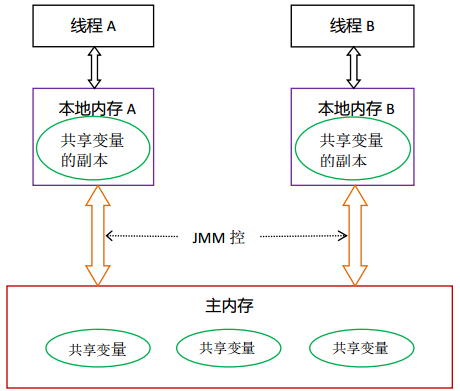
Java内存模型(JMM)
JMM 即 Java Memory Model,它定义了主存(所有线程共享的数据存放位置)、工作内存(每个线程私有的数据存放位置)抽象概念。线程可以把变量保存工作内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 CPU 缓存的影响
- 有序性 - 保证指令不会受 CPU 指令并行优化的影响
Volatile关键字
volatile关键字告诉编译器其修饰的变量是易变的,编译器根据易变属性会做一些操作。它会确保修饰的变量每次读操作都从主内存里读取,每次写操作都将值写到主内存里。volatile关键字就是给编译器做个提示,告诉编译器不要对修饰的变量做过度的优化,提示编译器该变量的值可能会以其它形式被改变,避免没有产生预期的行为,单例模式中的DCL就是用volatile修饰避免指令重排序导致的异常。volatile只能保证线程的可见性和禁止指令重排序,不能保证原子性,故不适用多线程。
public class Instance {private String str = "";private int a = 0;private volatile static Instance ins = null; //避免指令重排序/*** 构造方法私有化*/private Instance(){}/*** DCL方式获取单例* @return*/public static Instance getInstance(){if (ins == null){ //减少锁竞争synchronized (Instance.class){if (ins == null){ //如果不加判断,会导致多个线程newins = new Instance();}}}return ins;}}



如何保证线程安全
- 锁机制(同步阻塞)
- CAS(同步非阻塞 ABA问题用版本号解决)
- ThreadLocal
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作,所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 “重量级锁” 。但是,在JDK 1.6之后为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁,优化过程会涉及到锁的升级。synchronized的底层实现主要依靠 Lock-Free 的队列,基本思路是自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。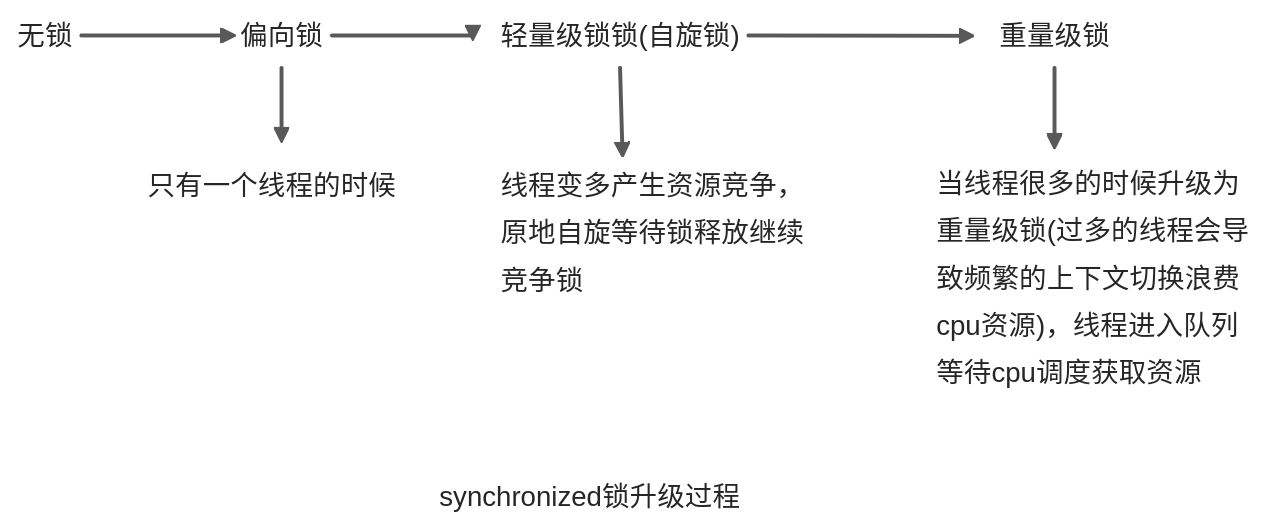
悲观锁与乐观锁
- 悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
Map集合
线程安全的map
- Collections.synchronizedMap(),使用synchronized锁实现
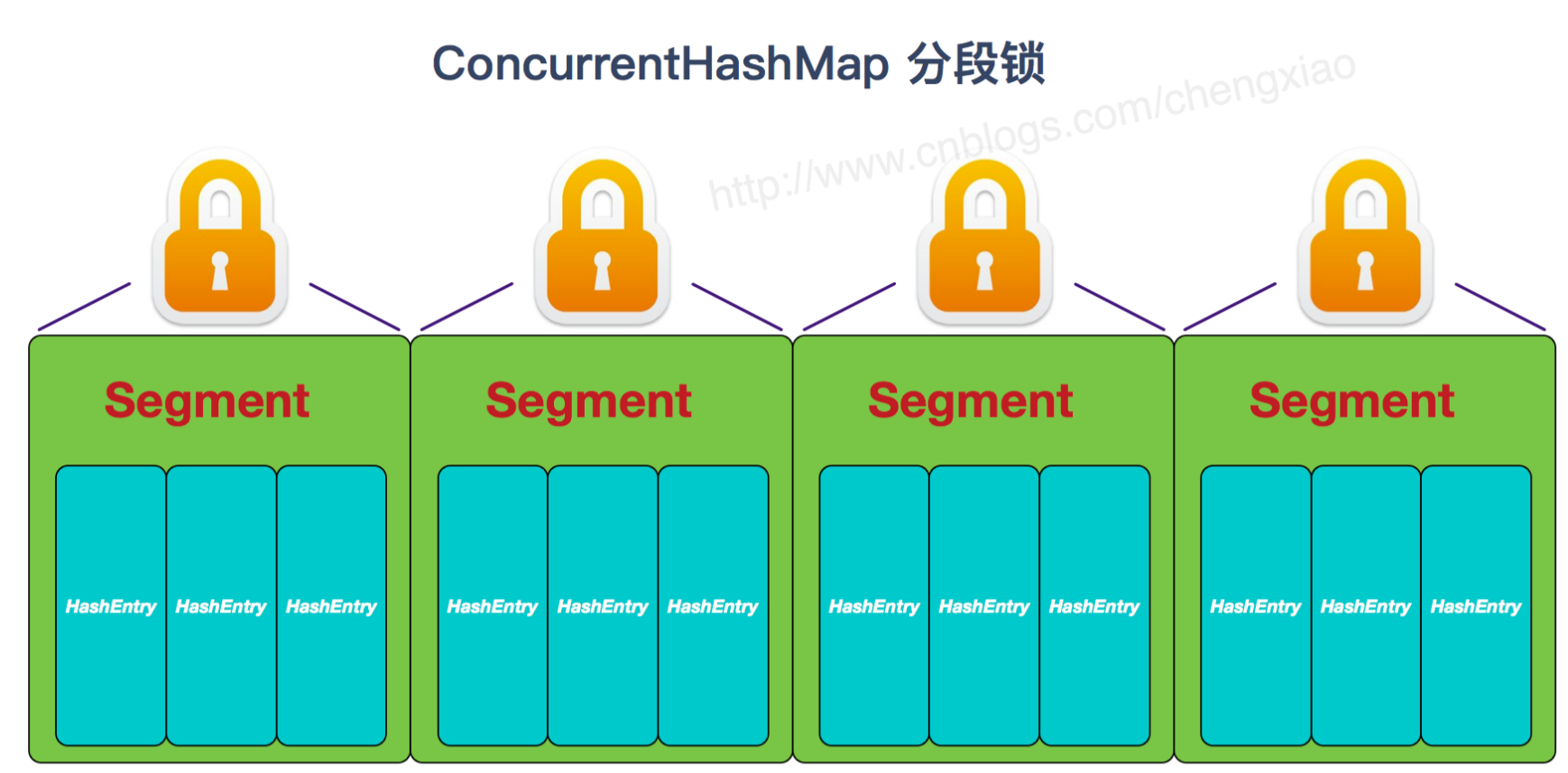
- ConcurrentHashMap,使用synchronized+CAS乐观锁实现
- Hashtable,使用synchronized锁实现(现在基本废弃)
- ConcurrentHashMap和Hashtable的区别
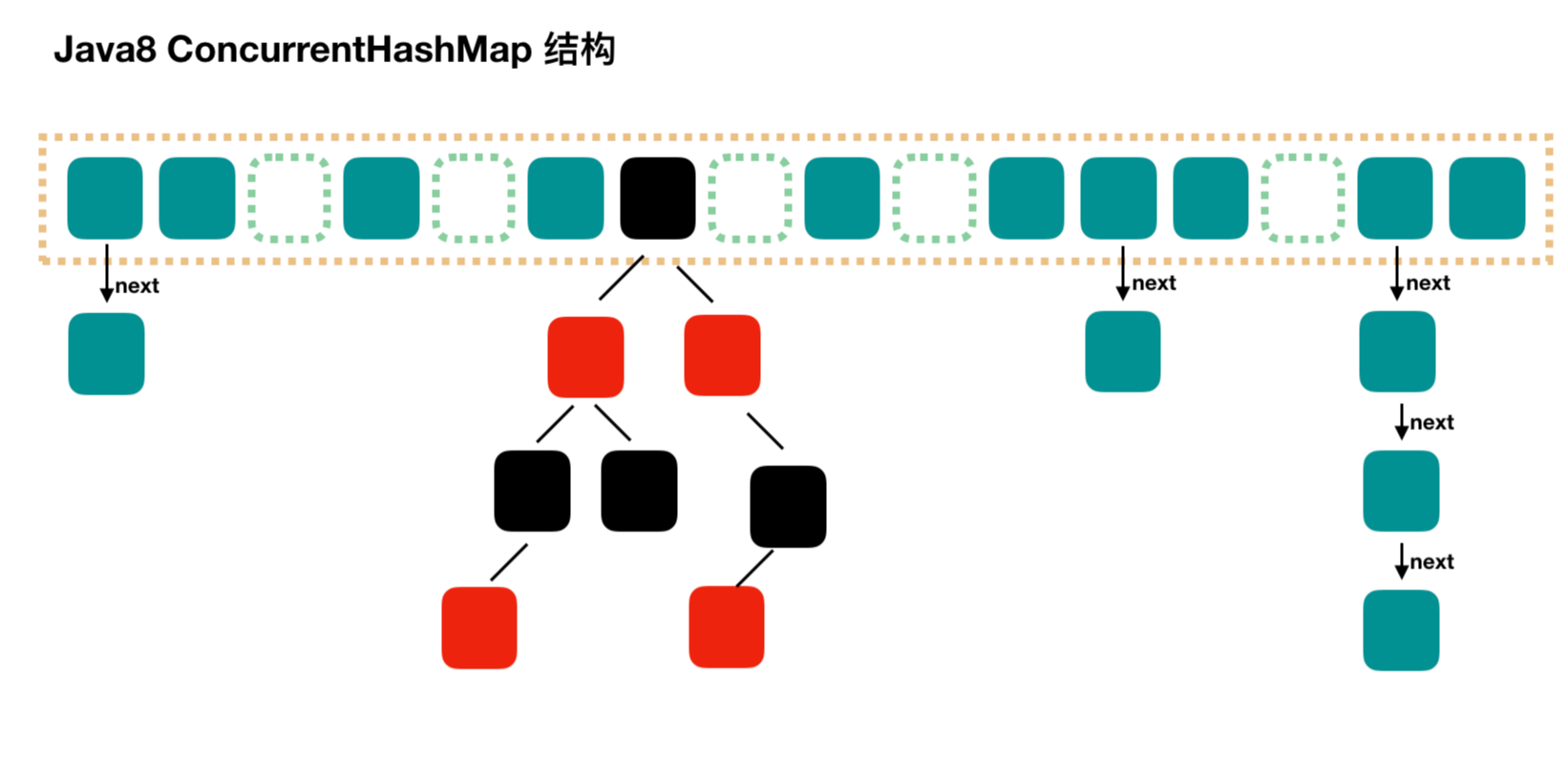
底层数据结构:JDK1.7的ConcurrentHashMap底层采用分段的数组+链表实现,JDK1.8 采用的数据结构跟 HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和JDK1.8 之前的HashMap的底层数据结构类似都是采用数组+链表的形式,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的;
实现线程安全的方式: ① 在JDK1.7的时候,ConcurrentHashMap(分段锁)对整个桶数组进行了分割分段,每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。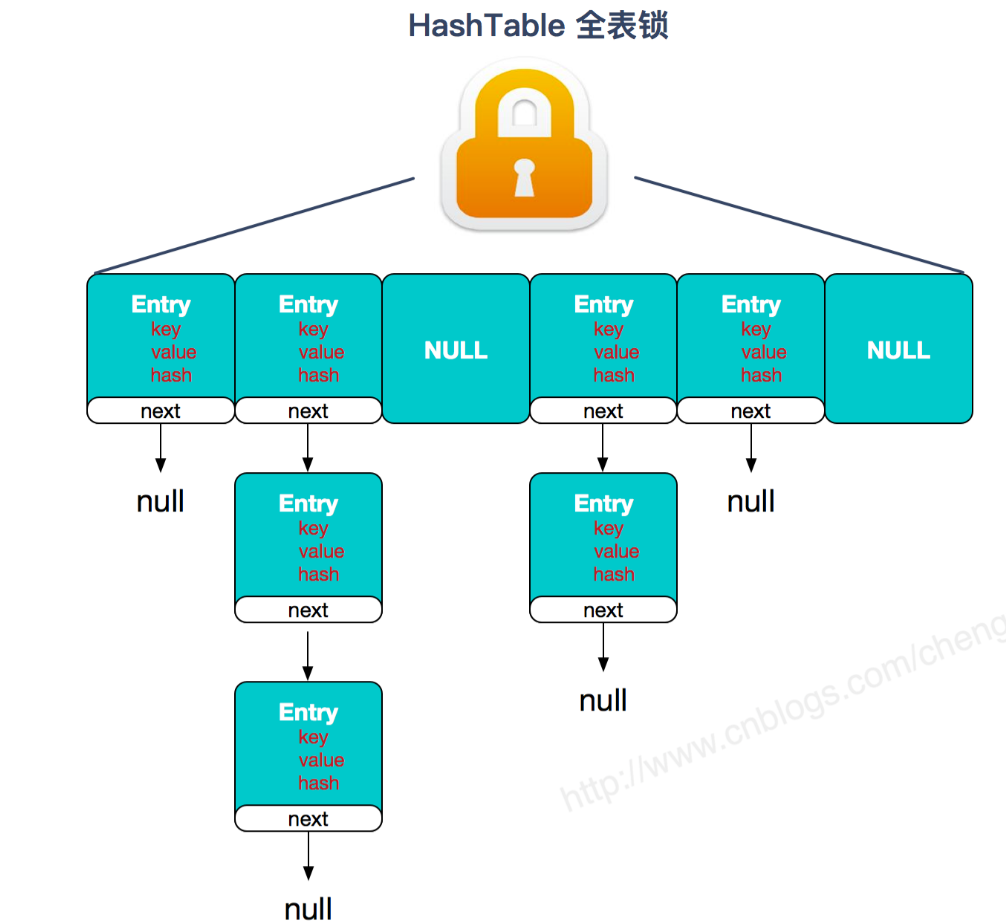
- Hashmap扩容机制
空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让 阈值=容量x负载因子 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;

若有收获,就点个赞吧
0 人点赞
