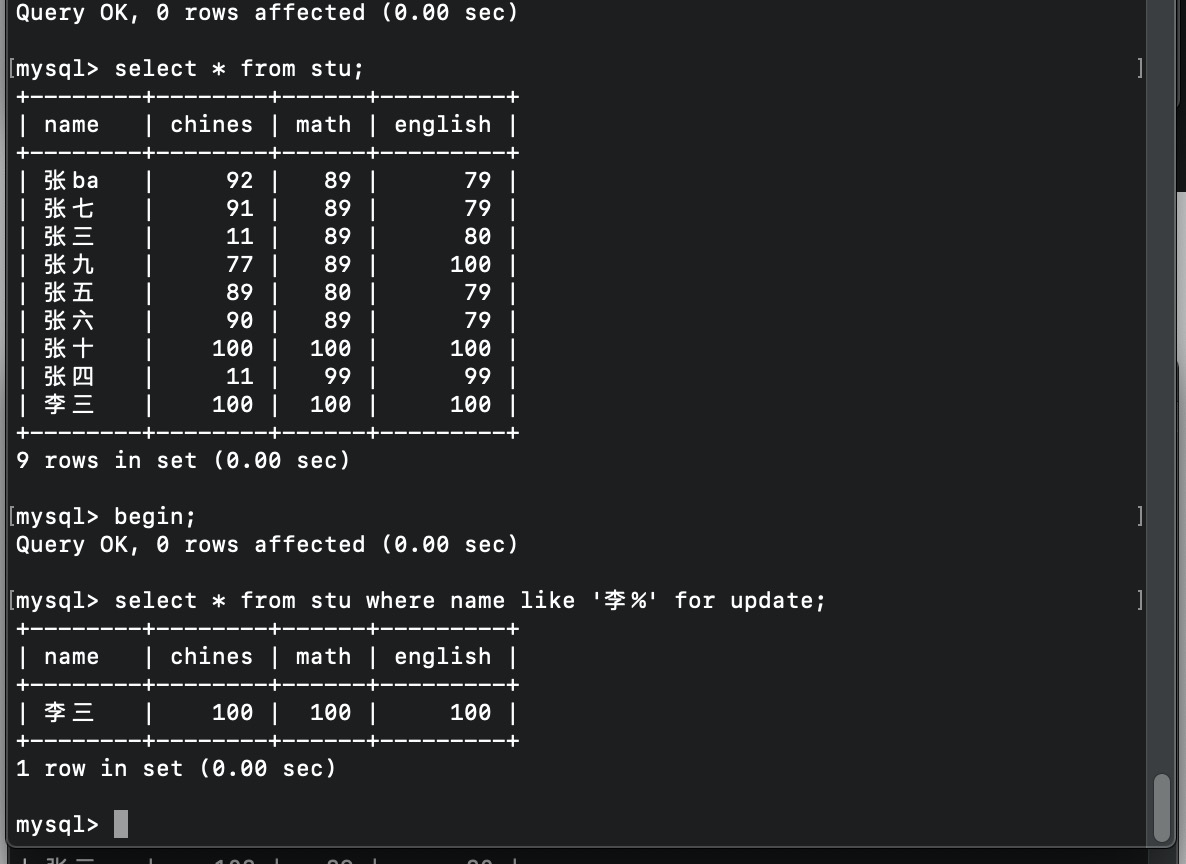
T1插入 阻塞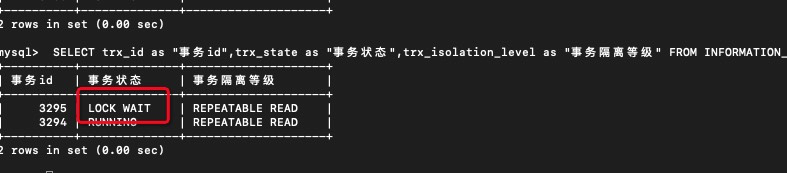
T2 插入提交
T1报错
5:一致性视图
必须得上这个图了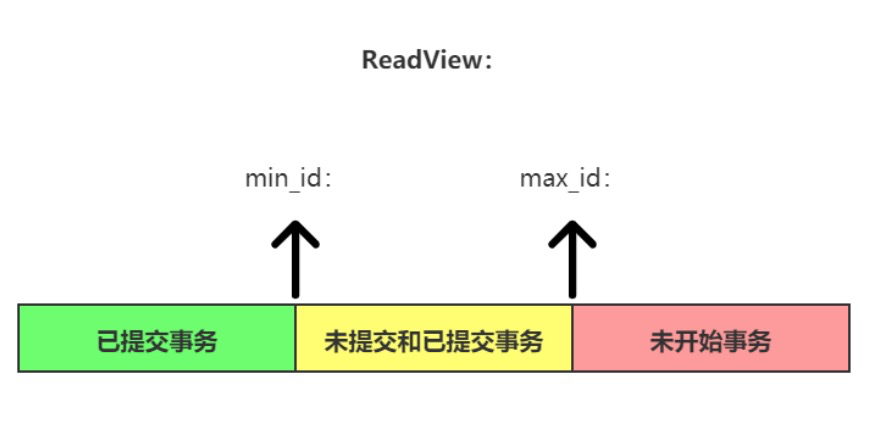
能查看的范围包括绿色及 黄色中 自己修改的记录
RC 更RR的区别
RC 每次select都会生成一次视图,如果这中间有其他事物提交,则能查到
RR
只在第一次select才会生成视图,事物内查询操作结果一至
但是注意,,在updata下,RR 是当前读
举例
T1 一致性视图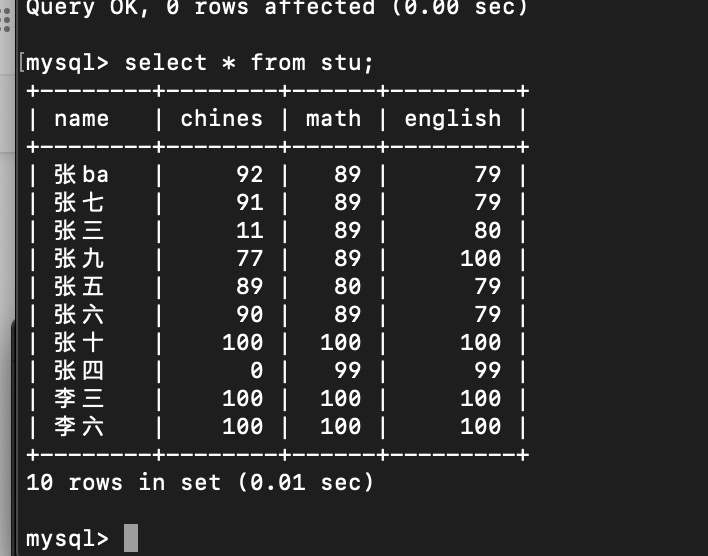
T2 更新视图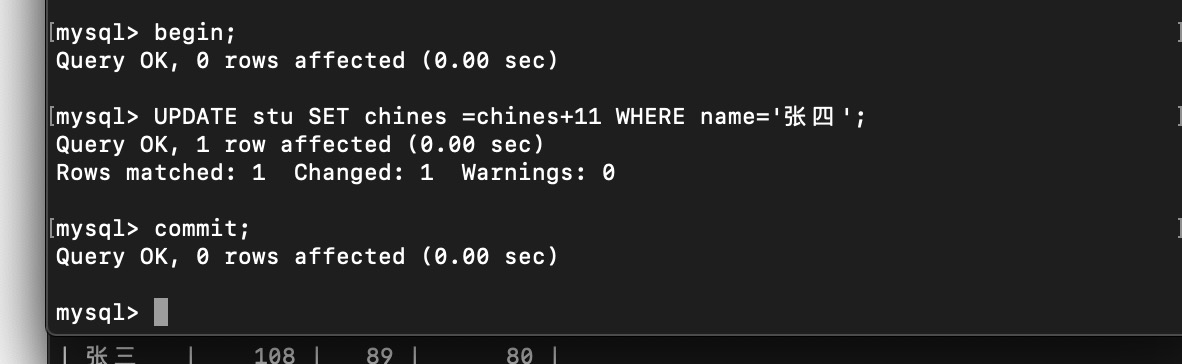
此时T1 直接查 还是一致性视图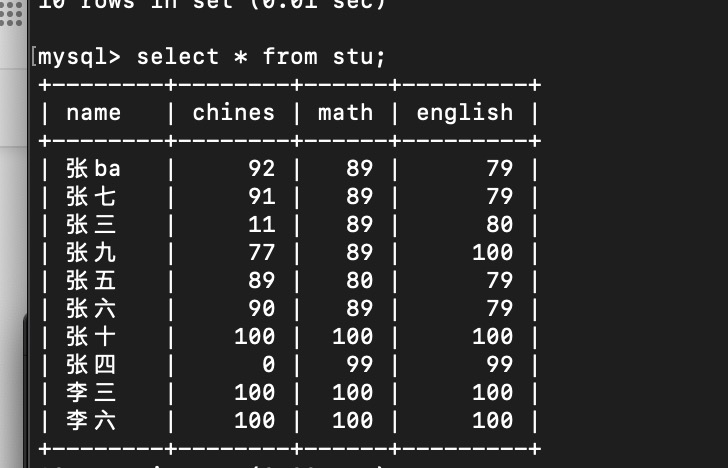
如果T1 update
按一致性查应该是11 ,结果是22 ,所以udate查的是当前视图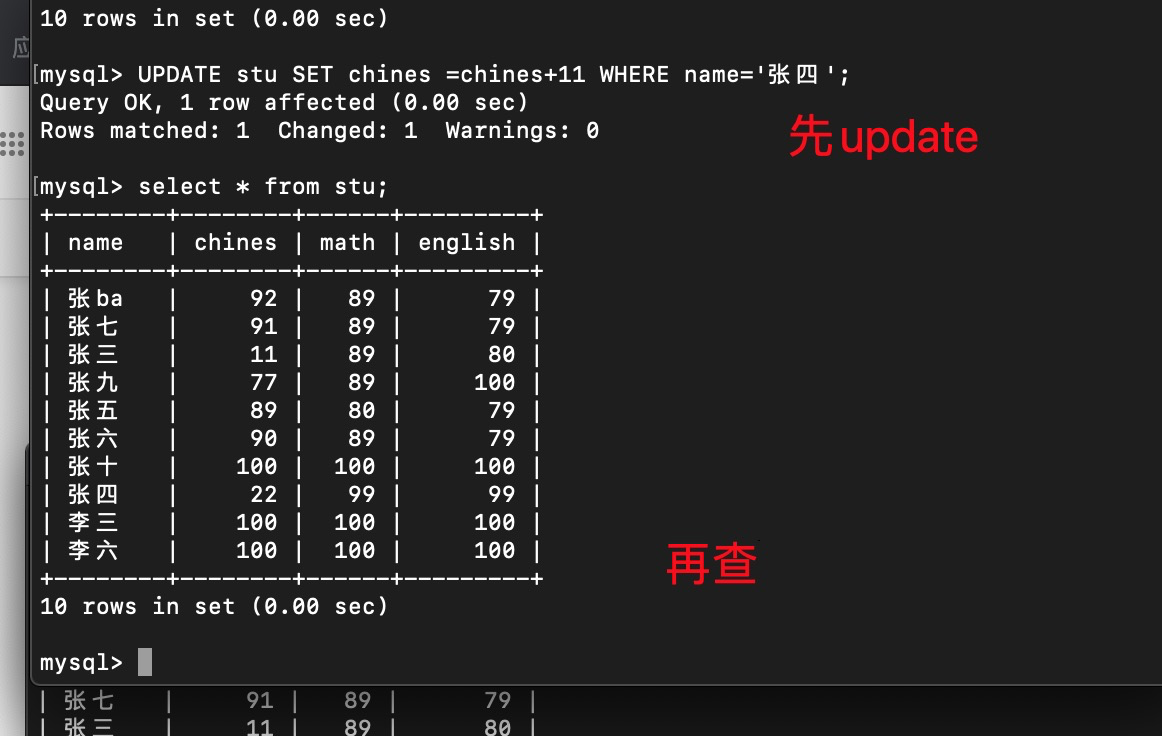
索引
1:概念
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
上面太多了,简化一下啥是索引
索引是一种维护了特定查找算法的数据结构,这种数据结构指向数据本身
可以理解成字典的目录,索引就是以某种顺序对该字段进行排序的一种方式
应该将表更索引分开理解
分聚集索引(按拼音搜索)跟非聚集索引(按偏旁搜索)
索引需要存储位置的,索引越多容量越大。。
聚集索引只能有一个。。即数据排序规则只能有一个(有多个规则就乱了)mysql默认主键为聚集索引,其他的都是非聚集索引
非聚集索引可以有多个。。非聚集索引不存数据,只存指向聚集索引指针,需要回表查询
2:常用命令
查看
新建
create index index_name on table_name (column_list) ;
create unique index index_name on table_name (column_list) ;
修改
alter table table_name add index index_name (column_list) ; 普通索引
alter table table_name add unique (column_list) ; 唯一索引
alter table table_name add primary key (column_list) ; 主键索引
删除
drop index index_name on table_name ;
alter table table_name drop index index_name ;
alter table table_name drop primary key ;
数据结构 B ,B+重要
基本概念
B树 == 可以理解为平衡树,数据存储在每个节点上
B+树 ==B树的升级,数据只存在叶子节点上,且叶子节点之间是双向回环链表
为啥要升级?
树的搜索效率取决于树的高度,高度越低,IO次数越少,效率越高
innoda 默认读取磁盘 16KB
B树节点是带数据的,假设每条数据1KB,则一次IO读取到的数据为16条
B+树节点只包含key跟指针,假设每条数据0.1kb,则一次IO 读160 条数据
同样高度为3,
B树可读取数据 112 ,B+树 1120
但是,B+树必须遍历到叶子节点,B树查到就返回
知道结构有啥用
1:主要体现在索引选择上,
索引字段要劲量小,使得每次io读取数据多
2:聚集索引(一般是主键)最好自增,
主要是树的自旋效率低,如果自定义主键,每次插入数据都要重排顺序
3:聚集索引最好同表建立,
如果数据量大,改索引会涉及到全表排序
锁
表锁
乐观锁
悲观锁
间隙锁

若有收获,就点个赞吧
0 人点赞
